Let's go in order. And immediately a small disclaimer: the article was written based on my speech at Ya Subbotnik Pro for front-end developers. If you are involved in the backend, then, perhaps, you will not discover anything new for yourself. Here I will try to summarize my experience of frontend in a large enterprise, explain why and how we use Node.js.
Let's define what we will consider as a frontend in this article. Let's put aside disputes about tasks and focus on the essence.
Frontend is the part of the application responsible for displaying. It can be different: browser, desktop, mobile. But there is always an important feature - the frontend needs data. Without a backend that provides this data, it is useless. Here is a fairly clear border. The backend knows how to go to databases, apply business rules to the received data and give the result to the frontend, which will accept the data, template it and give beauty to the user.
We can say that conceptually the backend is needed by the frontend to receive and save data. Example: a typical modern site with a client-server architecture. The client in the browser (to call it thin the language will no longer turn) knocks on the server where the backend is running. And of course there are exceptions everywhere. There are complex browser applications that do not need a server (we will not consider this case), and there is a need to execute a frontend on the server - what is called Server Side Rendering or SSR. Let's start with it, because this is the simplest and most understandable case.
SSR
The ideal world for the backend looks like this: HTTP requests with data arrive at the input of the application, and at the output we have a response with new data in a convenient format. For example JSON. HTTP APIs are easy to test and understand how to develop. However, life makes adjustments: sometimes API alone is not enough.
The server should respond with ready-made HTML to feed it to the search engine crawler, render a preview with meta tags for insertion into the social network, or, more importantly, speed up the response on weak devices. Just like in ancient times when we developed Web 2.0 in PHP.
Everything is familiar and has been described for a long time, but the client has changed - imperative client-side template engines have come to it. In the modern web, JSX rules the ball, the pros and cons of which can be discussed for a long time, but one thing cannot be denied - in server rendering you cannot do without JavaScript code.
It turns out when you need to implement SSR by back-end development:
- Areas of responsibility are mixed. Backend programmers are starting to be in charge of rendering.
- Languages are mixed. Backend programmers get started with JavaScript.
The way out is to separate the SSR from the backend. In the simplest case, we take a JavaScript runtime, put a self-written solution or a framework (Next, Nuxt, etc.) on it that works with the JavaScript template engine we need, and pass traffic through it. A familiar pattern in the modern world.
So we have already allowed front-end developers to the server a little. Let's move on to a more important issue.
Receiving data
A popular solution is to create generic APIs. This role is most often taken on by API Gateway, which is able to poll a variety of microservices. However, problems arise here too.
First, the problem of teams and areas of responsibility. A modern large application is developed by many teams. Each team is focused on its business domain, has its own microservice (or even several) on the backend and its own displays on the client. We will not go into the problem of microfronts and modularity, this is a separate complex topic. Suppose the client views are completely separate and are mini-SPA (Single Page Application) within one large site.
Each team has front-end and back-end developers. Everyone is working on their own application. API Gateway can be a stumbling block. Who is responsible for it? Who will add new endpoints? A dedicated API superteam that will be always busy solving problems for everyone else on the project? What will be the cost of a mistake? The fall of this gateway will put the whole system down.
Secondly, the problem of redundant / insufficient data. Let's take a look at what happens when two different frontends use the same generic API.

These two frontends are very different. They need different datasets, they have different release cycles. The variability of versions of the mobile frontend is maximum, so we are forced to design the API with maximum backward compatibility. The variability of the web client is low, in fact we only need to support one previous version to reduce the number of bugs at the time of release. But even if the “generic” API only serves web clients, we still face the problem of redundant or insufficient data.
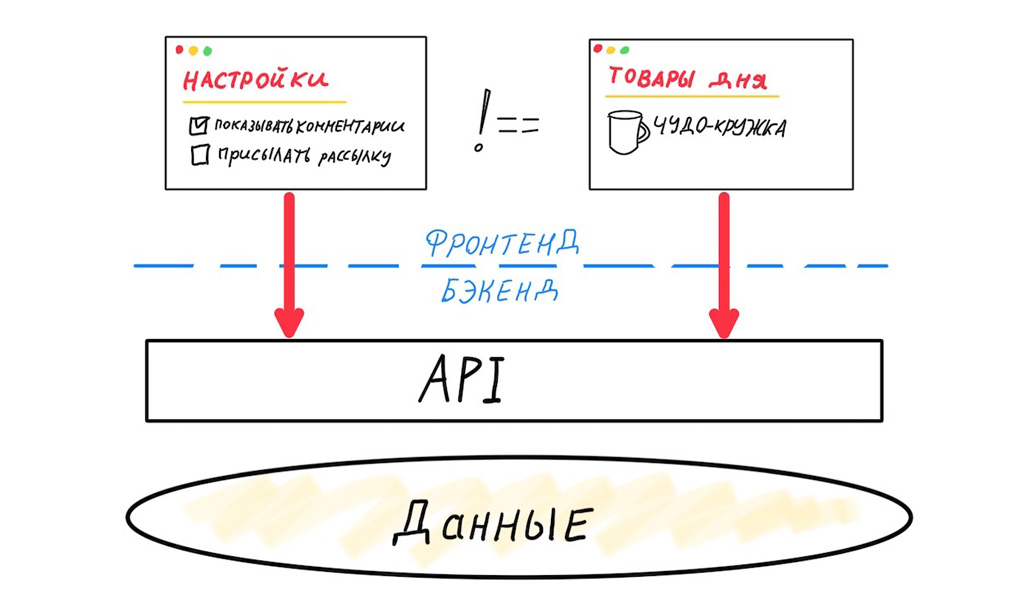
Each mapping requires a separate data set, which can be retrieved with one optimal query.
