In our company, we are actively working on the auto-abstraction of documents, this article did not include all the details and code, but described the main approaches and results using the example of a neutral dataset: 30,000 football sports news articles collected from the Sport-Express information portal.
So, summarization can be defined as the automatic creation of a summary (title, summary, annotation) of the original text. There are 2 significantly different approaches to this problem: extractive and abstractive.
Extractive summarization
The extractive approach consists in extracting the most "significant" information blocks from the source text. A block can be single paragraphs, sentences or keywords.

The methods of this approach are characterized by the presence of an evaluation function of the importance of the information block. By ranking these blocks in order of importance and choosing a previously specified number of them, we form the final summary of the text.
Let's move on to the description of some extractive approaches.
Extractive summation based on the occurrence of common words
This algorithm is very simple to understand and further implement. Here we work only with source code, and by and large we have no need to train any extraction model. In my case, the retrieved information blocks will represent certain sentences of text.
So, at the first step, we break the input text into sentences and break each sentence into tokens (separate words), carry out lemmatization for them (bringing the word to the "canonical" form). This step is necessary in order for the algorithm to combine words that are identical in meaning, but differ in word forms.
Then we set the similarity function for each pair of sentences. It will be calculated as the ratio of the number of common words found in both sentences to their total length... As a result, we get the similarity coefficients for each pair of sentences.
Having previously eliminated sentences that have no common words with others, we construct a graph where the vertices are the sentences themselves, the edges between which show the presence of common words in them.
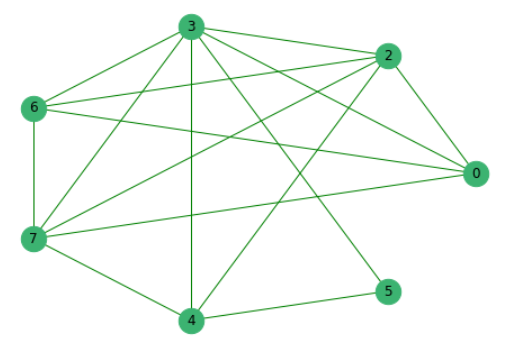
Next, we rank all the proposals according to their importance.

Choosing several sentences with the highest coefficients and then sorting them by the number of their occurrence in the text, we get the final summary.
Extractive summation based on trained vector representations
Previously collected full-text news data was used to construct the next algorithm.
We split the words in all texts into tokens and combine them into a list. In total, the texts contained 2,270,778 words, of which 114,247 were unique.
Using the popular Word2Vec model, we will find its vector representation for each unique word. The model assigns random vectors to each word and further, at each step of learning, “studying the context”, corrects their values. The dimension of the vector, which is able to "remember" the feature of the word, you can set any. Based on the volume of the available dataset, we will take vectors consisting of 100 numbers. I also note that Word2Vec is a retrainable model, which allows you to submit new data to the input and, on their basis, correct the existing vector representations of words.
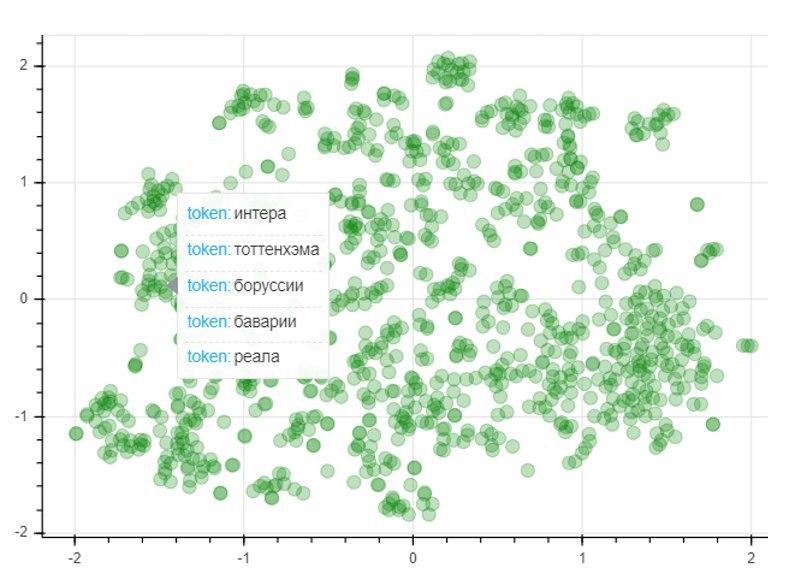
To assess the quality of the model, we will apply the T-SNE dimensionality reduction method, which iteratively constructs a vector mapping for the 1000 most used words into a two-dimensional space. The resulting graph represents the location of points, each of which corresponds to a certain word in such a way that words similar in meaning are located close to each other, and different ones on the contrary. So on the left side of the graph are the names of football clubs, and the dots in the lower left corner represent the names and surnames of football players and coaches:
After obtaining the trained vector representations of words, you can proceed to the algorithm itself. As in the previous case, at the input we have a text that we break into sentences. By tokenizing each sentence, we compose vector representations for them. To do this, we take the ratio of the sum of vectors for each word in the sentence to the length of the sentence itself. Previously trained word vectors help us here. If there is no word in the dictionary, a zero vector is added to the current sentence vector. Thus, we neutralize the influence of the appearance of a new word that is not in the dictionary on the general vector of the sentence.
Next, we compose a sentence similarity matrix that uses the cosine similarity formula for each pair of sentences.
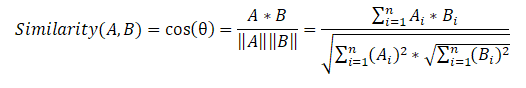
At the last stage, based on the similarity matrix, we also create a graph and perform ranking of sentences by importance. As in the previous algorithm, we get a list of sorted sentences according to their importance in the text.

