
The last part of a collection of stories from the Internet about how bugs sometimes have completely incredible manifestations. Part one , part two .
Little SSH that (sometimes) couldn't
This is a story about one of the most exciting bug hunts I was lucky enough to participate in.
At AdGear Technologies Inc., where I worked, everything was kept on SSH. We have used it for management, monitoring, deployment, log collection, even for live streaming. This protocol is robust and reliable, has the predictability of a native Unix tool, and just works.
But once letters without any specific time or host reference told us that the protocol was not working.
Time-out
The machines in our London data center had random crashes when sending log files to the Montreal data center. This task was periodically run from Cron, and the failure manifested itself like this:
- Cron emails reported problems with SSH.
- Sometimes it freezes.
- Sometimes it exits without a timeout error.
- In an internal health check, Nagios warns of missing data in Montreal.
We logged into the London cars, manually launched the command
pushand it worked successfully. We chalked it up to a temporary network problem.
Timeouts
But the crashes kept repeating randomly. Once a day, a couple of times a day, Friday morning, several times an hour. It was clear that it was getting worse. We continued to manually push files until we figured out what the problem was.
There were 17 hops between London and Montreal. We have created a packet delay and loss profile. It turned out that 1-3% of packets were lost on a couple of hops. Together with the Operations Department of the London Data Center, we applied for rerouting.
While Londoners were checking the packet loss information, we started looking for random timeouts on the way from London to our secondData center in Montreal. The hops on this route were different, not the ones that lost packets. We decided that the loss was not the main problem, and besides the Londoners reported that they could not reproduce the loss of packets or timeouts, and that everything looked fine on their side.
Apocalypse
While manually forwarding bad Cron messages, we noticed an interesting pattern. The files were either successfully transferred at high speed, or they were not transferred at all and hung on timeout. There have been no cases of files being downloaded successfully at low speeds.
By removing most of the data from the equation, we were able to recreate the script using simple vanilla SSH. In the London data center, the "SSH mtl-machine" server either immediately completed the task or hung and could not establish a connection. The surprise started to grow.
Where did the packages go?
We checked the SSH server configuration and systems in Montreal three times:
- DNS servers responded quickly.
- The reverse DNS lookup zone has been disabled.
- The maximum number of client connections was high enough.
- We were not attacked.
- The channel was not clogged.
In addition, even if something was not working, we would observe freezes when working with two different data centers in Montreal. Moreover, our non-London data centers successfully communicated with Montreal. That is, the problem was related to London.
We ran tcpdump and watched the packages. We were interested in the general dynamics and data obtained using Pcaps and loaded into Wireshark. We saw signs of packet loss and retransmission, but everything was minimal and not a cause for concern.
Then we analyzed the entire connection in situations where SSH communication was established successfully, and then - connections in situations where SSH communication was hanging.
When the connection from London to Montreal was stuck, we came to the following conclusions:
- Establishing a TCP connection went fine.
- Service SSH information was sent back and forth. Where necessary, there were normal TCP ack packets.
- A specific package was sent from London and received in Montreal.
- The same package was re-sent several times from London and received in Montreal.
- Montreal simply does not answer this!
It was not clear why Montreal was not responding (because of this London is sending data again). The connection hung on this because the Layer 4 protocol was hanging. Even more exciting was the fact that if you interrupt the repeated SSH sending in London and immediately restart it, then it will work successfully. In this case, tcpdump indicated that Montreal received the package and responded to it, and work continued.
On the SSH client in London, we enabled verbose debugging (
-vvv), and after these log entries, the connection hung:
debug2: kex_parse_kexinit: first_kex_follows 0
debug2: kex_parse_kexinit: reserved 0
debug2: mac_setup: found hmac-md5
debug1: kex: server->client aes128-ctr hmac-md5 none
debug2: mac_setup: found hmac-md5
debug1: kex: client->server aes128-ctr hmac-md5 none
debug1: SSH2_MSG_KEX_DH_GEX_REQUEST(1024<1024<8192) sent
debug1: expecting SSH2_MSG_KEX_DH_GEX_GROUP
We googled "SSH hang SSH2_MSG_KEX_DH_GEX_GROUP" and got a lot of results, from Wi-Fi issues to TCP bugs in Windows and buggy routers losing TCP fragments. One of the solutions for LAN was to calculate the MSS of the path and set this value as the MTU at both ends of the route.
I kept decreasing the MTU on the London server from 1500 - it didn't help until I got to the magic value of 576. After that, SSH didn't hang again. I was running a script with an SSH loop, and if I wanted, I could cause timeouts by returning MTU to 1500, or get rid of them by setting 576. Unfortunately, these are public ad servers, and globally assigning an MTU of 1500 will not solve the problem. However, it was already mentioned above that the process of fragmentation or reassembly of packets is probably broken somewhere.
Let's go back to checking the received packets with tcpdump: there were no signs of fragmentation. The size of the received packet was identical to the size of the sent one. If something fragmented the packet on byte 576+, then something was successfully reassembling it.
Twinkle twinkle, curve star
As I went deeper into the analysis, I looked at full packet dumps (
tcpdump -s 0 -X), not just headers. When comparing the magic packet from a successful send with a packet from a failed send, I found almost no difference except for the TCP / IP headers. But it was clear that this was the first packet on a TCP connection to contain enough data to go through the 576 byte mark. All previous packages were much smaller.
Comparing the same packet from the failed dispatch, in the form in which it left London and came to Montreal, my eyes caught on something. For something subtle, and I waved it off due to fatigue (it was late Friday evening). But after several updates and comparisons, I no longer imagined.
