
The life of a network engineer was happy and carefree until a certified crypto gateway appeared. Agree, dealing with solutions designed for encrypting data transmission channels in accordance with GOST is not an easy task. It's good if these are well-known and understandable products. Let us recall the same "S-Terra" (we have already written about their "S-Terra Gateway" ). But what to do with more exotic solutions based on their own encryption protocols, for example, "Continent" (from "Security Code") or ViPNet Coordinator HW (from "Infotex")? In this article I will try to facilitate the immersion into the world of ViPNet (we will also talk about Continent someday) and tell you what problems I faced myself and how I solved them.
I'll make a reservation right away that we will talk about version 4.2.1 certified by the FSB and FSTEC for today. In the current versions 4.3.x, a lot of interesting things have appeared, for example, DGD (Dead Gateway Detection) and a modified clustering mechanism, which provides almost seamless switching, but for now this is the future. I will not dive deeply into the depths of configuration commands and files, focusing on the key commands and variables, and a detailed description of these "keys" can be found in the documentation.
First, let's figure out how it all works. So, a ViPNet coordinator performs several functions. Firstly, it is a crypto gateway (CG) that allows you to implement both Site-to-site and RA VPN. Secondly, it is a server-router of envelopes containing encrypted service data (directories and keys) or data of client applications (file exchange, business mail). By the way, it is in directories that files containing information about objects of the ViPNet network, including their names, identifiers, addresses, connections, are stored. The coordinator is also a source of service information for his clients.
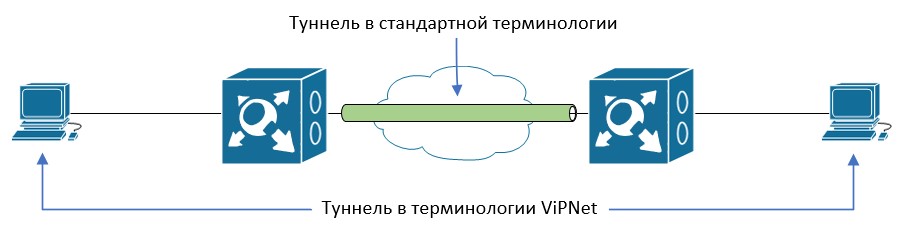
Besides, it can tunnel traffic from network computers where ViPNet software is not installed. By the way, people working with this solution often refer to open hosts as “tunnels” rather than “tunneled nodes”. This can be confusing for engineers who are accustomed to other VPN solutions, where the tunnel refers to the PtP connection between the network.
IPlir, also developed by Infotex, is used as an encryption protocol in ViPNet. To encapsulate traffic, the transport protocols IP / 241 (if the traffic does not leave the broadcast domain), UDP / 55777 and TCP / 80 (if UDP is not available) are used.
The concept of building secure connections is based on the so-called "connections", which are of two types. The former (at the node level) are needed to build a secure connection between nodes, the latter (at the user level) are needed for the operation of client applications. But there is an exception: ViPNet administrator nodes require both types of communication.
What can go wrong in this scheme? As practice shows, there are really a lot of peculiarities of work, and not all problems can be solved intuitively, without “the help of the audience,” but something must simply be taken for granted.
Coordinator unavailable
“We have no coordinator / client / tunnel available. What to do?" - the most frequent question that newbies come up with when setting up ViPNet. The only correct action in such a situation is to turn on the registration of all traffic on the coordinators and look at the IP packet log, which is the most important tool for troubleshooting all kinds of network problems. This method saves in 80% of cases. Working with the IP packet log also helps to better understand the mechanisms of operation of the ViPNet network nodes.
Envelope not delivered
But the IP packet log is, alas, useless when it comes to envelopes. They are delivered using a transport module (mftp), which has its own journal and its own queue. By default, envelopes are sent to the client's “own” coordinator (that is, the one on which the node is registered), and then through the inter-server channels that are configured between the coordinators (that is, not directly over a secure channel). This means that if you want to send a letter by business mail, the client will pack it in an envelope and send it first to his coordinator. Further on the way there may be several more coordinators, and only after that the envelope will reach the destination node.
Two conclusions follow from this. Firstly, communication between clients does not have to be checked (by pressing F5 and the corresponding icon in the menu) to deliver envelopes. Secondly, if the connection between them is still checked, this does not guarantee delivery, since the problem may be in one of the inter-server channels.
