
Continuation of the collection of stories from the Internet about how bugs sometimes have completely incredible manifestations. The first part is here .
More magic
A few years ago, I rummaged through the closets that housed the PDP-10 computer that belonged to the MIT AI lab. I noticed a small switch glued to the frame of one of the cabinets. It was clear that it was a homemade product, added by one of the laboratory craftsmen (no one knew who exactly).
You won't touch an unknown switch on your computer without knowing what it does, because you could break your computer. The switch was signed completely unintelligibly. It had two positions, and the words "magic" and "more magic" were scribbled on the metal body in pencil. The switch was in the more magic position. I called one of the technicians to take a look. He had never seen such a thing before. Upon closer examination, it turned out that only one wire goes to the switch! The other end of the wire disappeared into the jumble of cables inside the computer, but the nature of electricity dictates that a switch won't do anything until you plug two wires into it.
It was obvious that this was someone's stupid joke. After making sure the switch doesn't do anything, we toggle it. The computer immediately passed out.
Imagine our amazement. We chalked it up to a coincidence, but still put the button back in the "more magic" position before starting the computer.
A year later, I told this story to another technician, David Moon, as far as I can remember. He questioned my adequacy, or suspected of believing in the supernatural nature of that switch, or thought I was fooling around with his phony story. To prove my point, I showed him this switch, still glued to the frame and with a single wire, still in the "more magic" position. We examined the switch and wire closely and found that it was grounded. It looked doubly meaningless: the switch was not only electrically inoperative, but also plugged into a place that didn't affect anything. We moved it to a different position.
The computer went blank immediately.
We reached out to Richard Greenblatt, who was a longtime technician at MIT, who was nearby. He, too, had never seen the switch. I examined it, came to the conclusion that the switch was useless, took out the wire cutters and cut the wire. Then we turned on the computer and it began to work quietly.
We still don't know how this switch shut down the computer. There is a hypothesis that a small short circuit occurred near the ground contact, and the translation of the switch positions changed the electrical capacitance so that the circuit was interrupted when pulses with a duration of a millionth of a second passed through it. But we won't know for sure. We can only say that the switch was magic.
It is still in my basement. This is probably silly, but I usually keep it in the "more magic" position.
In 1994, another explanation for this story was proposed. Note that the body of the switch was metal. Suppose that a contact without a second wire was connected to the body (usually the body is grounded, but there are exceptions). The switch body was connected to the computer case, which was probably grounded. Then the ground circuit inside the machine may have a different potential than the frame ground circuit, and changing the position of the switch led to a drop or surge in voltage, and the machine was rebooted. This effect was probably discovered by someone who knew about the potential difference and decided to make such a joke switch.
OpenOffice doesn't print on Tuesdays
Today on the blog I came across a mention of an interesting bug. Some people were having trouble printing documents. Later, someone noted that his wife complained about not being able to print on Tuesdays!
In the bug reports, some initially complained that it must be an OpenOffice bug, because from all other applications it printed without problems. Others have noted that the problem comes and goes. One user found a solution: uninstall OpenOffice and wipe the system, then reinstall (any simple task on Ubuntu). The user reported on Tuesday that his printing problem had been resolved.
Two weeks later, he wrote (on Tuesday) that his solution didn’t work. About four months later, the Ubuntu hacker's wife complained that OpenOffice didn't print on Tuesdays. Imagine this situation:
Wife: Steve, the printer is closed on Tuesdays.
Steve: It's a day off at the printer, of course it doesn't print on Tuesdays.
Wife: I'm serious! I cannot print from OpenOffice on Tuesdays.
Steve: (incredulous) Okay, show me.
Wife: I can't show you.
Steve: (rolling his eyes) Why?
Wife: Today is Wednesday!
Steve: (nods, speaks slowly) Right.
The problem was traced back to a program called
file. This * NIX utility uses templates to detect file types. For example, if the file starts with%!and then it goes PS-Adobe-, then it's PostScript. Looks like OpenOffice is writing data to such a file. On Tuesday he takes his uniform %%CreationDate: (Tue MMM D hh:mm:...). An error in the template for Erlang JAM files meant that Tuethe PostScript file was recognized as an Erlang JAM file, and therefore, presumably, it was not being sent to print.
