So, there are two types of web bots - legitimate and malicious. The legitimate ones include search engines, RSS readers. Examples of malicious web bots are vulnerability scanners, scrapers, spammers, DDoS bots, and payment card fraud Trojans. Once the type of web bot has been identified, various policies can be applied to it. If the bot is legitimate, you can lower the priority of its requests to the server or lower the level of access to certain resources. If a bot is identified as malicious, you can block it or send it to the sandbox for further analysis. Detecting, analyzing, and classifying web bots is important because they can do harm, for example, leak business-critical data. It will also reduce the load on the server and reduce the so-called noise in traffic, because up to 66% of web bot traffic is exactlymalicious traffic .
Existing approaches
There are different techniques for detecting web bots in network traffic, ranging from limiting the frequency of requests to a host, blacklisting IP addresses, analyzing the value of the User-Agent HTTP header, fingerprinting a device - and ending with the implementation of CAPTCHAs, and behavioral analysis of network activity using machine learning.
But collecting reputation information about a site and keeping blacklists up to date using various knowledge bases and threat intelligence is a costly, laborious process, and when using proxy servers, it is not advisable.
The analysis of the User-Agent field in a first approximation may seem useful, but nothing prevents a web bot or a user from changing the values of this field to a valid one, disguising themselves as a regular user and using a valid User-Agent for the browser, or as a legitimate bot. Let's call such webbots impersonators. Using various device fingerprints (tracking mouse movement or checking the client's ability to render an HTML page) allows us to highlight more difficult-to-detect web bots that imitate human behavior, for example, requesting additional pages (style files, icons, etc.), parsing JavaScript. This approach is based on client-side code injection, which is often unacceptable, since a mistake while inserting an additional script can break the web application.
It should be noted that web bots can also be detected online: the session will be evaluated in real time. A description of this formulation of the problem can be found in Cabri et al. [1], as well as in the works of Zi Chu [2]. Another approach is to analyze only after the session ends. The most interesting, obviously, is the first option, which allows you to make decisions faster.
The proposed approach
We used machine learning techniques and ELK (Elasticsearch Logstash Kibana) technology stack to identify and classify web bots. The objects of research were HTTP sessions. Session is a sequence of requests from one node (unique value of the IP address and the User-Agent field in the HTTP request) in a fixed time interval. Derek and Gohale use a 30-minute interval to define session boundaries [3]. Iliu et al. Argue that this approach does not guarantee real session uniqueness, but is still acceptable. Due to the fact that the User-Agent field can be changed, more sessions may appear than there actually are. Therefore Nikiforakis and co-authors propose more fine-tuning based on whether ActiveX is supported, whether Flash is enabled, screen resolution, OS version.
We will consider an acceptable error in the formation of a separate session if the User-Agent field changes dynamically. And to identify bot sessions, we will build a clear binary classification model and use:
- automatic network activity generated by a web bot (tag bot);
- human-generated network activity (tag human).
To classify web bots by activity type, let's build a multi-class model from the table below.
| Name | Description | Label | Examples of |
|---|---|---|---|
| Crawlers | Web bots
collecting web pages |
crawler | SemrushBot,
360Spider, Heritrix |
| Social networks | Web bots of various
social networks |
social_network | LinkedInBot,
WhatsApp Bot, Facebook bot |
| Rss readers | -,
RSS |
rss | Feedfetcher,
Feed Reader, SimplePie |
| -
|
search_engines | Googlebot, BingBot,
YandexBot |
|
| -,
|
libs_tools | Curl, Wget,
python-requests, scrapy |
|
| - | bots | ||
| ,
User-Agent |
unknown |
We will also solve the problem of online training of the model.