In this case, a universal API will not work for us, we will have to separate the interfaces. This means that you need your own API Gateway for eachfrontend. The word "each" here denotes a unique mapping that operates on its own dataset.

We can entrust the creation of such an API to a backend developer who will have to work with the frontend and implement his wishes, or, which is much more interesting and in many ways more efficient, give the implementation of the API to the frontend team. This will remove the headache due to the SSR implementation: you no longer need to install a layer that knocks on the API, everything will be integrated into one server application. In addition, by controlling the SSR, we can put all the necessary primary data on the page at the time of rendering, without making additional requests to the server.
This architecture is called Backend For Frontend or BFF. The idea is simple: a new application appears on the server that listens for client requests, polls backends, and returns the optimal response. And of course, this application is controlled by the front-end developer.

More than one server in the backend? Not a problem!

Regardless of what communication protocol backend development prefers, we can use any convenient way to communicate with the web client. REST, RPC, GraphQL - we choose ourselves.
But isn't GraphQL by itself the solution to the problem of getting data in a single query? Maybe you don't need to fence any intermediate services?
Unfortunately, efficient work with GraphQL is impossible without close cooperation with backend developers who take on the task of developing efficient database queries. By choosing such a solution, we will again lose control over the data and return to where we started.

It is possible, of course, but not interesting (for a frontend)
Well, let's implement BFF. Of course, in Node.js. Why? We need a single language on the client and server to reuse the experience of front-end developers and JavaScript to work with templates. What about other runtime environments?

GraalVM and other exotic solutions are inferior to V8 in performance and are too specific. Deno is still an experiment and is not used in production.
And one moment. Node.js is a surprisingly good solution for implementing API Gateway. The Node architecture allows for a single-threaded JavaScript interpreter combined with libuv, an asynchronous I / O library that in turn uses a thread pool.
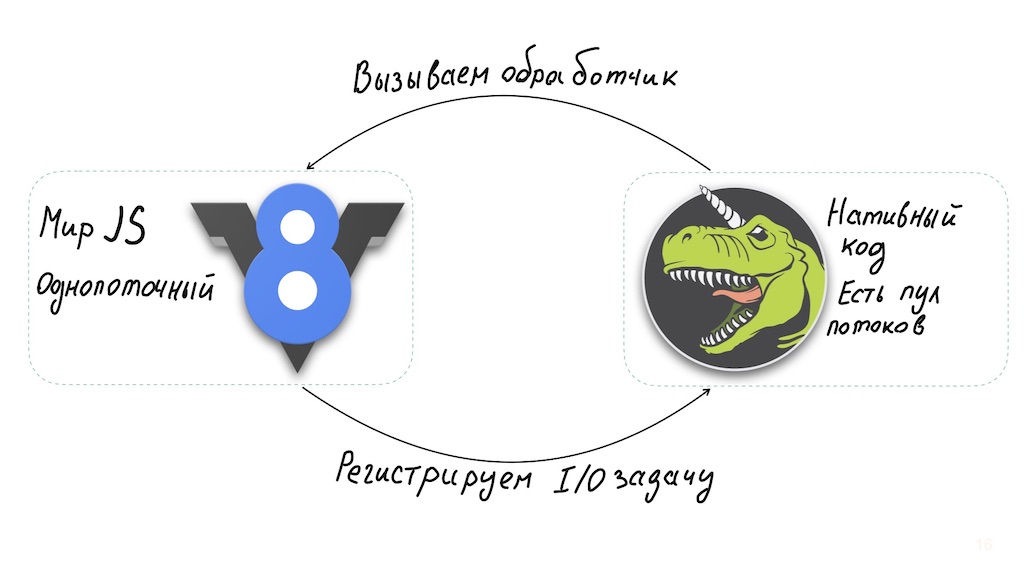
Long calculations on the JavaScript side hit the system performance. You can work around this: run them in separate workers or take them to the level of native binary modules.
But in the basic case, Node.js is not suitable for CPU-intensive operations, and at the same time, it works great with asynchronous I / O, providing high performance. That is, we get a system that can always quickly respond to the user, regardlesson how busy the backend is. You can handle this situation by instantly notifying the user to wait for the end of the operation.