This is what the packet looked like after leaving London (minus the first few bytes identifying the IP addresses)
0x0040: 0b7c aecc 1774 b770 ad92 0000 00b7 6563 .|...t.p......ec
0x0050: 6468 2d73 6861 322d 6e69 7374 7032 3536 dh-sha2-nistp256
0x0060: 2c65 6364 682d 7368 6132 2d6e 6973 7470 ,ecdh-sha2-nistp
0x0070: 3338 342c 6563 6468 2d73 6861 322d 6e69 384,ecdh-sha2-ni
0x0080: 7374 7035 3231 2c64 6966 6669 652d 6865 stp521,diffie-he
0x0090: 6c6c 6d61 6e2d 6772 6f75 702d 6578 6368 llman-group-exch
0x00a0: 616e 6765 2d73 6861 3235 362c 6469 6666 ange-sha256,diff
0x00b0: 6965 2d68 656c 6c6d 616e 2d67 726f 7570 ie-hellman-group
0x00c0: 2d65 7863 6861 6e67 652d 7368 6131 2c64 -exchange-sha1,d
0x00d0: 6966 6669 652d 6865 6c6c 6d61 6e2d 6772 iffie-hellman-gr
0x00e0: 6f75 7031 342d 7368 6131 2c64 6966 6669 oup14-sha1,diffi
0x00f0: 652d 6865 6c6c 6d61 6e2d 6772 6f75 7031 e-hellman-group1
0x0100: 2d73 6861 3100 0000 2373 7368 2d72 7361 -sha1...#SSH-rsa
0x0110: 2c73 7368 2d64 7373 2c65 6364 7361 2d73 ,SSH-dss,ecdsa-s
0x0120: 6861 322d 6e69 7374 7032 3536 0000 009d ha2-nistp256....
0x0130: 6165 7331 3238 2d63 7472 2c61 6573 3139 aes128-ctr,aes19
0x0140: 322d 6374 722c 6165 7332 3536 2d63 7472 2-ctr,aes256-ctr
0x0150: 2c61 7263 666f 7572 3235 362c 6172 6366 ,arcfour256,arcf
0x0160: 6f75 7231 3238 2c61 6573 3132 382d 6362 our128,aes128-cb
0x0170: 632c 3364 6573 2d63 6263 2c62 6c6f 7766 c,3des-cbc,blowf
0x0180: 6973 682d 6362 632c 6361 7374 3132 382d ish-cbc,cast128-
0x0190: 6362 632c 6165 7331 3932 2d63 6263 2c61 cbc,aes192-cbc,a
0x01a0: 6573 3235 362d 6362 632c 6172 6366 6f75 es256-cbc,arcfou
0x01b0: 722c 7269 6a6e 6461 656c 2d63 6263 406c r,rijndael-cbc@l
0x01c0: 7973 6174 6f72 2e6c 6975 2e73 6500 0000 ysator.liu.se...
0x01d0: 9d61 6573 3132 382d 6374 722c 6165 7331 .aes128-ctr,aes1
0x01e0: 3932 2d63 7472 2c61 6573 3235 362d 6374 92-ctr,aes256-ct
0x01f0: 722c 6172 6366 6f75 7232 3536 2c61 7263 r,arcfour256,arc
0x0200: 666f 7572 3132 382c 6165 7331 3238 2d63 four128,aes128-c
0x0210: 6263 2c33 6465 732d 6362 632c 626c 6f77 bc,3des-cbc,blow
0x0220: 6669 7368 2d63 6263 2c63 6173 7431 3238 fish-cbc,cast128
0x0230: 2d63 6263 2c61 6573 3139 322d 6362 632c -cbc,aes192-cbc,
0x0240: 6165 7332 3536 2d63 6263 2c61 7263 666f aes256-cbc,arcfo
0x0250: 7572 2c72 696a 6e64 6165 6c2d 6362 6340 ur,rijndael-cbc@
0x0260: 6c79 7361 746f 722e 6c69 752e 7365 0000 lysator.liu.se..
0x0270: 00a7 686d 6163 2d6d 6435 2c68 6d61 632d ..hmac-md5,hmac-
0x0280: 7368 6131 2c75 6d61 632d 3634 406f 7065 sha1,umac-64@ope
0x0290: 6e73 7368 2e63 6f6d 2c68 6d61 632d 7368 nSSH.com,hmac-sh
0x02a0: 6132 2d32 3536 2c68 6d61 632d 7368 6132 a2-256,hmac-sha2
0x02b0: 2d32 3536 2d39 362c 686d 6163 2d73 6861 -256-96,hmac-sha
0x02c0: 322d 3531 322c 686d 6163 2d73 6861 322d 2-512,hmac-sha2-
0x02d0: 3531 322d 3936 2c68 6d61 632d 7269 7065 512-96,hmac-ripe
0x02e0: 6d64 3136 302c 686d 6163 2d72 6970 656d md160,hmac-ripem
0x02f0: 6431 3630 406f 7065 6e73 7368 2e63 6f6d d160@openSSH.com
0x0300: 2c68 6d61 632d 7368 6131 2d39 362c 686d ,hmac-sha1-96,hm
0x0310: 6163 2d6d 6435 2d39 3600 0000 a768 6d61 ac-md5-96....hma
0x0320: 632d 6d64 352c 686d 6163 2d73 6861 312c c-md5,hmac-sha1,
0x0330: 756d 6163 2d36 3440 6f70 656e 7373 682e umac-64@openSSH.
0x0340: 636f 6d2c 686d 6163 2d73 6861 322d 3235 com,hmac-sha2-25
0x0350: 362c 686d 6163 2d73 6861 322d 3235 362d 6,hmac-sha2-256-
0x0360: 3936 2c68 6d61 632d 7368 6132 2d35 3132 96,hmac-sha2-512
0x0370: 2c68 6d61 632d 7368 6132 2d35 3132 2d39 ,hmac-sha2-512-9
0x0380: 362c 686d 6163 2d72 6970 656d 6431 3630 6,hmac-ripemd160
0x0390: 2c68 6d61 632d 7269 7065 6d64 3136 3040 ,hmac-ripemd160@
0x03a0: 6f70 656e 7373 682e 636f 6d2c 686d 6163 openSSH.com,hmac
0x03b0: 2d73 6861 312d 3936 2c68 6d61 632d 6d64 -sha1-96,hmac-md
0x03c0: 352d 3936 0000 0015 6e6f 6e65 2c7a 6c69 5-96....none,zli
0x03d0: 6240 6f70 656e 7373 682e 636f 6d00 0000 b@openSSH.com...
