This is not a systematic analysis and not a table. An individual view, also from the point of view of a geophysicist. But I am always curious to read Gartner MQ, they formulate some points perfectly. So here are the things that I paid attention to in technical, market and philosophical terms.
This is not for people who are deeply into ML, but for people who are interested in what is generally happening in the market.
The DSML market itself logically nests between BI and Cloud AI developer services.
Liked first quotes and terms:
- “A Leader may not be the best choice” - The market leader is not necessarily what you need. Very urgent! As a consequence of the lack of a functional customer, they are always looking for the “best” solution, not the “suitable” one.
- Model operationalisation is abbreviated as MOPs. And pugs are hard for everyone! - (cool pug theme makes the model work).
- Notebook environment is an important concept where code, comments, data and results are brought together. It is very clear, promising and can significantly reduce the amount of UI code.
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- "Reproducability" - the maximum preservation of all parameters of the environment, inputs and outputs, so that you can repeat the experiment once carried out. The most important term for an experimental test environment!
So:
Alteryx
The cool interface is just a toy. Scalability, of course, is a bit tight. Accordingly, the Citizen community of engineers around the same with tsatski to play. Analytics has its own all in one bottle. It reminded me of the Coscad Spectral Correlation Data Analysis suite that was programmed in the 90s.
Anaconda
A community around Python and R experts. Open source is large, respectively. It turned out that my colleagues are constantly using. I didn't know.
DataBricks
Consists of three opensource projects - Spark developers have raised a hell of a lot of money since 2013. I have to read the wiki directly:
“In September 2013, Databricks announced that it had raised $ 13.9 million from Andreessen Horowitz. The company raised additional $ 33 million in 2014, $ 60 million in 2016, $ 140 million in 2017, $ 250 million in 2019 (Feb) and $ 400 million in 2019 (Oct) ”!!!Some great people Spark sawed. Not familiar sorry!
And the projects are:
- Delta Lake - ACID on Spark was recently released (what we dreamed of with Elasticsearch) - it turns it into a database: a rigid scheme, ACID, audit, versions ...
- ML Flow - model tracking, packaging, management and storage.
- Koalas - Pandas DataFrame API on Spark - Pandas - Python API for working with tables and data in general.
You can see about Spark, who suddenly does not know or has forgotten: link . Vidosiki looked with examples from a little boring but detailed consulting woodpeckers: DataBricks for Data Science ( link ) and for Data Engineering ( link ).
In short, Databricks pulls out Spark. Who wants to use Spark normally in the cloud takes DataBricks without hesitation, as intended :) Spark is the main differentiator here.
I found out that Spark Streaming is not real fake realtime or microbatching. And if you need real Real Real time, it's in Apache STORM. Still everyone says and writes that Spark is cooler than MapReduce. The slogan is this.
DATAIKU
Cool end-to-end thing. There is a lot of advertising. Don't understand how it differs from Alteryx?
DataRobot
Paxata for preparing data is cool is a separate company that was bought by Date Robots in December 2019. Raised 20 MUSD and sold. Everything in 7 years.
Preparing data in Paxata, not Excel - see here: link .
There are automatic spoofs and join proposals between two datasets. A great thing is to deal with the data, even more emphasis on text information ( link ).
The Data Catalog is a great catalog of "live" datasets that nobody needs.
Also interesting is how directories are formed in Paxata ( link ).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
The main Data Robot product is here . Their slogan is from Model to corporate application! Discovered consulting for the oil industry in connection with the crisis, but very banal and uninteresting: link . Watched their videos on Mops or MLops ( link ). This is a Frankenstein made up of 6-7 acquisitions of various products.
Of course, it becomes clear that a large team of Data Scientists must have just such an environment for working with models, otherwise they will produce many of them and never deploy anything. And in our oil and gas upstream reality - one model would be successful to create and this is already a great progress!
