
Friends, hello everyone! My name is Kolya Arkhipov, I am responsible for Research & Development at Delivery Club.
Our team solves science-intensive tasks within the FoodTech platform: we develop components based on algorithms and data, of which there are many in the DC platform. In the process of solving, we are faced with many uncertainties from both the business and development sides.
The material turned out to be voluminous and, I hope, useful for you. Therefore, I recommend putting in a teapot and brewing delicious coffee, I did this myself while working on this article.
Today I will tell you about the race that our team has passed over the past year. The analogy arose by itself - we work in a very dynamic company, the market leader FoodTech in Russia. We are rapidly developing different areas of business, and it really drives! We not only came to the finish line successfully, but also got a lot of insights in the race. This is what I want to share with you.
The article appeared after the report at the RIT ++ 2020 conference . For those who love video, look for it at the end of the article.
Is the kettle boiling already? Super! So, what will be discussed today:
- R&D and uncertainty. What we faced.
- Experiments. How and why do we conduct them in battle.
- Measurability. Let's discuss the choice of metrics and work with risks.
- Autonomy. How we at DC Tech adapted the GIST framework and the Inner Source approach.
Green light, clutch, first - let's go.
R&D and uncertainty
In some companies, the R&D team is engaged in fundamental research of new technologies. The purpose of such research can be both the development of current processes and completely new verticals in business. For example, blockchain was such a technology a few years ago.
Immediately, we are talking about something else. R&D at Delivery Club is about solving applied problems. Our business is growing rapidly, the number of orders is growing, and most of our internal processes are based on data and algorithms. With an increase in the amount of input data, some algorithms cease to be effective, and those components that completely suited us yesterday, today we often find inoperable.
As you may have guessed, such problems are often weakly deterministic, and, as a result, are accompanied by many uncertainties from all sides. Let's highlight the key ones:

Let's take a closer look at what we are facing, and whether these are really difficulties.
How to achieve the goal
We always clearly understand the business goal - in which direction we plan to move, where we must go. But it is far from always immediately clear how to approach this goal when it comes to research tasks. Which strategy to adopt: through experiments or a large rollout of the feature right away? Build environments with simulation or experiment in combat? The choice is big - the eyes run wide.
What exactly is worth doing
Okay, we understand the business goal and agreed on which strategy we will follow. It's time to decide on a specific set of features that we will take to work. How to choose them, what to include in the backlog, in what order: you need to determine not only "what exactly is worth doing", but also who will have the maximum expertise in our area.
When We Can Reach Our Goal
Timing is definitely super important for business. Research is cool and entertaining, you can look for new features in the data, research algorithms, read interesting notes from our colleagues in other countries. But it is important for business to understand when the goal will be achieved, because a feature launched at the wrong time is often simply not needed - the FoodTech market is so dynamic now.
Why does anyone need my code at all
The last uncertainty, but far from being significant, is a matter of motivating developers. R&D is largely experimental development, as a result, our code does not always take root in production. At first, we were very upset because we did not understand why we made the feature, and with all our heart, and the business decides that it does not work and needs to be sawed off. Questions - why am I doing this? Why would anyone need my code? - appeared with us quite often. In the process, we realized how we can and should work with this, and now we are sure that this is one of the most critical uncertainties that needs to be overcome first of all.
