
I tell from personal experience what came in handy where and when. Survey and thesis, so that it was clear what and where to dig further - but here I have an exclusively subjective personal experience, maybe everything is completely different with you.
Why is it important to know and be able to handle query languages? At its core, in Data Science there are several most important stages of work and the very first and most important (without it, nothing will work, of course!) Is data acquisition or retrieval. Most often, data in some form is sitting somewhere and you need to "get it" from there.
Query languages just allow you to extract this very data! And today I will tell you about those query languages that came in handy for me and I will tell-show where and how exactly - why it is needed to study.
In total, there will be three main blocks of types of queries to data, which we will analyze in this article:
- "Standard" query languages are what they usually understand when talking about a query language such as relational algebra or SQL.
- Scripting query languages such as pandas python tricks, numpy or shell scripting.
- Query languages for knowledge graphs and graph databases.
Everything written here is just a personal experience, which came in handy, with a description of situations and "why it was needed" - everyone can try on how similar situations can meet you and try to prepare for them in advance, having dealt with these languages before you have to to (urgently) apply on a project or even get on a project where they are needed.
"Standard" query languages
Standard query languages are precisely in the sense that we usually think about them when we talk about queries.
Relational algebra
Why relational algebra is needed today? In order to have a good idea of why query languages are arranged in a certain way and to use them deliberately, you need to understand the underlying core.
What is Relational Algebra?
The formal definition is as follows: relational algebra is a closed system of operations on relations in a relational data model. More humanly, this is a system of operations on tables, such that the result is also always a table.
See all relational operations in this article from Habr - here we describe why you need to know and where it comes in handy.
What for?
You begin to understand what query languages are generally used for and what operations are behind the expressions of specific query languages - often gives a deeper understanding of what and how works in query languages.
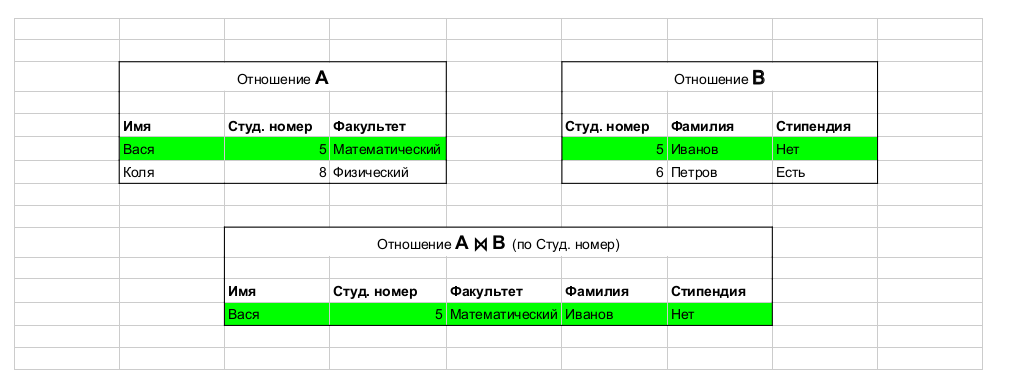
Taken from this article. Example operation: join, which joins tables.
Study Materials:
A good introductory course from Stanford . In general, there are a lot of materials on relational algebra and theory - Coursera, Udacity. There is also a huge amount of online materials, including good academic courses . My personal advice is to understand relational algebra very well - this is the foundation.
SQL

Taken from this article.
SQL is, in fact, an implementation of relational algebra - with an important caveat, SQL is declarative! That is, writing a query in the language of relational algebra, you actually say how to count - but with SQL you specify what you want to extract, and then the DBMS already generates (effective) expressions in the language of relational algebra (their equivalence is known to us under Codd's theorem ) ...
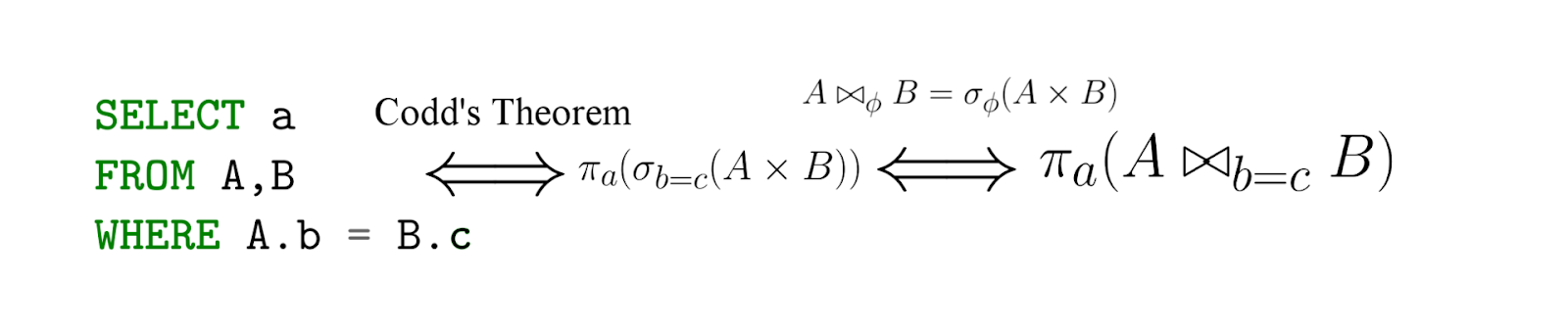
Taken from this article.
