
Scalability is a key requirement for cloud applications. With Kubernetes, scaling an application is as easy as increasing the number of replicas for an appropriate deployment, or
ReplicaSet- but it's a manual process.
Kubernetes allows applications to auto-scale (i.e. Pods in deployment or
ReplicaSet) in a declarative manner using the Horizontal Pod Autoscaler specification. The default criterion for auto scaling is CPU usage metrics (resource metrics), but custom metrics and externally provided metrics can be integrated. Kubernetes aaS
team from Mail.rutranslated an article on How to Use External Metrics to Scale Your Kubernetes Application Automatically. To show how everything works, the author uses HTTP access request metrics, they are collected using Prometheus.
Instead of horizontal autoscaling of pods, Kubernetes Event Driven Autoscaling (KEDA) is an open source Kubernetes operator. It integrates natively with the Horizontal Pod Autoscaler to provide smooth autoscaling (including to / from zero) for event-driven workloads. The code is available on GitHub .
System Operation Brief
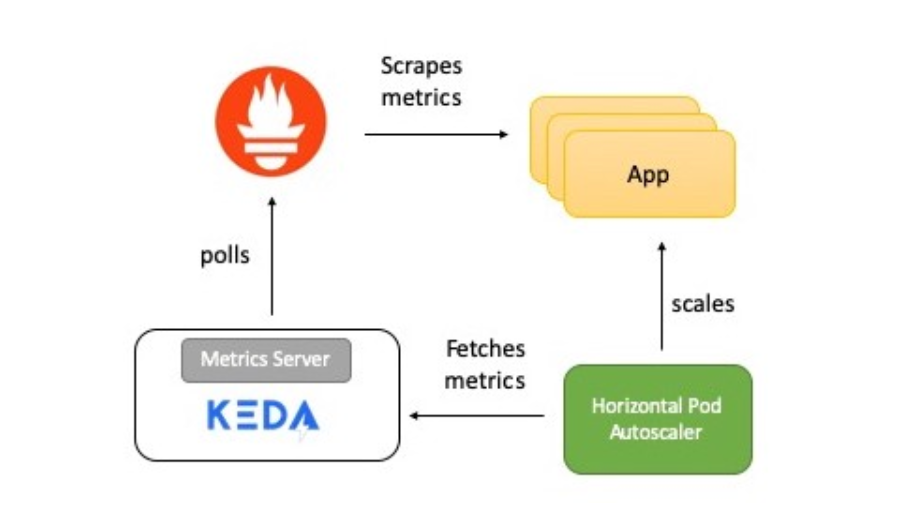
The diagram shows a short description of how everything works:
- The application provides metrics for the number of HTTP requests in Prometheus format.
- Prometheus is set to collect these metrics.
- The Prometheus scaler in KEDA is configured to automatically scale the application based on the number of HTTP requests.
Now I will tell you in detail about each element.
KEDA and Prometheus
Prometheus is an open source system monitoring and alerting toolkit, part of the Cloud Native Computing Foundation . Collects metrics from various sources and saves as time series data. To visualize data, you can use Grafana or other visualization tools that work with the Kubernetes API.
KEDA supports the scaler concept - it acts as a bridge between KEDA and the external system. The scaler implementation is specific to each target system and extracts data from it. KEDA then uses them to control autoscaling.
Scalers support multiple data sources like Kafka, Redis, Prometheus. That is, KEDA can be used to automatically scale Kubernetes deployments using Prometheus metrics as criteria.
Test application
The Golang test application provides HTTP access and serves two important functions:
- Uses the Prometheus Go client library to instrument the application and provide the http_requests metric that contains a hit counter. The endpoint for which Prometheus metrics are available is located by the URI
/metrics.
var httpRequestsCounter = promauto.NewCounter(prometheus.CounterOpts{ Name: "http_requests", Help: "number of http requests", }) - In response to the request, the
GETapplication increments the key (access_count) value in Redis. This is an easy way to get the job done as part of an HTTP handler, and also check Prometheus metrics. The metric value must be the same as the valueaccess_countin Redis.
func main() { http.Handle("/metrics", promhttp.Handler()) http.HandleFunc("/test", func(w http.ResponseWriter, r *http.Request) { defer httpRequestsCounter.Inc() count, err := client.Incr(redisCounterName).Result() if err != nil { fmt.Println("Unable to increment redis counter", err) os.Exit(1) } resp := "Accessed on " + time.Now().String() + "\nAccess count " + strconv.Itoa(int(count)) w.Write([]byte(resp)) }) http.ListenAndServe(":8080", nil) }
The app is deployed to Kubernetes via
Deployment. A service is also created ClusterIPthat allows the Prometheus server to receive application metrics.
