1 What is the Voynich manuscript?
The Voynich manuscript is a mysterious manuscript (codex, manuscript or just a book) in a good 240 pages that came to us, presumably, from the 15th century. The manuscript was accidentally acquired from an antiquarian by the husband of the famous Carbonarian writer Ethel Voynich - Wilfred Voynich - in 1912 and soon became the property of the general public.
The language of the manuscript has not yet been determined. A number of researchers of the manuscript suggest that the text of the manuscript is encrypted. Others are sure that the manuscript was written in a language that has not survived in the texts known to us today. Still others consider the Voynich manuscript to be nonsense (see the modern hymn to the absurdism Codex Seraphinianus ).
As an example, I will give a scanned fragment of a subject with text and nymphs:

2 Why is this outlandish manuscript so interesting?
Maybe this is a late forgery? Apparently not. Unlike the Turin Shroud, neither radiocarbon analysis nor other attempts to dispute the antiquity of the parchment have yet given an unambiguous answer. But Voynich could not have foreseen isotope analysis at the very beginning of the 20th century ...
But what if the manuscript is a meaningless set of letters from the pen of a playful monk, a nobleman in an altered consciousness? No, definitely not. Thoughtlessly slapping on the keys, for example, I will depict everyone's familiar modulated QWERTY-keyboard white noise like “ asfds dsf”. A graphological examination shows that the author wrote with a firm hand the symbols of the alphabet well-known to him. Plus, the correlations of the distribution of letters and words in the text of the manuscript correspond to the “living” text. For example, in a manuscript, conditionally divided into 6 sections, there are words - "endemic", often found in one of the sections, but absent in others.
But what if the manuscript is a complex cipher, and attempts to break it are theoretically meaningless? If we take on faith the venerable age of the text, the encryption version is extremely unlikely. The Middle Ages could have offered only a substitution cipher, which Edgar Allan Poe broke so easily and elegantly . Again, the correlation of letters and words of the text is not typical for the vast majority of ciphers.
Despite the colossal successes in translating ancient scripts, including with the use of modern computing resources, the Voynich manuscript still defies either experienced professional linguists or young ambitious data scientists.
3 But what if the language of the manuscript is known to us
... but the spelling is different? Who, for example, recognizes Latin in this text ?

And here is another example - transliteration of an English text into Greek:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονPython's Transliterate library . NB: this is no longer a substitution cipher - some multi-letter combinations are transmitted in one letter and vice versa.
I will try to identify (classify) the language of the manuscript, or find the closest relative to it from the known languages, highlighting the characteristic features and training the model on them:
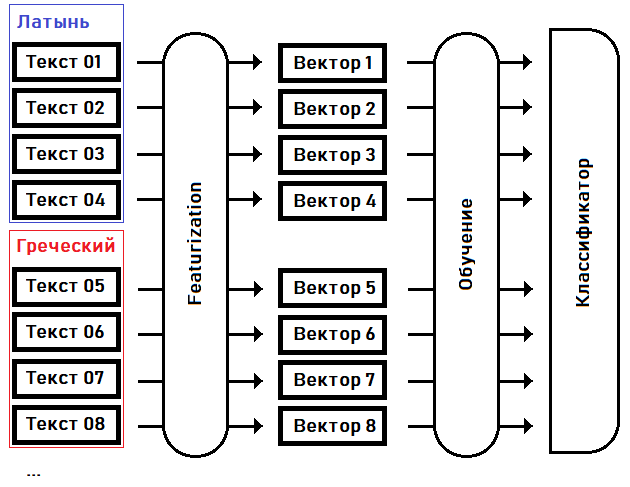
At the first stage - featurization- we turn texts into feature vectors: fixed-size arrays of real numbers, where each dimension of the vector is responsible for its own special feature (feature) of the source text. For example, let us agree in the 15th dimension of the vector to keep the frequency of the most common word in the text, in the 16th dimension - the second most popular word ... in the Nth dimension - the longest length of a sequence of the same repeated word, etc.
At the second step - training - we select the coefficients of the classifier based on the prior knowledge of the language of each of the texts.
Once the classifier is trained, we can use this model to determine the language of the text that was not included in the training sample. For example, for the text of the Voynich manuscript.
4 The picture is so simple - what's the catch?
The tricky part is how exactly to turn a text file into a vector. Separating the wheat from the chaff and leaving only those characteristics that are characteristic of the language as a whole, and not each specific text.