What for?
Relational DBMSs: Oracle, Postgres, SQL Server, etc are still virtually all over the place and there is an incredibly high chance that you will have to interact with them, which means that you will have to either read SQL (which is very likely) or write in it ( also not unlikely).
What to read and learn
From the same links above (on relational algebra), there is an incredible amount of material, such as this one .
By the way, what is NoSQL?
"It is worth emphasizing once again that the term" NoSQL "has a completely spontaneous origin and does not have a generally accepted definition or a scientific institution behind it." The corresponding article on Habré.
In fact, people realized that a complete relational model is not needed to solve many problems, especially for those where, for example, performance is fundamental and certain simple queries with aggregation dominate - it is critical to quickly read metrics and write them to the database, and most of the features are relational. turned out to be not only unnecessary, but also harmful - why normalize something if it will spoil the most important thing for us (for some specific task) - performance?
Also, often needed flexible schemas instead of the fixed mathematical schemas of the classical relational model - and this incredibly simplifies application development, when it is critical to deploy the system and start working quickly, processing the results - or the schema and types of stored data are not so important.
For example, we are creating an expert system and we want to store information on a specific domain along with some meta information - we may not know all the fields and it is corny to store JSON for each record - this gives us a very flexible environment for expanding the data model and fast iteration - therefore, in such the case of NoSQL would be even preferable and readable. An example of an entry (from one of my projects, where NoSQL was right where it was needed).
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775," ","ru"],
"en_wiki_pagecount":2338861}
You can read more about NoSQL here .
What to Study?
Rather, you just need to be good at analyzing your task, what properties it has and what NoSQL systems are available that would fit this description - and already study this system.
Scripting query languages
At first, it seems, what does Python have to do with it - it's a programming language, and not about queries at all.

- Pandas is a direct Swiss knife of Data Science, a huge amount of data transformation, aggregation, etc. takes place in it.
- Numpy is vector computing, matrices and linear algebra out there.
- Scipy is a lot of math in this package, especially stats.
- Jupyter lab - a lot of exploratory data analysis fits well into laptops - good to be able to.
- Requests - networking.
- Pysparks are very popular among data engineers, most likely you will need to interact with this or and spark, simply because of their popularity.
- * Selenium is very useful for collecting data from sites and resources, sometimes there is simply no other way to get the data.
My top tip: Learn Python!
Pandas
Let's take the following code as an example:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])\
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})\
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))In fact, we can see that the code fits into the classic SQL pattern.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_nameBut the important part is that this code is part of the script and the pipeline, in fact, we are embedding requests into the Python pipeline. In this situation, the query language comes to us from libraries such as Pandas or pySpark.
In general, in pySpark we see a similar type of data transformation through the query language in the spirit of:
df.filter(df.trip_type = “return”)\
.groupby(“day”)\
.agg({duration: 'mean'})\
.sort()Where and what to read
It is not a problem to find materials for study on python itself . There are a huge number of tutorials on pandas , pySpark and courses on Spark (as well as on DS itself ) on the net . In general, the materials here are great googling and if I had to choose one package to focus on, it would be pandas, of course. There are also a lot of materials on the DS + Python bundle .
Shell as a query language
A lot of data processing and analysis projects that I had to work with are, in fact, shell scripts that call code in Python, in java and the shell commands themselves. Therefore, in general, you can consider the pipelines in the bash / zsh / etc, as some high-level request (you can, of course, push loops there, but this is not typical for DS code in shell languages), let's give a simple example - I needed to map the QID of the wikidata and a complete link to the Russian and English wiki, for this I wrote a simple query from the commands in the bash and for the output I wrote a simple script in Python, which I put together like this:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
Where
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' This was, in fact, the entire pipeline that created the necessary mapping, as we see everything, it worked in stream mode:
- pv filepath - gives a progress bar based on file size and passes its contents on
- unpigz -c read part of the archive and gave jq
- jq with the key - stream immediately produced the result and passed it to the postprocessor (just like with the very first example) in Python
- internally the post processor is a simple state machine that formatted the output
In total, a complex pipeline working in a stream mode on big data (0.5TB), without significant resources and made of a simple pipeline and a couple of tools.
