int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}This is a simple application especially for experiments, it searches for prime numbers using the sieve of Eratosthenes . Let's run the solution 20 times and calculate the user time of each execution.
Test bench description
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
Scatter of execution time before optimizations:
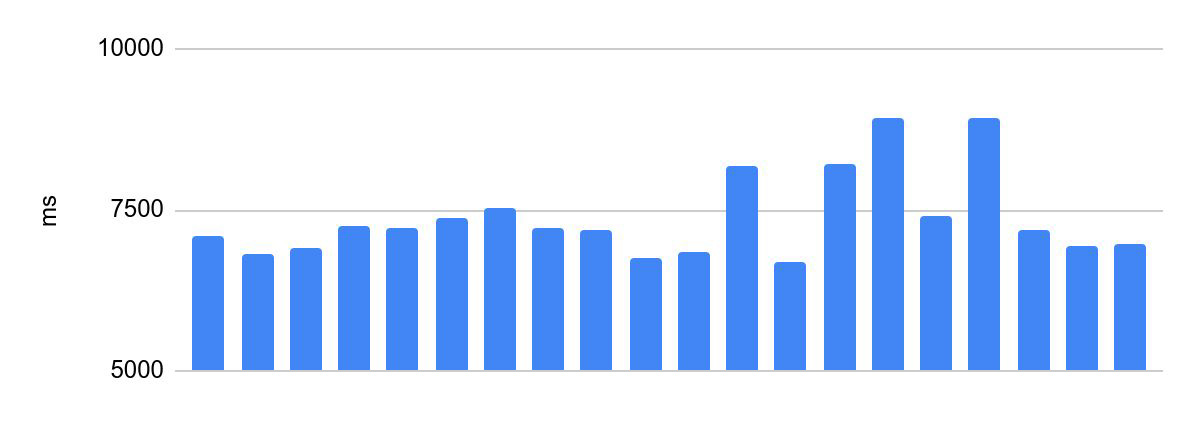
The difference between the fastest and the slowest execution is 2230 ms.
This is unacceptable for Olympiad programming. The execution time of the participant's code is one of the criteria for the success of his solution and one of the conditions of the competition, the distribution of prizes depends on this. Therefore, there is an important requirement for such systems - the same verification time for the same code. In what follows, we will call this the consistency of code execution.
Let's try to align the execution time.
Core isolation
Let's start with the obvious. Processes compete for cores, and you need to somehow isolate the core for the execution of the solution. In addition, with Hyper Threading enabled, the operating system defines one physical processor core as two separate logical cores. For fair core isolation, we need to disable Hyper Threading. This can be done in the BIOS settings.
The Linux kernel out-of-the-box supports a startup flag to isolate kernels isolcpus Add this flag to GRUB_CMDLINE_LINUX_DEFAULT in grub settings: / etc / default / grub. For example:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
Run update-grub and restart the system.
Everything looks as expected - the first two kernels are not used by the system:

Let's start on an isolated kernel. The CPU Affinity configuration allows you to bind a process to a specific core. There are several ways to do this. For example, let's run the solution in a porto container (the kernel is selected using the cpu_set argument):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop: we use QEMU-KVM to run solutions in production. The porto container is used throughout this article to make it easier to show.
Launching with a kernel dedicated to the solution, no load on neighboring kernels:

The difference is 375 ms. It got better, but it's still too much.
Tyunim performance
Let's try our stress test. Which one? Our task is to load all cores with multiple threads. This can be done in several ways:
- Write a simple application that will create many threads and start counting something in each of them.
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
Launching with a core dedicated to a solution, with a load on adjacent cores:

The difference is 1354 ms: one second more than without a load. Obviously, the load affected the execution time, despite the fact that we were running on an isolated kernel. It can be seen that at a certain moment the execution time decreased. At first glance, this is counterintuitive: with increasing load, performance also increases.
In production, this behavior (when the execution time starts to float under load) can be very painful to fire. What is the load in this case? A stream of decisions from participants, most often at major competitions and olympiads.
The reason is that Intel Turbo Boost is activated under load - a technology for increasing the frequency. Disable it. For my stand I also turned off SpeedStep... For an AMD processor, Turbo Core Cool'n'Quiet would have to be turned off. All of the above is done in the BIOS, the main idea is to disable what automatically controls the processor frequency.
Running on an isolated core with Turbo Boost disabled and load on neighboring cores:

Looks good, but the difference is still 252ms. And that's still too much.
Offtop: notice how the average execution time dropped by about 25%. In everyday life, disabled technologies are good.
We got rid of competition for cores, stabilized the core frequency - now nothing affects them. So where does the difference come from?
NUMA
Non-Uniform Memory Access, or Non-Uniform Memory Architecture, "an architecture with uneven memory." In NUMA systems (that is, conventionally, on any modern multiprocessor computer), each processor has local memory, which is considered part of the total. Each processor can access both its local memory and the local memory of other processors (remote memory). The unevenness is that access to local memory is noticeably faster.
The execution time "walks" precisely because of such unevenness. Let's fix it by binding our execution to a specific numa node. To do this, add numa node to the porto container configuration:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Running on an isolated core with Turbo Boost disabled, NUMA configuration and load on neighboring cores:
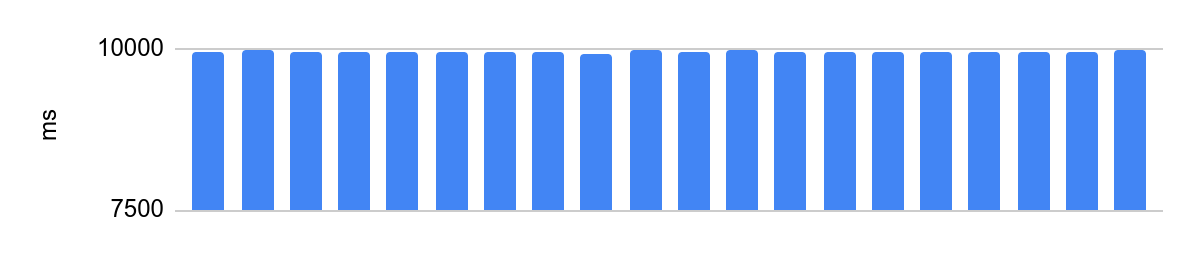
The difference is 48 ms, and the average execution time after we disabled processor optimizations is 10 seconds. 48ms at 10s is equivalent to 0.5% error, very good.
Important spoiler
A little more about isolcpus
The isolcpus flag has a problem: some system threads can still schedule to an isolated kernel.
Therefore, in production we use a patched kernel with extended functionality of this flag. Thus, we choose the kernel, taking into account the flag, when the scheduling of threads occurs.
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
Plans for the future
Pools
If one decisive machine is more powerful than the other, then no amount of core isolation tweaks will help - as a result, we will still get a big difference in execution time. Therefore, you need to think about heterogeneous environments. Until now, we simply did not support heterogeneity - the entire fleet of deciding machines is equipped with the same hardware. But in the near future, we will begin to split dissimilar hardware into homogeneous pools, and each competition will be held within the same pool with the same hardware.
Moving to the cloud
A new challenge for the system will be the need to launch in Yandex.Cloud. By today's standards, iron servers are unreliable, a move is necessary, but it is important to maintain consistency in the execution of packages. Here the technical possibilities are still being investigated. There is an idea that, in extreme cases, cloud machines can run solutions that do not require strict execution time. Thus, we will reduce the load on iron machines and they will only deal with solutions that just require consistency. There is another option: first check the parcel in the cloud and, if it did not meet the time limit, recheck it on real hardware.
Collecting statistics
Even after all the tweaks, processors will inevitably throttles. To reduce the negative effect, we will execute the solutions in parallel, compare the results and, if they differ, launch a recheck. In addition, if one of the decisive machines is constantly degrading, this is an excuse to take it out of service and deal with the reasons.
conclusions
Contest has a peculiarity - it may seem that it all comes down to simply running the code and getting the result. In this article, I have revealed only one small aspect of this process. There is something like this on every layer of the service.