Google: 90% of our engineers use a program you wrote (Homebrew), but you can't invert a binary tree on a board, so goodbye.
Although I have never had a need for inverting a binary tree, I came across examples of real use of data structures and algorithms in my daily work when I worked at Skype / Microsoft, Skyscanner and Uber . This included coding and decision making based on the specifics of data structures and algorithms. But I, for the most part, used the relevant knowledge in order to understand how certain systems were created, and why they were created that way. Knowledge of the relevant concepts makes it easier to understand the architecture and implementation of the systems in which these concepts are used.

In this article, I have included stories about situations in which data structures such as trees and graphs, as well as various algorithms, have been used in real projects. Here I hope to show the reader that a basic knowledge of data structures and algorithms is not a useless theory needed only for interviews, but something that is very likely to be really needed by someone who works in fast-growing innovative technology companies.
Here we will talk about a very small number of algorithms, but as far as data structures are concerned, I can note that I will touch on almost all of them here. It should come as no surprise to anyone that I am not a fan of the kind of interview questions that over-emphasize algorithms that are out of touch with practice and target exotic data structures like red-black trees or AVL trees. I have never asked such questions in interviews and will not ask them. At the end of this article, I will share my thoughts on such interviews. But despite the above, knowledge of the underlying data structures is of immense value. This knowledge allows you to select exactly what is needed to solve certain practical problems.
Now let's move on to examples of using data structures and algorithms in real life.
Trees and tree traversal: Skype, Uber and UI frameworks
When we were developing Skype for Xbox One, the code had to be written for a pure Xbox OS that didn't have the libraries we needed. We developed one of the first full-blown applications for this platform. We needed an application navigation system that could be operated using both the touch screen and giving voice commands to the application.
We've created a basic WinJS based navigation framework. In order to do this, we needed to maintain a DOM-like graph, which was required to organize the observation of the elements with which the user could interact. To find such elements, we performed DOM traversal, which boiled down to tree traversal, that is, the existing structure of DOM elements. This is a classic example of BFS or DFS (breadth-first search or depth-first search - breadth-first search or depth-first search).
If you are doing web development, this means that you are already working with a tree structure, namely the DOM. All DOM nodes can have child nodes. The browser displays the nodes after traversing the DOM tree. If you need to find a specific element, you can use the built-in DOM methods to solve this problem. For example, the getElementById method. An alternative is to develop your own BFS or DFS solution to traverse the nodes and find what you need. For example, something similar is done here .
Many frameworks that render UI elements use tree structures in their depths. So, React supports virtual DOM and uses a smart reconciliation algorithm(comparisons). This allows you to achieve high performance due to the fact that only the changed parts of the interface are re-rendered. A visualization of this process can be found here.
In mobile architecture Uber, RIBs, trees are also used. This makes this architecture similar to most other UI frameworks that display hierarchical structures of elements. The RIBs architecture maintains a RIB tree for state management purposes. Attaching RIBs to it and detaching them from it controls their rendering. While working with RIBs, we sometimes sketched, trying to understand if the RIBs fit into the existing hierarchy, and discussed whether the RIBs in question should have visible elements. That is, they talked about whether this structure will take part in the formation of the visual presentation of the interface, or it will be used only for state management.

State transitions when using RIBs. You can find more details about RIBs here.
If you ever need to render hierarchical elements, be aware that tree structures are usually used for this, traversing them and rendering visited elements. I have come across many internal tools that take this approach. An example of such a tool is the RIBs renderer created by the Mobile Platform team at Uber. Here is a report on this topic.
Weighted graphs and shortest path finder: Skyscanner
Skyscanner is a project that aims to find the best deals on air tickets. The search for such proposals is carried out by viewing and analyzing all routes existing in the world and combining them. The essence of this task is more related to the automatic data collection by a search robot, and not to caching all this data, since airlines independently calculate the waiting time for the next flight. But the possibility of planning a trip to visit several cities comes down to the task of finding the shortest path.