0x03e0: 156e 6f6e 652c 7a6c 6962 406f 7065 6e73 .none,zlib@opens
0x03f0: 7368 2e63 6f6d 0000 0000 0000 0000 0000 sh.com..........
0x0400: 0000 0000 0000 0000 0000 0000 ............
And this is how the same package looked like when it arrived in Montreal
0x0040: 0b7c aecc 1774 b770 ad92 0000 00b7 6563 .|...t.p......ec
0x0050: 6468 2d73 6861 322d 6e69 7374 7032 3536 dh-sha2-nistp256
0x0060: 2c65 6364 682d 7368 6132 2d6e 6973 7470 ,ecdh-sha2-nistp
0x0070: 3338 342c 6563 6468 2d73 6861 322d 6e69 384,ecdh-sha2-ni
0x0080: 7374 7035 3231 2c64 6966 6669 652d 6865 stp521,diffie-he
0x0090: 6c6c 6d61 6e2d 6772 6f75 702d 6578 6368 llman-group-exch
0x00a0: 616e 6765 2d73 6861 3235 362c 6469 6666 ange-sha256,diff
0x00b0: 6965 2d68 656c 6c6d 616e 2d67 726f 7570 ie-hellman-group
0x00c0: 2d65 7863 6861 6e67 652d 7368 6131 2c64 -exchange-sha1,d
0x00d0: 6966 6669 652d 6865 6c6c 6d61 6e2d 6772 iffie-hellman-gr
0x00e0: 6f75 7031 342d 7368 6131 2c64 6966 6669 oup14-sha1,diffi
0x00f0: 652d 6865 6c6c 6d61 6e2d 6772 6f75 7031 e-hellman-group1
0x0100: 2d73 6861 3100 0000 2373 7368 2d72 7361 -sha1...#SSH-rsa
0x0110: 2c73 7368 2d64 7373 2c65 6364 7361 2d73 ,SSH-dss,ecdsa-s
0x0120: 6861 322d 6e69 7374 7032 3536 0000 009d ha2-nistp256....
0x0130: 6165 7331 3238 2d63 7472 2c61 6573 3139 aes128-ctr,aes19
0x0140: 322d 6374 722c 6165 7332 3536 2d63 7472 2-ctr,aes256-ctr
0x0150: 2c61 7263 666f 7572 3235 362c 6172 6366 ,arcfour256,arcf
0x0160: 6f75 7231 3238 2c61 6573 3132 382d 6362 our128,aes128-cb
0x0170: 632c 3364 6573 2d63 6263 2c62 6c6f 7766 c,3des-cbc,blowf
0x0180: 6973 682d 6362 632c 6361 7374 3132 382d ish-cbc,cast128-
0x0190: 6362 632c 6165 7331 3932 2d63 6263 2c61 cbc,aes192-cbc,a
0x01a0: 6573 3235 362d 6362 632c 6172 6366 6f75 es256-cbc,arcfou
0x01b0: 722c 7269 6a6e 6461 656c 2d63 6263 406c r,rijndael-cbc@l
0x01c0: 7973 6174 6f72 2e6c 6975 2e73 6500 0000 ysator.liu.se...
0x01d0: 9d61 6573 3132 382d 6374 722c 6165 7331 .aes128-ctr,aes1
0x01e0: 3932 2d63 7472 2c61 6573 3235 362d 6374 92-ctr,aes256-ct
0x01f0: 722c 6172 6366 6f75 7232 3536 2c61 7263 r,arcfour256,arc
0x0200: 666f 7572 3132 382c 6165 7331 3238 2d63 four128,aes128-c
0x0210: 6263 2c33 6465 732d 6362 632c 626c 6f77 bc,3des-cbc,blow
0x0220: 6669 7368 2d63 6263 2c63 6173 7431 3238 fish-cbc,cast128
0x0230: 2d63 6263 2c61 6573 3139 322d 6362 632c -cbc,aes192-cbc,
0x0240: 6165 7332 3536 2d63 6263 2c61 7263 666f aes256-cbc,arcfo
0x0250: 7572 2c72 696a 6e64 6165 6c2d 6362 7340 ur,rijndael-cbs@
0x0260: 6c79 7361 746f 722e 6c69 752e 7365 1000 lysator.liu.se..
0x0270: 00a7 686d 6163 2d6d 6435 2c68 6d61 732d ..hmac-md5,hmas-
0x0280: 7368 6131 2c75 6d61 632d 3634 406f 7065 sha1,umac-64@ope
0x0290: 6e73 7368 2e63 6f6d 2c68 6d61 632d 7368 nSSH.com,hmac-sh
0x02a0: 6132 2d32 3536 2c68 6d61 632d 7368 7132 a2-256,hmac-shq2
0x02b0: 2d32 3536 2d39 362c 686d 6163 2d73 7861 -256-96,hmac-sxa
0x02c0: 322d 3531 322c 686d 6163 2d73 6861 322d 2-512,hmac-sha2-
0x02d0: 3531 322d 3936 2c68 6d61 632d 7269 7065 512-96,hmac-ripe
0x02e0: 6d64 3136 302c 686d 6163 2d72 6970 756d md160,hmac-ripum
0x02f0: 6431 3630 406f 7065 6e73 7368 2e63 7f6d d160@openSSH.c.m
0x0300: 2c68 6d61 632d 7368 6131 2d39 362c 786d ,hmac-sha1-96,xm
0x0310: 6163 2d6d 6435 2d39 3600 0000 a768 7d61 ac-md5-96....h}a
0x0320: 632d 6d64 352c 686d 6163 2d73 6861 312c c-md5,hmac-sha1,
0x0330: 756d 6163 2d36 3440 6f70 656e 7373 782e umac-64@openssx.
