
The Mail.ru Cloud Solutions teamtranslated an abridged essay by Kevin Wu , which discusses what the pharmaceutical and healthcare industry has already achieved using artificial intelligence and machine learning, and when new technologies will help find drugs from all diseases.
Why it may seem like there is no progress
Some people express their frustration with life something like this: "If this is the future, then where is my jetpack?" At first glance, such a longing for a retro future seems strange in an era of ubiquitous computing, programmable cells and a resurgent space exploration . But for some, this nostalgic futurism holds up surprisingly well. They cling to predictions that look odd in retrospect, ignoring startling reality that no one could have predicted.
Who would have thought that thanks to deep learning we could predict the properties of drugs that do not yet exist? This is of great importance to the pharmaceutical industry.
With regard to artificial intelligence, complaints can sound something like this: “Almost eight years have passed since the invention of the AlexNet neural network [ approx. translator : in 2012, Aleksey Krizhevsky published the design of the AlexNet convolutional neural network, which won the ImageNet competition by a large margin], so where is my self-driving car? " Indeed, it may seem that the expectations of the mid-2010s have not been met. Among pessimists, forecasts of the next stagnation in AI research are gaining momentum .
The purpose of this essay is to discuss the significant progress of machine learning in the real-world drug discovery challenge. I want to remind you of another old adage, this time from AI researchers. To rephrase slightly, it sounds like this: "AI is called AI until it works, then it's just software."
What until a few years ago was considered cutting-edge fundamental research in machine learning is now often referred to as “just data science ” (or even analytics) - and is revolutionizing the pharmaceutical industry. There is a solid chance that the use of deep learning to discover drugs will dramatically change our lives for the better.
Computer vision and deep learning in biomedical imaging
As soon as scientists got access to computers and the opportunity to upload images there, they immediately tried to process them. Basically, we are talking about biomedical images: radiographs, ultrasound and MRI results. Back in the days of good old AI, processing usually meant manually inferring logical statements based on simple attributes such as contours and brightness.
The 1980s saw a shift towards supervised machine learning algorithmsbut they still relied on hand-set tags. Simple supervised learning models (such as linear regression or polynomial fit) are trained on features extracted by algorithms such as SIFT (Scale Invariant Feature Transformation) and HOG (Histogram of Directed Gradients). It should come as no surprise that the developments that have led to the practical use of deep learning today started decades ago.
Convolutional neural networks were first used for the analysis of biomedical images in 1995, when Law and colleaguespresented a model for the recognition of cancerous tumors in the lungs on fluorograms. Their method was a little different from what we are used to today, deriving the result took about 15 seconds, but the concept was essentially the same - with learning through backpropagation all the way to the convolutional cores of the neural network. Their model involved two hidden layers, whereas today's popular deep network architectures often have a hundred or more layers.
Fast forward to 2012. Convolutional neural networks made a splash with the arrival of the AlexNet system, which led to a leap in performance of the now famous ImageNet dataset. The success of AlexNet, a network with five convolutional and three tightly coupled layers trained on game GPUs, has become so famous in machine learning that people are now talking about “Moments of ImageNet ”in different niches of machine learning and AI.
For example, "natural language processing may have outlived its ImageNet moment with the development of large transformers in 2018" or "reinforcement learning is still waiting for its ImageNet moment."
Almost ten years have passed since AlexNet. Computer vision and deep learning models are gradually improving. Applications have gone beyond the classification. Today they have learned how to segment images, estimate depth, and automatically reconstruct 3D scenes from multiple 2D images. And this is not a complete list of their capabilities.
Deep learning for biomedical imaging analysis has become a hot area of research. A side effect is an inevitable increase in noise. Published in 2019approximately 17,000 scientific articles on deep learning . Of course, not all of them are worth reading. It is likely that many researchers overfit models too much on their modest datasets.
Most of them have not made any contributions to basic science or machine learning. A passion for deep learning has gripped academic researchers who had previously shown no interest in it, and for good reason. It can do what classical computer vision algorithms do (see Tsybenko and Hornik 's universal approximation theorem ), and often does it faster and better, saving engineers from the tedious manual design of each new application.
A rare opportunity to fight "neglected" diseases
This brings us to the topic of drug discovery today, an industry that is in for a good shake-up. Pharmaceutical companies and their contractors love to reiterate the huge costs of bringing a new drug to market. These costs are largely due to the fact that many drugs take a long time to study and test before they are consumed.