The process itself was very reminiscent of the work of design systems in geology-geophysics, for example, Petrel... All and sundry make and modify models. Collect data in the model. Then they made a reference model and put it into production! There are many similarities between, say, a geological model and an ML model.
Domino
Emphasis on open platform and collaboration. Business users are allowed in for free. Their Data Lab strongly resembles a Sharepoint. (And from the name strongly gives IBM). All experiments are linked to the original dataset. How familiar it is :) As in our practice - some data was dragged into the model, then it was cleaned and put in order in the model, and all this already lives there in the model and you cannot find the ends in the initial data.
Domino has cool infrastructure virtualization. I collected the machine how many cores per second and went to count. How it was done is not entirely clear right away. Docker everywhere. Lots of freedom! Any workspaces of the latest versions can be connected. Run experiments in parallel. Tracking and selection of successful ones.
The same as DataRobot - the results are published for business users in the form of applications. For especially gifted “stakeholders”. And the actual use of the models is also monitored. Everything for the Pugs!
I did not fully understand how complex models go into production. Some kind of API is provided to feed them data and get results.
H2O
Driveless AI is a very compact and straightforward system for Supervised ML. Everything in one box. It's not clear about the backend right away.
The model is automatically packaged into a REST server or Java App. This is a great idea. Much has been done for Interpretability and Explainability. Interpretation and explanation of the results of the model's operation (What in its essence should not be explainable, otherwise a person can calculate the same?).
For the first time, a case study about unstructured data and NLP is considered in detail . High-quality architectural picture. In general, I liked the pictures.
There is a large open source H2O framework that is not entirely clear (a set of algorithms / libraries?). Own visual laptop without programming like Jupiter ( link). I also read about Pojo and Mojo - H2O models wrapped in reality. The first is on the forehead, the second is with optimization. H20 are the only ones (!) To whom Gartner has written text analytics and NLP in their strengths, as well as their Explanability efforts. It is very important!
Ibid: High Performance, Optimization, and Industry Standard for Iron and Cloud Integration.
And it's logical in weakness - Driverles AI is weak and narrow in comparison with their own open source. Data preparation is lame compared to the same Paxata! And ignore industrial data - stream, graph, geo. Well, everything can't be right.
KNIME
I liked 6 very specific very interesting business cases on the home page. Strong OpenSource.
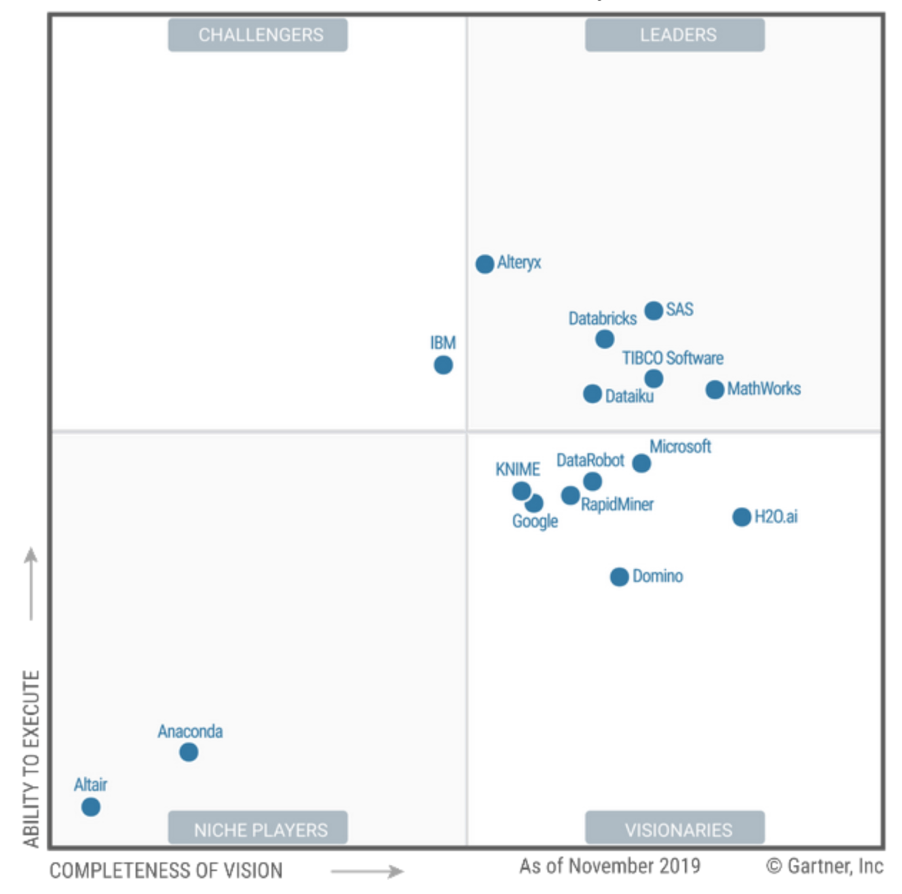
Gartner has lowered from leaders to visionaries. Poor money making is a good sign for users, given that Leader is not always the best choice.