0x0340: 636f 6d2c 686d 6163 2d73 6861 322d 3235 com,hmac-sha2-25
0x0350: 362c 686d 6163 2d73 6861 322d 3235 362d 6,hmac-sha2-256-
0x0360: 3936 2c68 6d61 632d 7368 6132 2d35 3132 96,hmac-sha2-512
0x0370: 2c68 6d61 632d 7368 6132 2d35 3132 3d39 ,hmac-sha2-512=9
0x0380: 362c 686d 6163 2d72 6970 656d 6431 3630 6,hmac-ripemd160
0x0390: 2c68 6d61 632d 7269 7065 6d64 3136 3040 ,hmac-ripemd160@
0x03a0: 6f70 656e 7373 682e 636f 6d2c 686d 7163 openSSH.com,hmqc
0x03b0: 2d73 6861 312d 3936 2c68 6d61 632d 7d64 -sha1-96,hmac-}d
0x03c0: 352d 3936 0000 0015 6e6f 6e65 2c7a 7c69 5-96....none,z|i
0x03d0: 6240 6f70 656e 7373 682e 636f 6d00 0000 b@openSSH.com...
0x03e0: 156e 6f6e 652c 7a6c 6962 406f 7065 6e73 .none,zlib@opens
0x03f0: 7368 2e63 6f6d 0000 0000 0000 0000 0000 sh.com..........
0x0400: 0000 0000 0000 0000 0000 0000 ............
Have you noticed anything? If not, that's okay. You can copy into two windows in a text editor and quickly switch between them to see the symbol changes.
Well well. This is not packet loss, but packet corruption! Very little, very predictable damage. Interesting observations:
- The initial part of the packet (<576 bytes) is intact.
- Every 15th byte out of 16 is damaged.
- The damage is predictable. All
hbecamex, allcbecames.
You may already have consulted the ASCII table and concluded that one bit is stuck on the value
1. Turning into the 1fourth bit in a byte spoils the previous letters on the left to the values on the right.
The obvious culprits in our field of vision (NICs accepting servers) are beyond suspicion because the failure has a pattern (multiple London machines → multiple Montreal data centers and machines). The reason must be on the route and closer to London.
The situation began to make sense. I also noticed a little hint in verbose tcpdump mode (
tcp cksum bad), which I had not noticed before. The Montreal server dropped a kernel-level packet when it realized it was corrupted and did not forward the packet to the SSH daemon in user space. Then London sent the packet again, it was damaged again, and Montreal silently discarded it. From the point of view of SSH and SSHd, the connection is stuck. From the point of view of tcpdump, there was no loss and the Montreal servers simply ignore the data.
We reported our findings to the London Data Center Operations Department, and in a few minutes they changed their outbound routes dramatically. The first hop and most of the subsequent ones were different. The freeze problem is gone.
Fixes late Friday night are nice, because on weekends you can relax and not think about problems and support :)
Where is Wally?
Happy that we were no longer suffering from this problem and that our systems were catching up, I decided to find the device responsible for this packet corruption.
Updating the London routes to keep traffic off the old route meant I couldn't easily reproduce the problem. I found a friend in Montreal with a suitable FreeBSD machine that was available from London via old routes.
I wanted to make sure the damage was predictable even without SSH involved. I managed this easily with a few pipelines.
In Montreal:
nc -l -p 4000 > /dev/null
Then in London:
cat /dev/zero | nc mtl 4000
Given the factor of randomness and tweaking in the retry cycle, I received several packages that dispelled any doubts about the previous conclusions. Here's part of one of the packages:
We just sent a packet of zeros
0x0210 .....
0x0220 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0230 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0240 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0250 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0260 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0270 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0280 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0290 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02a0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02b0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02c0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02d0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02e0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x02f0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0300 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0310 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0320 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0330 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0340 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0350 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0360 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0370 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0380 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x0390 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03a0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03b0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03c0 0000 0000 0000 0000 0000 0000 0000 1000 ................
0x03d0 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x03e0 .....
Reproducing the bug, I needed to find the one of the 17 hops on which the damage occurred. I couldn't just call the providers of all the clusters and ask them to check their systems.
I decided to ping each router sequentially, it might help. Wrote special ICMP packets large enough to exceed the 576 byte safe limit and filled them with zeros. Then using these packets I pinged the Montreal server from London.
Packages returned intact.
I've tried every combination of speed, content, size - to no avail. I did not find any damage in the returned ICMP ping packets.
In netcat pipelines, I've replaced TCP with UDP. No damage again.
It needed TCP to reproduce the damage, and TCP needed two communicating endpoints. I tried in vain to find out if all routers have an open TCP port that I can communicate with directly.
It seemed impossible to identify the faulty hop from the outside. Or is it possible?
Mirror mirror on the wall
To determine if damage occurs, one of the following scenarios had to be used:
- Check the packet at the destination via the TCP node with which it is communicating.
- Not in user space, where the packet will not be delivered in case of an error during checksum verification, but check the received packet for damage using root and tcpdump.
- Using a TCP node that acts as an echo server and mirrors the received data back, check the packet on the sending node.
It suddenly turned out that a second measuring point is available to us. Not directly available, but still: in the very first approach to solving the problem, we noticed that SSH clients hang when communicating with SSH servers through a damaging hop. This is a good passive signal that can be used in place of the active "echo" signal.
And in this we can be helped by numerous open SSH servers on the Internet.
We do not need current accounts on these servers, we just need to start an SSH connection, see if the cipher exchange phase will be successful (with a reasonable number of retries to take into account the accidental damage).
The plan was this:
- Use the wonderful nmap tool in "random IP" mode to compile a list of geographically distributed open SSH servers.
- :
- , → .
- N- → «».
- telltale N- → «».
- «» «».
I thought like this: in the traces of all "bad" servers, several of the same hops will be used. We will be able to isolate suspicious hops and identify those that are used in the traces of "good" servers. In the hope that one or two will remain.
After spending an hour manually classifying the servers, I stopped exploring the data. I had 16 "bad" and 25 "good" servers.
The first step was to make a list of the hops that are found in all traces of the bad servers. After cleaning the list, I realized that I don't even need to go to the list of "good" ones to remove false positive hops. The bad guys only had one common hop.
However, there were two providers before it: London → N hops upstream1 → Y hops upstream2.