Multi-city travel planning was one of the possibilities that Skyscanner took a long time to implement. At the same time, the difficulties mainly related to the system being developed itself. The best deals of this kind are found using shortest-path algorithms like Dijkstra's or A *. Flight routes are presented in the form of a directed graph. Each of its edges is assigned a weight in the form of a ticket price. When searching for the best route, finding the cheapest route between two cities is performed using the implementation of the modified A * algorithm . If you are interested in the topic of selecting air tickets and finding the shortest routes, then here is a good article on using BFS to solve such problems.
However, in the case of Skyscanner, which algorithm was used to solve the problem was not particularly important. Caching, using search robots, organizing work with various sites - all this was much more difficult than choosing an algorithm. But at the same time, different variants of the problem of finding the shortest path arise in many different travel planning companies and optimizing the cost of such trips. Unsurprisingly, this topic has been the subject of behind-the-scenes talk at Skyscanner as well.
Sort: Skype (or something like that)
I rarely had a reason to implement sorting algorithms myself or to deeply study the intricacies of their structure. But despite this, it was interesting to understand how such algorithms work - from bubble sort, insertion sort, merge sort and selection sort, to the most complex algorithm - quicksort. I've found that there is rarely a need to implement such algorithms, especially if you don't need to write a sort function that is part of a library.
In Skype, however, I had to resort to the practical use of my knowledge of sorting algorithms. One of our programmers decided to implement sorting by inserts to display contacts. In 2013, when Skype was online, contacts were downloaded in batches. It took some time to download them all. As a result, that programmer thought that it would be better to build a list of contacts sorted by name using insertion sort. We discussed this algorithm a lot, thinking about why not just use something that has already been implemented. As a result, it took us the most time to properly test our algorithm implementation and check its performance. Personally, I didn't see much point in creating my own implementation of this algorithm. But then the project was at such a stagewhere we had time for such things.
Of course, there are real-world situations in which efficient sorting plays a very important role in a project. And if the developer can independently, based on the features of the data, choose the most suitable algorithm, this can give a noticeable increase in the performance of the solution. Insertion sort can be very useful where you work with large datasets transmitted somewhere in real time, and immediately visualize this data. Merge Sort can work well for divide and conquer approaches when dealing with large amounts of data stored in different nodes. I have never worked with such systems, so for now I continue to consider sorting algorithms as something that has limited use in everyday work. It's true,it is not about the importance of understanding how the different sorting algorithms work.
Hash tables and hashing: everywhere
The data structure I use regularly is a hash table. This also includes hash functions. This is a very useful tool that can be used to solve a variety of tasks - from counting the number of certain entities, detecting duplicates, caching, to scenarios like sharding used in distributed systems . Hash tables are, after arrays, the most common data structure in programming. I've used it in countless situations. It is present in almost all programming languages, and if necessary, you can simply implement it yourself.
Stacks and queues: from time to time
The stack is a data structure that is familiar to anyone who has debugged code written in a language that supports stack traces. If we talk about the stack as a data structure, then, in the course of work, I encountered several problems for the solution of which it was needed. But it should be noted that I got to know the stacks properly while debugging and profiling code performance. Stacks are also a natural choice for the data structure to use when doing DFS.
I rarely had to resort to using queues, but I encountered them quite often in the codebases of various projects. Let's say that something was placed in the queue and something was retrieved from it. Typically, queues are used to implement breadth-first tree traversal, and they are ideal for this task. Queues can be used in many other situations as well. Once I came across some job scheduling code in which I found an example of a decent use of the priority queue , implemented by the Python module heapq , when the shortest jobs were executed first.
Cryptographic Algorithms: Uber
Important data that users enter into mobile apps or web apps must be encrypted before being transmitted over the network. And they decrypt them only where they are needed. In order to organize such a scheme of work, the implementation of cryptographic algorithms must be present on the client and server parts of the applications.
Understanding cryptographic algorithms is very interesting. At the same time, you should not offer your own algorithms for solving certain problems. This is one of the worst ideas a programmer can think of. Instead, it takes an existing, well-documented standard and uses the native primitives of the respective frameworks. Usually, AES acts as the standard chosen when implementing cryptographic solutions.... It is secure enough to use it to encrypt classified information in the United States . There are no known working attacks on the protocol. AES-192 and AES-256 are usually quite reliable for most practical tasks.