Another important tip: be good and efficient in the terminal and write in bash / zsh / etc.Where is it useful? Yes, almost everywhere - there are, again, a LOT of materials for study on the net. In particular, this is my previous article.
R scripting
Again, the reader may exclaim - well, this is a whole programming language! And of course he will be right. However, I usually had to deal with R always in such a context that, in fact, it was very similar to a query language.
R is a statistical computing framework and a static computing and visualization language (according to this ).
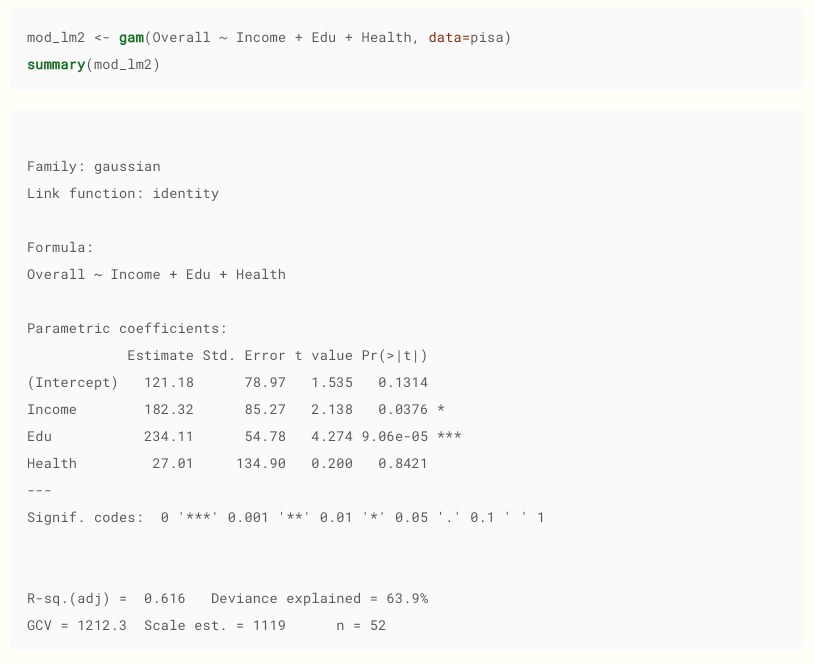
Taken from here . By the way, I recommend, good material.
Why date a Scientist to know R? At least, because there is a huge layer of non-IT people who are engaged in data analysis in R. I have met in the following places:
- Pharmaceutical sector.
- Biologists.
- Financial sector.
- People with a purely mathematical education, dealing with stats.
- Specialized statistical and machine learning models (which can often only be found in the upstream version as an R package).
Why is it actually a query language? In the form in which it is often found, it is actually a request to create a model, including reading data and fixing query parameters (model), as well as visualizing data in packages such as ggplot2 - this is also a form of writing queries.
Example of queries for rendering
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))In general, many ideas from R have migrated to python packages such as pandas, numpy or scipy, like dataframes and data vectorization - therefore, in general, a lot of things in R will seem familiar and convenient to you.
There are many sources for studying, for example, this one .
Knowledge graph
Here I have a slightly unusual experience, because I still quite often have to work with knowledge graphs and query languages for graphs. Therefore, let's just go over the basics briefly, as this part is a little more exotic.
In classical relational databases we have a fixed schema - here the schema is flexible, each predicate is actually a "column" and even more.
Imagine that you would model a person and would like to describe key things, for example, let's take a specific person by Douglas Adams, we will take this description as a basis.
www.wikidata.org/wiki/Q42
If we were using a relational database, we would have to create a huge table or tables with a huge number of columns, most of which would be NULL or filled with some default False value, for example, unlikely many of us have an entry in the national Korean library - of course, we could put them in separate tables, but this would ultimately be an attempt to model flexible logic with predicates using a fixed relational one.