And so, having filled such a decent bunch of bumps, we collected all our problems in one place and realized that for happiness we lack three processes at the intersection of these uncertainties.
- , , .
- . , , . , - , , .
- , , - . . IT- ( ), , , , 2-3 . — , .
Schematically in the picture below.
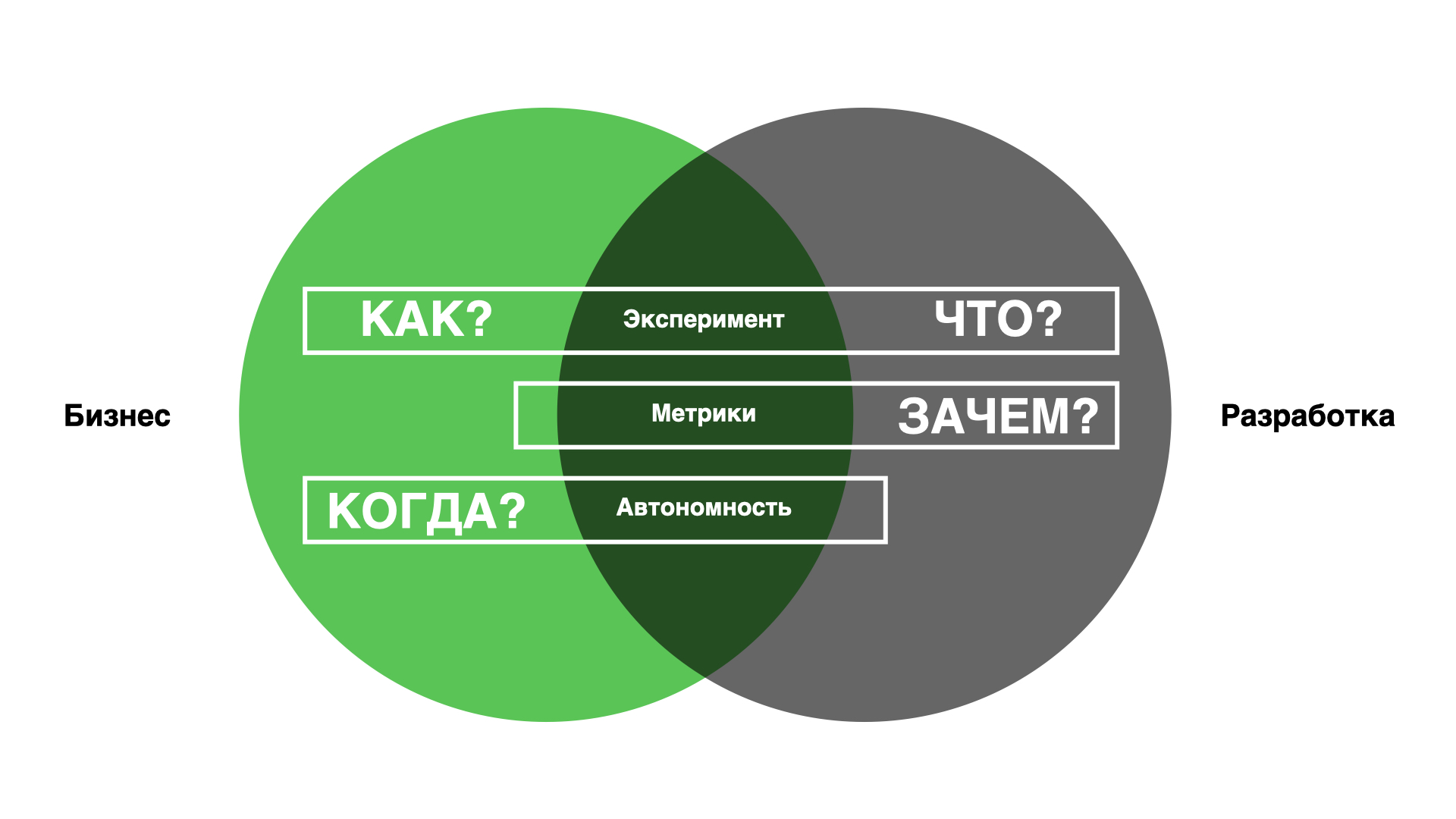
Experiments will answer the questions of how to achieve goals and what exactly to do. Metrics will make it possible to very clearly and transparently answer the question of whether this code should really remain in production. Full autonomy will help to assess and meet the deadlines.
We do not stop. Clutch, second gear, we are rapidly gaining momentum.
Experiments
Consider a custom courier auto-assignment platform. She has a fairly simple task - to bring together three market participants: our partners, logisticians (that is, their couriers) and customers, so that all participants are satisfied. That is, when an order arrives, we must choose a courier who will come to the restaurant exactly by the time the restaurant finishes preparing the dish, quickly picks it up and delivers it to the client hot and tasty at the time we promised.
Looks pretty straightforward, and here you might say - enough theory! It's time to move on to real launches.
I agree with you, but still let's dwell a little on the process of experiments. Let's look at the whole picture.
- - — . — , , .
- — . . — , .
- — Just In Time. , : , , . , , , . , FoodTech- : , . , .
Let's take a closer look at what process is under the hood of the product increment.

3.1 Hypothesis. It can be formulated in words or shown schematically. The main thing is to clearly justify why it should work at all. That is, the experiment must have theoretical training.
3.14 Development. I will not dwell here, more details about our development are described in this article . We use Scrum, two week iterations with all the required activities.
3.2 Preparation. Next, you need to prepare an experiment. That is, we need to decide on the geosegment or audience with which we want to communicate during this experiment. And also select the segment with which we will compare the results.
3.3 Experiment. Next, we start the experiment itself. An important point: even before the start, we agree on the business metrics that we will monitor. Let's leave today the discussion of technical metrics, which tell us that the experiment is launched and technically stable, we will talk more about business indicators. We will definitely fix the red flags - these are some threshold values that we should not cross during our experiment.
3.4 Analysis. We have accumulated a lot of cool, unique data that only we have. It would be strange not to extract useful information from them, that is, to draw reasonable conclusions about the validity of the hypothesis being tested, as well as to emphasize new things about the audience of our service.
3.5 Conclusion.Probably the most important point in this process. In our case, the output is always pressing three buttons:
- rollout the experiment further, to the next geography or the next segment of the audience;
- rollback if something went wrong;
- continue. There are cases when we see the influence of third-party factors, which we did not take into account, and as a result, we cannot draw an unambiguous conclusion. In these cases, we decide to continue.
Real experiment
It's finally time to see how this works with a real-world example. Are you tired yet? The fun begins.
Returning to the auto-assignment platform. Before that, we suggested that the Just In Time approach would be very cool for us to reduce delivery time. We will compare it with the current assignment strategy, which we denote as a greedy algorithm.
To begin with, we will justify the hypothesis.
Greedy algorithm
Its key feature is to prescribe immediately. As soon as the order arrives on the platform, we look for the most suitable courier of our partner for this order, appoint without delay and inform the courier about this order. As a result, we will optimize the time spent looking for a courier. But this approach is not always effective, because in a minute the situation may change: a new order arrives or another courier is released. The algorithm no longer reacts to this. Below is an illustration.