The template for the Erlang JAM file looks like this:
4 string Tue Jan 22 14:32:44 MET 1991 Erlang JAM file - version 4.2
And it should look like this:
4 string Tue\ Jan\ 22\ 14:32:44\ MET\ 1991 Erlang JAM file - version 4.2
Given the multitude of file types this program tries to recognize (over 1600), template errors are not surprising. But the order of comparison also leads to frequent false positives. In this case, the Erlang JAM type was mapped to the PostScript type.
Death packages
I started calling them that because they were exactly death packets.
Star2Star has partnered with a hardware manufacturer that has created the last two versions of our local client system.
About a year ago we released an update for this hardware. It all started out pretty simple, following Moore's usual law. Bigger, better, faster, cheaper. The new hardware was 64-bit, had 8 times more memory, had more drives, and had four Intel Gigabit Ethernet ports (my favorite manufacturer of Ethernet controllers). We had (and still have) many ideas on how to use these ports. In general, the piece of iron was amazing.
The novelty whizzed through performance and functionality tests. Both the speed is high and the reliability. Ideally. Then we slowly deployed the equipment to several test sites. Of course, problems began to arise.
A quick Google search suggests that the Intel 82574L Ethernet controller had at least a few issues. In particular, problems with EEPROM, bugs in ASPM, tricks with MSI-X, etc. We have been solving each of them for several months. And we thought we were done.
But no. It only got worse.
I thought I designed and deployed the perfect software image (and BIOS). However, the reality was different. The modules continued to fail. Sometimes they recovered after a reboot, sometimes they didn't. However, after the module was restored, it needed to be tested.
Wow. The situation was getting weird.
The oddities continued, and finally I decided to roll up my sleeves. I was lucky to find a very patient and helpful reseller who stayed with me on my phone for three hours while I was collecting data. At that client point, for some reason, the Ethernet controller could fall while transmitting voice traffic over the network.
I will dwell on this in more detail. When I say the Ethernet controller “could have gone down,” it means that it MIGHT have gone. The system and the Ethernet interface looked fine, and after sending a random amount of traffic, the interface could report a hardware error (loss of communication with the PHY) and lose connection. The LEDs on the switch and interface literally went out. The controller was dead.
It was possible to bring it back to life only by turning the power off and on. Attempting to reboot a kernel module or machine resulted in a PCI scan error. The interface remained dead until the machine was physically unplugged and plugged in again. In most cases, for our clients, this meant removing equipment.
While debugging with this very patient reseller, I started to stop receiving packets when the interface crashed. In the end, I identified a pattern: the last packet from the interface was always
100 Trying provisional response, and it always had a certain length. That's not all, I eventually traced this response (from Asterisk) back to the original INVITE request specific to one of the manufacturers' phones.
I called the reseller, gathered people, and showed the evidence. Although it was Friday evening, everyone took part in the work and assembled a test bench from our new equipment and phones from this manufacturer.
We sat down in a conference room and started dialing numbers as fast as our fingers could. It turned out that we can reproduce the problem! Not on every call and not on every device, but from time to time we managed to put the Ethernet controller on, and from time to time we didn't. After dropping power, we tried again, and we succeeded. In any case, as anyone who has tried to diagnose technical problems knows, the first step is to reproduce the problem. We have finally succeeded.
Believe me, it took a long time. I know how the OSI stack works. I know how software is segmented. I know that the contents of the SIP packets should not affect the Ethernet adapter. It's all nonsense.
Finally, we were able to isolate the problem of packets between their arrival at our device and on the mirroring port in the switch. It turned out that the problem was with the request
INVITE, not the response 100 Trying. There was 100 Tryingno response in the data captured on the mirrored port .
It was necessary to deal with this
INVITE. Was the problem related to the handling of this package by the userspace daemon? Maybe the transmission was the problem 100 Trying? A colleague suggested closing the SIP application and seeing if the problem persisted. Without this app, packages100 Tryingwere not transmitted.
It was necessary to somehow improve the transmission of problem packets. We isolated the packet transmitted from the phone
INVITEand played it using tcpreplay. It worked. For the first time in months, we were able to drop ports on command with a single packet. This was a significant progress, and it was time to go home, that is, to repeat the test bench in the home laboratory!