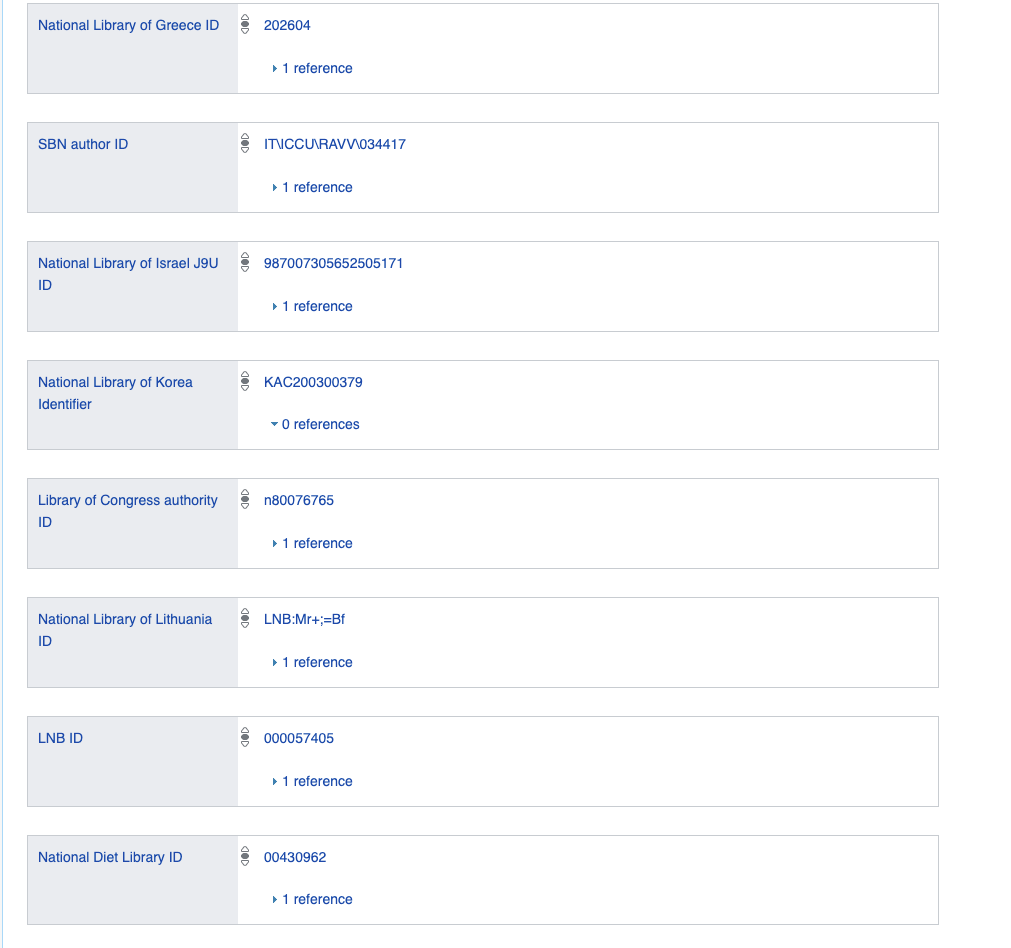
Therefore, imagine that all data is stored as a graph or as binary and unary logical expressions.
Where can you even run into this? First, working with wiki data , and with any graph databases or connected data.
The following are the main query languages that I have used and worked with.
SPARQL
Wiki:
SPARQL ( . SPARQL Protocol and RDF Query Language) — , RDF, . SPARQL W3C .
But in reality it is a language of queries to logical unary and binary predicates. You are simply conditionally stating what is fixed in a boolean expression and what is not (very simplistic).
The RDF (Resource Description Framework) base itself, over which SPARQL queries are executed, is a triplet
object, predicate, subject- and the query selects the necessary triplets according to the specified constraints in the spirit of: find an X such that p_55 (X, q_33) is true - where, of course, p_55 is what -that relation with ID 55, and q_33 is an object with ID 33 (that's the whole story, again omitting all sorts of details).
Example of data presentation:
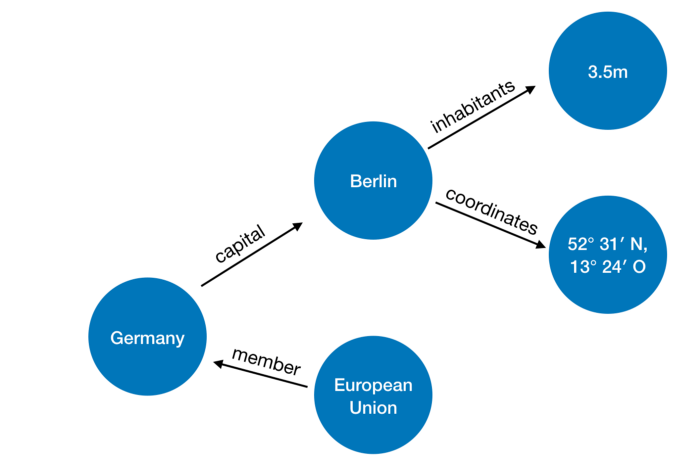
Pictures and an example with countries are from here .