When I came to Uber, the mobile encryption system and the encryption system of the web application were already implemented, they were based on the mechanisms described above, so I had an excuse to study the details about AES (Advanced Encryption Standard), about HMAC (Hashed Message Authentication Codes) , about the RSA algorithm and other such things. It was also interesting to get to the understanding of how the cryptographic strength of the sequence of actions used in encryption is proved. For example, if we talk about authenticated encryption with attached data, it turns out that analyzing the encrypt-and-MAC, MAC-then-encrypt and encrypt-then-MAC modes, it is possible to prove the cryptographic strength of only one of them , although this does not mean that the rest are not cryptographically secure.
You will hardly ever need to implement cryptographic primitives yourself, unless you are implementing a completely new cryptographic framework. But you may well be faced with the need to make decisions about which primitives to use and how to combine them. You may also need knowledge in the field of cryptographic algorithms in order to understand why a certain system uses a certain approach to data encryption.
Decision trees: Uber
While working on one of the projects, we had to implement complex business logic in a mobile application. Namely, based on half a dozen rules, one of several screens had to be shown. These rules were very complex because the results of the test sequence and the user's preference had to be taken into account.
The programmer who started solving this problem first tried to express all these rules in the form of if-else statements. This resulted in extremely confusing code. As a result, it was decided to use the decision tree. With his help, it was easy to carry out all the necessary checks. It was relatively easy to implement. In addition, if necessary, it could be changed without much problem. We needed to create our own implementation of the decision tree, such that conditions are checked on its edges. This is all we needed from this tree. While we could have saved the time spent implementing the tree by taking a different approach, the team decided that the particular tree would be easier to maintain, and went to work. This tree looks like this:the edges symbolize the results of checking the conditions (these are binary results, or the results represented by ranges of values), and the leaf nodes of the tree describe the screens to which you need to navigate.
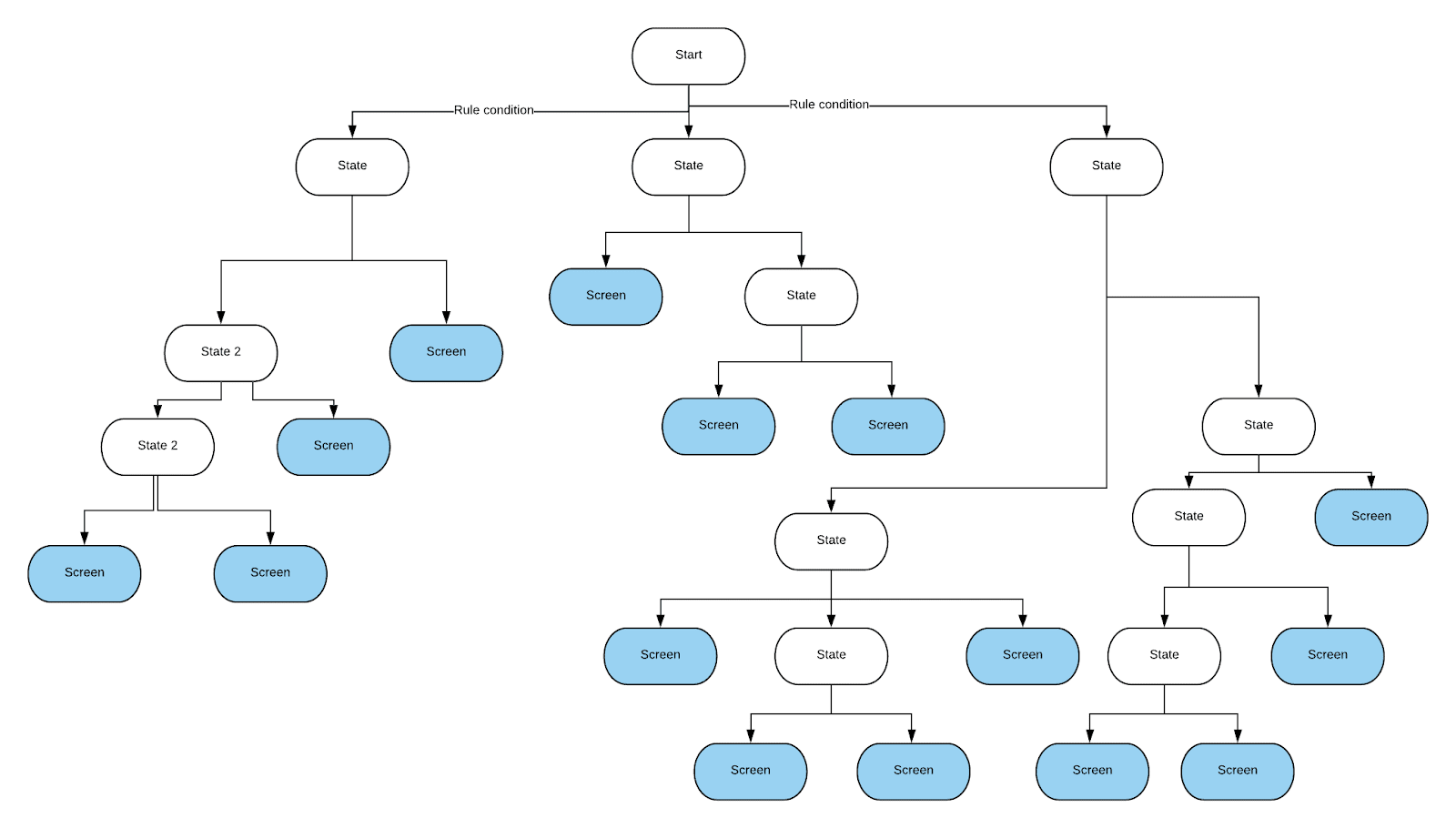
, , .