Before I continue my story, I want to tell you about a great open source application that I found. Ostinato turns you into a packet master. Its possibilities are literally endless. Without this application, I would not have been able to progress further.
Armed with this versatile package tool, I started experimenting. I was amazed at what I found.
It all started with a weird SIP / SDP quirk. Take a look at this SDP:
v=0
o=- 20047 20047 IN IP4 10.41.22.248
s=SDP data
c=IN IP4 10.41.22.248
t=0 0
m=audio 11786 RTP/AVP 18 0 18 9 9 101
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:0 PCMU/8000
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:9 G722/8000
a=rtpmap:9 G722/8000
a=fmtp:101 0-15
a=rtpmap:101 telephone-event/8000
a=ptime:20
a=sendrecv
Yes that's right. The sound transmission proposal is duplicated. This is a problem, but again, what does the Ethernet controller have to do with this ?! Well, apart from the fact that nothing else increases the size of the Ethernet frame ... But wait, there were a lot of successful Ethernet frames in the packets being transmitted. Some of them were smaller, some more. There were no problems with them. I had to dig further. After a few kung fu tricks with Ostinato and a bunch of electrical reconnections, I was able to identify the problematic relationship (with the problem frame). Note: we will be looking at hexadecimal values.
An interface crash was initiated by a specific byte value at a specific offset. In our case, it was the hexadecimal value
32c 0x47f. In ASCII, hexadecimal 32is2... Guess where it came from 2.
a=ptime:20
All of our SDPs were identical (including
ptime). All source and destination URIs were identical. The only differences were the caller's number, tags, and unique session IDs. Problem packets had such a combination of call IDs, tags and branches, which ptimeresulted in a value 2with an offset 0x47f.
Boom! With the correct IDs, tags, and branches (or any random junk) a "good package" could turn into a "killer" package as soon as the line
ptimeended at a certain address. It was very strange.
When generating packages, I experimented with different hexadecimal values. The situation turned out to be even more complicated. It turned out that the behavior of the controller entirely depended on this particular value located at the specified address in the first received packet. The picture was like this:
0x47f = 31 HEX (1 ASCII) -
0x47f = 32 HEX (2 ASCII) -
0x47f = 33 HEX (3 ASCII) -
0x47f = 34 HEX (4 ASCII) - (inoculation)
When I said "does not affect", I meant not only does not kill the interface, but also does not inoculate (more or less). And when I say that "the interface is crashing", well, remember my description? The interface is dying. Completely.
After new tests, I found that the problem persists with every version of Linux I could find, with FreeBSD, and even turning on the machine without bootable media! It was about the hardware, not the OS. Wow.
Moreover, with the help of Ostinato, I was able to create different versions of the killer packet: HTTP POST, ICMP echo request, and others. Almost everything I wanted. With a modified HTTP server that generated data in byte values (based on headers, host, etc.), it was easy to create the 200th HTTP request to contain the death packet and kill the client machines behind the firewall!
I have already explained how strange the whole situation was. But the strangest thing was with the vaccine. It turned out that if the first received packet contains any value (from tested by me), with the exception
1, 2or 3, if the interface becomes invulnerable to any packets death (containing the value 2or 3). Moreover, the codes and attributes ptimehave been multiples of 10: 10, 20, 30, 40. Depending on the combination of Call ID, Tag, Branch, IP, URI, and more (with this buggy SDP), these valid attributes ptimelined up in a perfect sequence. Incredible!
It suddenly became clear why the problem was occurring sporadically. It's amazing that I was able to figure it out. I have been working with networks for 15 years and have never seen anything like it. And I doubt I'll see you again. Hopefully ...
I contacted two engineers at Intel and sent them a demo so they could reproduce the problem. After experimenting for a couple of weeks, they figured out that the problem was with the EEPROM in the 82574L controllers. They sent me a new EEPROM and a writing tool. Unfortunately, we could not distribute it, and besides, it was necessary to unload and reload the e1000e kernel module, so the tool was not suitable for our environment. Luckily (with a little knowledge of the EEPROM circuit) I was able to write a bash script and then magically
ethtoolsaved the "fixed" values and registered them in the systems where the bug manifested itself. Now we could identify problem devices. We've contacted our vendor to apply the patch to all devices before shipping it to us. It is not known how many of these Intel Ethernet controllers have already been sold.
