For my debut, I wanted to find a topic that would be of interest to the widest possible audience and require detailed consideration. Daniel Defoe argued that death and taxes await anyone. For my part, I can say that any support engineer will have questions about recovery point storage policies (or, more simply, retention). How retention works, I started explaining 4 years ago, as a junior engineer of the first level, and continue to explain now, already being the team leader of the Spanish and Italian speaking team. I am sure that my colleagues from the second and even the third level of support also regularly answer the same questions.
In this light, I wanted to write the final, most detailed post to which Russian-speaking users could come back again and again as a reference. The moment is right - the recently released 10th Anniversary version added new features to the basic functionality that has not changed for years. My post is focused primarily on this version - although most of what was written is true for previous versions, you simply will not find some of the functionality described there. Finally, looking a little into the future, I will say that some changes are expected in the next version, but we will tell you about this when the time comes. So let's get started.
Backup jobs
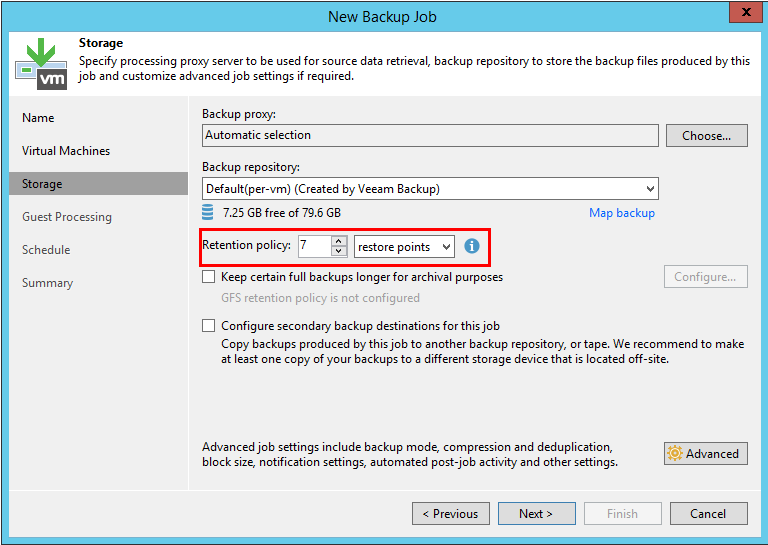
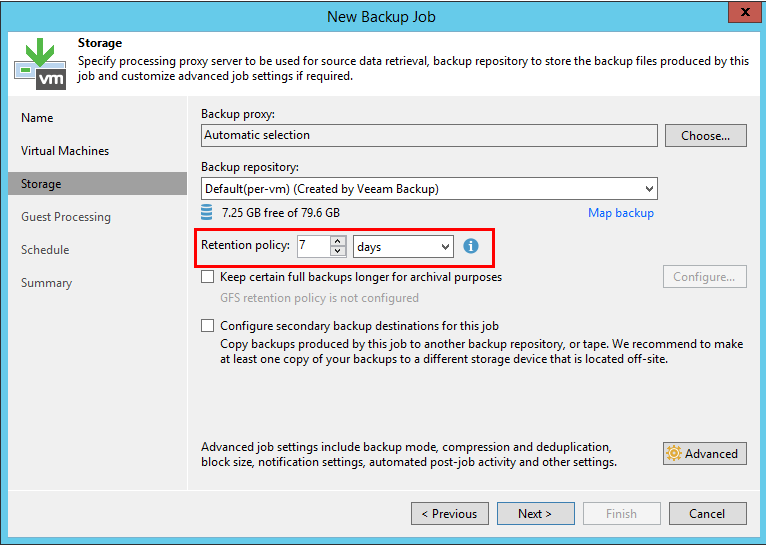
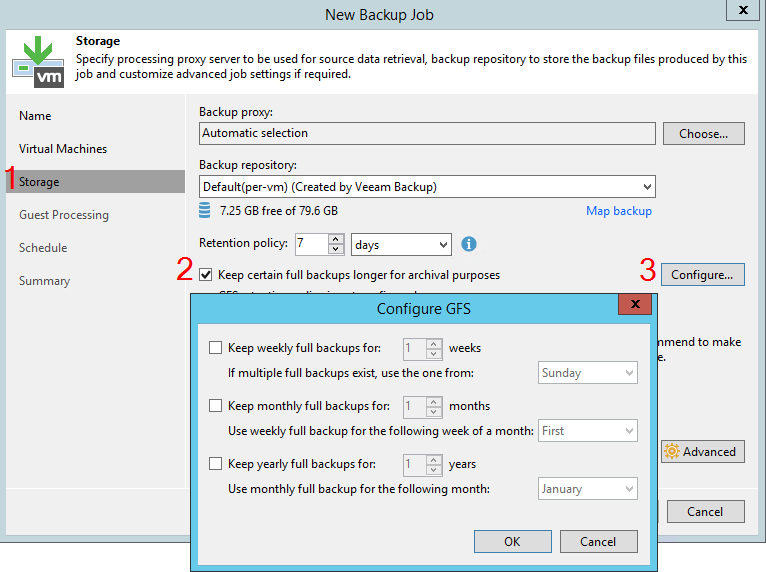
To begin with, let's take a look at the part that has not changed in version 10. The retention policy is determined by several parameters. Let's open the window for creating a new task and go to the Storage tab. Here we will see a parameter that determines the desired number of recovery points:
However, this is only part of the equation. The actual number of points is also determined by the backup mode set for the task. To select this parameter, you need to click on the Advanced button on the same tab. This will open a new window with many options. Let's number them and consider them one by one:
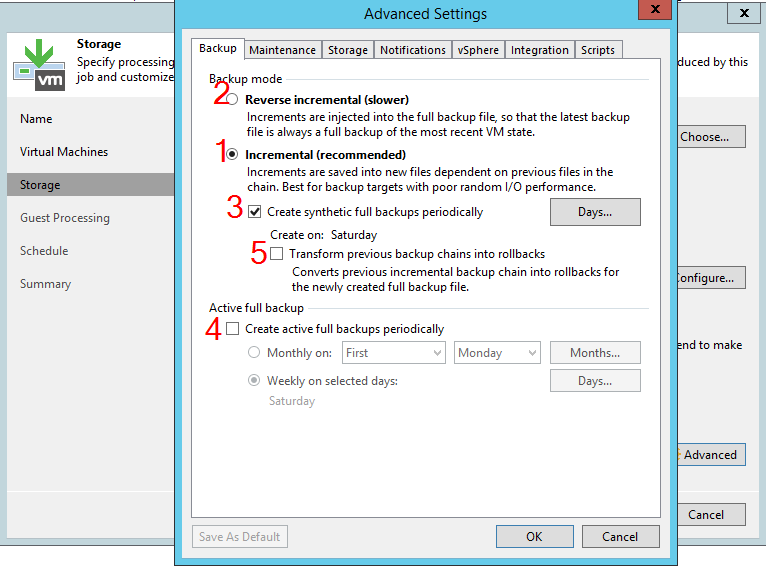
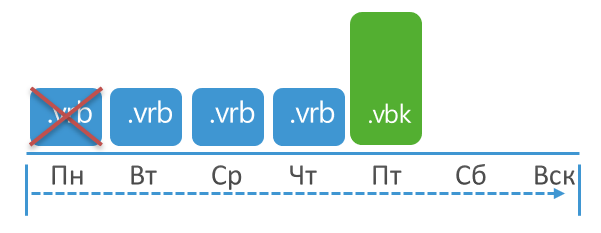
If only option 1 is enabled, the job will run in "forever forward incremental" mode. There are no difficulties here - the task will store the set number of restore points from a full backup (file with the VBK extension) to the last increment (file with the VIB extension). When the number of points exceeds the specified value, the oldest increment will be merged with the full backup. In other words, if the task is set to store 3 points, then immediately after the next session there will be 4 points in the repository, after which the full backup will be merged with the oldest increment and the total number of points will return to 3.