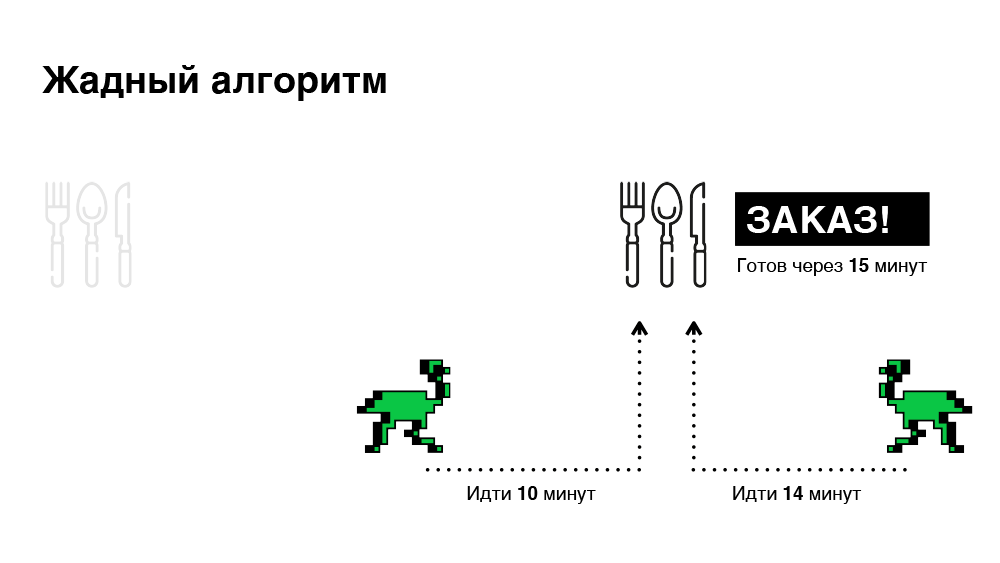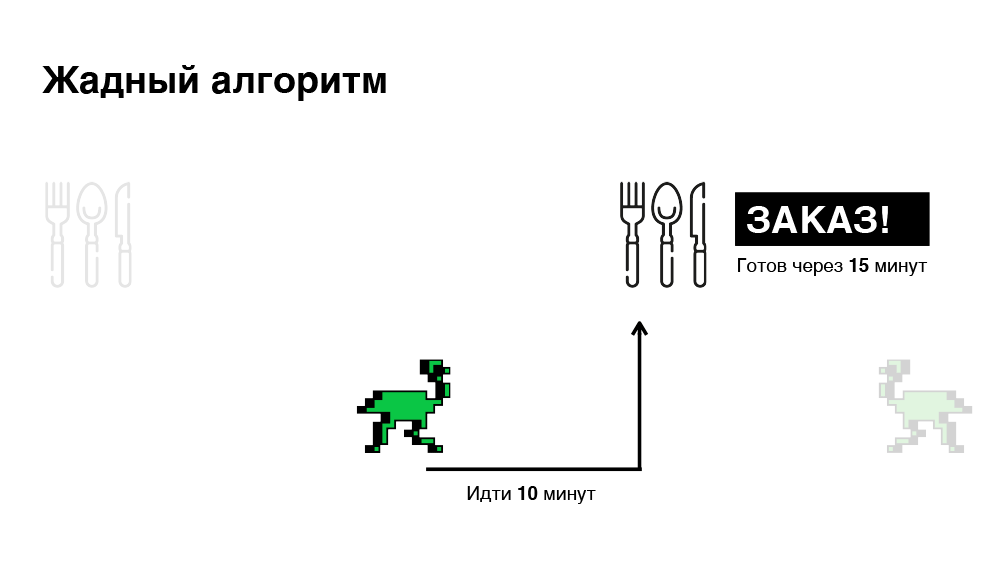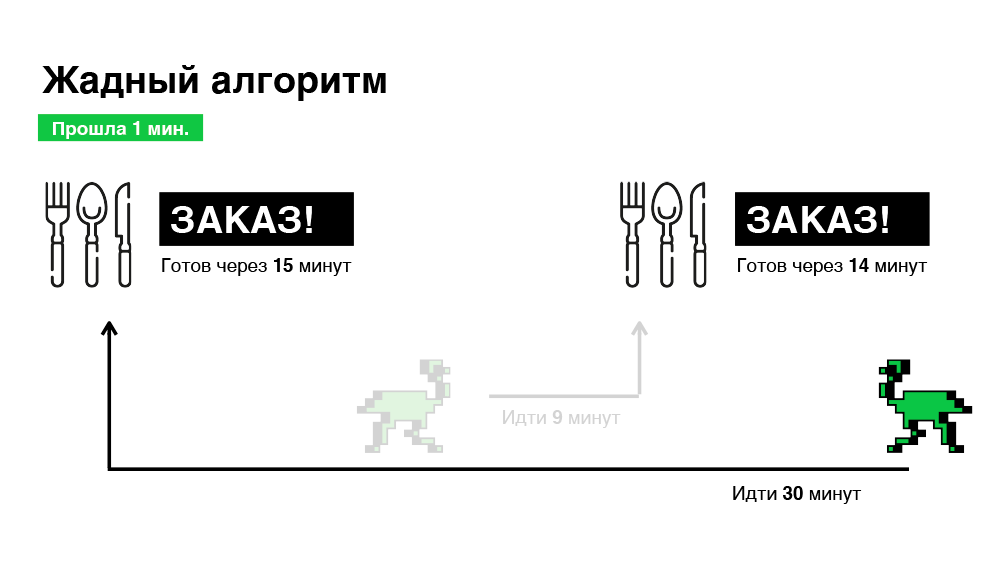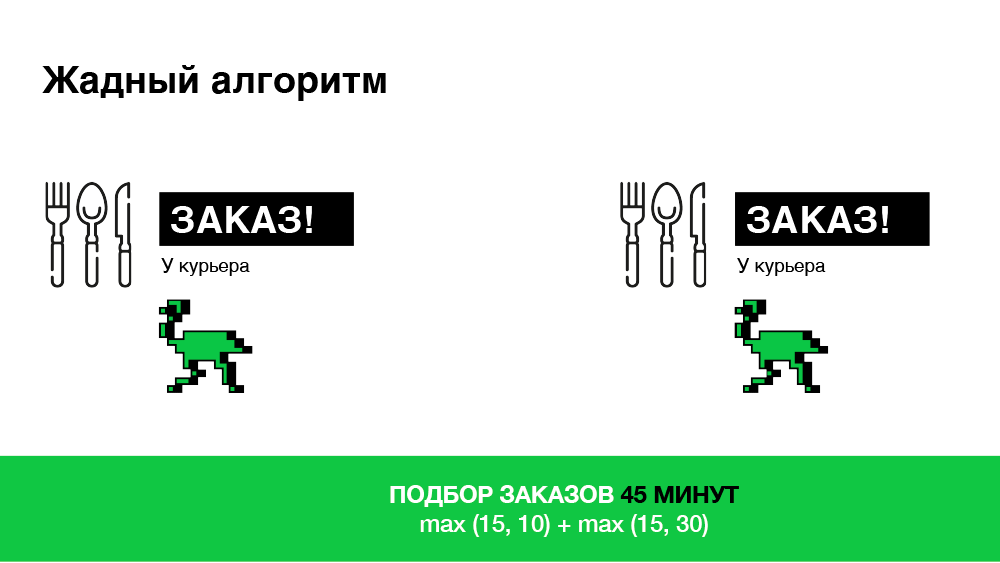
In this example, we get a total of 45 minutes to pick two orders. It seems we can do better.