One more pallet
In 2005, I had an unexplained problem at work. A day after the unplanned shutdown (due to the hurricane), I started getting calls from users who were complaining about timeouts when connecting to the database. Since we had a very simple network of 32 nodes and with practically unused bandwidth, I was alarmed that the server with the database pinged normally for 15-20 minutes, and then “request timed out” responses came within about two minutes. This server was running performance monitoring and other tools and pinging from various locations. With the exception of the server, the rest of the machines could communicate with other network members all the time. I searched for a failed switch or connection but couldn't find an explanation for the random and intermittent failures.
I asked a colleague to watch the LEDs on the switch in the warehouse while I was doing the routing and reconnecting different devices. It took 45-50 minutes, a colleague told me on the radio "this one is off, that one got up." I asked if he noticed any pattern.
- Yes ... I noticed. But you’ll think I’m nuts. Every time a forklift takes a pallet out of the shipping hall, a timeout occurs after two seconds on the server.
- WHAT???
- Yeah. And the server is restored when the loader starts shipping a new order.
I ran to look at the forklift and was sure that he was marking the successful completion of the order by turning on some giant magnetron. Undoubtedly, the electromagnetic waves from the capacitor lead to a break in the space-time continuum and temporarily interrupt the operation of the server network card located in another room 50 meters away. No. The forklift simply stacked larger boxes on the pallet with smaller boxes on top, while scanning each box with a wireless barcode scanner. Aha! It is probably the scanner that is accessing the database server, causing other queries to fail. Nope. I checked and found out that the scanner had nothing to do with it. The wireless router and its UPS in the shipping hall have been configured correctly and are functioning normally. The reason was something else, because before the closure due to the hurricane, everything worked fine.
As soon as the next timeout started, I ran to the shipping hall and watched the loader fill the next pallet. As soon as he had placed four large boxes of shampoo on an empty tray, the server was down again! I did not believe in the absurdity of what was happening, and for another five minutes I removed and put boxes of shampoo, with the same result. I was about to fall on my knees and pray for the mercy of the Intranet God when I noticed that the router in the shipping hall was hanging about 30 cm below the level of the boxes on the pallet. There is a clue!
When large boxes were placed on a pallet, the wireless router lost line of sight to the outside warehouse. After ten minutes, I solved the problem. Here's what happened. During the hurricane, there was a power outage that dropped the only device not connected to the UPS - a test wireless router in my office. The default settings somehow turned it into a repeater for the only other wireless router hanging in the shipping hall. Both devices could only communicate with each other when there was no pallet between them, but even then the signal was not too strong. When the routers talked, they created a loop in my small network, and then all other packets to the database server were lost. The server had its own switch from the main router, therefore, as a network node, it was much further away.Most of the other computers were on the same 16-port switch, so I could ping between them without any problems.
In one second, I solved a problem that I had been tormenting for four hours: I turned off the power to the test router. There were no more timeouts on the server.
Like the Tron movie, only on an Apple IIgs computer
One of my favorite films as a child was Tron, which was filmed in the early 1980s. It told about a programmer who was “digitized” and was absorbed in the computer world inhabited by personalized programs. The protagonist joined a resistance group in an attempt to overthrow the oppressor Master Control Program (MCP), a rebellious program that evolved, gained a lust for power and attempted to take over the Pentagon's computer system.
In one of the most impressive scenes of the programs, the characters race on light cycles - two-wheeled cars that look like motorcycles that leave walls behind them. One of the protagonists forced the enemy pepelats to crash into the wall in the arena, making a through hole. The heroes dealt with their opponents and fled through the hole to freedom - the first step towards the overthrow of the MCP.
When I watched the movie, I had no idea that years later I would inadvertently recreate the world of Tron, rebellious programs and everything else on an Apple IIgs computer.