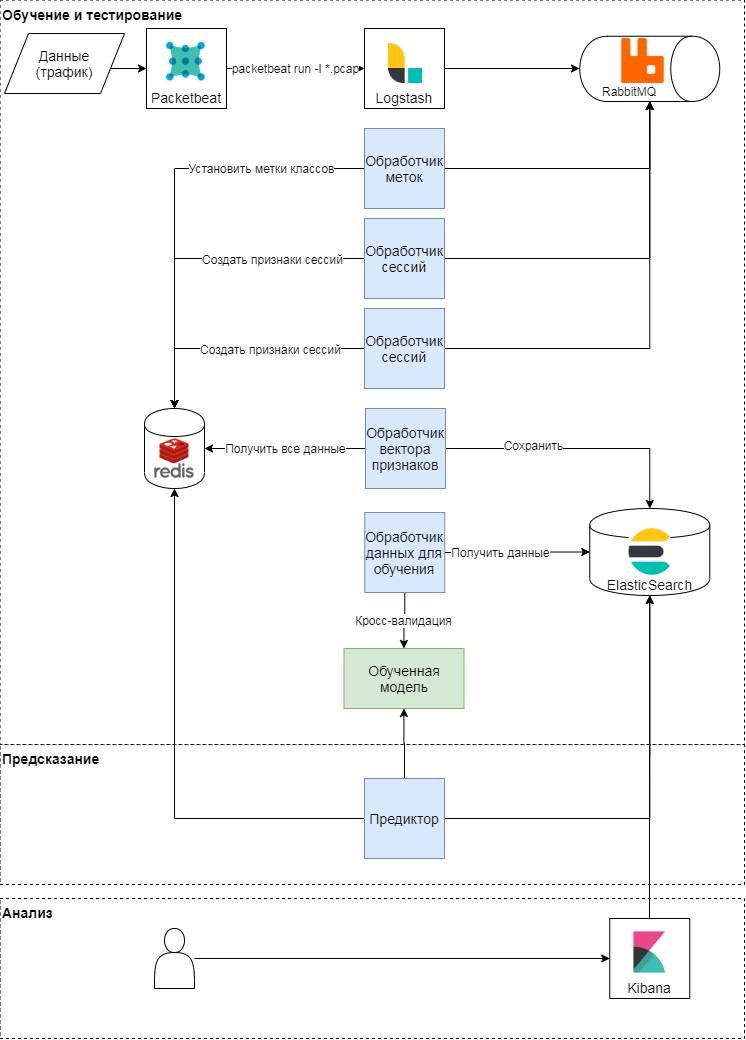
Conceptual scheme of the proposed approach
This approach has three stages: training and testing, prediction, analysis of results. Let's consider the first two in more detail. Conceptually, the approach follows the classic pattern of learning and applying machine learning models. First, quality metrics and attributes for classification are determined. After that, a vector of features is formed and a series of experiments (various cross-checks) are carried out to validate the model and select the hyperparameters. At the last stage, the best model is selected and the quality of the model is checked on a deferred sample.
Model training and testing
The packetbeat module is used to parse traffic. Raw HTTP requests are sent to logstash, where tasks are generated using a Ruby script in Celery terms. Each of them operates with a session identifier, request time, request body and headers. Session identifier (key) - the value of the hash function from the concatenation of the IP address and User-Agent. At this stage, two types of tasks are created:
- on the formation of a vector of features for the session,
- by labeling the class based on the request text and User-Agent.
These tasks are sent to a queue where message handlers execute them. Thus, the labeler handler performs the task of labeling the class using expert judgment and open data from the browscap service based on the User-Agent used; the result is written to key-value storage. The Session processor generates a feature vector (see the table below) and writes the result for each key in the key-value storage, and also sets the key lifetime (TTL).
| Sign | Description |
|---|---|
| len | Number of requests per session |
| len_pages | Number of requests per session in pages
(URI ends with .htm, .html, .php, .asp, .aspx, .jsp) |
| len_static_request | Number of requests per session in
static pages |
| len_sec | Session time in seconds |
| len_unique_uri | Number of requests per session
containing a unique URI |
| headers_cnt | Number of headers per session |
| has_cookie | Is there a cookie header |
| has_referer | Is there a Referer header |
| mean_time_page | Average time per page per session |
| mean_time_request | Average time per request per session |
| mean_headers | Average number of headers per session |
This is how the feature matrix is formed and the target class label for each session is set. Based on this matrix, periodic training of models and subsequent selection of hyperparameters occurs. For training, we used: logistic regression, support vector machine, decision trees, gradient boosting over decision trees, random forest algorithm. The most relevant results were obtained using the random forest algorithm.
Prediction
During the parsing of traffic, the vector of session attributes in key-value storage is updated: when a new request appears in the session, the attributes describing it are recalculated. For example, the sign the average number of headers in a session (mean_headers) is calculated every time a new request is added to the session. The Predictor sends the session feature vector to the model, and writes the response from the model to Elasticsearch for analysis.