Just in time
The task of this algorithm is to choose exactly the courier who will arrive at the restaurant exactly at the time the order is ready. What will it give us? It will ultimately reduce the delivery time due to the fact that:
- the courier will spend less time in the restaurant;
- we will choose the courier more optimally.
Technically, this is pretty straightforward to implement. When an order is received, we choose a courier right away, but we do not tell him about the order, thereby making a "virtual appointment" and giving ourselves time to change our choice. And we will finally decide (whether to transfer the order to the courier) only when the path to the restaurant is equal to the remaining time for preparing the order. Schematically - in the illustration below.
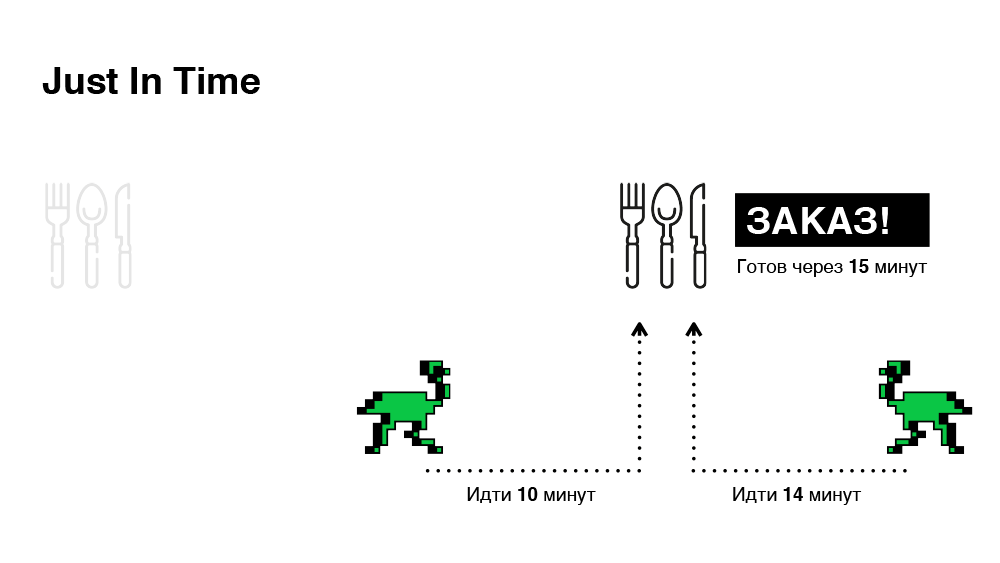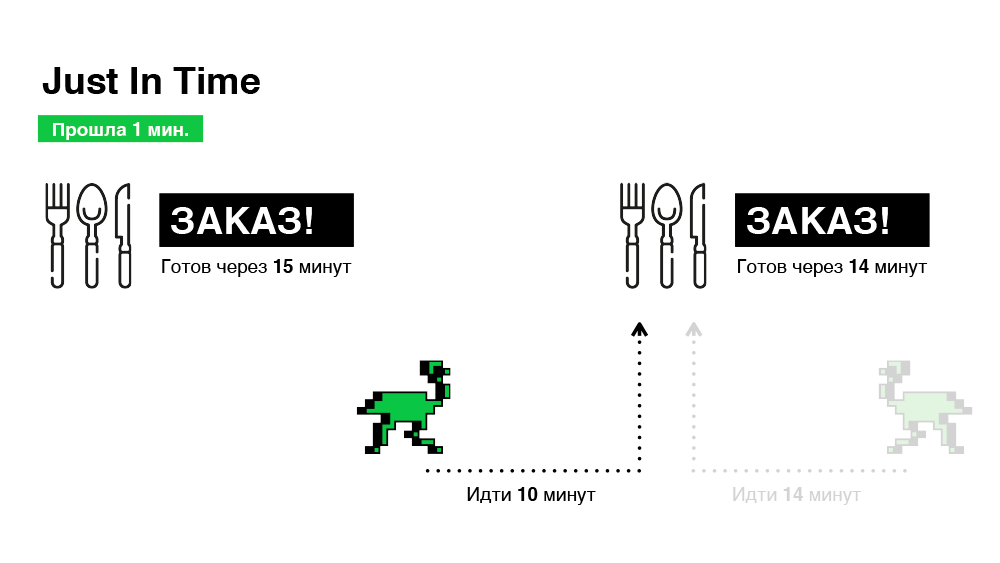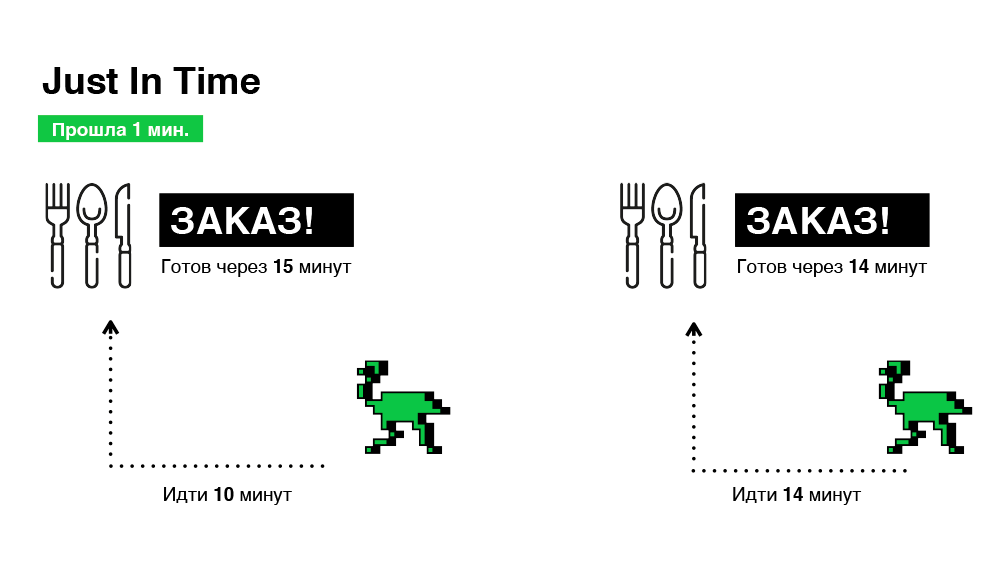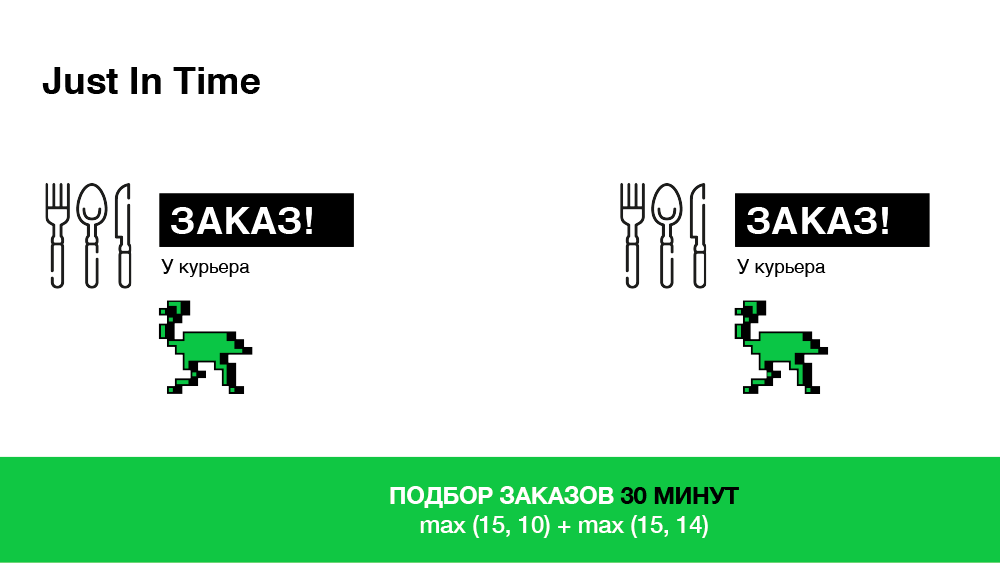
As a result, we select orders in only 30 minutes, which is one third less than in the previous case.
In my opinion, the hypothesis is justified, we are taking it into development. As agreed, we will not consider the development process in detail.
Let's move on to preparing the experiment
What needs to be prepared in our case? Not so much: the period of the A / B test, the geography of the experiment and the one with which we will compare. We settled on a specific city, selected the conditions so as to minimize the impact of one appointment strategy on the second.
We will definitely negotiate with the business about red flags and reactions to them. The red flags are business metric thresholds that we don't want to cross during the experiment. If crossed, then in the overwhelming number of experiments this is rollback. But there are exceptions when we know for sure that the intersection did not happen because of us, but was the result of other factors. In this case, we can sometimes decide to continue the experiment.
What else needs to be prepared? Agree with our colleagues from the control room, who observe in real time that everything is fine with orders. For them, our change will be visible, because before we assigned an order for the courier immediately, but now we do not do this, we give ourselves some time to change our mind. That is why colleagues should be warned about the planned experiments.
Okay, let's move on. Prepared an experiment, conducted it and got the results. And here comes the fun part - analysis.
Experiment Analysis
We agreed to improve the total delivery time, and suddenly there were four schedules. It is worth explaining here. When launching an experiment, it is important to look not at one key metric, but at several business indicators that are critical for the business - in this case, we can significantly reduce the risks of an unsuccessful hypothesis affecting real processes in the platform. Let's be honest, we made such mistakes at the start of our experiments, and sometimes they led to really unpleasant consequences. But mistakes are good, we learn from them.