The cost of developing a new drug can be as high as $ 2.5 billion or more . Sometimes, due to the high cost and relatively low profitability, a number of works on certain classes of drugs are relegated to the background .
It is also leading to a spike in incidence in the aptly named category of "neglected diseases", including a disproportionate number of tropical diseases.that afflict people in the poorest countries and are considered disadvantageous to treatment; and rare diseases with low incidence rates. Relatively few people suffer from each of them, but the total number of people with all rare diseases is quite large. It is estimated that about 300 million people. And even this number may turn out to be an underestimate due to the gloomy assessment of experts: about 30% of those suffering from a rare disease do not live to be five years old.
" Long tail»Rare diseases have significant potential to improve the lives of huge numbers of people, and this is where machine learning and big data come to the rescue. The blind spot for rare (orphan) diseases that do not have an officially approved treatment opens up an opportunity for innovation from small teams of biologists and machine learning developers.
One such startup in Salt Lake City, Utah is trying to do just that. The founders of Recursion Pharmaceuticals view the lack of rare disease drugs as a gap in the pharmaceutical industry. They receive huge amounts of data by analyzing the results of microscopy and laboratory tests. With the help of neural networks, it is possible to identify the features of diseases and seek treatment methods.
By the end of 2019, the company had run thousands of experiments and collected over 4 petabytes of information. They posted a small subset of this data (46 GB) for the NeurIps 2019 competition, you can download it from the RxRx website and play around on your own.
The workflow described in this article is largely based on information from the Recursion Pharmaceuticals white papers [ pdf ], but this approach may well serve as an inspiration for other areas.
Other startups in the field include Bioage Labs (aging diseases), Notable Labs (oncology) and TwoXAR.(various diseases for which there are no treatment options). Typically, young startups are engaged in innovative data processing techniques and apply a variety of machine learning methods in addition to or instead of deep learning with computer vision.
Next, I'll describe the image analysis process and how deep learning fits into the rare disease drug discovery workflow. We will look at a high-level process that is applicable to a variety of other areas of drug discovery.
For example, it can be easily used to screen cancer drugs for their effect on tumor cell morphology. Perhaps even to analyze the response of cells of specific patients to different drug options. This approach uses concepts from nonlinear principal component analysis, semantic hashing [ pdf ] and good old convolutional neural network image classification.
Classification in morphological noise
Biology is a mess. Therefore, high-throughput multiparameter microscopy is a source of constant frustration for cell biologists. The resulting images differ greatly from one experiment to the next. Fluctuations in temperature, exposure time, the amount of reagents, and others lead to changes that are not related to the studied phenotype or drug action, and therefore to errors in the results obtained.
Maybe climate control in a laboratory works differently in summer and winter? Maybe someone had lunch next to the slides before inserting them into the microscope? Maybe the supplier of one of the ingredients of the culture medium has changed? Or has the supplier changed its own supplier? A huge number of variables affect the result of an experiment. Tracking and highlighting unintentional noise is one of the main challenges in data-driven drug discovery.
Microscopic images can be very different in the same experiments. The brightness of the image, the shape of cells, the shape of organelles, and many other characteristics change due to the corresponding physiological effects or random errors.
So, the images in the figure below are obtained from the samea publicly available set of metastatic cancer cell micrographs compiled by Scott Wilkinson and Adam Marcus. Variations in saturation and morphology should reflect the uncertainty of the experimental data. They are created by introducing distortions into the processing. It is a kind of analogue of augmentation, which researchers use to regularize deep neural networks in classification problems. Therefore, it should come as no surprise that the ability to generalize large models to large datasets is a logical choice for looking for physiologically significant features in a sea of noise.
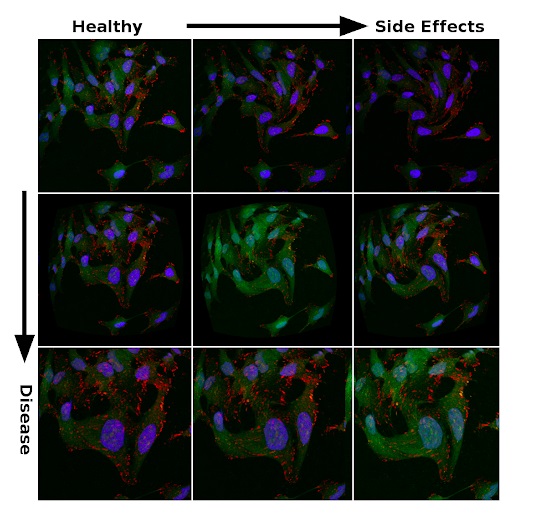
Signs of treatment effectiveness and side effects among noisy data
The main cause of rare diseases is usually a genetic mutation. To build models to find a cure for these diseases, it is necessary to understand the effects of a wide range of mutations and their relationship to different phenotypes. To effectively compare possible treatments for a specific rare disease, neural networks are trained based on thousands of different mutations.