Where to store business logic
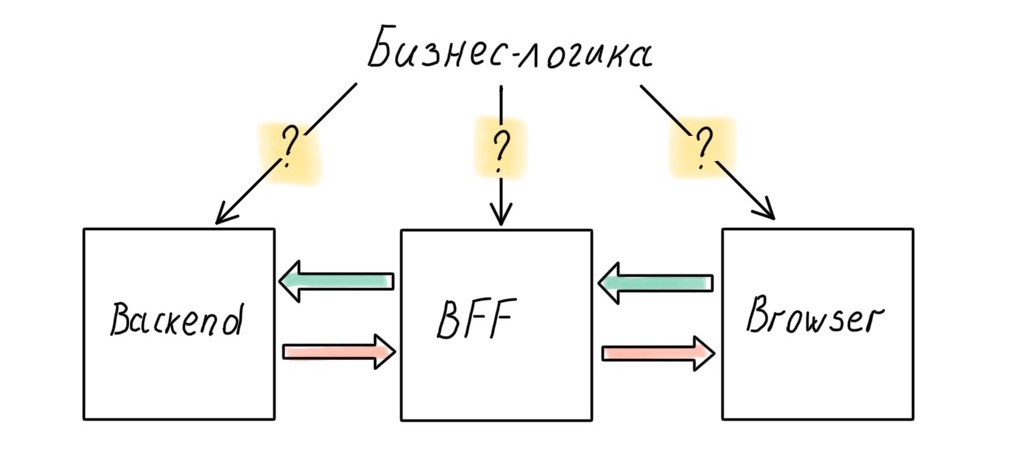
Our system now has three big parts: backend, frontend and BFF in between. A reasonable (for an architect) question arises: where is the business logic to be kept?

Of course, an architect does not want to smear business rules across all layers of the system; there should be one source of truth. And that source is the backend. Where else to store high-level policies, if not in the part of the system closest to the data?

But in reality, this does not always work. For example, a business problem comes in that can be efficiently and quickly implemented at the BFF level. Perfect system design is great, but time is money. Sometimes you have to sacrifice the cleanliness of the architecture, and the layers begin to leak.
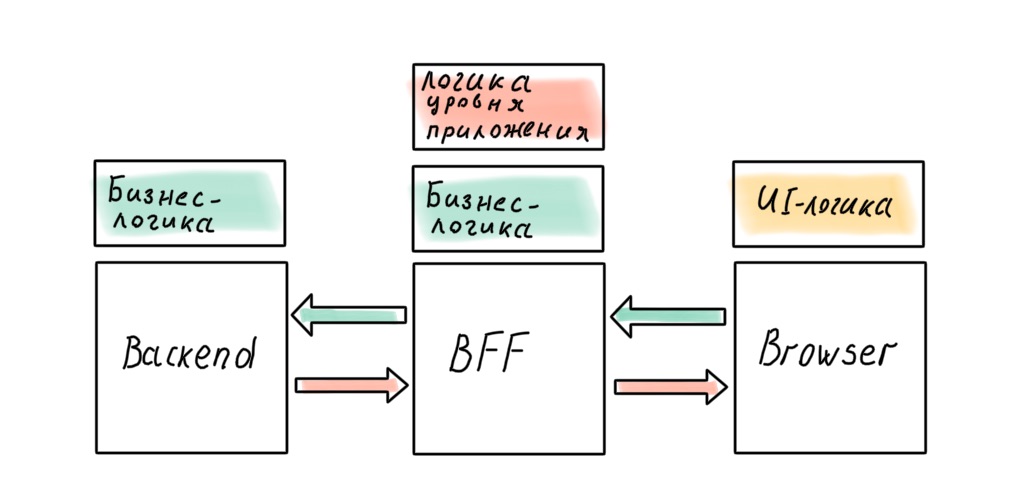
Can we get the perfect architecture by ditching the BFF in favor of a "full" Node.js backend? It seems that in this case there will be no leaks.
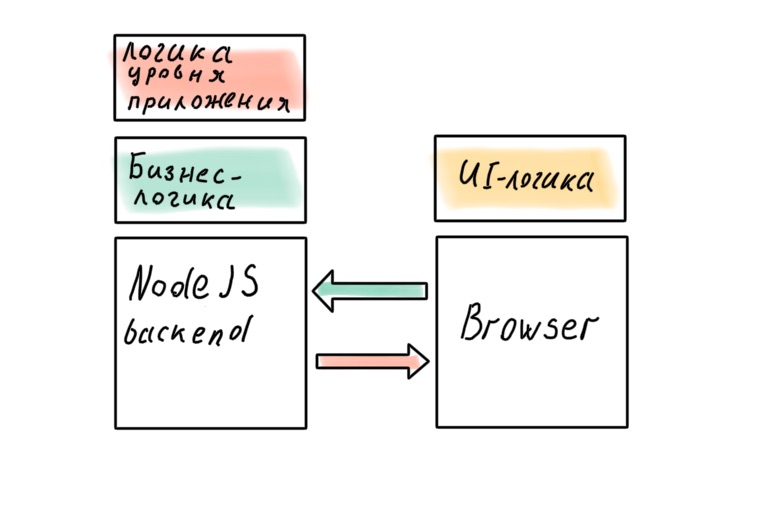
Is not a fact. There will be business rules that, if transferred to the server, will affect the responsiveness of the interface. You can resist this to the last, but most likely you will not be able to avoid it completely. Application-level logic will also penetrate the client: in modern SPA it is smeared between the client and the server, even in the case when there is a BFF.

No matter how hard we try, business logic will infiltrate the API Gateway on Node.js. Let's fix this conclusion and move on to the most delicious - implementation!
Big ball of mud
The most popular solution for Node.js applications in recent years is Express. Proven, but too low-level and does not offer good architectural approaches. The main pattern is middleware. A typical application in the Express like a big lump of mud (it is not name-calling, and antipattern ).
const express = require('express');
const app = express();
const {createReadStream} = require('fs');
const path = require('path');
const Joi = require('joi');
app.use(express.json());
const schema = {id: Joi.number().required() };
app.get('/example/:id', (req, res) => {
const result = Joi.validate(req.params, schema);
if (result.error) {
res.status(400).send(result.error.toString()).end();
return;
}
const stream = createReadStream( path.join('..', path.sep, `example${req.params.id}.js`));
stream
.on('open', () => {stream.pipe(res)})
.on('error', (error) => {res.end(error.toString())})
});All layers are mixed, in one file there is a controller, where everything is there: infrastructure logic, validation, business logic. It's painful to work with this, you don't want to maintain such code. Can we write enterprise-level code in Node.js?