It is also extremely simple to retouch for the reverse incremental mode (option 2). Since in this case the newest point will be a full backup, followed by a chain of so-called rollbacks (files with the VRB extension), then to apply retention, you just need to delete the oldest rollback. The situation will be the same: immediately after the session, the number of points will exceed the set by 1, after which it will return to the desired value.
Note that with the reverse-incremental mode, you can also enable a periodic full backup (option 4), but this will not change the essence. Yes, full restore points will appear in the chain, but we will still just delete the oldest points one by one.
Finally, we come to the interesting part. If you activate an incremental backup, but in addition enable options 3 or 4 (or both at the same time), the task will start creating periodic full backups using the "active" or synthetic method. The method for creating a full backup is not important - it will contain the same data, and the incremental chain will be split into subchains. This method is called forward incremental, and it is he who raises a significant part of the questions from our clients.
Retaining is used here by removing the oldest part of the chain (from full backup to increment). At the same time, we will not delete only a hollow backup or only part of the increments. The entire "subset" is removed completely at once. The meaning of setting the number of points also changes - if in other methods this is the maximum allowable number, after which you need to apply retention, then this setting determines the minimum number. In other words, after removing the oldest "sub-string", the number of points in the remaining part should not fall below this minimum.
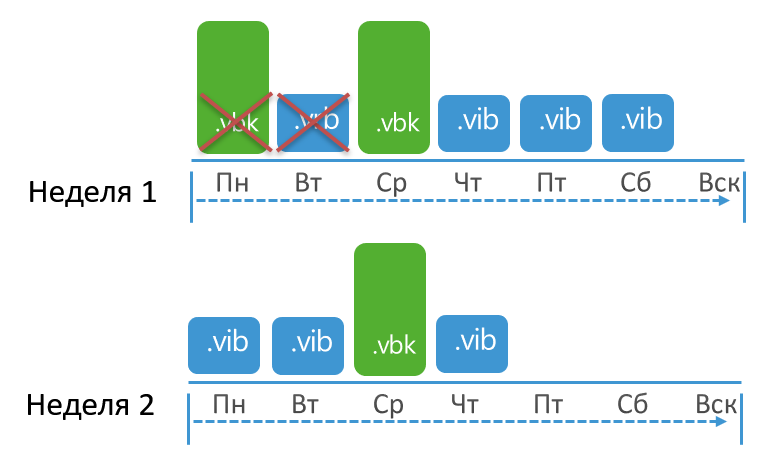
I will try to depict this concept graphically. Let's say the retention is set to 3 points, the task runs every day with a full backup on Monday. In this case, retention will be applied when the total number of points reaches 10:
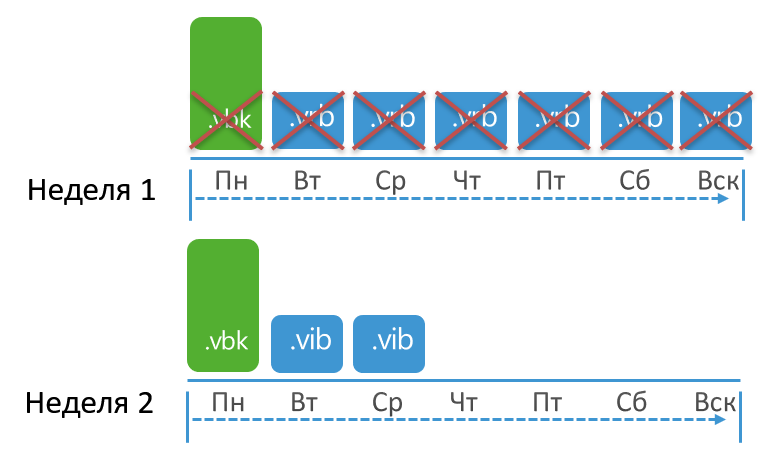
Why as many as 10 when they put up 3? A full backup was created on Monday. From Tuesday to Sunday, the job created increments. Finally, next Monday, a full backup is created again, and only when 2 increments are created can finally the entire old part of the chain be deleted, because the remaining number of points will not fall below the set 3.