Let's take a look at the results. We will show the graphs without specific values, because the purpose of the article is not a detailed analysis of the efficiency of the Just In Time algorithm. We want to focus more on our approach when conducting experiments. For the same reason, we will not dwell on the theory of conducting A / B tests and determining the statistical significance of the results, this is a huge topic for the next publication, and perhaps even for the whole cycle.
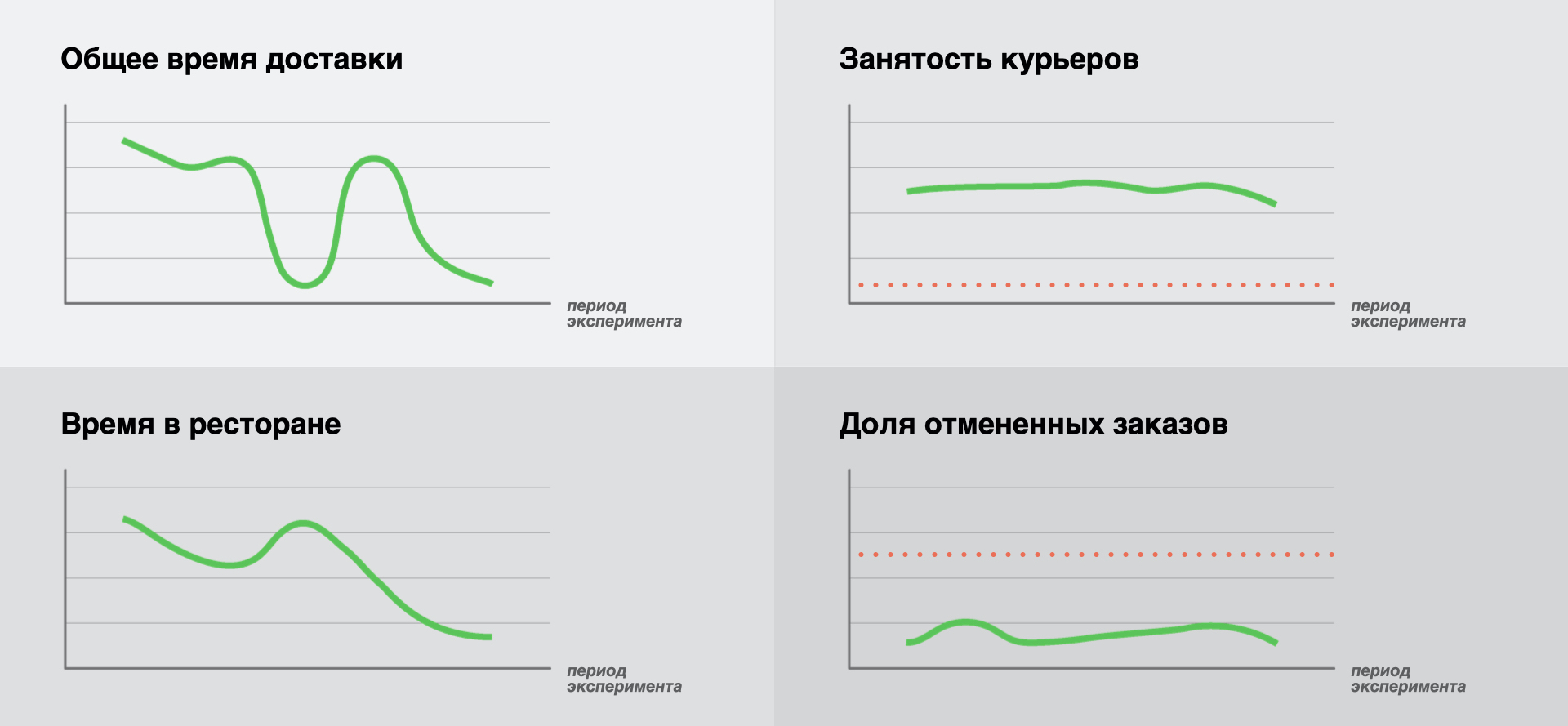
- « ». , , . , . , — , . , . , , . , . , , (/), — , , . -, .
- « ». . , , , . , . , .
- « » « ». : . .
As a result, we have a decrease in the key metric (1), a decrease in a very important metric (2), stable values of the other two key metrics (3, 4), the red flags are not lit. This allows us to conclude about the success of the experiment and the validity of the hypothesis being tested.
Class! Did you run on to the next hypothesis? It's fantastically entertaining and designed to improve everyone's life! But no, that's not all. There remains, perhaps, one of the most important steps, which we should not forget. This is to press one of three buttons:
- Rollout
- Rollback
- Continue
In the process of experiments, the team must have a colleague whose role is to be responsible for the feature entirely, who will press one of these three buttons. At the start, we had cases when we forgot about this step, as a result, we received several dozen simultaneously launched experiments without an understandable status for each of them. They gave positive results, but were not fully rolled out, which is ineffective for business. In addition, we had to spend significant resources just to remember the details and put things in order. But, again, we learn from mistakes.
Real-world experiments
Let us dwell briefly on why we experiment immediately in battle. This approach is usually opposed by analytical simulation environments, which, based on historical data, can, with a certain accuracy, answer what “it would be” if we implemented such a feature.
Why did we choose the first approach for ourselves? Two reasons.
- -, .
, , . , - , , . — .
. .
? , , , — . , , , , , . , .
It's worth being honest here that this is a rather risky approach. The risk of disappointing the audience, customers, business. This article is largely devoted to how to reduce such risks: carefully and accurately select metrics (several) and monitor them in real time. In case something goes wrong, we just turn off the experiment immediately.