This requires a codebase that is easy to maintain and develop. In other words, you need architecture.
Node.js application architecture (finally)
"The goal of software architecture is to reduce the human effort involved in building and maintaining a system."
Robert "Uncle Bob" Martin
Architecture consists of two important things: layers and the connections between them. We need to break our application into layers, prevent leaks from one to another, properly organize the hierarchy of layers and the connections between them.
Layers
How do I split my application into layers? There is a classic three-tiered approach: data, logic, presentation.
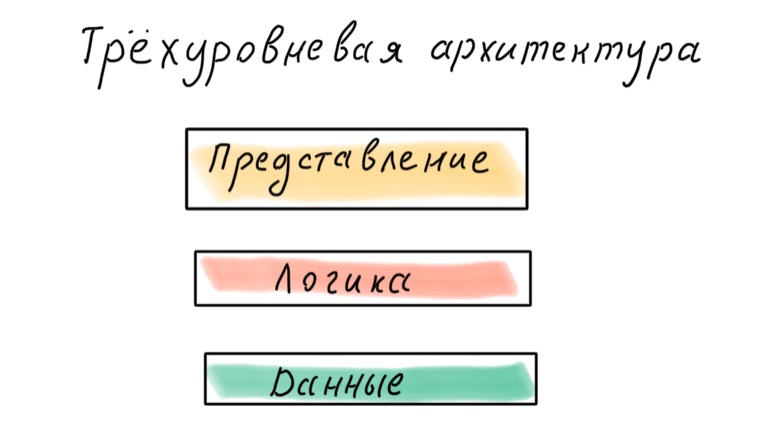
This approach is now considered obsolete. The problem is that data is the basis, which means that the application is designed depending on how the data is presented in the database, and not on what business processes they are involved in.
A more modern approach assumes that the application has a dedicated domain layer that works with business logic and is a representation of real business processes in code. However, if we turn to the classic work of Eric Evans Domain-Driven Design , we will find there the following application layer scheme:

What's wrong here? It would seem that the basis of a DDD-designed application should be a domain - high-level policies, the most important and valuable logic. But under this layer lies the entire infrastructure: data access layer (DAL), logging, monitoring, etc. That is, policies of a much lower level and of less importance.
The infrastructure is at the center of the application, and a banal replacement of the logger can lead to a shake-up of all business logic.
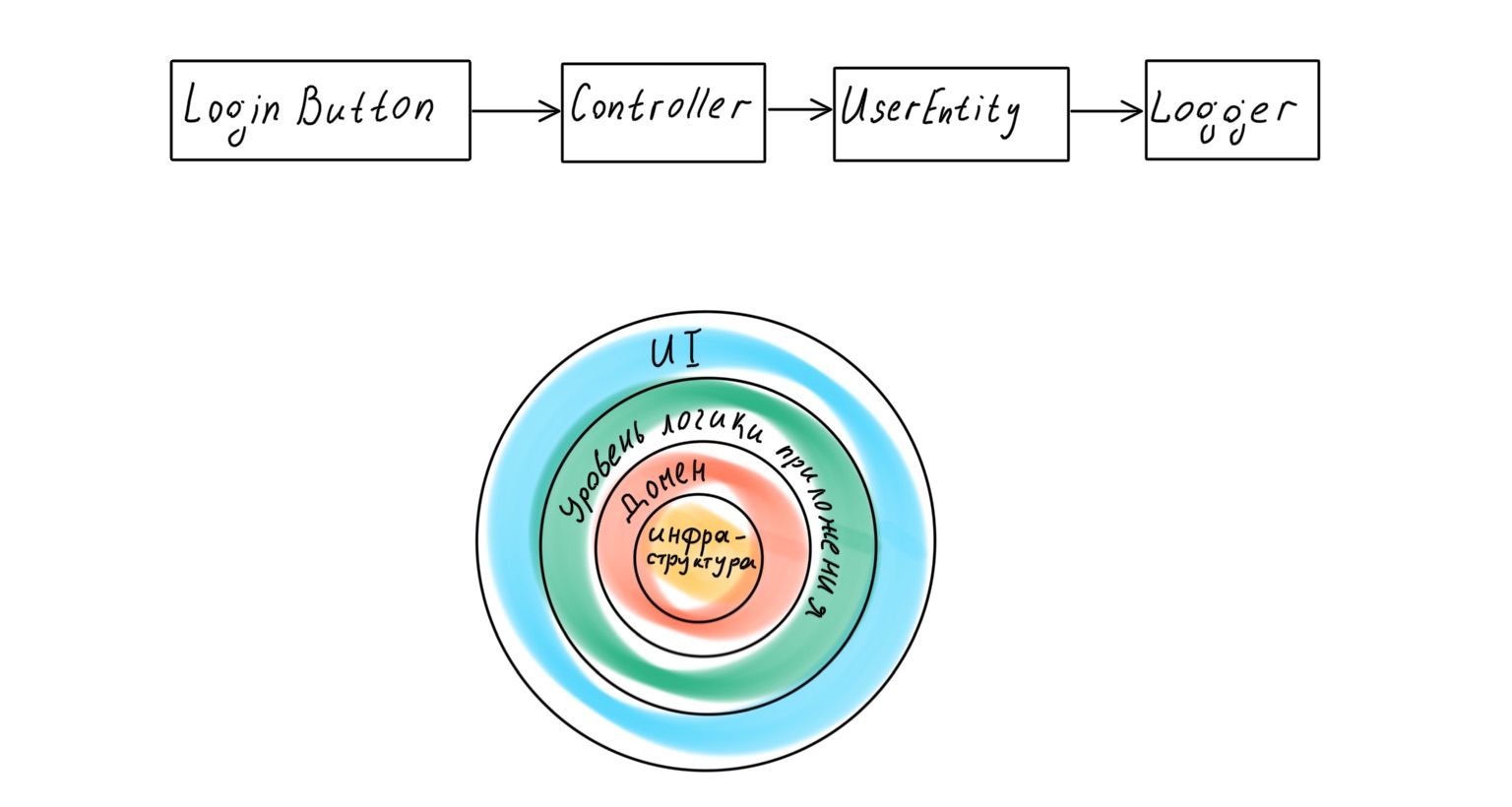
If we turn to Robert Martin again, we find that in the book Clean Architecture he postulates a different layer hierarchy in the application, with the domain in the center.