In unobvious cases, it is possible to diagnose the passage of envelopes through interserver channels or between a client and a coordinator using the journal and envelope queue, as well as logs on the coordinator. Also, the ViPNet client transport module can be configured for direct delivery of envelopes, delivery via a shared folder, or SMTP / POP3 (but this is a completely exotic option). We will not dive into these settings.
Consequences of flashing
It can be problematic to upgrade to the current version of old pieces of hardware that have been in use for a long time, for example, as a spare part. In the process, an "unsupported hardware" error may appear, which indicates either that you have really unsupported hardware platform of the outdated G1 line (these are HW100 E1 / E2 and HW1000 Q1), or about problems in BIOS setup or incorrect information embedded in DMI. Whether to manage DMI on their own, everyone decides for himself, since there is a risk of turning the equipment into a useless "brick". With BIOS, it's a little easier: incorrect system settings are in disabled HT (Hyper Threading) or disabled ACHI (Advanced Host Controller Interface) for HDD. In order not to guess what exactly the problem is, you can refer to the USB flash drive from which the firmware is being produced.Files with diagnostic information are created on it, in particular, all supported platforms are listed in the verbose.txt file with the result of checking with yours. For example, the error cpu :: Vendor (# 3) == 'GenuineIntel' 24 times => [Failed] most likely indicates that HT is disabled. By the way, flashing is often confused with updating, but these are different processes. During the update, all settings are saved, and the parameters described above are not checked. And when you reflash, you return to the factory settings.During the update, all settings are saved, and the parameters described above are not checked. And when you reflash, you return to the factory settings.When updating, all settings are saved, and the parameters described above are not checked. And when you reflash, you return to the factory settings.
Non-informative configs
The main configuration file for HW is "iplir.conf", but it does not always reflect the current settings. The fact is that at the moment the IPlir driver is loaded, this config is interpreted in accordance with the laid down logic, and not all information can be loaded into the driver (for example, if there are IP address conflicts). Engineers who have worked with the Linux software coordinator are probably aware of the "iplirdiag" command, which displays the current node settings loaded into the driver. In HW, this command is also present in the "admin escape" mode.
The most popular conclusions are:
iplirdiag -s ipsettings --node-info <node id> ## display information about the node
iplirdiag -s ipsettings --v-tun-table ## display all tunnels loaded into the driver
Let's dwell a little on the "admin escape" mode. In fact, this is an exit from the ViPNet shell to bash. Here I agree with the vendor, who recommends using this mode only for diagnostics and making any modifications only under the supervision of the vendor's technical support. This is not your usual Debian, here any careless movement can disable the OS, the protective mechanisms of which will perceive your "initiative" as a potential threat. In conjunction with the BIOS locked by default, this condemns you to non-warranty (read "expensive") repairs.
(Un) split tunneling
Another fact that not everyone knows: by default, the ViPNet client works in split tunnel mode (when you can specify which traffic to wrap into the tunnel and which not). ViPNet has the "Open Internet" technology (later renamed to "Protected Internet Gateway"). Many people mistakenly attribute this functionality to the coordinator rather than the client. On a client that is registered with a coordinator with this function, two sets of preset filters are created. The first allows interaction only with the coordinator itself and its tunnels, the second - with other objects, but denies access to the OI coordinator and its tunnels. Moreover, according to the vendor's concept, in the first case, the coordinator must either tunnel the proxy server or be the proxy server itself. Service traffic, as well as reception and transmission of envelopes (both service,and applications) work in any configuration.
TCP-
Once I ran into an application that did not want to work in any way through the coordinator. This is how I learned that the coordinator has service ports through which unencrypted traffic is blocked without the possibility of any configuration. These include UDP / 2046,2048,2050 (basic ViPNet services), TCP / 2047,5100,10092 (for ViPNet Statewatcher) and TCP / 5000-5003 (MFTP). Here I summed up the TCP tunnel functions. It is no secret that ISPs love to filter high UDP ports, so administrators, in an effort to improve the availability of their CNs, enable the TCP tunnel feature. In this case, resources in the DMZ (via the TCP tunnel port) become unavailable. This is due to the fact that the TCP tunnel port also becomes a service port, and no firewall rules and NAT (Network Address Translation) rules on it anymore. It is difficult to diagnose the fact thatthat this traffic is not being logged in the IP packet log as if it weren't there at all.