- The second is, of course, speed. Experiments in combat conditions will show results much more accurately and faster.
Before we run further, let's fix some small victories.

A transparent experimenting process gives us the answer to the question of how to achieve a goal. And by conducting tests immediately in real conditions, we begin to better understand our audience. As a result, the development team has sufficient expertise to propose specific features that solve a business problem.
Not bad, but that's not all. Now is the time to talk more about measurability. And meanwhile we turn on the third, gas to the floor, the wind whistles.
Measurability
Why do we need metrics at all? Primarily to confirm a hypothesis or reduce the impact of a failed assumption. Hypotheses, even well-founded in theory, do not always shoot. And when they shoot, sometimes in the knee.
- -, FoodTech, : , , , .
- -, , , . , , , . ! , , , . , , -.
Our experience shows that a good recipe is when there are several metrics. One target metric - improving it; and a few more key ones - we must not drop them.
Introduce a unified monitoring space into which both business and development look. It does not have to be one tool, we use two: Metabase and Grafana, but in the future we plan to choose one of them. Most importantly, there should be a single space where colleagues from both business and development will look. And be sure to identify red flags.
Red flags
Yes, these are some threshold values of metrics that we should not cross during the experiment. It is worth agreeing with the business about reactions, if they have crossed, and posting alerts on them.
And one more small victory: we answered the question “Why does anyone need my code at all”. Let's not forget about her!

Let me remind you that this uncertainty on the part of the development is that we did not always understand why our code did not remain in production, and, frankly, we were sad about this. By adopting a peer-to-peer immersion approach from development to business metrics, we not only improved our understanding of customer solutions, but also provided ourselves with a dose of drive in solving business problems by focusing on the end result.
Okay, we figured out experiments and transparent processes, metrics and measurability. Ahead is the finish line, we turn on the fourth, and at maximum speed until victory.
Autonomy
All of the above works as well as possible only when we become autonomous from both the business and development sides.
GIST
Here, by autonomy, we mean the minimum dependency when making a decision. What have we done on the business side to make decisions quickly and not drown in approval processes? We have implemented the GIST framework.
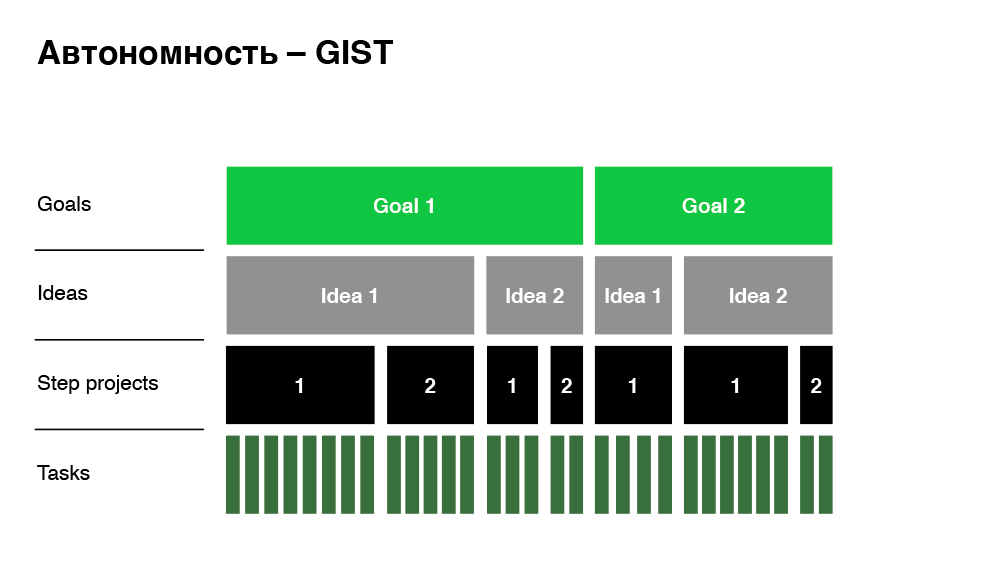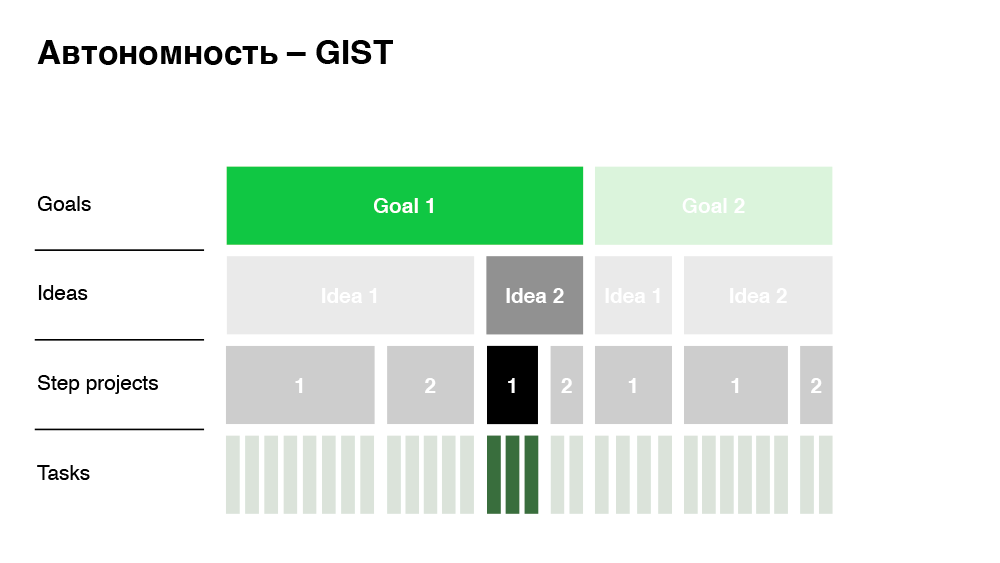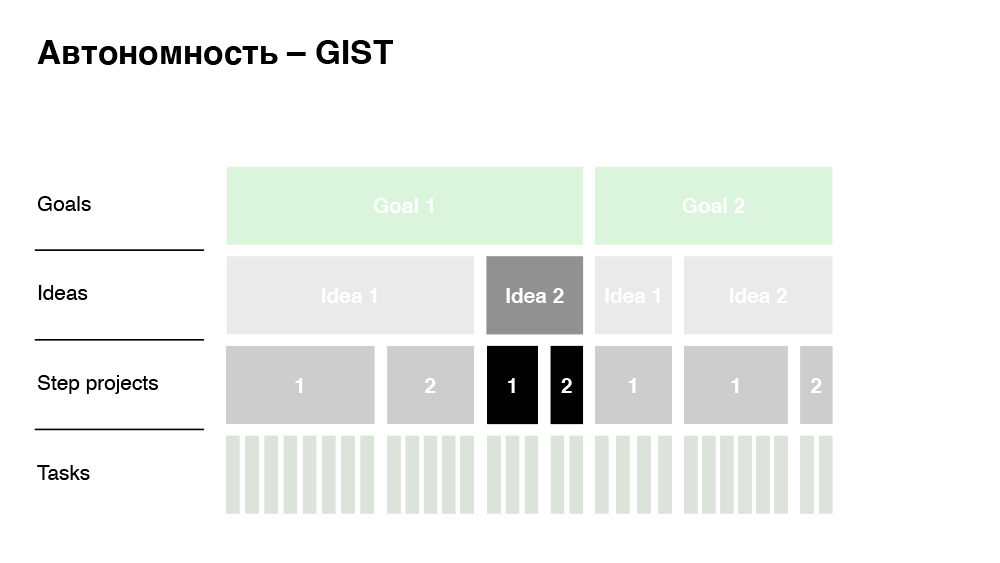
This approach is Goals, Ideas, Step-projects, Tasks. The company has clear business goals that management transparently communicates to all employees. To achieve these goals, employees throw ideas. There can be a dozen or one ideas. It is important that an idea is not a project yet. These are some of the approaches that I would like to implement. Step-project - these are already projects: quite large features that implement these ideas. In our Just In Time example, the destination is exactly the Step-project. At the last level are the tasks we are used to - this is already a decomposed Step-project, estimated in labor costs.
So how does the approach help you achieve autonomy? When we propose to make this feature (Just In Time), the business transparently sees:
- The size and cost of implementing the feature.