This is how it happened. When I started learning to program, I decided to create a light cycle game from Tron. Together with my friend Marco, I wrote a program on Apple IIgs in ORCA / Pascal and 65816 assembler. During the game, the screen was painted black with a white border. Each line represents one of the players. We displayed game scores in a row at the bottom of the screen. Graphically, it was not the most advanced program, but it was simple and fun. She looked like this:

The game supported up to four players if they sat in front of one keyboard. It was inconvenient, but it worked. We were rarely able to get enough people to use all four light cycles, so Marco added computer-controlled players who could reasonably compete.
Arms race
The game was already very funny, but we wanted to experiment. We've added rockets to give players a chance to escape an imminent accident. As Marco later described:
Humans and AI each had three rockets that could be used during the game. When the rocket hit the wall, there was an "explosion", the background of which was painted over black, thereby removing sections of the trail left by the previous light cycles.
Soon, players and computers could blast their way out of difficult situations with rockets. Although Tron purists will scoff at this, the programs in the film did not have the luxury of rockets.
The escape
As with all unusual and bizarre events, it was also unexpected.
Once, when Marco and I were playing against two computer players, we trapped one of the AI loops between its own wall and the bottom edge of the screen. Anticipating an imminent accident, he fired a rocket, as he always did before. But this time, instead of a wall, he shot at the border of the screen, which looked like the trail of one of the light cycles. The missile hit the border, left a hole the size of a light cycle, and the computer immediately exited the playing field through it. We stared in confusion at the light cycle as it passed through the score line. He easily avoided colliding with the symbols and then left the screen altogether.
And immediately after that, the system crashed.

Our minds swayed as we tried to grasp what had happened. The computer found a way to get out of the game. When the light cycle left the screen, it escaped into computer memory, just like in the movie. Our jaws dropped when we realized what had happened.
What did we do when we discovered a defect in our program that could regularly crash the entire system? We did it all over again. First we tried to get out of the bounds ourselves. Then they forced the computer to run away again. Every time we were rewarded with enchanting system crashes. Sometimes the drive light blinked as the drive grumbled endlessly. Other times, the screen filled with meaningless characters, or the speaker made a squeal or low hum. And sometimes it all happened at once, and the computer was in a state of complete disarray.
Why did this happen? To understand this, let's look at the architecture of the Apple IIgs computer.
(Un) protected memory
The Apple IIgs operating system did not have protected memory, which appeared in later operating systems when areas of memory were assigned to a program and protected from outside access. Therefore, a program under Apple IIgs could read and write anything (except for ROM). IIgs used memory-bound I / O to access devices like the floppy drive, so it was possible to activate the floppy drive by reading from a specific area of memory. This architecture allowed graphics programs to read and write directly to screen memory.
The game used one of the Apple IIgs graphics modes - Super Hi-Res: an amazing resolution of 320x200 pixels with a palette of 16 colors. To select a palette, the programmer specified 16 entries (numbered from 0 to 15 or from $ 0 to F in hexadecimal format) for 12-bit color values. For drawing on the screen, you could read and write colors directly into video memory.
Collision detection algorithm
We took advantage of this feature and implemented a crash detector by reading directly from video memory. The game calculated for each light cycle its next position based on the current direction, and read this pixel from the video memory. If the position was empty, that is, represented by a black pixel (entry in the $ 0 palette), then the game continued. But if the position was taken, the player crashed into the light cycle or the white frame of the screen (entry in the palette 15 or $ F). Example:
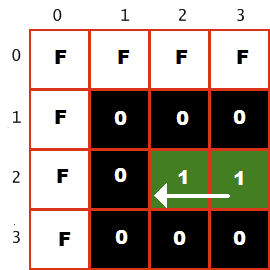
The top left corner of the screen is shown here. The color $ F denotes a white border, and the color $ 1 denotes the player's green light cycle. It moves to the left as shown by the arrow, that is, the next pixel is empty, its color is $ 0. If the player continues to move in this direction for more than one turn, he will collide with a wall (color $ F) and break.
Going beyond
The algorithm for determining the next pixel using assembler mathematics quickly computed the memory address of one pixel above, below, to the left, or to the right of the current pixel. Since any pixel on the screen was an address in memory, the algorithm simply calculated a new address to read. And when the light cycle left the screen, the algorithm determined a place in system memory to check for a collision with a wall. This meant that the light cycle was now traversing system memory, pointlessly turning on bits and "crashing" into memory.