These mutations can be mimicked by suppressing gene expression using small interfering RNAs(siRNA). It's a bit like babies grab your ankles: even if you can run fast, your speed will drop dramatically with your niece or nephew hanging from each leg. siRNA works in a similar way: a small sequence of interfering RNAs sticks to the corresponding parts of the messenger RNA of specific genes, preventing their full expression.
By learning from thousands of mutations instead of a singular cellular model of a specific disease, the neural network learns to code phenotypes in a multidimensional hidden space. The resulting code makes it possible to evaluate drugs by their ability to bring the disease phenotype closer to a healthy phenotype, each of which is represented by a multidimensional set of coordinates. Likewise, the side effects of drugs can be embedded in the encoded representation of the phenotype, and drugs are evaluated not only for the disappearance of symptoms of the disease, but also for minimizing harmful side effects.

The diagram shows the effect of treatment on the cellular model of the disease (represented by a red dot) Treatment is the movement of the encoded phenotype closer to the healthy phenotype (blue dot). This is a simplified 3D representation of phenotypic coding in a multidimensional hidden space
The deep learning models used for this workflow are very similar to other classification problems with a large dataset, although if you are used to working with a small number of categories, as in CIFAR-10 datasets and CIFAR-100, you will not immediately get used to the thousands of different classification marks.
Also, this image-based drug discovery method works well with the same DenseNet or ResNet architecture with hundreds of layers, which provides optimal performance on datasets like ImageNet.
Layer activation values encoded in a multidimensional space reflect phenotype, disease pathogenesis, relationships between treatments, side effects, and other ailments. Therefore, all these factors can be analyzed by displacement in the coded space. This phenotypic code can be subjected to special regularization (for example, by minimizing covariance between different activations of layers) to reduce coding correlations or for other purposes.
The figure below shows a simplified model. Black arrows represent the operations of convolution + pooling. Blue lines represent tight connections. For simplicity, the number of layers has been reduced and residual connections are not shown.
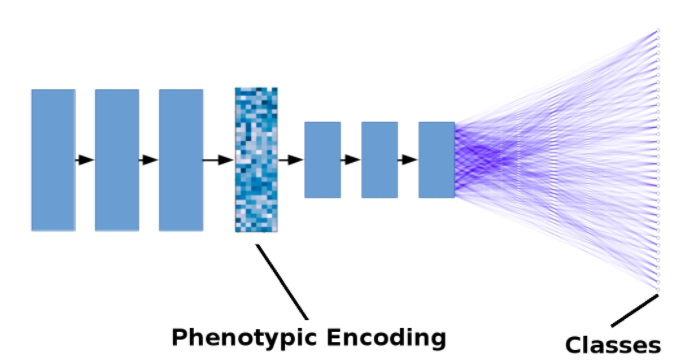
Simplified illustration of a deep learning model for drug discovery
The Future of Deep Learning in Drug Discovery and the Pharmaceutical Industry
The high cost of bringing new drugs to market has led pharmaceutical companies to often opt for market hits rather than researching drugs for serious diseases. Smaller, data analytics teams in startups are better equipped to innovate in this area, while neglected and rare diseases provide an opportunity to enter the market and demonstrate the value of machine learning.
The effectiveness of this approach has been proven. We are seeing significant research progress and several drugs are already in the first phase of clinical trials. For example, teams of just a few hundred scientists and engineers at companies such as Recursion Pharmaceuticals achieve this. Other startups are close by: TwoXAR has several drug candidates undergoing preclinical trials in other categories of diseases.
The deep learning and computer vision approach to drug development can be expected to have a significant impact on large pharmaceutical companies and healthcare in general. We will soon see how this will affect the development of new treatments for common diseases (including heart disease and diabetes), as well as rare ailments that have remained out of sight to this day.
What else to read on the topic:
- File formats in big data: a short educational program .
- Analyzing Big Data in the Cloud: How a Company Can Become Data-Driven .
- Our Telegram channel about digital transformation .