Replacing the coordinator
Sooner or later, the question arises of replacing the coordinator with a more productive or temporary option. For example, replacing HW1000 with HW2000 or software coordinator with PAK and vice versa. The difficulty lies in the fact that each performance has its own "role" in the NCC (Network Control Center). How to properly change the role without losing cohesion? First, in the NCC we change the role to a new one, form directories, but do not send (!) Them. Then we release a new DST file in the UCC and initialize the new Coordinator. After that we make a replacement and, after making sure that all interactions are functional, we send the reference books.
Clustering and node crash
A hot reserve is a must have for any large site, so a cluster of older models (HW1000, HW2000, HW5000) has always been purchased from them. However, the creation of a cluster from more compact crypto gateways (HW50 and HW100) was impossible due to the vendor's licensing policy. As a result, the owners of small sites had to seriously overpay and buy HW1000 (well, or no fault tolerance). This year, the vendor finally made additional licenses for junior coordinator models. So with the release of versions 4.2.x, it became possible to collect them into a cluster.
When setting up a cluster for the first time, you can save a lot of time by not configuring the interfaces in wizard mode or using CLI commands. You can immediately enter the necessary addresses into the cluster configuration file (failover config edit), just do not forget to specify the masks. When the failover daemon is started in cluster mode, it will assign addresses to the corresponding interfaces by itself. At the same time, many are afraid to stop the daemon, assuming that the addresses are changed to passive or single-mode addresses. Don't worry: the interfaces will retain the addresses that were at the time the daemon was stopped.
In the cluster version, there are two common problems: cyclic reboot of the passive node and its failure to switch to active mode. In order to understand the essence of these phenomena, let us understand the mechanism of the cluster operation. So, the active node counts packets on the interface and, if there are no packets in the allotted time, sends a ping to testip. If the ping passes, then the counter is restarted, if it does not pass, then an interface failure is registered and the active node goes into reboot. At the same time, the passive node sends regular ARP requests on all interfaces described in failover.ini (the cluster configuration file, which contains the addresses that the active and passive nodes receive). If the ARP record of at least one address disappears, then the passive node switches to active mode.
Let's get back to cluster problems. I'll start with a simple one - not switching to active mode. If there is no active node, but its mac-address is still present on the passive one in the ARP table (inet show mac-address-table), you need to go to the switch administrators (either the ARP cache is configured this way, or it is some kind of failure ). Cyclic reloading of the passive node is a little more complicated. This happens due to the fact that the passive does not see the ARP record active, goes into active mode and (attention!) Polls the neighbor via the HB link. But our neighbor is in active mode and has more uptime. At this moment, the passive node realizes that something is wrong, since a state conflict has arisen, and goes into a reboot. This continues indefinitely. If this problem occurs, you need to check the IP address settings in failover.ini and the switching.If all the settings on the coordinator are correct, then it's time to connect the network engineers to the question.
Crossing addresses
In our practice, we often encounter the intersection of tunneled addresses behind different coordinators.

It is for such cases that there is virtualization of addresses in ViPNet products. Virtualization is a kind of NAT without monitoring the state of a one-to-one connection or range to range. By default, this function is disabled on coordinators, although you can find potential virtual addresses in iplir.conf in the "tunnel" line after "to" in the sections of neighboring coordinators. To enable virtualization globally for the entire list, in the [visibility] section, change the "tunneldefault" parameter to "virtual". If you want to enable it for a specific neighbor, you need to add the parameter "tunnelvisibility = virtual" to its [id] section. It is also worth making sure that the tunnel_local_networks parameter is set to "on". To edit virtual addresses, the tunnel_virt_assignment parameter must be set to "manual" mode.On the opposite side, you need to perform similar actions. The "usetunnel" and "exclude_from_tunnels" parameters are also responsible for tunnel settings. The result of the work performed can be checked using the "iplirdiag" utility, which I mentioned above.
Of course, virtual addresses bring some inconvenience, so infrastructure administrators prefer to minimize their use. For example, when organizations connect to information systems (IS) of some government agencies, these organizations are issued a DST file with a fixed range of tunnels from the IS address plan. As we can see, the wishes of the connecting person are not taken into account. How to fit into this pool, everyone decides for himself. Someone migrates workstations to a new addressing, and someone uses SNAT on the way from the hosts to the coordinator. It is no secret that some administrators use SNAT to bypass the licensing restrictions of lower platforms. We do not undertake to assess the ethics of such a "life hack", but do not forget that the performance of the platforms themselves still has a limit,and when overloaded, the quality of the communication channel will begin to degrade.