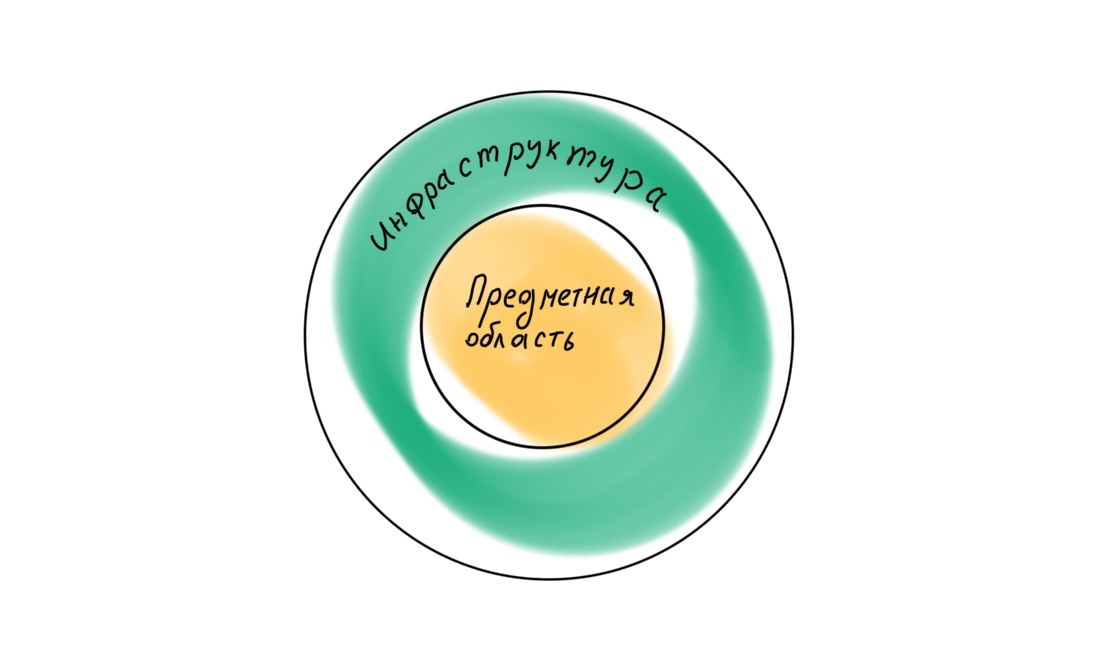
Accordingly, all four layers should be arranged differently:
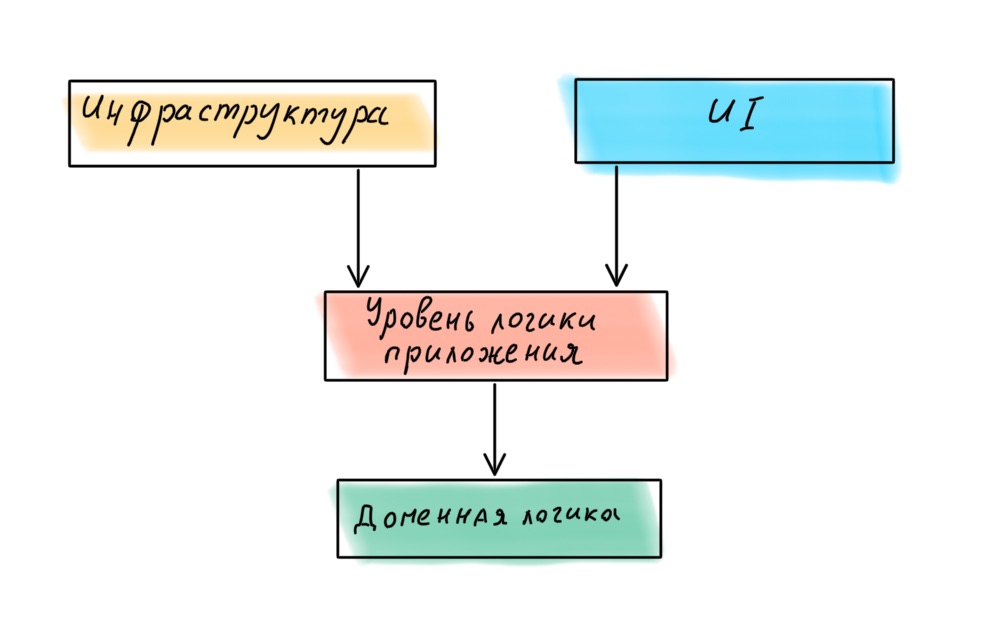
We have selected the layers and defined their hierarchy. Now let's move on to the connections.