If the idea is clear, then I suggest you try to calculate the retention yourself. Let's take these conditions: the task is launched for the first time on Thursday (of course, a full backup will be made). The task is set to create a full backup on Wednesdays and Sundays and store 8 restore points. When will the retention be applied for the first time?
To answer this question, I recommend that you take a piece of paper, line it up by days of the week and write down which point is created every day. The answer will become obvious
Answer

: « »? – 3 (VBK, VIB, VIB) 8 . , , 11 , . . .
: « »? – 3 (VBK, VIB, VIB) 8 . , , 11 , . . .
Some readers may argue: "Why all this if there is rps.dewin.me ?" Without a doubt, this is a very useful tool, and in some cases I would use it, but it also has limitations. First of all, it does not allow you to specify the initial conditions, and in many cases the question is exactly “we have such a chain, what will happen if we change such and such settings?”. Secondly, the tool still lacks clarity. Showing the RPS page to clients, I did not find understanding, but when I painted it as in the example (even using the same Paint), day after day, everything became clear.
Finally, we have not covered the option “Transform previous backup chains into rollbacks” (marked with 5). This option sometimes confuses clients who activate it “automatically”, wanting to enable a synthetic backup. Meanwhile, this option activates a very special backup mode. Without going into details, I will immediately say that at this stage of product development, “Transform previous backup chains into rollbacks” is an outdated option, and I cannot think of a single scenario when it should be used. Its value is so questionable that for a while Anton Gostev himself threw a cry through the forum, asking him to send him examples of its useful use (if you have them, write in the comments, I'm very interested). If there are none (I think it will be so), then the option will be removed in future versions.
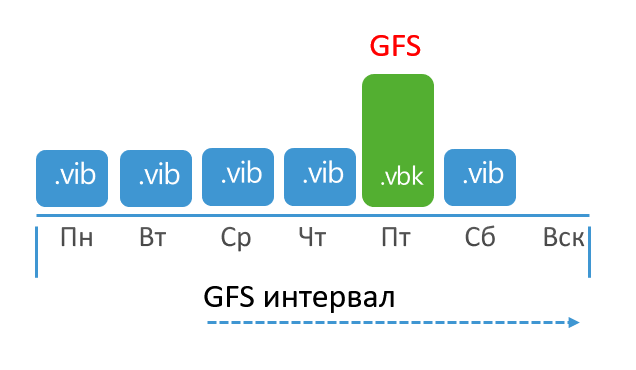
The job will create increments (VIB) until the day the synthetic full backup is scheduled. On this day, VBK is really created, but all points before this VBK are transformed into rollbacks (VRB). After that, the task will continue to create increments to the full backup until the next synthetic backup. As a result, an explosive mixture of VBK, VBR and VIB files is created in the chain. Retaining is applied very simply - by removing the last VBR:

Problems
In addition to understanding how it works, most of the problems that arise when using the incremental mode are usually associated with a full backup. A regular full backup is necessary for this mode, otherwise the repository will accumulate points until it overflows.
For example, a full backup may be created too rarely. Let's say the task is set to store 10 points, and a full backup is created once a month. It is clear that the actual number of points here will be much higher than the one set. Or the task is generally set to work in an infinite-incremental mode and store 50 points. Then someone accidentally created a full backup. That's it, from now on, the task will wait until the full point accumulates 49 increments, after which it will apply retention and return to the infinitely full mode.
In other cases, a full backup is set to be created regularly, but for some reason it does not. I'll write down the most popular reason here. Some clients prefer to use the “run after” scheduling option and set up jobs to run in a chain. Let's take this example: there are 3 jobs that run every day and create a full backup on Sunday. The first task starts at 22.30, the rest are launched in a chain. An incremental backup takes 10 minutes, and therefore by 23.00 all tasks are finished. But a full backup takes an hour, so the following happens on Sunday: the first task runs from 22.30 to 23.30. The next one is from 23.30 to 00.30. But the third task starts on Monday. The full backup is set for Sunday, so in this case it simply won't be there.The task will wait for a full backup to apply retention. Therefore, be careful when using the “run after” option, or do not use it at all - just set the jobs to start at the same time and let the resource scheduler do its job.
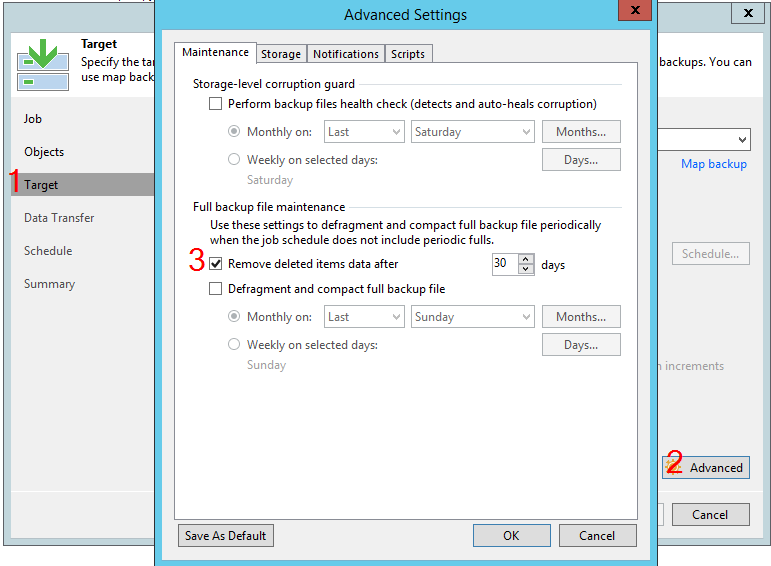
Difficult option “Remove deleted items”
Going through the settings of the Storage - Advanced - Maintenance task, you can stumble upon the option “remove deleted items data after”, calculated in days.