Inability to work GRE
Of course, every IT solution has its own limitations on the supported use cases, and ViPNet Coordinator is no exception. A rather annoying problem is the inability to work GRE (and the protocols that use it) from multiple sources to a single destination via SNAT. Take, for example, a bank-client system that sets up a PPTP tunnel to the bank's public address. The problem is that the GRE protocol does not use ports, so after the traffic passes through NAT, the socketpair of such traffic becomes the same (we have the same destination address, the protocol is the same, and we just translated the source address into one address). The coordinator reacts to this by blocking traffic on the background of error 104 - Connection already exists. It looks like this:
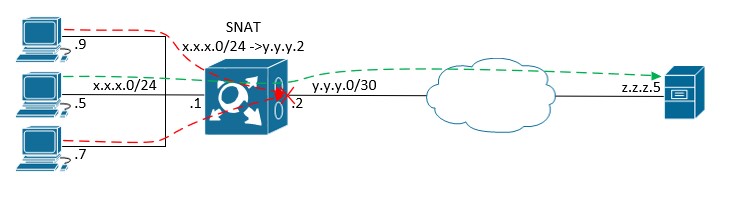
Therefore, if you are using multiple GRE connections, you should avoid applying NAT to those connections. As a last resort, perform 1: 1 broadcasting (although this is a rather impractical solution when using public addresses).

Don't forget about time
We continue the topic of blocking with event number 4 - IP packet timeout. Everything is banal here: this event occurs when there is a discrepancy between the absolute (excluding time zones) time between the ViPNet network nodes (coordinators and ViPNet clients). On HW coordinators, the maximum difference is 7200 seconds and is set in the "timediff" parameter of the IPlir configuration file. I do not consider the HW-KB coordinators in this article, but it is worth noting that in the KB2 version the timediff is 7 seconds by default, and in KB4 it is 50 seconds, and the event there may be generated not 4, but 112, which may be confusing an engineer accustomed to "normal" HW.
Unencrypted traffic instead of encrypted
It can be difficult for beginners to understand the nature of the 22 event - Non-encrypted IP Packet from network node - in the IP packet log. It means that the coordinator was expecting encrypted traffic from this IP address, but unencrypted traffic came. Most often it happens like this:
- ViPNet-, , . IPlir , , , . , : ViPNet-, – . , , , . , , , ViPNet-, . , ViPNet-, ;
- . , , ( ). , , , ;
- . , . , «» . , , , 22 .
(ALG)
Many firewalls, including ViPNet Coordinator, may have problems with SIP passing through NAT. Given that virtual addresses are internal NAT, the problem can occur even when explicitly NAT is not used, but only virtual addresses are used. The coordinator has an application protocol processing (ALG) module that should solve these problems, but it does not always work as desired. I will not dwell on the ALG mechanism (a separate article can be written on this topic), the principle is the same for all ITUs, only the headings of the application level change. For the correct operation of the SIP protocol through the coordinator, you need to know the following:
- ALG must be enabled when using NAT;
- when using virtual addressing, ALG must be enabled on both nodes participating in the interaction (coordinator-coordinator, coordinator-client), even if virtual visibility is set on only one side;
- when using real visibility and there is no NAT, you must turn off ALG so that it does not interfere with SIP;
- ALG lines 3.x and 4.x are incompatible (strictly speaking, in line 3.x there was no way to control it at all). In such a scenario, the vendor cannot guarantee the correct operation of SIP.
The module is controlled by the commands of the "alg module" group from the privileged mode (enable).
Finally
I tried to consider the most pressing problems, identify their roots and talk about solutions. Of course, these are far from all the features of ViPNet, so I recommend not to be shy - contact support and ask for advice in the community (on the vendor's forum, in the telegram channel, in the comments under this post). And if you don’t want to dive into all the difficulties of working with ViPNet or it’s too laborious, then you can always leave the management of your ViPNet network in the hands of professionals.
Author: Igor Vinokhodov, engineer of the 2nd line of administration, Rostelecom-Solar