Basic query example

In fact, we want to find the value of the variable? Country, such that for the predicate
member_of, it is true that member_of (? Country, q458) and q458 is the ID of the European Union.
An example of a real SPARQL query inside the python engine:
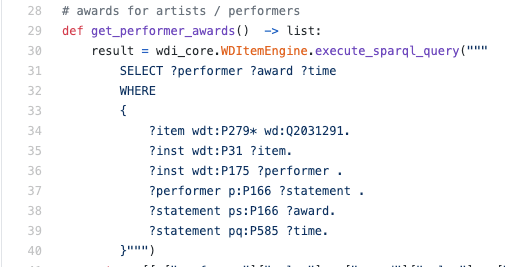
As a rule, I had to read SPARQL, not write - in such a situation, most likely it will be a useful skill to understand the language at least at a basic level in order to understand exactly how the data is retrieved.
There is a lot of study material online, like this one and this one . I myself usually google specific constructions and examples, and so far I have enough.
Logical query languages
You can read more on the topic in my article here . Here, we will just briefly discuss why logical languages are well suited for writing queries. In fact, RDF is just a collection of logical statements of the form p (X) and h (X, Y), and a logical query looks like this:
output(X) :- country(X), member_of(X,“EU”).
Here we are talking about creating a new predicate output / 1 (/ 1 means unary), when provided that it is true for X that country (X) - that is, X is the country and also member_of (X, “EU”).
That is, we have both the data and the rules in this case are generally presented in the same way, which makes it very easy and good to model tasks.
Where did you meet in the industry: a whole large project with a company that writes queries in such a language, as well as on the current project in the core of the system - it would seem that a rather exotic thing, but sometimes it occurs.
An example of a snippet of code in logical language processing wikidata:
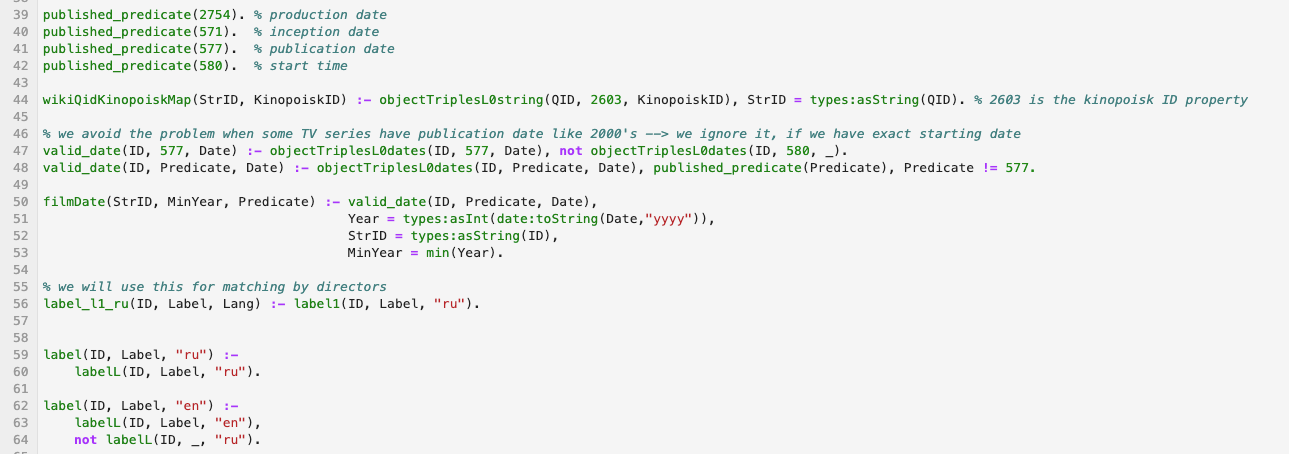
Materials: I will give here a couple of links to the modern logical programming language Answer Set Programming - I recommend studying it:
- http://peace.eas.asu.edu/aaai12tutorial/asp-tutorial-aaai.pdf
- http://ceur-ws.org/Vol-1145/tutorial1.pdf
- https://www.youtube.com/watch?v=gVQ0bP8zyHw
- https://www.youtube.com/watch?v=kdcd7Je2glc
- https://potassco.org/book/
- http://potassco.sourceforge.net/teaching.html
- https://www.cs.uni-potsdam.de/~torsten/Potassco/Tutorials/fmcad12.pdf