- What idea is he implementing.
- What is the specific goal of the company (impact).
Then we just need to compare it with the neighboring Step-project according to the same criteria: cost, impact. We hold a meeting (they are regular with us), discuss, prioritize and make a decision.
It looks very simple and straightforward. In our case, it is, and it works: the business makes decisions quickly, we are happy. But this is only the first step towards autonomy, because from the development side we also should not be blocked.
Inner Source
It's like open source, only within the company. The Delivery Club architecture is microservices, now there are more than a hundred of them. Often, in order to make a feature, it is necessary to modify not only the components for which our team is responsible, but also the neighboring services. And here we have two ways:
- Put improvements in the backlog of other teams, agree that the guys will make them.
- Do it yourself.

In our adaptation, the process works as follows. There is a big Just In Time feature, it affects three groups of services:
- an auto-assignment platform for which R&D is responsible,
- logistics platform,
- components of interaction with partners (restaurants and shops).
We do this:
- collecting all tasks into the R&D team backlog;
- we prioritize and distribute within the team which of the guys will refine which of the components;
- we agree with the technical leaders of the teams of logistics and partner areas on the nuances of implementation;
- we develop ourselves, colleagues conduct a review;
- then we test ourselves;
- We are already giving the service owners for rolling into production.
After getting into production, these improvements remain in the area of responsibility of the teams that own these services.
To be absolutely honest, the approach is not perfect and it has risks. The main one is timing. Most often, we modify components 2-2.5 times longer than the service owners would have done.
But the benefit is also obvious, it far outweighs the small delay in implementation - it's predictability. It is important to note here that other teams have their own backlog, their own priorities, and they most often cannot take our tasks “urgently”. Therefore, our deadline for business is realistic; it will not be affected by possible changes in priorities in other teams.
So, congratulations - finish, victory!

We have implemented the GIST framework for fast and transparent decision making, and the Inner Source approach for autonomy in development, and now all the pieces of the puzzle are assembled. It's time to wrap up, it was an interesting race, thank you for your participation! Let's summarize.
conclusions
- An experiment is a transparent and effective tool to achieve a goal.
- Carrying it out in a real environment, we study our audience, which allows us to make changes more and more useful every time, as well as understand why not all features should remain in production.
- But to avoid chaos, you need a clear process, the distribution of roles and the appointment of a responsible person.
- In the active phase of the experiment and during analysis, it is worthwhile to monitor several key metrics at once and do not forget to draw a conclusion (in our case, press one of the three buttons).
- Making quick decisions and autonomy in development helps to achieve results and keep the team motivated.
Video recording of the report from the RIT ++ 2020 conference .
That's all, thank you for being with me on this race. I am sure that we are at the very beginning and that great challenges still lie ahead. I will gladly share them, see you soon!