This was the first of the Y hops in upstream2, right on the border between upstream1 and upstream2. It damaged random TCP packets, which led to numerous retransmissions and, depending on the specifics of the protocol data exchange, freezes or reduced transmission volumes.
Together with the London data center operations department, we tracked the IP address of this hop. I was hoping that through their direct connection to upstream1 it would be possible to force corrections.
Through upstream1, I received confirmation that the hop I specified (the first one in upstream2) had an internal "control module failure" that was affecting BGP and routing between the two internal networks. They rerouted the faulty device and turned it off pending replacement.
Rock music filter
I helped a user of a streaming audio application set up a LAN experience. The user played only classical music, not rock music. Seriously. Classics streamed seamlessly, and when trying to stream rock music, the connection dropped after a few minutes.
The app received chunks of audio, compressed them using a lossless compression codec, and then sent each chunk in a separate UDP packet to the endpoint. Whenever possible, the application tried to use IPv6, because it was more reliable than the LAN environment, although it could work over IPv4 if necessary.
After an endless and tedious search for the cause of the problem, I finally figured out what was the matter. Somehow the user has set the MTU to 1200 bytes on the network interface. And IPv6 will not automatically fragment packets at the IP level when the MTU is below 1280 bytes, so larger packets simply cannot be sent. The streaming application will try to send audio packets larger than 1200 bytes, receive an error, and disconnect.
Why did this only happen with rock music? It's simple. Lossless codecs use a variable bitrate, and classical music is compressed better than rock music. When streaming classics, audio was consistently compressed into packets of less than 1200 bytes, and packets of rock music randomly exceeded this threshold.
The user didn't know why his MTU was reduced, he didn't need it, so we increased the value and everything worked fine.
Self-Disappearing Internet Disruption
When I entered university in 1999, I lived in an old and dilapidated student dormitory because I couldn't afford anything better. But at least there was a pretty decent internet in the hostel, which was not yet widespread in my country. And since it was forbidden to change the building, network cables (still coaxial) were divorced according to a temporary scheme. They were hidden behind false ceilings in corridors and pulled through doorways into rooms where they simply lay on the floor. Any break in communication could lead to the fact that a whole floor was left without a network. Since I studied at the Faculty of Computer Science, I quickly and involuntarily turned into a person on my floor who fixes fairly frequent interruptions, although I had no experience with networking at all.
Sometimes the interruption was on the side of the provider, sometimes the problem was related to our proxy, but more often than not someone simply disconnected some cable and did not insert a terminator into it.
One evening the internet went down, but only for a few minutes. Then he reappeared, so I didn't think much of it. But the next day the short interruption was repeated, and on the third day too. Usually it happened about 20 hours, the exact time floated, and sometimes it was not at all. But every time the network went down, my on-site phone started ringing, and people were increasingly annoyed by these repeated interruptions.
Since each interruption lasted only a few minutes, I could not pinpoint a specific location before the network reappeared. I tried to run across the floor and knock on all the doors, asking if someone had pulled out a cable or done something with it, but the idea did not help. Finally I decided to wait for the daily interruption with my trusty multimeter in hand. Within a week, I expelled one room after another from suspects. Finally, in one of the room cables, I noticed a surge in resistance during the next interruption.
I knocked, but they didn’t open it. The castle was locked. But if there is no one in the room to do something with the computer or the cable, then why is the connection interrupted? And why is it recovering? The next day everything happened again, they didn’t open the door again. I decided to completely turn off this room so that the Internet would work on the rest of the floor.
The next morning, the tenants of that room informed me that their internet was not working. I went to them and measured the resistance in all cables, checked all connections and terminators. All cables have zero ohms, everything is in perfect order. I asked the guy what was he doing last night? I read textbooks before exams, nothing related to the computer, he answered. I rechecked everything a second and third time, but found no problems. I almost gave up, and then I noticed: the cable was fastened under the bed. Of course, the copper core of the cable was broken exactly in this place, but it was held tightly by the sheath that, under normal conditions, contact was maintained even if you sit on the bed. But when I started swinging it, the contact disappeared for a few seconds with each push.
You yourself can guess what happened on that bed for several minutes every evening, behind a locked door and without an answer to a knock.
Mel's story
Real programmers write in Fortran
This may be the case now, in the decadent era of non-alcoholic beer, calculators and "user-friendly" applications, but in the Good Old Times, when the term "software" sounded funny and Real Computers were made of magnetic drums and radio tubes, Real Programmers wrote in machine code. Not at FORTRAN. Not on RATFOR. Not even assembly language. In machine code. On real, unadorned, incomprehensible hexadecimal numbers. Just like that. Several generations of programmers have grown up without knowing about this glorious past, and I believe that I should try to bridge the generation gap and talk about how a Real Programmer wrote code. I will call him Mel because that was his name.
I met Mel when I got a job at Royal McBee Computer Corp., a now defunct subsidiary of a typewriter manufacturer. The firm was making the LGP-30 - a small and cheap (by today's standards) drum computer - and had just started making the RPC-4000, also on drum memory, much improved, larger and faster. Magnetic cores were too expensive, and they couldn't withstand the competition (which is why you haven't heard of this company or its computers). I was hired to write a FORTRAN compiler for this new miracle, and Mel was my guide to its capabilities. Mel disapproved of compilers. “What good is it that a program can't rewrite its own code?” He asked. Mel wrote the company's most popular program in hex.She worked for the LGP-30 and played blackjack with potential buyers at computer shows. It has always had a dramatic effect. An LGP-30 booth was displayed at every trade show, and IBM vendors gathered around and talked to each other. Did it help sell computers? We have never discussed this issue.
Mel's job was to rewrite the blackjack program for RPC-4000. (Porting? What is it?) The new computer had a one-plus-one addressing scheme: in addition to the opcode and the address of the required operand, each machine instruction also had a second address, which showed where the next instruction was written on a rotating magnetic drum ... That is, after each instruction went
GO TO! Stuff this into a Pascal pipe and smoke it.