Experiment
We tested our solution on the traffic of the SecurityLab.ru portal . Data volume - more than 15 GB, more than 130 hours. The number of sessions is more than 10,000. Due to the fact that the proposed model uses statistical features, sessions containing less than 10 requests were not involved in training and testing. As quality metrics, we used the classic quality metrics - accuracy, completeness and F-measure for each class.
Testing the Web Bot Discovery Model
We will build and evaluate a binary classification model, that is, we will detect bots, and then we will classify them by the type of activity. Based on the results of a five-fold stratified cross-validation (this is exactly what is required for the data under consideration, since there is a strong class imbalance), we can say that the constructed model is quite good (accuracy and completeness - more than 98%) is able to separate the classes of human users and bots.
| Average accuracy | Average fullness | Average F-measure | |
|---|---|---|---|
| bot | 0.86 | 0.90 | 0.88 |
| human | 0.98 | 0.97 | 0.97 |
The results of testing the model on a deferred sample are presented in the table below.
| Accuracy | Completeness | F-measure | Number of
examples |
|
|---|---|---|---|---|
| bot | 0.88 | 0.90 | 0.89 | 1816 |
| human | 0.98 | 0.98 | 0.98 | 9071 |
The values of the quality metrics on the deferred sampling approximately coincide with the values of the quality metrics during model validation, which means that the model on these data can generalize the knowledge gained during training.
Let's consider the errors of the first kind. If these data are marked out expertly, then the error matrix will change significantly. This means that some errors were made when marking up the data for the model, but the model was still able to recognize such sessions correctly.
| Accuracy | Completeness | F-measure | Number of
examples |
|
|---|---|---|---|---|
| bot | 0.93 | 0.92 | 0.93 | 2446 |
| human | 0.98 | 0.98 | 0.98 | 8441 |
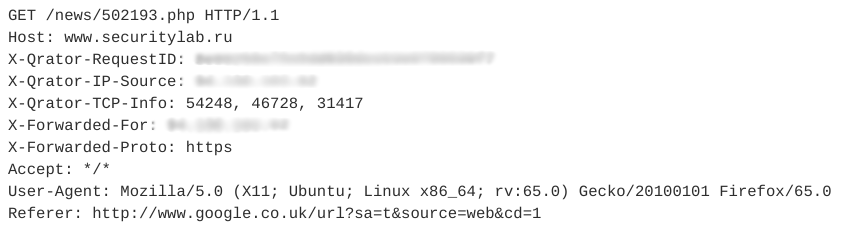
Let's look at an example session impersonators. It contains 12 similar queries. One of the requests is shown in the figure below.
All subsequent requests in this session have the same structure and differ only in the URI.
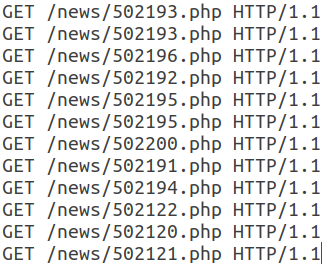
Note that this webbot uses a valid User-Agent, adds a Referer field, usually used non-automatically, and the number of headers in a session is small. In addition, the temporal characteristics of requests - session time, average time per request - allow us to say that this activity is automatic and belongs to the class of RSS readers. In this case, the bot itself is disguised as an ordinary user.
Testing the web bot classification model
To classify web bots by activity type, we will use the same data and the same algorithm as in the previous experiment. The results of testing the model on a deferred sample are presented in the table below.
| Accuracy | Completeness | F-measure | Number of
examples |
|
|---|---|---|---|---|
| bot | 0.82 | 0.81 | 0.82 | 194 |
| crawler | 0.87 | 0.72 | 0.79 | 65 |
| libs_tools | 0.27 | 0.17 | 0.21 | eighteen |
| rss | 0.95 | 0.97 | 0.96 | 1823 |
| search engines | 0.84 | 0.76 | 0.80 | 228 |
| social_network | 0.80 | 0.79 | 0.84 | 73 |
| unknown | 0.65 | 0.62 | 0.64 | 45 |
The quality for the libs_tools category is low, but the insufficient volume of examples for evaluation does not allow us to speak about the correctness of the results. A second series of experiments should be carried out to classify web bots on more data. We can say with confidence that the current model with a fairly high accuracy and completeness is able to separate the classes of RSS readers, search engines and general bots.