Connections
Let's go back to the example with the user logic call. How to get rid of the direct dependency on the infrastructure to ensure the correct layer hierarchy? There is a simple and well-known way to reverse dependencies - interfaces.

Now the high-level UserEntity does not depend on the low-level Logger. On the contrary, it dictates the contract that must be implemented in order to include the Logger in the system. Replacing the logger in this case comes down to connecting a new implementation that observes the same contract. An important question is how to connect it?
import {Logger} from ‘../core/logger’;
class UserEntity {
private _logger: Logger;
constructor() {
this._logger = new Logger();
}
...
}
...
const UserEntity = new UserEntity();The layers are rigidly connected. There is a tie to the file structure and implementation. We need Dependency Inversion, which we will do using Dependency Injection.
export class UserEntity {
constructor(private _logger: ILogger) { }
...
}
...
const logger = new Logger();
const UserEntity = new UserEntity(logger);Now the "domain" UserEntity knows nothing more about the implementation of the logger. It provides a contract and expects the implementation to conform to that contract.
Of course, manually generating instances of infrastructure entities is not the most pleasant thing. We need a root file in which we will prepare everything, we will have to somehow drag the created instance of the logger through the entire application (it is advantageous to have one, not create many). Tiring. And this is where IoC containers come into play and can take over this bollerplate work.
What might using a container look like? For example, like this:
export class UserEntity {
constructor(@Inject(LOGGER) private readonly _logger: ILogger){ }
}What's going on here? We used the magic of decorators and wrote the instruction: “When creating an instance of UserEntity, inject into its private field _logger an instance of the entity that lies in the IoC container under the LOGGER token. It is expected to conform to the ILogger interface. " And then the IoC container will do everything by itself.
We have selected the layers, decided how we will untie them. It's time to choose a framework.
Frameworks and architecture
The question is simple: by moving away from Express to a modern framework, will we get a good architecture? Let's take a look at Nest:
- written in TypeScript,
- built on top of Express / Fastify, there is compatibility at the middleware level,
- declares the modularity of logic,
- provides an IoC container.
It seems to have everything we need here! They also left the concept of an application as a middleware chain. But what about good architecture?
Dependency Injection in Nest
Let's try to follow the instructions . Since in Nest the term Entity is usually applied to ORM, rename UserEntity to UserService. The logger is supplied by the framework, so we'll inject the abstract FooService instead.
import {FooService} from ‘../services/foo.service’;
@Injectable()
export class UserService {
constructor(
private readonly _fooService: FooService
){ }
}And ... it seems we took a step back! There is injection, but there is no inversion, the dependency is
aimed at implementation, not abstraction.
Let's try to fix it. Option number one:
@Injectable()
export class UserService {
constructor(
private _fooService: AbstractFooService
){ } }We describe and export this abstract service somewhere nearby:
export {AbstractFooService};FooService now uses AbstractFooService. As such, we register it manually in the IoC.
{ provide: AbstractFooService, useClass: FooService }Second option. Let's try the previously described approach with interfaces. Since there are no interfaces in JavaScript, it will not be possible to pull the required entity out of IoC at runtime using reflection. We have to explicitly state what we need. We'll use the @ Inject decorator for this.
@Injectable()
export class UserService {
constructor(
@Inject(FOO_SERVICE) private readonly _fooService: IFooService
){ } }And register by token:
{ provide: FOO_SERVICE, useClass: FooService }We've won the framework! But at what cost? We turned off quite a bit of sugar. This is suspicious and suggests that you shouldn't bundle the entire application into a framework. If I haven't convinced you yet, there are other problems.
Exceptions
Nest is flashed with exceptions. Moreover, he suggests using exception throwing to describe the logic of application behavior.