If, to simplify, turn the source texts into encoding (ie numbers), and “feed” this data as it is to one of the many neural network models, the result will probably not please us. Most likely, a model trained on such data will be tied to the alphabet and it is on the basis of symbols that, first of all, it will try to determine the language of an unknown text.
But the alphabet of the manuscript "has no analogues." Moreover, we cannot fully rely on patterns in the distribution of letters. Theoretically, it is also possible to transfer the phonetics of one language by the rules of another (the language is Elvish - and the runes are Mordor).
The cunning scribe did not use any punctuation marks or numbers as we know it. The entire text can be thought of as a stream of words, divided into paragraphs. There is not even certainty about where one sentence ends and another begins.
This means that we will rise to a higher level in relation to letters and will rely on words. Let's compose a dictionary based on the text of the manuscript and trace the patterns already at the word level.
5 Original text of the manuscript
Of course, you don't need to encode the intricate characters of the Voynich manuscript into their Unicode equivalents and vice versa yourself - this work has already been done for us, for example, here . With the default options, I get the following equivalent to the first line of the manuscript:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-Periods and exclamation marks (as well as a number of other characters in the EVA alphabet ) are just separators, which for our purposes can be replaced with spaces. Question marks and asterisks are unrecognized words / letters.
For verification, let's substitute the text here and get a fragment of the manuscript:
6 Program - text classifier (Python)
Here is a link to the code repository with the minimum README hints you need to test the code in action.
I collected 20+ texts in Latin, Russian, English, Polish, and Greek, trying to maintain the volume of each text in ± 35,000 words (the volume of the Voynich manuscript).
I tried to select close dating in the texts, in one spelling - for example, in Russian-language texts I avoided the letter Ѣ, and variants of writing Greek letters with different diacritics led to a common denominator. I also removed numbers, specials from the texts. characters, extra spaces, converted letters to one case.
The next step is to build a "dictionary" containing information such as:
- frequency of use of each word in the text (texts),
- The "root" of a word - or rather, an unchangeable, common part for a set of words,
- common "prefixes" and "endings" - or rather, the beginning and end of words, together with the "root" constituting the actual words,
- common sequences of 2 and 3 identical words and the frequency of their occurrence.
I took the “root” of the word in quotes - a simple algorithm (and sometimes I myself) is not able to determine, for example, what is the root of the word support? By becoming ka? Under the rate ?
Generally speaking, this vocabulary is half-prepared data for building a feature vector. Why did I single out this stage - compiling and caching dictionaries for individual texts and for a set of texts for each of the languages? The fact is that such a dictionary takes a long time to build, about half a minute for each text file. And I already have over 120 text files.
7 Featurization
Obtaining a feature vector is just a preliminary stage for further magic of the classifier. As an OOP freak, of course, I created an abstract BaseFeaturizer class for the upstream logic, so as not to violate the principle of dependency inversion . This class bequeaths to descendants to be able to transform one or many text files at once into numeric vectors.
And the inheritor class must give each individual feature (the i-coordinate of the feature vector) a name. This will come in handy if we decide to visualize the machine logic of the classification. For example, the 0th dimension of the vector will be marked as CRw1 - autocorrelation of the frequency of the use of words taken from the text at the adjacent position (with a lag of 1).
From the BaseFeaturizer class , I inherited the classWordMorphFeaturizer , the logic of which is based on the frequency of the use of words throughout the text and within a sliding window of 12 words.
An important aspect is that the code of a specific successor to BaseFeaturizer, in addition to the texts itself, also needs dictionaries prepared on their basis (the CorpusFeatures class ), which are most likely already cached on disk at the time of the start of training and testing the model.
8 Classification
The next abstract class is BaseClassifier . This object can be trained and then classify texts by their feature vectors.
For the implementation (the RandomForestLangClassifier class ), I chose the Random Forest Classifier algorithm from the sklearn library . Why this particular classifier?
- Random Forest Classifier suited me with its default parameters,
- it does not require normalization of the input data,
- offers a simple and intuitive visualization of the decision-making algorithm.
Since, in my opinion, the Random Forest Classifier coped well with its task, I have not written any other implementations.
9 Training and testing
80% of the files - large fragments from the opuses of Byron, Aksakov, Apuleius, Pausanias and other authors, whose texts I could find in txt format - were randomly selected to train the classifier. The remaining 20% (28 files) are determined for out-of-sample testing.