The build system for Uber's mobile app, called SubmitQueue, also used a decision tree, but it was generated dynamically. The Developer Experience team had to tackle the difficult problem of performing a daily merge of hundreds of source branches with the target branch. At the same time, each assembly took about 30 minutes to complete. This included compiling, running unit and integration tests, and interface tests. Parallelizing assemblies was not a good enough solution, as there were often overlapping changes in different assemblies, which caused merge conflicts. In practice, this meant that sometimes programmers had to wait 2-3 hours, resort to rebase, and restart the merging process again, hoping that this time they would not face a conflict.
The Developer Experience team took an innovative approach to predict merge conflicts and queue assemblies accordingly. This was done using a special binary decision tree (speculation tree).

SubmitQueue uses a binary decision tree with edges annotated with predicted probabilities. This approach allows you to determine which sets of assemblies can be run in parallel. This is done in order to reduce the time between receiving and executing tasks and in order to increase the throughput of the system. In this case, only fully tested and workable code should get into the master branch. The
Developer Experience team who created this system have written excellent material about it. But here- another article on the same topic, well illustrated. The result of the introduction of this system was the creation of a much faster project assembly system than before. It allowed us to optimize the build time of projects and helped make the lives of hundreds of mobile programmers easier.
Hexagonal grids, hierarchical indexes: Uber
This is the last project that I want to talk about here. It was completely based on one particular data structure. It was by doing it that I learned about this data structure. We are talking about a hexagonal grid with hierarchical indices.
One of the most challenging and interesting problems at Uber was the optimization of the cost of travel and the distribution of orders among partners. Rates for trips can change dynamically, drivers are constantly on the move. Uber engineers created the H3 grid system. It is designed to visualize and analyze data across cities at different scales. The data structure that is used to solve the above problems is a hexagonal grid with hierarchical indices. A couple of specialized internal tools are used to visualize the data.

Splitting the map into hexagonal cells
This data structure has its own indexing system, traversal, its own definitions of individual areas of the grid, its own functions. A detailed description of all this can be found in the documentation for the corresponding API. Read more about H3 here . Here is the source code. Here you can find a story about how and why this system was created.
