Attributes with meta information
Title (title attribute)
The title briefly describes the essence of the rule. This text field is up to 256 characters long. Here you should give the shortest and most capacious description. Follow these guidelines:
- Don't use constructs like "Detects ..." as your heading. And without this, it is clear that the rule detects something.
- Use capacious titles no longer than 50 characters.
- Write any explanations and important comments in the description field (we will consider it further).
Detailed description and additional explanations for the rule (description attribute)
If the title contains a brief description of the rule for a general understanding of its purpose, then in the description field you can specify all the nuances and features that the author puts into this rule. It also briefly describes the attack that is proposed to be detected using this rule. The maximum length for this field is 65,535 characters.
Unique identifier of the rule and identifiers of related rules (id, relative)
Since the specific values of the title and description attributes can be arbitrary, including the same for two different rules (never do this), they are not suitable for uniquely identifying a rule. A more formal, unique identifier is needed. Universally unique identifier (UUID) is used in the vast majority of products to solve this problem. Sigma's authors advise rule developers to follow the same path, however, any identifier generation scheme can be used for private rules. In the public repository, the aforementioned UUID is selected as the scheme for creating identifiers. We followed the same approach in the example rule in the first part of the article. If you want to publish your rule in the future or send a request to add it to the official repository,then we advise you to follow the same scheme for creating a rule identifier.
The unique identifier can be generated in different ways, in Windows the easiest way is to run the following PowerShell code:
PS C:\> "id: $(New-Guid)"
id: b2ddd389-f676-4ac4-845a-e00781a48e5fOn a Linux kernel based operating system, you can use the uuidgen utility:
$ echo “id: `uuidgen`”
id: b2ddd389-f676-4ac4-845a-e00781a48e5fWhen making significant changes to a rule, its identifier must be changed. Situations in which to create a new identifier:
- changing the logic of the rule;
- inheritance of a rule from an existing one while preserving the original one (it is also true for the situation of improving the rule);
- merging rules.
For the cases of inheritance and merging of rules, there is a special identifier related with four possible values of the type (the type attribute).
Let's consider hypothetical situations in which we might find it useful to use the related identifier. For clarity, instead of long identifiers in the UUID format, we will simply write X, Y, Z.
In the first case, the new rule (id: X) is derived from the existing one (id: Y). This can happen if we have improved the logic of work in a new rule, but for some reason we want to keep the old rule. Thus, our rule has a parent rule that is saved and can be used in the future:

The second case is similar to the first except for one fact: the old rule is not preserved. That is, we rewrote the rule radically, and it was necessary to assign a new identifier, and the old one is obsolete (obsoletes) and will no longer be used. So, we had a rule (id: Y) that we rewrote, and we decided that we no longer need it. The new rule received an identifier (id: X). In the Sigma rule, a similar situation will look something like this:

In the third case, consider a situation where a new rule appeared as a result of merging two or more existing rules. The new rule (id: X) is the result of merging two rules (id: Y, Z). It is important to note that both parent rules that were involved in the merge are preserved and can be used further. In a Sigma rule, a similar situation might look like this:

Although the order of the rules is not defined during the merge, in the comments we have numbered them for clarity.
The fourth type is rename. As the name suggests, this type of association between identifiers is applied when renaming an old rule. In fact, this type is not used in practice. As an example of use, the authors cite a case of changing the scheme for creating identifiers (we remember that UUID is not the only possible naming scheme).
Rule ready status (status attribute)
According to the specification, a rule can be in one of three states:
- stable - the rule can be used in a real infrastructure to detect attacks, no modification is required;
- test - the rule is almost stable, but a little adjustment is required;
- experimental - such a rule can generate a large number of false positives, but at the same time it reveals interesting events.
Usually, before running a rule on a real infrastructure, the rule has the experimental status, since it is not yet known exactly how often it will generate errors. Further, after several months of testing, if the rule is written well and does not generate errors (or there are negligible ones), it is transferred to the stable category. Otherwise, corrections are made and checked again. There are no rules with the test status in the official Sigma repository.
The license under which the rule is distributed (the license attribute)
The license under which the rule is distributed. This field came from the world of free software. This parameter is rarely specified, but if specified, it must conform to the SPDX ID specification.
Rule creators (author attribute)
This field lists all the authors of the rule. It is considered good form to indicate not only the person who wrote the rule itself, but also the author of the original idea of detection.
Links to studies that helped develop the rule (references attribute)
When writing Sigma rules, it is customary to include links to original articles, tweets and research that helped or inspired the creation of the rule. In addition to expressing respect for someone else's work, such links later help to understand how the rule works.
Event fields useful for analytics to show when a rule is triggered (fields attribute)
Since the author of the rule has a deep understanding of the attack algorithm and the events that are generated during its execution, he can select a list of fields from events that will help the SOC operator or another employee of the information security team to understand the incident.
Cases of false positives of the rule (attribute falsepositives)
The falsepositives field is rather unusual for detection rules. It does not affect the course of event validation in any way, but it does two useful things:
- Help the user determine if a given rule trigger is an error.
- Remind the developer of the rule once again that his rule can be triggered falsely. Such thoughts can help a developer write a more precise rule.
Various tags and tags (tags attribute)
Typically this field is used for MITER ATT & CK and CAR tags. We highly recommend that you immediately classify your rule, since such markup allows you to integrate Sigma rules with other information security projects. However, the format does not limit the authors of the rules only to such labels, you can put any.
Collections of rules
According to the YAML standard, one file (in their terminology stream) can contain several YAML documents. This is achieved thanks to the YAML document tag - three hyphens (“---"). For the Sigma format, these documents can be independent Sigma rules or action documents.
With the first case, everything is simple: one file contains full Sigma rules that separated from each other by a YAML document label (example rules / proxy / proxy_ursnif_malware.yml ) The
second case is more complicated: A YAML document is treated as an action document if the top-level action attribute has one of the following three values:
- global — , YAML- . action- . : , Sigma- ;
- reset — , action-;
- repeat — repeat .
Note : the action attribute can appear anywhere in the rule.
The most common use case for a collection of rules is to define multiple Sigma rules for similar events, such as Windows Security EventID 4688 and Sysmon EventID 1. Both events appear as a result of process creation, they just have different sources. The collection of Sigma rules for a given scenario can contain three action documents:
- A global action document that defines common metadata fields and detection indicators.
- Rule that defines the source of the Windows Security Event Log and event EventID = 4688.
- A rule that defines the source of the Windows Sysmon Event Log and event EventID = 1.
An alternative solution could be:
- A global action document that defines common metadata fields.
- Windows Security Event Log ( EventID=4688) .
- Action- repeat, logsource EventID , . 2.
action-
In this section, we will describe in detail how Sigma generates summary rules based on the values of the action attribute. YAML documents that contain an action attribute with the value global are considered global documents within this file, and their fields will be added to all other documents.
Note : if the current document contains the action attribute with the reset value, then the global document fields will not be added to it.
The logic for working with global documents is as follows: as soon as the parser encounters a global document (a document that contains an action attribute with the global value), it adds its fields to a special buffer and proceeds to the next document. Let's call this special buffer GLOBALYAML, it will help in the future to refer to it in diagrams.
Important: Since document boundaries are defined by the “---” label, it is important to place these labels correctly in the file.
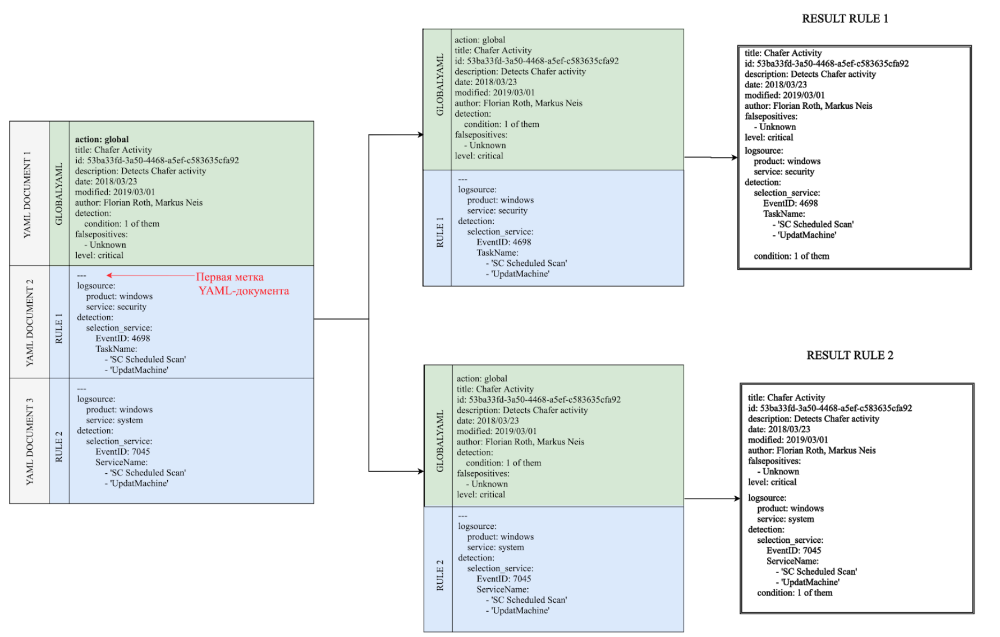
In the example below, the first YAML document contains an action attribute with the value global. The boundaries of this document extend to the first document mark. Thus, the entire first document is written into the global buffer. The fields of this buffer are then added to each subsequent document. As a result, we get two rules at the output. Scheme 1. Processing a simple rule with the correct definition of the YAML document labels But if you delete or forget the first label, then all the fields of YAML DOCUMENT 2 will be included in the global document. As a result, we get only one rule with an incorrect set of search identifiers at the output. Therefore, it is very important to properly label YAML documents in such compound rules.