While I tested the classifier on ~ 30 English and 20 Russian texts, the classifier gave a large percentage of errors: in almost half of the cases, the language of the text was determined incorrectly. But when I started ~ 120 text files in 5 languages (Russian, English, Latin, Old Hellenic and Polish), the classifier stopped making mistakes and began to recognize correctly the language of 27 - 28 files from 28 test cases.
Then I complicated the problem a little: I transcribed the 19th century Irish novel "Rachel Gray" into Greek and submitted it to a trained classifier. The language of the text in transliteration was again correctly defined.
10 The classification algorithm is clear
This is how one of 100 trees in the trained Random Forest Classifier looks like (to make the image more readable, I cut off 3 nodes of the right subtree):
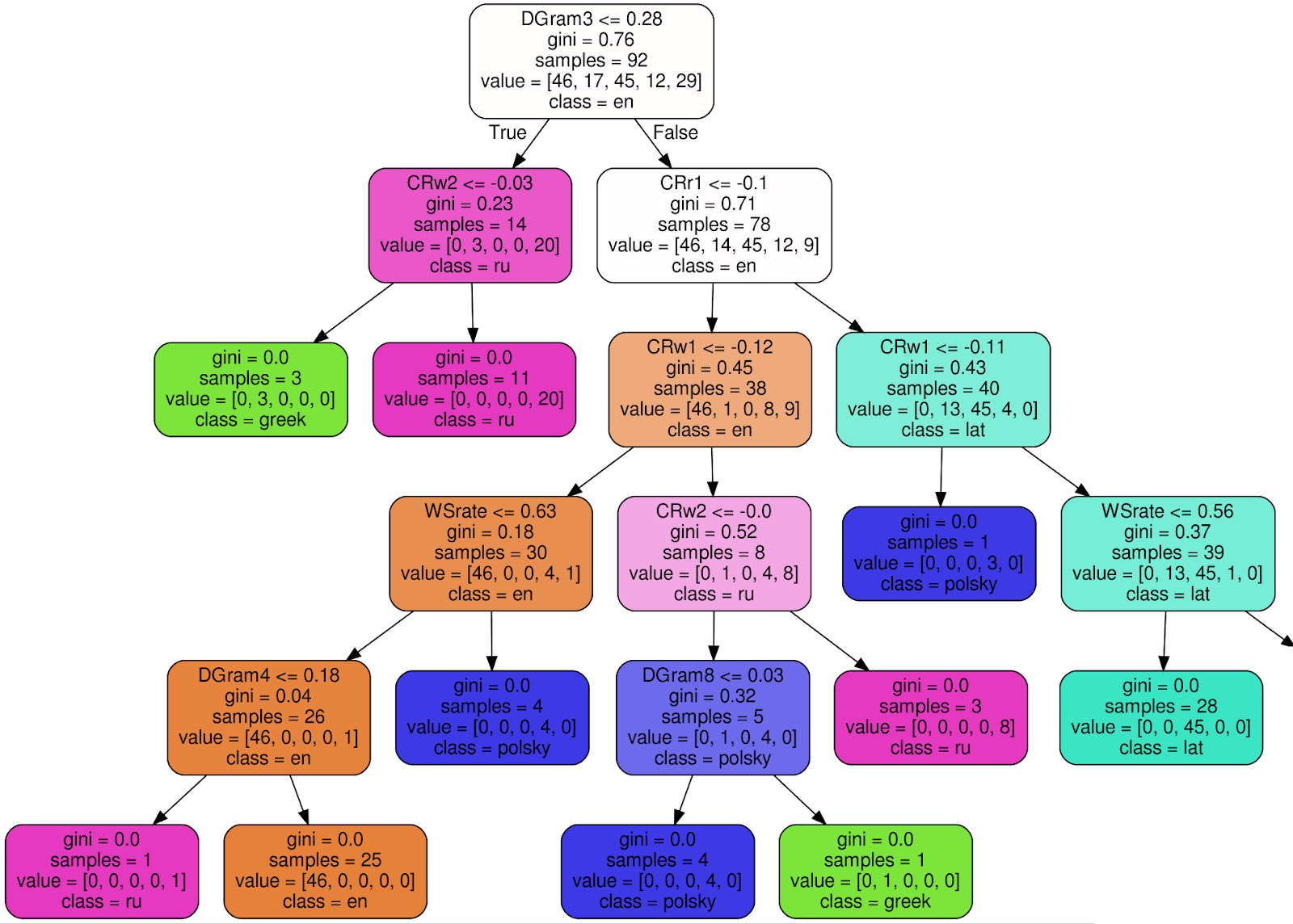
Using the root node as an example , I will explain the meaning of each signature:
- DGram3 <= 0.28 - classification criterion. In this case, DGram3 is a specific dimension of a feature vector named by the WordMorphFeaturizer class, namely, the frequency of the third most common word in a sliding window of 12 words,
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
If the criterion (DGram3 <= 0.28 for the root node) is met, go to the left subtree, otherwise - to the right. In each sheet, all texts should be assigned to one class (language) and the Gini uncertainty criterion ≡ 0. The
final decision is made by an ensemble of 100 similar trees built during training of the classifier.