Mel loved the RPC-4000 because he could optimize his code: place instructions on the reel so that as soon as one completes, the second is immediately under the "read head" and is ready for immediate execution. To do this, a program was written that optimizes assembler, but Mel refused to use it. "You never know where it will put the data," he explained, "so you have to use separate constants." I understood the essence of this phrase much later. Since Mel knew the numerical values of all operating codes and assigned his own addresses in the drum memory, each instruction he wrote could be considered a numerical constant. For example, he could select an earlier “add” instruction and multiply by it if it had a suitable numeric value. Very few people could change its code.I compared Mel's manually optimized programs with the same code that had been processed by the optimizing assembler, and Mel's code always ran faster. The fact is that the top-down method of building architecture has not yet been invented, and Mal would not have used it anyway. First, he wrote the inner parts of his programming loops so that they were the first to get the optimal addresses on the reel. And the optimizing assembler was not capable of that. Mel never wrote time-delayed loops, even when the hulking Flexowriter required a delay between character outputs. Mel simply placed the instructions on the reel so that when the next instruction had to be read, it would go throughthat the top-down architecture method hasn't been invented yet, and Mel wouldn't have used it anyway. First, he wrote the inner parts of his programming loops so that they were the first to get the optimal addresses on the reel. And the optimizing assembler was not capable of that. Mel never wrote time-delayed loops, even when the hulking Flexowriter required a delay between character outputs. Mel simply placed the instructions on the reel so that when the next instruction was to be read, it would go throughthat the top-down architecture method has not yet been invented, and Mal would not have used it anyway. First, he wrote the inner parts of his programming loops so that they were the first to get the optimal addresses on the reel. And the optimizing assembler was not capable of that. Mel never wrote time-delayed loops, even when the hulking Flexowriter required a delay between character outputs. Mel simply placed the instructions on the reel so that when the next instruction had to be read, it would go througheven when the hulking Flexowriter required a delay between character outputs. Mel simply placed the instructions on the reel so that when the next instruction had to be read, it would go througheven when the hulking Flexowriter required a delay between character outputs. Mel simply placed the instructions on the reel so that when the next instruction had to be read, it would go throughpast the read head, and the drum would have to make another revolution to find it. Mel found an inimitable term for this procedure. The word "optimum" (optimum) has an absolute meaning, as well as "unique", so in colloquial speech they were often made relative: "not quite optimal" or "less optimal" or "not very optimal". Mel called the places on the drum with the longest lag time "the most pessimum" ( pessimum - the worst environmental conditions tolerated by the body ).
After finishing work on the blackjack program and running it (“Even the initializer is optimized,” he said proudly), Mel received a request from the sales department to make changes. An elegant (optimized) random number generator was responsible for shuffling cards and dealing from the deck in the program. And some of the salespeople thought it was too honest, because sometimes the buyers lost. They asked Mel to change the program so that the touch switch on the console could change the player's odds and let the buyer win. Mel refused. He considered it dishonest - it was so - and that it encroached on his programmer morality - it was so - so he refused to participate. Mel was persuaded by the head of the sales department, and Big Boss, and fellow programmers at the insistence of the Boss. Finally Mel gave up and wrote the codebut did the cheat check the other way around: when the switch was turned on, the program cheated and always won. Mel was delighted with his decision. He claimed that his subconscious mind showed uncontrollable ethics and flatly refused to correct the program. When Mel left the company for a higher salary, Big Boss asked me to look at the code and tell me if I could find a validator and change how it worked. I agreed reluctantly.can I find the verification module and change the way it works. I agreed reluctantly.can I find the verification module and change the way it works. I agreed reluctantly.
Dealing with Mel's code was a real adventure. It often seemed to me that programming is an art form whose real value can only be appreciated by those who understand this mysterious art. It contains real jewels and brilliant moves, hidden from human sight and admiration by the very nature of the process, sometimes forever. You can learn a lot about a person just by reading their code, even hexadecimal. I think Mel was an unrecognized genius. Perhaps the most powerful shock was the innocent cycle I found, in which there was no fraudulent verification. No verification. No .
Common sense dictated that this should be a closed loop, inside which the program circulates, forever, endlessly. However, software control successfully passed through it and exited safely on the other side. It took me two weeks to figure this out. The RPC-4000 was equipped with a modern device - an index register. It allowed writing program loops, inside which indexed instructions were used. Each time it went through the loop, a number from the register was added to the instruction address so that it refers to the next position in the series. All that remained was to increment the index register with each pass. Mel did not take advantage of this. Instead, he pulled the instruction into the machine register, added one to its address, and saved it back. And then it executed the modified instruction directly from the register.The cycle was written taking into account the extra execution time: as soon as the instruction was completed, the next one appeared under the readhead of the drum. But there was no rogue check in the loop. The saving clue was that a bit in the index register was turned on - it was located in the command code between the address and the operating code. However, Mel did not use the index register, leaving it at zero.
When my epiphany came, I almost went blind. The data he was working on near the high levels of memory — the largest addresses that instructions could reference — Mel arranged so that after the last position was processed, incrementing the instruction address would cause an overflow. During the transfer, one was added to the operating code, changing it to the following code in the set: the jump instruction. Of course, this next instruction was located at address zero, and the program happily went there. I haven't spoken to Mel and I don't know if he gave up in the face of the flood of change that has flooded programming ever since. I prefer to think I didn't give up. I was so impressed that I stopped looking for a cheat check and told Big Boss I couldn't find it. He was not surprised. When I left the companythe blackjack program was still cheating if the right switch was turned on, and rightly so, I think. I didn't like hacking the code of a Real Programmer.
Exceptionally USB issue
Right out of college, I joined a company and worked on a consumer device for five months before it was shown to the public. The device was running Linux. And while I was getting used to the idea of pampering in kernel space, I was yanked to a meeting to prioritize bugs. Numerous bugs. Hundreds of bugs. Each of them reads: "This is impossible, how did this happen?"
They shouted: "Memory damage!" I thought, "Hospadi, fix your bugs." Looking at the crash dumps, we saw ... what is it? The program executed the forbidden instruction by concatenating the two strings using a function from the standard library. Hmm, weird ... Next log: Can't fetch a page from a paging file on a device that has no paging file space allocated at all (I think I understand why we couldn't fetch the page!).
I once wrote a short program. It allocated 80% of the system memory to a single array and wrote sequential integers to it. Then I waited for Enter to be pressed and checked to see if the contents of the array had changed. Now I downloaded this program, waited 30 seconds and then ran the check. No problem. I tried a few more times - ha, I knew there was no memory damage! I pulled out the debug cable (USB), after 10 seconds I quickly inserted and pulled out, then reinserted. Bam! 90 errors.
Yours.
Okay, I'll have to tinker with the USB port. So the problem is related to him? The USB driver does not seem to implement a magic bit fairy algorithm that randomly throws bit errors around. Probably a problem with the hardware? No, not with him, but that did not stop us from doing all sorts of lewdness with the USB port. They called in engineers who had switched to another product a long time ago, and now they were puzzling over the problem. I don't remember how much time we spent proving to ourselves that the hardware was in complete, complete, oooooo order. The grounding was in order, the voltage was stable, the clock was running accurately, and the DDR lines were so perfect that you would have cried with happiness when you saw it.
Devices that were tested by engineers became more and more unstable. I assumed that the machine could load data into memory, get bit errors, and then dump it back into flash memory, perhaps even in the wrong place (the page table was often damaged, so it could be assumed that this also happens with file tracking structures Content could be written to the wrong places, and file system structures could break, etc.) Over time, devices degraded so much that they could no longer boot reliably. Finally, one of the engineers broke down and overwritten the image that was on his laptop. This image was relatively ancient.
- Dude. It's about the software.
- What?!?!?! I assure you, we didn't write bit fairy!
No: he uploaded an assembly three months ago and the problem went away. At that moment, I felt responsible for having involved a bunch of people in a very long and meaningless venture, so I stayed overnight and did a binary search through all the patches over the past months (it took more time to study full assemblies of the whole OS than I would like ...).
So what was that magic patch? Someone added a driver for the chip we analyzed to the kernel. This chip was not in the device.
Ha! We found a witch! BURN IT!
Many announced that the problem was solved. They were happy that in the next release they could roll back the patch and move on. We rolled it back with extreme pickiness, put together an image, tested it, everything was fine. We didn't expect the same defect to appear in the nucleus in a few days.
Wait. If the chip was not on the board, how did the driver prevent us? I ran lsmod, the driver was not loaded ... “Anyway, what's the difference, delete the module file and reload. Nifiga, the problem remains. This not normal..."
Now I was alone and watched the devilry going on. I started to analyze the patch carefully. It was a nice 10K line C file provided by the chip manufacturer. It would be too condescending to describe it with the word "chaos" (in fairness, after a few weeks they sent us a much more thoughtful driver). After digging around a bit, I decided that the driver did not implement bit-juggling-for-fun. So what's the deal? 48 bytes from five lines of code. A small structure in the boot file that says which bus address to look for the chip. I removed most of the driver, but left a different structure in it. The problem persisted.
So boys and girls, we have an alignment problem! Somehow this 48-byte structure is moving something in memory and that leads to errors. I found out that the problem occurs when you put anything larger than 32 and less than 64 bytes in a file. This knowledge did not help much, but at least it created a sense of progress.
The kernel compilation produced a neat System.map file. It listed where in the kernel's virtual address space all the variables compiled into the kernel are. I found out that my little structure is in the middle of the ".data" section. This section is filled with initialized variables, so that when the kernel binary was unpacked into memory, it would write all those variables from the compiled image. Using System.map as a reference, I've implemented a rather goofy binary search. For the most part I searched the linkers of different C files. I found a variable to compare with; found the kernel file that contains it; put my magic structure next to me in a random file and started to see if the problem reappeared.
The search proceeded to the last few .data elements and came back empty-handed. There was no required data in memory with initialized variables. As I scrolled through the System.map file, I saw that I had not paid attention to the whole .bss section, which contained uninitialized variables. Learned from past mistakes, I first checked the beginning and the end. Of course, an uninitialized variable at the beginning of a section resulted in errors, while a variable at the end of a section did not. Finding the culprit was only a matter of time. The variable whose movement caused the problem was ...
Function pointer ?!
How the heck does function pointer alignment crash our system? In the ARM architecture, you cannot read words when accessing without alignment, that is, each 32-bit variable must be put into memory at an address multiple of 4. A function pointer is no exception, it always gets the minimum address. It turns out that in our problem situation, the address was a multiple of 2 n , greater than or equal to 64. Any value less than this threshold - and the problem disappeared. There was also order with pointer alignment.
There is no good alignment. At least not before this bug occurred.
Now this function pointer was not the "old-fashioned" pointer. He was referring to something special. There was an area in the CPU SRAM that we could use for load related tasks if we couldn't use RAM. To save energy while idle, we copied a subroutine into this area, set a special pointer that referred to it, and then called it. What was the subroutine doing? Let's take a look at the assembler. I am not an ARM assembler expert, but the comments were quite eloquent.
// ...
...
// LPDDR
What are you doing?! You quickly moved from basic register operations to disabling the memory controller. I sent an email to the manufacturer who wrote the subroutine and asked if they were missing something.
Three days later, I received an answer in the style of "Oh yes, there must be a memory barrier." It turns out that, due to the structure of their L2 cache, they would have to additionally support TLB if we accidentally wrote a multiple of 64 to the memory address. In such cases, we can still use the RAM when the controller is off.
Considering that the variable alignment requires a minimum multiplicity of 4, and that the last record cannot have a multiplicity of 64 or more, at each compilation one sixteenth of the data was completely unusable by the system.
In the end, we shipped a reliable product with a memory barrier, and the customers loved it. Yes, and in case you're wondering, I couldn't notice it with the USB cable because we couldn't enter low power mode due to USB usage. This is purely a USB problem.
Invalid error message
In the final hours of September 17, 1996, the day before the planned launch of the WebTV service, our group gathered at the operations center in Palo Alto. A crowd of network sysadmins and service software developers hung out nearby to witness the official launch.
When the appointed hour struck, one of the networkers began to register on his WebTV device. We understood that good nicknames would end quickly, so it was important to register before users start doing it. Plus, it was nice to be among the first to register for the first "real" service. Before that, all accounts were "one-time" test accounts.
Several people crowded around, watching him type on the keyboard, feeling dizzy with anticipation and lack of sleep. Bryce entered his name, address, and other information, and then began typing a nickname. That was his name for an email address. He typed "jazz", which means his mail should have been "jazz@webtv.net". When he pressed Enter on the wireless keyboard, we heard a distinctive sound indicating the appearance of an error message. Everyone looked at the screen.
To understand what happened next, it is important to know a thing or two about the service. WebTV was positioned as a family TV, so it was necessary to check for foul language and filter out usernames and other information visible to users. It is impossible to catch everything, but it is not difficult to filter out the obvious things.
The custom names were compared against a list of regular expressions, which allowed them to be matched against a pattern. For example, "fu. * Bar" will compare against all names starting with "fu" and ending with "bar". If you choose your patterns carefully, you can catch and reject egregious variations like "shitake" and "matsushita", which have built-in curses.
The same mechanism was used to prevent users from choosing "forbidden" names like "postmaster", "root", "admin" and "help". We had a text file like this:
admin.*
"admin".
postmaster
postmaster.
poop
.
weenie
.
Each entry consisted of two lines. The first was the regular expression to be compared against, and the second line was the error message that was shown to the user. The system read the file two lines at a time, and when the user entered the name, it was compared against all regular expressions. An error message was displayed for the first match found. If there was no match, the custom name was accepted.
The code that read the file knew how to skip comments. But he didn’t know how to handle empty lines.
Someone made changes to the swearing file, along the way adding one blank line after the "reserved" names and before the swear words. When the code reads the list, it took the empty string as a regular expression, and the word following it as an error message. An empty string expression matches anything.
Midnight. We're all a little on edge. Bryce writes the name, and the system responds with a simple message:
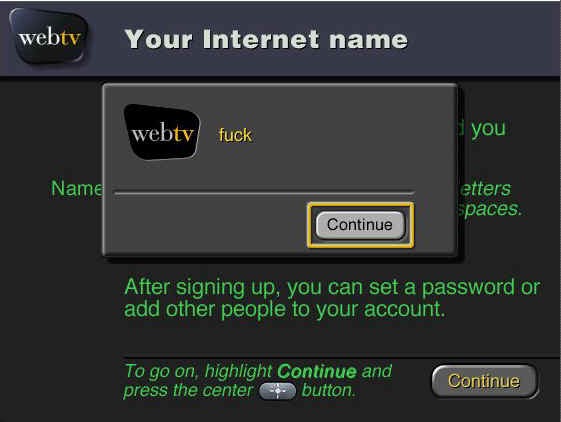
We started laughing hysterically. Others came up to us to find out what was going on. We showed it to the screen. They started laughing hysterically.
At that time, in another building, Mark Armstrong (in charge of QA), along with Bruce Leek (one of the founders of the company), sat in front of a counter of sixteen WebTV consoles. This rack, nicknamed "racksville", was connected via a video multiplexer to a large TV displaying images from all 16 boxes simultaneously. Mark and Bruce started registering the set-top boxes using a keyboard with an infrared transmitter. We called them on the intercom:
- How is it going?
- All perfectly.
- Oh good. You may have noticed a few things when registering.
- Yes? We did not notice anything strange.
- Notice.
- Okay. Entering the postal code ... so far everything is fine. OGO !!!
A friendly message appeared on images from all 16 consoles. The bosses suggested that we might need to fix this glitch as soon as possible. This seemed like a great idea to us.
We fixed the file and taught the code to recognize and ignore empty lines. As far as I know, WebTV hasn't said "f - k" to any customer.
Xbox crash problem
At the time, the team was working on one of the first games for an all-new console called the Xbox. When the final testing was accelerated, QA launched three set-top boxes from the installation batch to run automated tests at night. If yesterday's build of the game was still being tested in the morning, this indicated its stability.
Unfortunately, one of the consoles crashed in the morning. Crashes are always bad, but it was an extremely bad case: something executed by the video card crashed the entire system. Diagnosing graphics card problems is hard: no debuggers, no stack traces, no debugging with
printf. You can only read the code and experiment.
Thus began the Bug Hunt. Every day, the lead engineers reviewed the available evidence, hypothesized and ruled out possibilities. Every night, QA got a "random" drop for no reason. "This is impossible", "How does this happen?", "Maybe this is a bug in the compiler?" - all the most popular hits.
On the engineers' car, the game worked perfectly for many days. But this was little consolation, because the deadline for sending the game to print and shipping to stores was approaching.
Fortunately, we soon found a pattern, albeit a rather strange one. The game crashed only at night and only on one of the three consoles. We started looking for differences between them. It wasn't about the power cable. Not in controllers. DVD burned out of order. Transferring the console to your table - it does not fall. Put it back - it falls. It was about a specific stand that QA used.
Now the process of excluding factors required excluding all variables. In the end, in despair, the engineer tried to swap the attachments on the table.
It turned out that it was not a specific prefix that was malfunctioning. Any prefix on this table fell. In the middle of the night. Sometimes for the sake of science you have to act strange, and this was one of those cases. The engineer sat down stoically in a chair, overlaid with cans of Red Bull, and Bug Hunt turned into Bug Watching. The engineer vowed that he would watch automated tests run on the consoles on this damn table until he saw the failure with his own eyes.
The night passed slowly, then quickly, and finally dawn came. The game continued to run. It was inspiring. The sun began to rise.
And then something interesting finally happened: a ray of the rising sun fell on the table. Minute after minute, the beam crept across the table to the attachments, its warm glow quietly enveloped the black dome of the attachment.
Which fell quickly.
The first Xbox had a problem: the video card could malfunction if the temperature of the console reached a certain value. The software had nothing to do with it. A hardware issue was reported, the game was released, and Red Bull was replaced with beer. Okay, let's be honest, for whiskey. One: zero for science.