Scheme 2. Processing of the previous rule - if you forget to put the first label of the YAML document
It should be noted that the global document does not necessarily come at the beginning. If you look at the two previous schemes, then it is not always YAML DOCUMENT 1. Moreover, it does not have to be in the singular. The following diagram illustrates this clearly. Scheme 3. Processing a rule containing various options for specifying a global YAML document So, we have considered the issues related to the correct placement of tags in a YAML document. We also saw that you can set the global YAML document in different ways using the action attribute with the global value. Next, let's look at the scheme for transforming the rule using the two remaining values of the action attribute - reset and repeat.


Scheme 4. Processing a rule containing the action attributes with the reset and repeat values
What else needs to be said about the Sigma project
Sigma is not only a set of formatted rules that we covered in this series.
In our publications, we focused on describing the format and syntax of the rules. But rules are only one half of the project, the second is the backends used by the sigmac converter. Conventionally, these converters can be thought of as "adapters" with a universal input and a specific output. It is the presence of such "adapters" that makes the universal description format so useful. In this situation, it does not matter which of the supported systems you use, Sigma allows you to describe the idea and the detection algorithm, while one or another backend for the sigmac converter is responsible for the specific syntax of the target system and the mapping of fields.
However, do not assume that by downloading the rules and converting them into the syntax of the required target system, you will solve all the problems associated with filling your system with expertise. We will briefly discuss why Sigma is not an out-of-the-box solution at the moment, and why it is necessary to understand the syntax of the rules.
Current Sigma Challenges
Sigma is an actively developing project, and like any growing project, Sigma has its own challenges. Personally, I perceive them as points of development and areas of growth. Well, since this is an open source project, joining forces can make a significant contribution to the development of certain parts of the project. I will list what at the moment I refer to the main calls of the framework:
- . .
- , Windows- (. ). , .
- Wiki , . .
- experimental — , .
- .
- , .
From my own experience, I will say that when I got acquainted with the Sigma project and participated in OSCD, the first item on the list turned out to be the most significant. It turned out that the differences between the syntax in MaxPatrol SIEM and in Sigma do not end only with the semantics of keywords and the design of correlation rules. Some of our ideas cannot be described in terms of Sigma syntax, since at this stage there is no possibility of event correlation. The correlation mechanism allows you to search for common values of event fields and relate such events to each other. This is useful when we want to accurately establish the relationship between events. For example, to track events within one user session. To do this, you need to bind events by the value of the LogonID field or its equivalent.
It should be noted that point detections or detections based on not directly related events are described very successfully using Sigma.
One way to help address these and other issues is to actively participate in one of the OSCD Sprints. And since there are many tasks, everyone will be able to find what is interesting to him.
New sprint coming soon, join us!
We express our gratitude to the organizers of the first sprint for the high-quality conduct of the event and the attentive attitude towards the participants. What are the only personalized postcards filled in by hand and sent to each participant! For our part, we plan to continue participating in new sprints and make a feasible contribution to the Sigma repository.
After reading our series of articles and familiarizing yourself with the format of the rules, you will be able to apply your expertise for the benefit of the entire information security community.
Be sure to join the second sprint. Participate individually and assemble teams, let's make the world safer together!
OSCD Initiative contacts:
- oscd.community
- twitter.com/oscd_initiative
Author : Anton Kutepov, specialist of the department of expert services and development of Positive Technologies (PT Expert Security Center)