The keyword is just like in H2O - augmented, it means helping the poor citizen data scientists. This is the first time anyone has been scolded for performance in a review! Interesting? That is, there is so much computing power that performance cannot be a systemic problem at all? Gartner has a separate article about this word “Augmented” , which I could not get to.
And KNIME seems to be the first non-American in the review! (And our designers really liked their landing page. Strange people.
MathWorks
MatLb is an old honorary friend known to everyone! Toolboxes for all areas of life and situations. Something very different. In fact, a lot, a lot, a lot of math for all occasions!
Simulink add-on product for systems design. I dug into the toolboxes for Digital Twins - I don't understand anything about it, but a lot has been written here. For the oil industry . In general, this is a fundamentally different product from the depths of mathematics and engineering. To select specific math toolkits. According to Gartner, they all have problems like smart engineers - no collaboration - each rummages in his own model, no democracy, no exploitability.
RapidMiner
I have encountered and heard a lot before (along with Matlab) in the context of good open source. Buried a little in TurboPrep as usual. I'm interested in how to get clean data from dirty data.
Again, you can see that people are good in the 2018 marketing materials and terrible English speaking people in the feature demo.
And people from Dortmund since 2001 with a strong German past)

I did not understand from the site what exactly is available in the open source - you need to dig deeper. Good videos about deployment and AutoML concepts.
There is nothing special about the RapidMiner Server backend either. It will probably be compact and work well on premice out of the box. Packaged in Docker. Shared environment only on RapidMiner server. And then there is Radoop, data from hadup, counting rhymes from Spark in Studio workflow.
Pushed them down as expected by the hot young vendors "striped stick sellers". Gartner, however, predicts future success in the Enterprise space. You can raise money there. The Germans know how holy and holy :) Don't mention SAP !!!
They do a lot for the Citizens! But on the page you can see how Gartner says that they have a hard time with sales innovation and they are not fighting for breadth of coverage, but for profitability.
Left SAS and Tibco typical BI vendors for me ... And both are in the top, which confirms my belief that the normal DataScience logically grows
from BI, and not out of the clouds and the Hadoop infrastructure. From business, i.e., not from IT. As in Gazpromneft for example: link , a mature DSML environment grows out of solid BI practice. But maybe she has a taint and bias on MDM and other things, who knows.
SAS
Not much to say. Only obvious things.
TIBCO
The strategy is read in the shopping list on a page-long Wiki page. Yes, long story, but 28 !!! Charles. bribed BI Spotfire (2007) back in my techno youth. And also reporting by Jaspersoft (2014), then as many as three predictive analytics vendors Insightful (S-plus) (2008), Statistica (2017) and Alpine Data (2017), event processing and streaming Streambase System (2013), MDM Orchestra Networks (2018 ) and Snappy Data (2019) in-memory platform.
Hi Frankie!