Experience with this system allowed me to get a feel for the fact that creating your own specialized data structures can make sense when solving very specific problems. There are very few problems in the solution of which you can apply a hexagonal grid, if you do not take into account the division into map fragments with a comparison with each resulting data fragment of different levels. But, as in other cases, if you are familiar with other data structures, this will be much easier to understand. And for a person who has dealt with a hexagonal grid, it will be easier to create a new data structure designed to solve problems similar to those that are solved using such a grid.
Data structures and algorithms in interviews
Above, I talked about what data structures and algorithms I encountered while working in various companies for a long time. I propose now to return to that tweet by Max Howell, which I mentioned at the very beginning of the article. There, Max complained that in a Google interview he was asked to invert a binary tree on a board. He didn't. He was shown the door. In this situation, I am on Max's side.
I believe that knowing how popular algorithms work, or how exotic data structures work, is not the kind of knowledge you need to work for a tech company. You need to know what an algorithm is, you need to be able to independently come up with simple algorithms, for example, working on the "greedy" principle. You also need to have knowledge of the most common data structures like hash tables, queues, and stacks. But something quite specific, like Dijkstra's algorithm or A *, or something even more complex, is not something that needs to be learned by heart. If you really need these algorithms, you can easily find reference materials on them. For example, if we talk about algorithms that are not related to sorting algorithms, I usually tried to understand them in general terms and understand their essence.The same goes for exotic data structures like red-black trees and AVL trees. I have never had a need to use them. And if I needed them, I could always refresh my knowledge about them by resorting to the appropriate publications. When interviewing, as I said, I never ask such questions, and I do not plan to ask them.
I am in favor of practical problems related to programming, in solving which you can apply a variety of approaches: from methods of "brute force" and "greedy" variants of algorithms to more advanced algorithmic ideas. For example, I think it is perfectly okay to have a text alignment task like this . For example, I had to solve this problem when creating a component for rendering text on Windows Phone. You can solve this problem simply by using an array and a few if-else statements, without resorting to some tricky data structures.
In fact, many teams and companies exaggerate the importance of algorithmic problems. I understand the attractiveness of the algorithm questions. They allow you to evaluate the applicant in a short time, the questions are easy to redo, which means that if the questions that were asked to someone become public, it will not cause any special problems. Algorithm questions are good for organizing trials for a large number of applicants. For example, you can create a pool of over a hundred questions and distribute them randomly to applicants. Questions regarding dynamic programming and exotic data structures are becoming more and more common. Especially in Silicon Valley. These questions can help companies hire strong programmers. But these same questions can close the way in the company to those people who have succeeded in business,where deep knowledge of algorithms is not needed.
If you are from a company that only hires people who have a deep knowledge of complex algorithms almost from birth, I suggest that you think carefully about whether these are the people you need. For example, I hired great teams at Skyscanner (London) and Uber (Amsterdam) without asking tricky algorithm questions. I have limited myself to the most common data structures and to test the capabilities of the interviewees related to problem solving. That is, they needed to know about common data structures and be able to come up with simple algorithms to solve the problems they face. Data structures and algorithms are just tools.
Bottom line: data structures and algorithms are tools
If you work for a dynamic, innovative technology company, then you will probably encounter implementations of a wide variety of data structures and algorithms in the code of the products of this company. If you are developing something completely new, then you often have to look for data structures that make it easier to solve the problems you face. In situations like this, you need a general knowledge of algorithms and data structures and their pros and cons to make the right choice.
Data structures and algorithms are tools that you should use with confidence when writing programs. When you know these tools, you will see a lot of what you already know in the codebases that use them. In addition, such knowledge will allow you to solve complex problems with much more confidence. You will be aware of the theoretical limitations of algorithms and how they can be optimized. This will help you ultimately arrive at a solution that, with all the necessary trade-offs, turns out to be as good as possible.
If you'd like to get a better understanding of data structures and algorithms, here are some tips and resources:
- -, , , , , , . , , . , . — , .
- « ». , , , . — , , . , , , .
- Here are a couple more books: “ Algorithms. Development Guide "and" Algorithms in Java, 4th Edition ". I used them to refresh my university knowledge of algorithms. True, I haven't read them to the end. They seemed to me rather dry and inapplicable to my daily work.
What data structures and algorithms have you encountered in practice?