Here is the deployment manifest for the application .
Prometheus Server
The Prometheus deployment manifest consists of:
ConfigMap- to transfer the Prometheus config;Deployment- for deploying Prometheus in a Kubernetes cluster;ClusterIP- service for accessing UI Prometheus;ClusterRole,ClusterRoleBindingandServiceAccount- for the auto-detection of services in Kubernetes (Auto-discovery).
Here is the manifest for running Prometheus .
KEDA Prometheus ScaledObject
The scaler acts as a bridge between KEDA and the external system from which metrics need to be obtained.
ScaledObjectIs a custom resource, it needs to be deployed to synchronize the deployment with the event source, in this case Prometheus.
ScaledObjectcontains deployment scaling information, event source metadata (such as connection secrets, queue name), polling interval, recovery period, and other information. It results in the appropriate autoscaling resource (HPA definition) to scale the deployment.
When an object
ScaledObjectis deleted, its corresponding HPA definition is cleared.
Here is the definition
ScaledObjectfor our example, it uses a scaler Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
http://prometheus-service.default.svc.cluster.local:9090
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Consider the following points:
- He points to
Deploymentwith a namego-prom-app. - Trigger type -
Prometheus. The Prometheus server address is mentioned along with the metric name, threshold, and the PromQL request to be used. PromQL request -sum(rate(http_requests[2m])). - According to
pollingIntervalKEDA, it requests a target from Prometheus every fifteen seconds. At least one pod (minReplicaCount) is supported , and the maximum number of pods does not exceedmaxReplicaCount(in this example, ten).
Can be set
minReplicaCountto zero. In this case, KEDA activates the zero-to-one deployment and then provides HPA for further automatic scaling. The reverse order is also possible, that is, scaling from one to zero. In the example, we did not select zero because this is an HTTP service and not a system on demand.
The magic inside autoscaling
The threshold is used as a trigger to scale the deployment. In our example, the PromQL query
sum(rate (http_requests [2m]))returns the aggregated value of the HTTP request rate (requests per second), measured over the last two minutes.
Since the threshold is three, there will be one under as long as the value is
sum(rate (http_requests [2m]))less than three. If the value increases, an additional under is added each time it sum(rate (http_requests [2m]))increases by three. For example, if the value is from 12 to 14, then the number of pods is four.
Now let's try to configure!
Presetting
All you need is a Kubernetes cluster and a customized utility
kubectl. This example uses a cluster minikube, but you can use any other. There is a guide for installing the cluster .
Install the latest version on Mac:
curl -Lo minikube
https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
Install kubectl to access your Kubernetes cluster.
Install the latest version on Mac:
curl -LO
"https://storage.googleapis.com/kubernetes-release/release/$(curl -s
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
Installing KEDA
You can deploy KEDA in several ways, they are listed in the documentation . I am using monolithic YAML:
kubectl apply -f
https://raw.githubusercontent.com/kedacore/keda/master/deploy/KedaScaleController.yaml
KEDA and its components are installed in the namespace
keda. Command to check:
kubectl get pods -n keda
Wait, when under KEDA Operator starts - goes to
Running State. And then continue.
Installing Redis with Helm
If you don't have Helm installed, use this tutorial . Command to install on Mac:
brew install kubernetes-helm
helm init --history-max 200
helm initinitializes the local CLI and also installs Tillerinto the Kubernetes cluster.
kubectl get pods -n kube-system | grep tiller
Wait for the Tiller pod to enter the Running state.
Translator's Note : The author uses Helm @ 2, which requires the Tiller server component to be installed. Helm @ 3 is currently relevant, it does not need a server part.