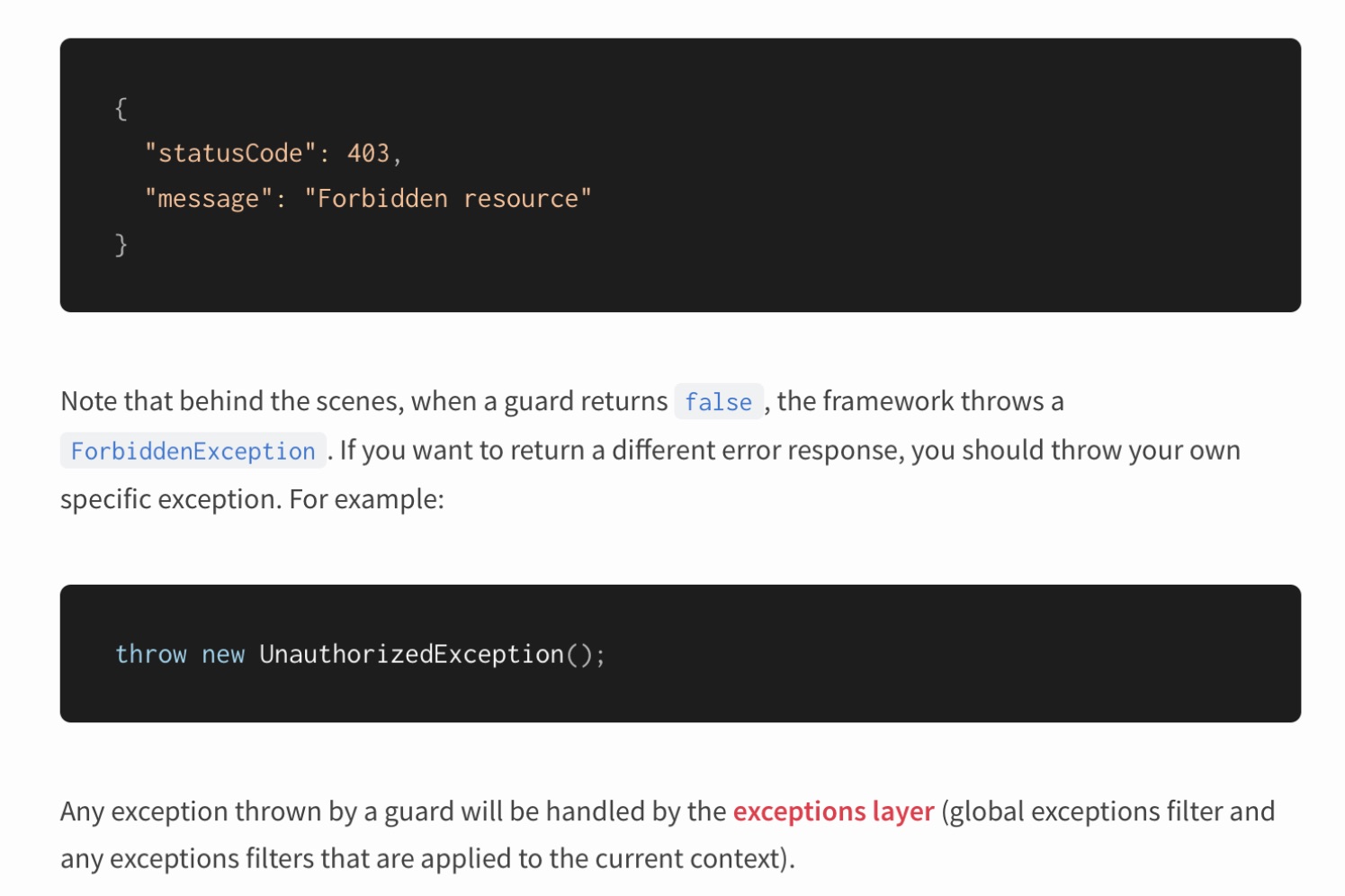
Is everything okay here in terms of architecture? Let's turn to the luminaries again:
"If the error is the expected behavior, then you shouldn't use exceptions."Exceptions suggest an exceptional situation. When writing business logic, we must avoid throwing exceptions. If only for the reason that neither JavaScript nor TypeScript guarantees that the exception will be handled. Moreover, it obfuscates the flow of execution, we start programming in the GOTO style, which means that while examining the behavior of the code, the reader will have to jump throughout the program.
Martin Fowler

There is a simple rule of thumb to help you understand if using exceptions is legal:
"Will the code work if I remove all exception handlers?" If the answer is no, then perhaps exceptions are used in non-exceptional circumstances. "Is it possible to avoid this in business logic? Yes! It is necessary to minimize throwing exceptions, and to conveniently return the result of complex operations, use the Either monad , which provides a container in a state of success or error (a concept very close to Promise).
The Pragmatic Programmer
const successResult = Result.ok(false);
const failResult = Result.fail(new ConnectionError())Unfortunately, inside the entities provided by Nest, we often cannot act otherwise - we have to throw exceptions. This is how the framework works, and this is a very unpleasant feature. And again the question arises: maybe you shouldn't flash the application with a framework? Maybe it will be possible to separate the framework and business logic into different architectural layers?
Let's check.
Nest entities and architectural layers
The harsh truth of life: everything we write with Nest can be stacked in one layer. This is Application Layer.