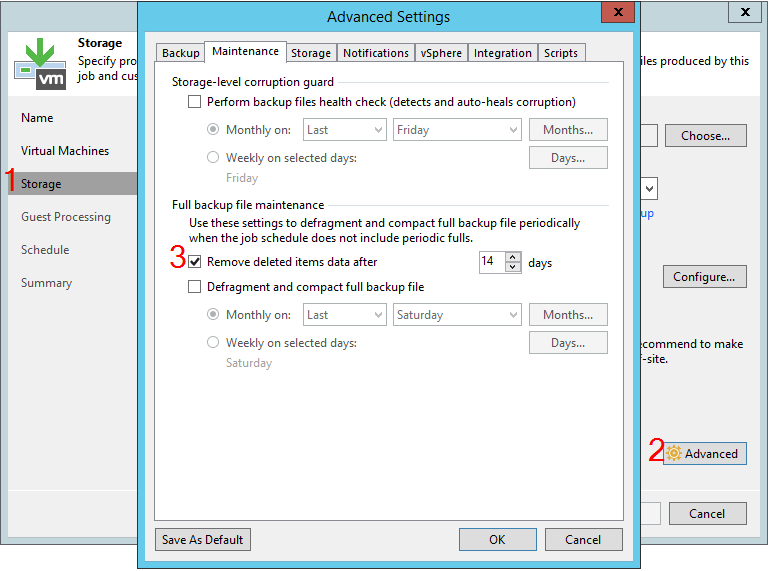
Some clients expect this to be retention. In fact, this is a completely separate option, misunderstanding of which can lead to unexpected consequences. However, the first step is to explain how B&R reacts to situations where only a few machines are successfully backed up during a session.
Consider this scenario: an infinitely incremental job configured to store 6 points. In the task there are 2 machines, one was always backed up successfully, the other sometimes gave errors. As a result, the following situation developed by the seventh point:
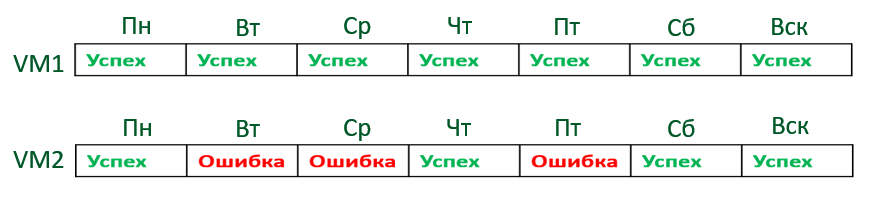
Time to apply retention, but one machine has 7 points and the other has only 4. Will retention be applied here? The answer is yes it will. If at least one object has been backed up, B&R considers the point to be created.
A similar situation can arise if a certain machine was simply not included in the task during a certain session. This happens, for example, when machines are not added to the task individually, but as part of containers (folders, storages) and some machine is temporarily migrated to another container. In this case, the task will be considered successful, but in the statistics you will find a message urging you to pay attention that such and such a machine is no longer processed by the task.

What will happen if you do not pay attention to this? In the case of infinite-incremental or reverse-incremental modes, the number of recovery points of the "problem" machine will decrease with each session until it reaches 1 stored in the VBK. In other words, even if the machine is not backed up for a long time, one restore point will still remain. This is not the case if periodic full backups are enabled. If you ignore the signals from B&R, the last point can be deleted along with the old part of the chain.
With these details clear, we can finally look at the “Remove deleted items data after” option. It will delete all points for a specific vehicle if that vehicle hasn't been backed up for X days. Please note that this setting does not respond to errors (tried it - it did not work). There should not even be an attempt to backup the machine. It would seem that this option is useful and should always be kept enabled. If the administrator removed the machine from the task, then it is logical to clear the chain from unnecessary data after a while. However, tuning takes discipline and care.
Let me give you an example from practice: several containers were added to the task, the composition of which was quite dynamic. Due to the lack of B&R RAM, the server was experiencing problems that went unnoticed. The task started and tried to backup machines, except for one that was not present in the container at that time. Since many machines gave errors, by default B&R has to make 3 additional attempts to backup the "problem" machines. Due to constant problems with RAM, these attempts took several days. There was no repeated attempt to make a backup of the missing VM (the absence of a VM is not an error). As a result, during one of the retries, the “Remove deleted items” condition was met and all points of the machine were deleted.
In this regard, I can say the following: if you have configured notifications about the results of tasks, or even better - you are using integration with Veeam ONE, then most likely this will not happen to you. If you look at the B&R server once a week to check that everything is working, then it is better to refuse options that could potentially lead to the deletion of backups.
What's added in v.10
What we talked about before has existed at B&R for many versions. Having understood these principles of work, let's now see what has been added to the anniversary "ten".
Daily retention
Above, we considered the "classic" storage policy based on the number of points. An alternative approach is to set “days” instead of “restore points” in the same menu.
The idea is clear from the name - retention will store a set number of days, but the number of points in each day does not matter. In doing so, remember the following:
- The current day is not taken into account when calculating retention
- The days when the task did not work at all are also counted. This should be borne in mind so that you do not accidentally lose the points of those tasks that work irregularly.
- The recovery point is counted from the day when its creation began (i.e., if the task started working on Monday and finished on Tuesday, then this point is from Monday)
As for the rest, the principles of application of retention by tasks are also determined by the selected backup method. Let's try another calculation task using the same incremental method. Let's say the retention is set for 8 days, the task runs every 6 hours with a full backup on Wednesday. However, the task does not work on Sunday. The job starts on Monday for the first time. When will the retention be applied?
Answer
, . , , . , , 4 .
. ? 8 . , , , . – .
. ? 8 . , , , . – .
GFS Archiving for Normal Jobs
Prior to v.10, the Grandfather-Father-Son (GFS) storage method was available only for Backup copy and Tape copy jobs. Now it is available for regular backups.
While this is not relevant to the current topic, I cannot help but say that the new functionality does not mean a departure from the 3-2-1 strategy. The presence of archive points in the main repository does not affect its reliability in any way. It is intended that GFS will be used in conjunction with a Scale-out repository to offload these points to S3 and similar repositories. If you are not using it, it is best to continue to store the primary and archive points in different repositories.Now let's look at the principles of creating GFS points. In the task settings, at the Storage step, a special button has appeared that calls the following menu:
The essence of GFS can be reduced to several points (note that GFS works differently in other types of tasks, but more on that later):
- The task does not create a separate full backup for the GFS point. Instead, the most suitable full backup available will be used. Therefore, the task must work in an incremental mode with a periodic full backup, or a full backup must be created manually by the user.
- If only one period is enabled (for example, a week), then at the beginning of the GFS period, the task will simply start waiting for a full backup and mark the first suitable one as GFS.
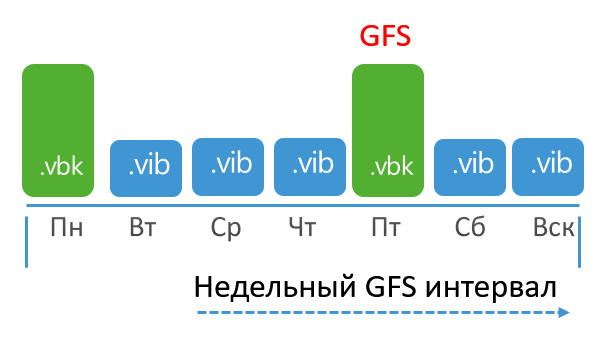
Example: A job is configured to store a weekly GFS using a Wednesday backup. The task runs every day, but the full backup is scheduled for Friday. In this case, the GFS period will begin on Wednesday and the job will begin to wait for a suitable point. It will appear on Friday and will be marked with the GFS flag.
- (, ), B&R , GFS ( ). , .
Example: Weekly GFS is billed on Wednesday, and monthly GFS is billed on the last week of the month. The task runs every day and creates full backups on Mondays and Fridays.
For simplicity, let's start from the penultimate week of the month. This week, a full backup will be created on Monday, but it will be ignored because the weekly GFS interval starts on Wednesday. But the Friday full backup is fully suitable for the GFS point. This system is already familiar to us.
Now consider what happens in the last week of the month. The monthly GFS interval will start on Monday, but the Monday VBK will not be flagged as GFS because the job seeks to mark one VBK as both a monthly and a weekly GFS point. In this case, the search begins with the weekly one, therefore, by definition, it can also become monthly.
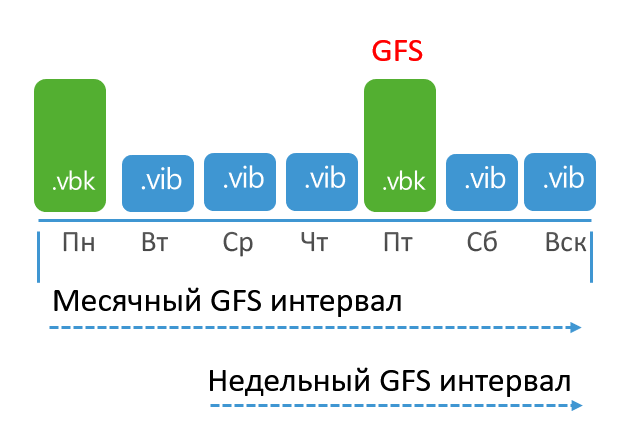
In this case, if you include only the weekly and annual intervals, then they will act independently of each other and can mark 2 separate VBKs as corresponding to the GFS intervals.
Backup copy tasks
Another type of assignment that often requires clarification on the job. To begin with, let's analyze the "classic" method of work, without innovations v.10
Simple retention method
By default, such jobs run in infinite incremental mode. The creation of points is determined by two parameters - the copy interval and the desired number of recovery points (there is no retention by days). The copying interval is set on the very first Job tab when creating a job: The
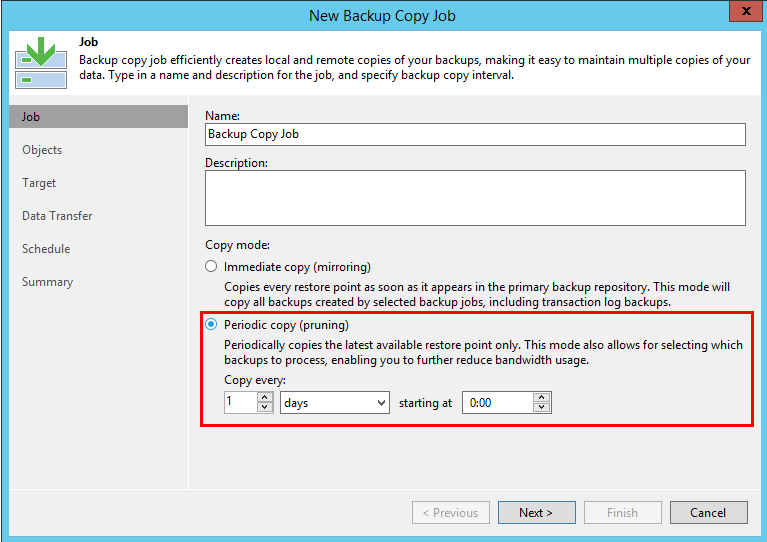
number of points is determined a little further on the Target
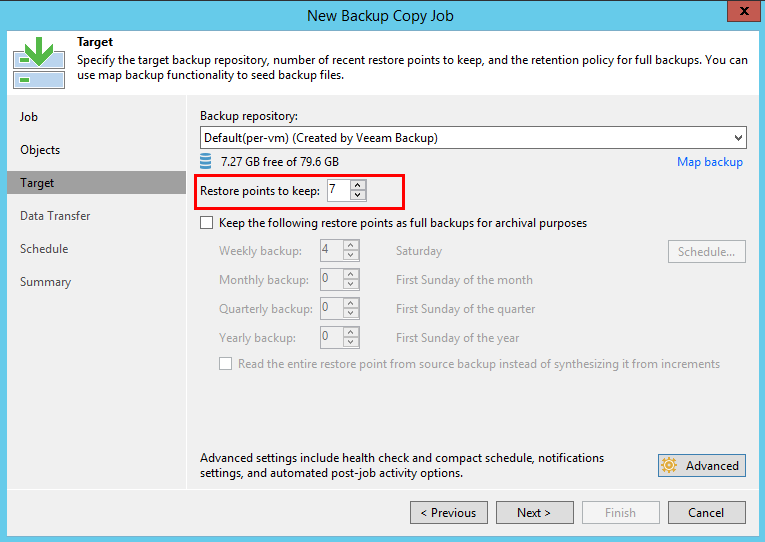
tab.The job creates 1 new point for each interval (it does not matter how many points were created for the VM by the original jobs). At the end of the interval, the new point is finalized and, if necessary, retention is applied by combining VBK and the oldest increment. We are already familiar with this mechanism.
Retaining method using GFS
BCJ also knows how to store archive points. This is configured on the same Target tab, just below the setting for the number of recovery points:

GFS points can be created in two ways - synthetically, using data in the secondary repository, or by simulating a full backup and reading all data from the primary repository (activated by the option marked with the number 3) ... Retaining in both cases will be very different, so we will consider them separately.
Synthetic GFS
In this case, the GFS point is not created on the exact date. Instead, a GFS point will be created when the VIB of the day the GFS point was scheduled to be created is merged with a full backup. This sometimes causes confusion, because time goes on, but there is still no GFS point. And only a powerful shaman from technical support can predict on what day the point will appear. In fact, magic is not needed - just look at the set number of points and the synchronization interval (how many points are created every day). Try to calculate yourself using this example: the task is set to store 7 points, the synchronization interval is 12 hours (i.e. 2 points per day). At the moment, there are already 7 points in the chain, today is Monday, and the creation of a GFS point is scheduled for this day. What day will it be created?
Answer
, , :
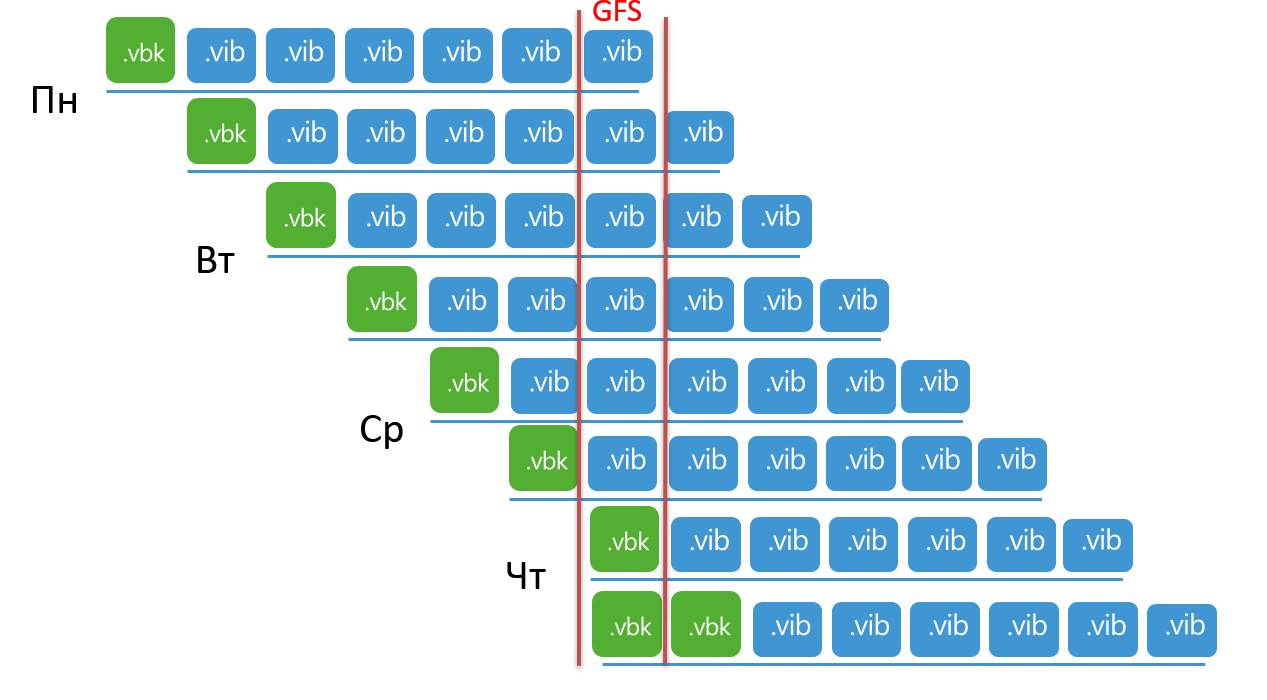
, GFS, . 2 , . , . , – «» . 8 – 7 + GFS.
, GFS, . 2 , . , . , – «» . 8 – 7 + GFS.
Creating GFS Points with the "Read entire point" option
Above, I said that BCJ operates in infinite incremental mode. Now we will analyze the only exception to this rule. If you enable the “Read entire point” option, the GFS point will be created exactly on the scheduled day. The task itself will work in an incremental mode with periodic full backups, which we discussed above. Retaining will also be applied by removing the oldest part of the chain. However, in this case, only the increments will be deleted, and the full backup will be left as a GFS point. Accordingly, points marked with GFS flags are not taken into account when calculating retention.
Let's say the task is set to store 7 points and create a weekly GFS point on Monday. In this case, every Monday the job will actually create a full backup and mark it as GFS. Retaining will be applied when, after removing the increments from the oldest part, the number of remaining increments does not fall below 7. This is how it looks in the diagram:

So, by the end of the second week there are 14 points in the chain. During the second week, the task created 7 points. If it were a simple task, the retention would have already been applied. But this is a BCJ with GFS retention, so we do not count GFS points, which means there are only 6 of them. That is, we cannot yet apply retention. In the third week we create another full backup with the GFS flag. 15 points, but we don't count this one again. Finally, on Tuesday of the third week, we create an increment. Now, if we remove the chain increments of the first week, the total number of increments will satisfy the set retention.
As mentioned above, in this method it is very important that full backups are created regularly. For example, if you set the main retention for 7 days, but only 1 annual point, it is easy to imagine that the increments will accumulate strongly, much more than 7. In such cases, it is better to use the synthetic method of creating GFS.
And again “Remove deleted items”
This option is also present for BCJ:
The logic of this option here is the same as in regular backup jobs - if the machine is not processed for the specified number of days, then its data is removed from the chain. However, for BCJ, the usefulness of this option is objectively higher, and here's why.
In normal mode, the BCJ operates in an infinite-incremental mode, so if at some point the machine is removed from the task, then retention will gradually remove all restore points until there is only one left - in VBK. Now, imagine that the job is still configured to create synthetic GFS points. When the time comes, the job will need to create a GFS for all machines in the chain. If some car does not have new points at all - well, you will have to use the one that is. And so every time. As a result, the following situation may arise:
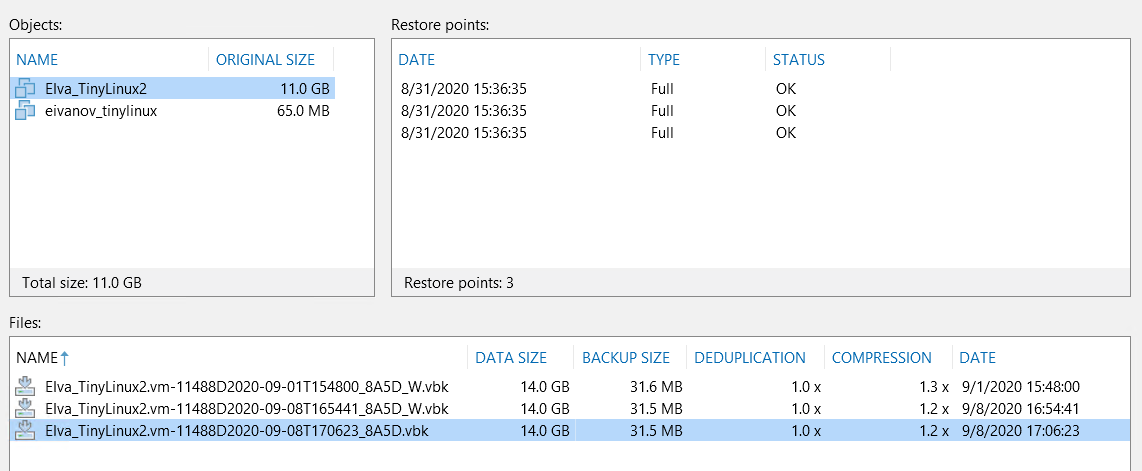
Pay attention to the Files section: we have the main VBK and 2 weekly GFS points. And now on the Restore points section - in fact, these files contain the same image of the machine. Naturally, there is no point in such GFS points, they only take up space.
This situation is only possible when using synthetic GFS. To prevent this, use the “Remove deleted items” option. Just don't forget to set it for an adequate number of days. Technical support has seen cases when the option was set for fewer days than the synchronization interval - BCJ began to rampage and delete points before they could create them.
Note also that this option does not affect existing GFS points. If you want to clean the archives, you need to do it manually - by right-clicking on the machine and selecting “Delete from disk” (in the window that appears, do not forget to check the “Remove GFS full backup” box):

New in v.10 - immediate copy
Having dealt with the "classic" functionality, let's move on to a new one. The innovation is one, but very important. This is a new mode of operation.
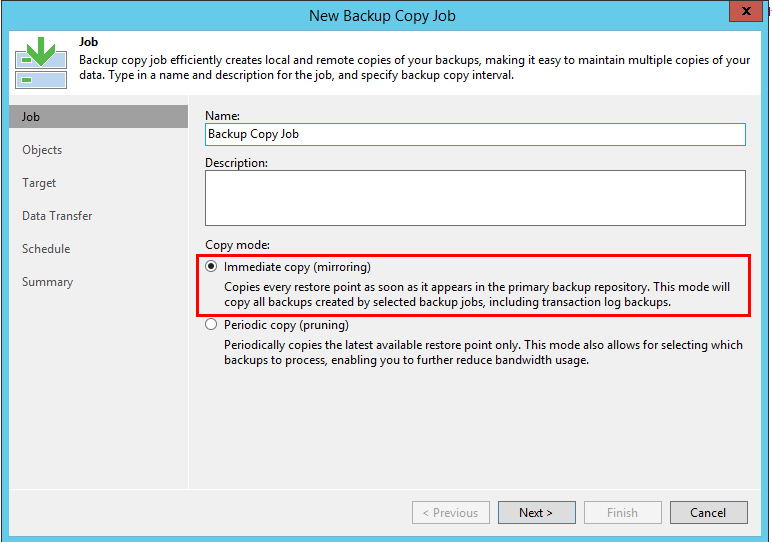
There is no such thing as a "synchronization interval", the task will constantly monitor whether new points have appeared, and copy all of them, no matter how many of them. However, the job remains incremental, that is, even if the main job creates a VBK or VRB, these points will be copied as VIB. Otherwise, there are no surprises in this mode - both standard and GFS retention work according to the rules described above (although only synthetic GFS is available here).
Discs are spinning. Features of rotated drives repositories
The constant threat of ransomware viruses has made it the de facto security standard to have a copy of data on a medium where the virus cannot reach. One option is to use disk rotation repositories, where disks are used in turn: while one disk is connected and writable, the rest are stored in a safe place.
To teach B&R to work with such repositories, in the repository settings, at the Repository step, click on the Advanced button and select the appropriate option:
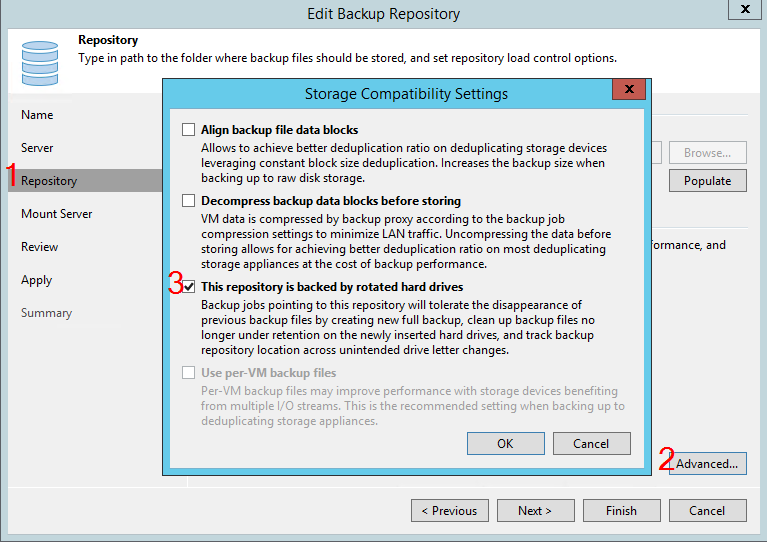
After that, VBR will expect that the periodically existing chain will disappear from the repository, which means disk rotation. B&R will behave differently depending on the type of repository and the type of job. This can be represented by the following table:
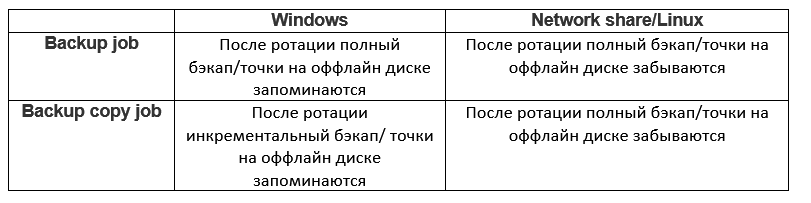
Consider each option.
Regular job and Windows repository
So, we have a task that saves the chains to the first disk. During the rotation, the created chain actually disappears, and the task needs to somehow survive this loss. It finds consolation in creating a full backup. Thus, each rotation means a full backup. But what happens to the points on a disconnected disk? They are remembered and taken into account when calculating retention. Thus, the set number of points in the task is how many points must be kept on all disks. Here is an example:
The job is running in infinite incremental mode and is configured to store 3 restore points. But we also have a second disc, and we rotate once a week (there may be more discs, this does not change the essence).
In the first week, the task will create points on the first disk and merge the extra ones. Thus, the total number of points will be three:

Then we connect the second disk. On startup, B&R will notice that the disc has changed. The chain on the first disk will disappear from the interface, but information about it will remain in the database. Now the task will keep 3 points on the second disk. The general situation will be as follows:

Finally, we reconnect the first drive. Before creating a new point, the task will check what is there with the retention. And the retention, I remind you, is set to store 3 points. In the meantime, we have 3 points on disk 2 (but it is disabled and stored in a safe place where B&R cannot reach) and 3 points on disk 1 (and this one is connected). This means that you can safely remove 3 points from disk 1, since they exceed the retention. After that, the task again creates a full backup, and our chain begins to look like this:

If the retention is configured to store days instead of the number of points, then the logic does not change. Additionally, GFS retention is not supported at all when using rotated repositories.
Common job and Linux repository \ network storage
This option is also possible, but is generally less recommended due to the imposed restrictions. The task will react to disk rotation and the disappearance of the chain in the same way - creating a full backup. The limitation is due to the trimmed retention mechanism.
Here, during rotation, the entire chain on the disconnected disk is simply deleted from the B&R database. Please note - from the database, the files themselves remain on the disk. They can be imported and used for recovery, but it's not hard to guess that sooner or later, such forgotten chains will fill the entire repository.
The solution is to add DWORD ForceDeleteBackupFiles as indicated on this page: www.veeam.com/kb1154... After that, the job will start simply deleting all the contents of the job folder or the repository folder (depending on the value) on each rotation.
However, this is not an elegant retention, but a purge of all content. Unfortunately, technical support encountered cases when just the root directory of the disk was specified as a repository, where, in addition to backups, other data lay. All this was destroyed during the rotation.
In addition, when you enable ForceDeleteBackupFiles, it works for all types of repositories, that is, even repositories on Windows will stop applying retention and start deleting content. In other words, a local disk on Windows is the best choice for such a backup storage system.
Backup copy and Windows repository
Things get even more interesting with BCJ. Not only is there a full-fledged retention, but there is no need to make a full backup with every disk change! It works like this:
First B&R starts creating points on the first disc. Let's say we set retention at 3 points. The task will work in an infinite-incremental mode and combine all unnecessary (remind, GFS retention is not supported in this case).

Then we connect the second drive. Since there is no chain on it yet, we create a full backup, after which we have a second chain of three points:

Finally, it's time to reconnect the first disk. And this is where the magic begins, as the job will not create a full backup, but instead will simply continue the incremental chain:

After that, virtually every disk will have its own independent chain. Therefore, retention here does not mean the number of points on all disks, but the number of points on each disk separately.
Backup copy and Linux repository \ network storage
Again, all the elegance is lost if the repository is not on the local Windows drive. This script works similarly to the one discussed above with a simple task. With each rotation, BCJ will create a full backup, and the existing points will be forgotten. In order not to be left without free space, you need to use DWORD ForceDeleteBackupFiles.
Conclusion
So, as a result of such a long text, we considered two types of tasks. Of course, there are many more tasks, but it will not be possible to consider all of them in the format of one article. If, after reading, you still have any questions, then write them in the comments, I will be happy to answer personally.