After installing Helm, one command is enough to start Redis:
helm install --name redis-server --set cluster.enabled=false --set
usePassword=false stable/redis
Verify Redis has started successfully:
kubectl get pods/redis-server-master-0
Wait for under Redis to go into state
Running.
Deploy the application
Command for deployment:
kubectl apply -f go-app.yaml
//output
deployment.apps/go-prom-app created
service/go-prom-app-service created
Check that everything started:
kubectl get pods -l=app=go-prom-app
Wait for Redis to transition to state
Running.
Deploying Prometheus Server
The Prometheus Manifest uses Kubernetes Service Discovery for Prometheus . It allows you to dynamically discover application pods based on a service label.
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_run]
regex: go-prom-app-service
action: keep
For deployment:
kubectl apply -f prometheus.yaml
//output
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/default configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prom-conf created
deployment.extensions/prometheus-deployment created
service/prometheus-service created
Check that everything started:
kubectl get pods -l=app=prometheus-server
Wait for under Prometheus to go into state
Running.
Use
kubectl port-forwardto access the Prometheus user interface (or API server) at http: // localhost: 9090 .
kubectl port-forward service/prometheus-service 9090
Deploying the KEDA autoscaling configuration
Command to create
ScaledObject:
kubectl apply -f keda-prometheus-scaledobject.yaml
Check the logs of the KEDA operator:
KEDA_POD_NAME=$(kubectl get pods -n keda
-o=jsonpath='{.items[0].metadata.name}')
kubectl logs $KEDA_POD_NAME -n keda
The result looks something like this:
time="2019-10-15T09:38:28Z" level=info msg="Watching ScaledObject:
default/prometheus-scaledobject"
time="2019-10-15T09:38:28Z" level=info msg="Created HPA with
namespace default and name keda-hpa-go-prom-app"
Check under applications. One instance should be running because it
minReplicaCountis 1:
kubectl get pods -l=app=go-prom-app
Verify that the HPA resource has been successfully created:
kubectl get hpa
You should see something like:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 0/3 (avg) 1 10 1 45s
Health check: access to the application
To access the REST endpoint of our application, run:
kubectl port-forward service/go-prom-app-service 8080
You can now access the Go app using the address http: // localhost: 8080 . To do this, run the command:
curl http://localhost:8080/test
The result looks something like this:
Accessed on 2019-10-21 11:29:10.560385986 +0000 UTC
m=+406004.817901246
Access count 1
Check Redis at this point as well. You will see the key
access_countincreased to 1:
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
"1"
Make sure the metric value
http_requestsis the same:
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 1
Load creation
We will use hey , a utility to generate the load:
curl -o hey https://storage.googleapis.com/hey-release/hey_darwin_amd64
&& chmod a+x hey
You can also download the utility for Linux or Windows .
Run it:
./hey http://localhost:8080/test
By default, the utility sends 200 requests. You can verify this using Prometheus metrics as well as Redis.
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests number of http requests
# TYPE http_requests counter
http_requests 201
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
201
Confirm the actual metric value (returned by the PromQL query):
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//output
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1571734214.228,"1.686057971014493"]}]}}
In this case, the actual result is equal
1,686057971014493and displayed in the field value. This is not enough for scaling as the threshold we set is 3.
More load!
In the new terminal, keep track of the number of application pods:
kubectl get pods -l=app=go-prom-app -w
Let's increase the load using the command:
./hey -n 2000 http://localhost:8080/test
After a while, you will see HPA scaling the deployment and launching new pods. Check the HPA to make sure:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 1830m/3 (avg) 1 10 6 4m22s
If the load is not constant, the deployment will be reduced to the point where only one pod works. If you want to check the actual metric (returned by the PromQL query), then use the command:
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
Cleaning
//Delete KEDA
kubectl delete namespace keda
//Delete the app, Prometheus server and KEDA scaled object
kubectl delete -f .
//Delete Redis
helm del --purge redis-server
Conclusion
KEDA allows you to automatically scale your Kubernetes deployments (to / from zero) based on data from external metrics. For example based on Prometheus metrics, queue length in Redis, consumer latency in Kafka theme.
KEDA integrates with an external source and also provides metrics through the Metrics Server for the Horizontal Pod Autoscaler.
Good luck!
What else to read: