Introduction
Hello, Habr!
Many people liked the previous part, so I again shoveled half of the boost documentation and found something to write about. It is very strange that there is no such excitement around boost.compute as around boost.asio. After all, enough, this library is cross-platform, and it also provides a convenient (within the framework of c ++) interface for interacting with parallel computing on the GPU and CPU.
All parts
- Part 1
- Part 2
Content
- Asynchronous operations
- Custom functions
- Comparison of the speed of different devices in different modes
- Conclusion
Asynchronous operations
It would seem much faster? One way to speed up your work with containers in the compute namespace is to use asynchronous functions. Boost.compute provides us with several tools. Of these, the compute :: future class to control the use of functions and the copy_async (), fill_async () functions to copy or fill the array. Of course, there are also tools for working with events, but there is no need to consider them. The following will be an example of using all of the above:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
There is nothing special to explain here. The first three lines are the standard initialization of the required classes, then two vectors for copying, a vector for filling, the variable of which will fill the previous vector and directly the functions for filling and copying, respectively. Then we wait for their execution.
For those who worked with std :: future from STL, everything is absolutely the same here, only in a different namespace and there is no analogue of std :: async ().
Custom functions for calculations
In the previous part, I said that I will explain how to use my own methods to process a dataset. I counted 3 ways to do this: use a macro, use make_function_from_source <> () and use a special framework for lambda expressions.
I'll start with the very first option - a macro. First I will attach a sample code and then I will explain how it works.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
The first argument is the type of the return value, then the name of the function, its arguments and the body of the function. Further under the name add, this function can be used, for example, in the compute :: transform () function. Using this macro is very similar to a regular lambda expression, but I have checked that they will not work.
The second and probably the most difficult method is very similar to the first. I looked at the code of the previous macro and it turned out that it uses the second method.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Here everything is more obvious than it might seem at first glance, the make_function_from_source () function uses only two arguments, one of which is the name of the function, and the second is its implementation. After a function is declared, it can be used in the same way as after a macro implementation.
Well, the last option is a lambda expression framework. Usage example:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
As the fourth argument, we indicate that we want to multiply each element from the first vector by 2, everything is quite simple and is done in place.
Boolean expressions can be specified in the same way. For example, in the compute :: count_if () method:
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Thus, we have counted all the even numbers in the array, counter will be equal to one.
Comparison of the speed of different devices in different modes
Well, the last thing I would like to write about in this article is a comparison of the processing speed on different devices and in different modes (only for the CPU). this comparison will prove when it makes sense to use GPUs for computing and parallel computing in general.
I will test like this: using compute for all devices, I will call the compute :: sort () function in order to sort an array of 100 million float values. To test single-threaded mode, call std :: sort on an array of the same size. For each device, I will note the time in milliseconds using the chrono standard library and output everything to the console.
The result is the following:

Now I will do the same only for a thousand values. This time the time will be in microseconds.

This time the processor in single-threaded mode was ahead of everyone. From this we conclude that this kind of operation is worth doing only when it comes to really big data.
I would like to do some more tests, so let's do a test for calculating the cosine, square root and squaring.
In calculating the cosine, the difference is very large (the GPU runs 60 times faster than the CPU in one thread).
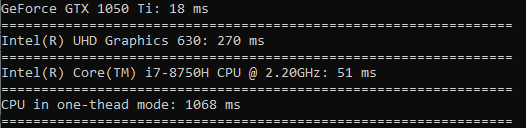
The square root is calculated at almost the same speed as the sort.
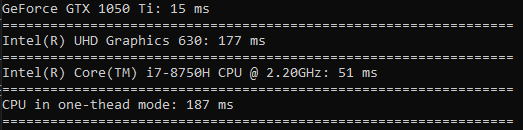
The time spent on squaring is even less of a difference than sorting (GPU is only 3.5 times faster).

Conclusion
So, after reading this article, you learned how to use asynchronous functions to copy arrays and fill them. We learned in what ways you can use your own functions to perform calculations on data. And also clearly saw when it is worth using a GPU or CPU for parallel computing, and when you can get by with one thread.
I would be glad to receive positive feedback, thanks for your time!
Good luck to all!