11 And how did the program define the language of the manuscript?
Latin , probability estimate 0.59. And, of course, this is not yet the solution to the problem of the century.
A one-to-one correspondence between the manuscript dictionary and the Latin language is not easy - if not impossible. For example, here are ten of the most frequently used words: Voynich manuscripts, Latin,

Ancient Greek and Russian:
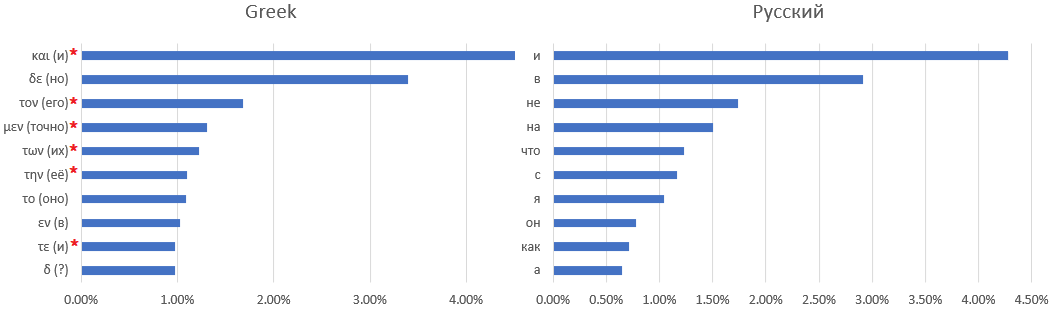
Words that are difficult to find a Russian equivalent for are marked with an asterisk - for example, articles or prepositions that change meaning depending on the context.
An obvious match like
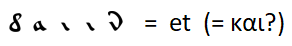
with the extension of the rules for replacing letters with other frequently used words, I could not find. You can only make assumptions - for example, the most common word is the conjunction "and" - as in all other languages considered except English, in which the conjunction "and" was pushed into second place by the definite article "the".
What's next?
First, it is worth trying to supplement the sample of languages with texts in modern French, Spanish, ..., Middle Eastern languages, if possible - Old English, French languages (before the 15th century) and others. Even if none of these languages is the language of the manuscript, the accuracy of the definition of known languages will still increase, and a closer equivalent will probably be selected to the language of the manuscript.
A more creative challenge is to try to define a part of speech for each word. For a number of languages (of course, first of all - English) PoS (Part of Speech) tokenizers as part of packages available for download do this task well. But how to determine the roles of words in an unknown language?
Similar problems were solved by the Soviet linguist B.V. Sukhotin - for example, he described the algorithms:
- separation of characters of an unknown alphabet into vowels and consonants - unfortunately, not 100% reliable, especially for languages with non-trivial phonetics, such as French,
- selection of morphemes in the text without spaces.
For PoS tokenization, we can start from the frequency of the use of words, occurrence in combinations of 2/3 words, the distribution of words over sections of the text: unions and particles should be distributed more evenly than nouns.
Literature
I will not leave here links to books and tutorials on NLP - that's enough on the net. Instead, I will list works of art that became a great find for me as a child, where the heroes had to work hard to unravel the encrypted texts:
- E. A. Poe: The Golden Beetle is a timeless classic
- V. Babenko: “Meeting” is a famously twisted, somewhat visionary detective story of the late 80s,
- K. Kirita: “Knights from Chereshnevaya Street, or the Castle of the Girl in White” is a fascinating teenage novel, written without discount for the age of the reader.