Writing to random locations in system memory is not a wise architectural decision. Unsurprisingly, the game crashed because of this. A human player will not ride blindly and will usually crash straight away, which limits the scope of the system problems. And AI has no such weakness. The computer instantly scans the positions around it to determine if it hits a wall and changes direction. That is, in the computer's view, system memory was no different from screen memory. As Marco described:
, , . , , 0. «» , . «», - - , , — . , - , .
As a result, we not only recreated the light cycle race from the movie, but also the escape itself. As in the film, the escape had great consequences.
This is difficult to repeat today, since operating systems have acquired protected memory. But I'm still wondering if there are programs like Tron that are trying to escape their "protected spaces" in an attempt to prevent the rebel AI code from taking over the Pentagon.
I guess to find out, we need to wait for the invention of the digitalization of consciousness.
Sit down to login
Every programmer knows that debugging is hard. Although, for excellent debuggers, the job looks deceivingly simple. Distraught programmers describe a bug that they spend hours catching, the master asks a few questions, and after a few minutes the programmers see faulty code in front of them. A debugging expert does not forget that there is always a logical explanation, no matter how mysterious the system behaves at first glance.
This attitude is illustrated by a story that took place at the IBM Yorktown Heights Research Center. The programmer recently installed a new workstation. Everything was fine when he was sitting in front of the computer, but he could not log in while he was standing. This behavior was always reproduced: the programmer always logged in while sitting, but he could not even once while standing.
Many of us just sat there and wondered. How could the computer know if they were standing in front of it or sitting? However, good debuggers know there must be a reason. The first thing that comes to mind is electricity. Broken wire under carpet, or static charge? But electrical problems are rarely reproduced 100% of the time. One of the colleagues finally asked the right question: how did the programmer log in while sitting and standing? Try it yourself.
The reason was the keyboard: the two buttons were reversed. When the programmer was sitting, he would type blindly, and the problem went unnoticed. And when he stood, it confused him, he looked for buttons and pressed them. Armed with this hint and a screwdriver, the debugging expert swapped the buttons and everything worked out.
The banking system deployed in Chicago worked well for many months. But it quit unexpectedly when it was first used to process international data. Programmers poked around the code for days, but could not find a single command that led to the program termination. When they took a closer look at her behavior, they found that the program would terminate when Ecuador data was entered. Analysis showed that when the user typed the name of the capital (Quito), the program interpreted it as an exit command!
One day Bob Martin came across a system that "worked once twice." It handled the first transaction correctly, and there were minor problems in all subsequent transactions. When the system was rebooted, it again correctly processed the first transaction and failed on all subsequent ones. When Bob described this behavior as "running once twice," the developers immediately realized that they needed to look for a variable that was correctly initialized when the program was loaded, but was not reset after the first transaction. In all cases, the right questions allowed wise programmers to quickly identify unpleasant mistakes: “What did you do differently when you were standing and sitting? Show me how you log in in both cases "," What exactly did you enter before the end of the program? " “Did the program work correctly before the crashes started? How many times?"
Rick Lemons said that the best lesson he learned about debugging was when he watched the magician perform. He had done a dozen impossible tricks, and Lemons felt that he believed in it. He then reminded himself that the impossible is not possible, and he tested every trick to prove this obvious inconsistency. Lemons started with what was an unshakable truth - the laws of physics, and from them he began to search for simple explanations for each trick. This attitude makes Lemons one of the best debuggers I have met.
The best debugging book in my opinion is The Medical Detectives, written by Berton Roueche and published by Penguin in 1991. The heroes of the book debug complex systems, from a moderately sick person to very sick cities. The problem-solving methods used there can be directly used in debugging computer systems. These real stories are as fascinating as any fiction.
The 500 Mile Email Case
Here is a situation that sounded inconceivable ... I almost refused to talk about it because it is a great bike for conferences. I slightly tweaked the story to protect the culprit, to discard irrelevant and boring details, and overall to make the story more engaging.
Several years ago, I was serving an email system on campus. The head of the department of statistics called me.
- We have a problem with sending letters.
- What's the problem?
“We cannot send letters further than 500 miles.