According to these experiments on the data under consideration, more than 22% of sessions (with a total volume of more than 15 GB) are created automatically, and among them 87% are related to the activity of general bots, unknown bots, RSS readers, web bots using various libraries and utilities ... Thus, if you filter the network traffic of web bots by the type of activity, then the proposed approach will reduce the load on the used server resources by at least 9-10%.
Testing the web bot classification model online
The essence of this experiment is as follows: in real time, after parsing the traffic, features are identified and feature vectors are formed for each session. Periodically, each session is sent to the model for prediction, the results of which are saved.
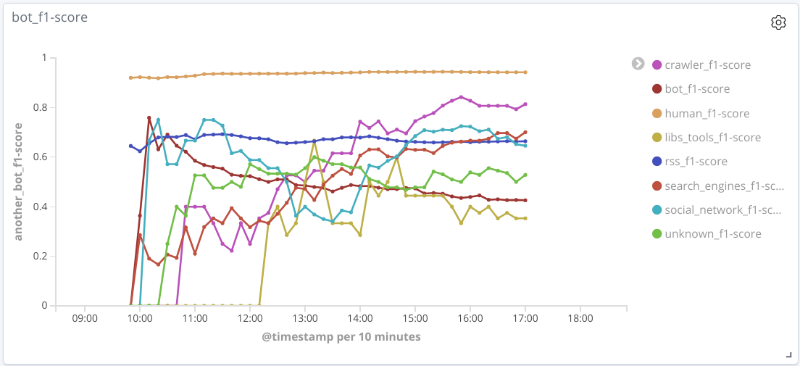
F-measure of the model over time for each class The
graphs below illustrate the change in the value of quality metrics over time for the most interesting classes. The size of the points on them is related to the number of sessions in the sample at a particular time.

Precision, completeness, F-measure for the search engines class

Precision, completeness, F-measure for the libs tools class
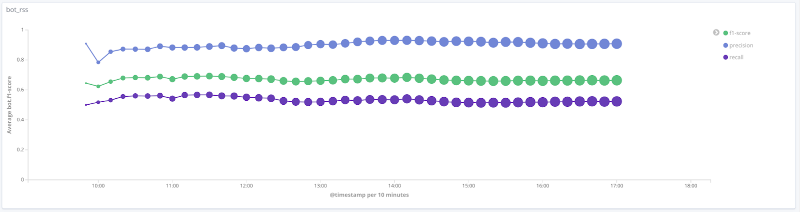
Precision, completeness, F-measure for the rss class

Precision, completeness, F-measure for the crawler class

Precision, completeness, F-measure for class human
For a number of classes (human, rss, search_engines) on the data under consideration, the quality of the model is acceptable (accuracy and completeness over 80%). For the crawler class, with an increase in the number of sessions and a qualitative change in the feature vector for this sample, the quality of the model increases: the completeness increased from 33% to 80%. It is impossible to draw reasonable conclusions for the libs_tools class, since the number of examples for this class is small (less than 50); therefore, negative results (poor quality) cannot be confirmed.
Main results and further development
We have described one approach to detecting and classifying web bots using machine learning algorithms and using statistical features. On the data under consideration, the average accuracy and completeness of the proposed solution for binary classification is more than 95%, which indicates that the approach is promising. For certain classes of web bots, the average accuracy and completeness is about 80%.
The validation of the constructed models requires a real assessment of the session. As shown earlier, the performance of the model is significantly improved when the correct markup is available for the target class. Unfortunately, now it is difficult to automatically build such markup and you have to resort to expert markup, which complicates the construction of machine learning models, but allows you to find hidden patterns in the data.
For the further development of the problem of classification and detection of web bots, it is advisable to:
- allocate additional classes of bots and retrain, test the model;
- add additional signs to classify web bots. For example, adding a robots.txt attribute, which is binary and is responsible for the presence or absence of access to a robots.txt page, allows you to increase the average F-score for a class of web bots by 3% without worsening other quality metrics for other classes;
- make more correct markup for the target class, taking into account additional meta-features and expert judgment.
Author : Nikolay Lyfenko, Leading Specialist, Advanced Technologies Group, Positive Technologies
Sources
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.