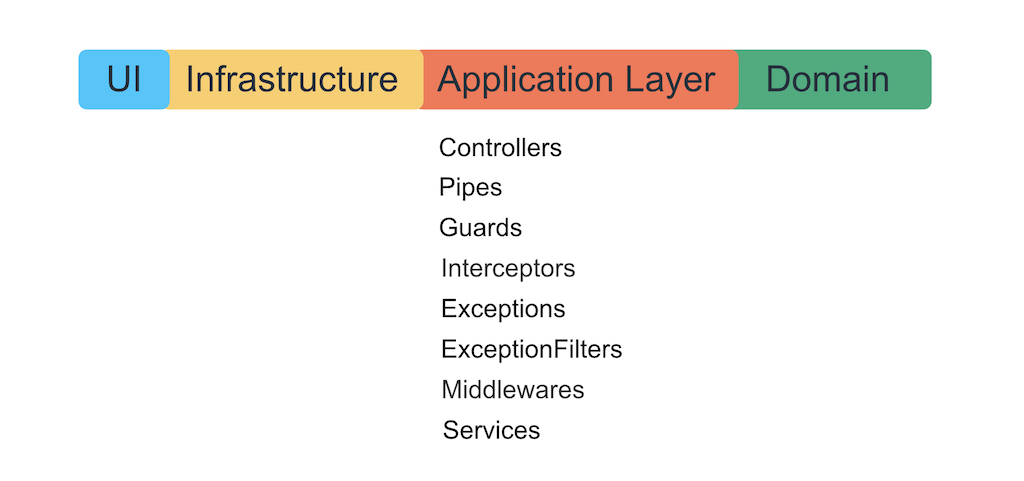
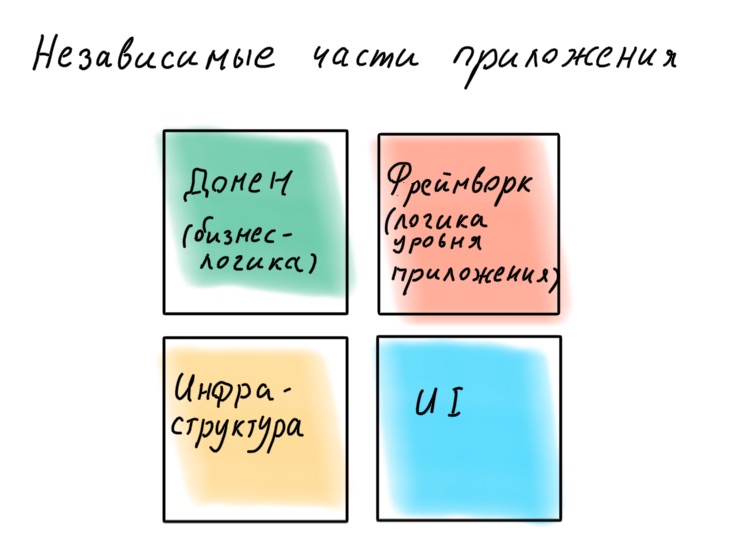
We do not want to let the framework go deeper into the business logic, so that it does not grow into it with its exceptions, decorators and IoC container. The authors of the framework will roll out how great it is to write business logic using its sugar, but their task is to tie you to themselves forever. Remember that a framework is just a way to conveniently organize application-level logic, connect the infrastructure and UI to it.

"A framework is a detail."
Robert "Uncle Bob" Martin
It is better to design an application as a constructor in which it is easy to replace components. One example of such an implementation is the hexagonal architecture ( port and adapter architecture ). The idea is interesting: the domain core with all the business logic provides ports for communicating with the outside world. Everything that is needed is connected externally via adapters.
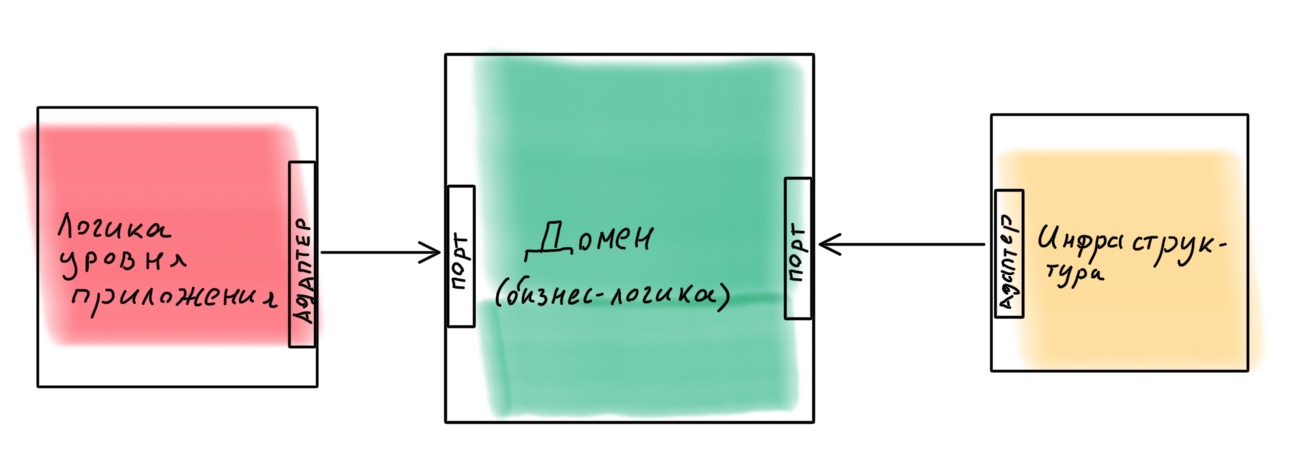
Is it realistic to implement such an architecture in Node.js using Nest as a framework? Quite. I made a lesson with an example, if you are interested - you can find it here .
Let's sum up
- Node.js is good for BFFs. You can live with her.
- There are no ready-made solutions.
- Frameworks are not important.
- If your architecture becomes too complex, if you run into typing, you may have chosen the wrong tool.
I recommend these books:
- Robert Martin, "Clean Architecture",
- Vaughn Vernon, Domain-Driven Design Distilled,
- Khalil Stemmler, khalilstemmler.com,
- Martin Fowler, martinfowler.com/architecture.