I choked on my coffee.
- Not understood.
“We cannot send letters from the department further than 500 miles. In fact, a little further. Approximately 520 miles. But this is the limit.
“Hmm… Actually, email doesn't work that way,” I replied, trying to control the panic in my voice. You cannot show panic in a conversation with the head of a department, even one such as the department of statistics. - Why did you decide that you cannot send letters further than 500 miles?
“I haven't decided ,” he replied weightily. - You see, when we noticed what was happening a few days ago ...
- You waited a few DAYS? I cut him off in a trembling voice. - And you couldn't send letters all this time?
- We could send. Just no further…
”“ Five hundred miles, yes, ”I finished for him. - Clear. But why didn't you call earlier?
“Well, up to this point we didn't have enough data to be sure of what was happening.
Exactly, this is the head of statistics .
- Anyway, I asked one of the geostatisticians to work with this ...
- Geostatisticians ...
- Yes, and she made a map showing the radius within which we can send letters, a little over 500 miles. There are several places in this zone where our letters do not arrive at all or periodically, but outside the radius we cannot send anything at all.
“I see,” I said, and dropped my head in my hands. - When it started? You said that a few days ago, but we haven't changed anything on your systems.
- A consultant came, patched and rebooted our server. But I called him, and he said that he did not touch the mail system.
“Okay, let me take a look and call you back,” I replied, hardly believing that I was participating in such a thing. Today was not the first of April. I tried to remember if someone owed me a prank.
I logged into their department's server and sent in some verification emails. This took place in the North Carolina Research Triangle, and the letter arrived in my mailbox without any problems. So did the letters sent to Richmond, Atlanta and Washington. There was also a letter sent to Princeton (400 miles).
But then I sent a letter to Memphis (600 miles). It didn't come. In Boston, it didn't come. In Detroit, it didn't come. I took out my address book and started sending letters through it. It came to New York (420 miles), but did not come to Providence (580 miles).
I began to doubt my sanity. Wrote to a friend in North Carolina whose provider was in Seattle. Fortunately, the letter did not arrive. If the problem was related to the location of the recipients, and not their mail servers, I probably would burst into tears.
After figuring out that the problem did exist (incredibly) and reproducible, I began to analyze the sendmail.cf file. He looked fine. As usual. I compared it to sendmail.cf in my home directory. There was no difference - it was the file I wrote. And I was pretty sure I didn't include the option
FAIL_MAIL_OVER_500_MILES. In confusion, I telnetted the SMTP port. The server happily responded with a Sendmail banner from SunOS.
Wait ... the Sendmail banner from SunOS? At the time, Sun was still shipping Sendmail 5 with its operating system, although Sendmail 8 was already fully doped. Since I was a good sysadmin, I introduced Sendmail 8 as the standard. Also, since I was a good sysadmin, I wrote sendmail.cf, which used the cool long, self-documenting options and variable names available in Sendmail 8, rather than the cryptic punctuation codes used in Sendmail 5.
Everything fell into place. and I choked on my already cooled coffee again. It looks like when the consultant "patched the server", he upgraded the SunOS version from which he rolled out an older version of Sendmail. Fortunately, the sendmail.cf file survived, but now it didn't match.
It turned out that Sendmail 5 - at least the Sun-shipped version with a number of improvements - can work with sendmail.cf for Sendmail 8, because most of the rules are the same. But new long configuration options were now not recognized and discarded. And since there were no default values for most of them in the Sendmail binary, the program did not find any suitable values in sendmail.cf and reset them to zero.
One of these zeroed values was the connection timeout to a remote SMTP server. After some experimentation, it turned out that on this particular machine, under normal load, a zero timeout leads to a disconnection in a little more than three milliseconds.
At the time, the campus network was completely switch-based. The outgoing packet was not delayed until it reached the router on the other side via POP. That is, the duration of a connection to a weakly loaded remote host in a neighboring network mostly depended on the distance covered at the speed of light, and not on random delays by routers.
Feeling a little dizzy, I entered at the command line:
$ units
1311 units, 63 prefixes
You have: 3 millilightseconds
You want: miles
* 558.84719
/ 0.0017893979
"500 miles or more."
To be continued.