At the end, I will schematically depict and once again describe the main stages of the algorithm implementation (for the first extractive algorithm, the sequence of actions is exactly the same, except that we do not need to find vector representations of words, and the similarity function for each pair of sentences is calculated based on the occurrence of common words):

- Splitting the input text into separate sentences and processing them.
- Search for a vector representation for each sentence.
- Computing and storing similarity between sentence vectors in a matrix.
- Transformation of the resulting matrix into a graph with sentences in the form of vertices and similarity estimates in the form of edges to calculate the rank of sentences.
- Selection of proposals with the highest score for the final resume.
Comparison of extractive algorithms
Using the Flask microframework (a tool for creating minimalistic web applications ), a test web service was developed to visually compare the output of extractive models using the example of a variety of source news texts. I analyzed the summary generated by both models (retrieving the 2 most significant sentences) for 100 different sports news articles.

Based on the results of comparing the results of determining the most relevant offers by both models, I can offer the following recommendations for using the algorithms:
- . , . , .
- . , , , . , , , .
Abstractive summarization
The abstractive approach differs significantly from its predecessor and consists in generating a summary with the generation of a new text, meaningfully summarizing the primary document.
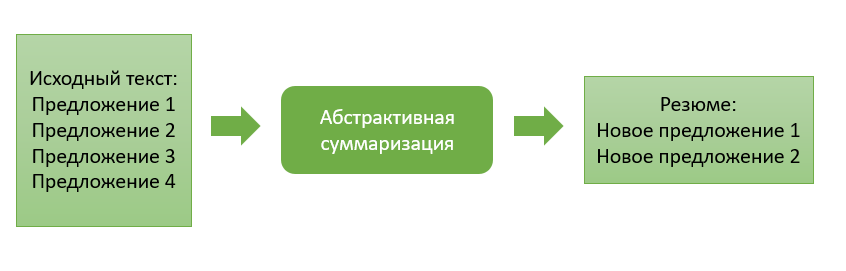
The main idea of this approach is that the model is able to generate a completely unique summary, which may contain words that are not in the original text. Model inference is some retelling of the text, which is closer to the manual compilation of a summary of the text by people.
Learning phase
I will not dwell on the mathematical justification of the algorithm, all the models I know are based on the "encoder-decoder" architecture, which, in turn, is built using recurrent LSTM layers (you can read about the principle of their work here ). I will briefly describe the steps for decoding the test sequence.
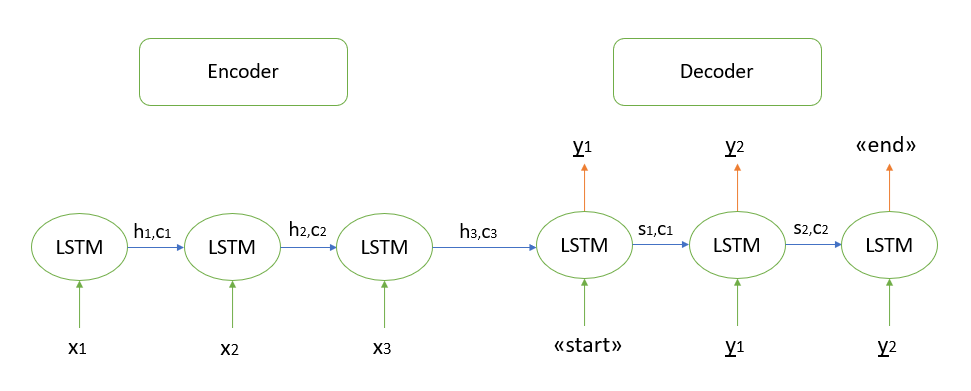
- We encode the entire input sequence and initialize the decoder with the internal states of the encoder
- Pass the "start" token as input to the decoder
- We start the decoder with the internal states of the encoder for one time step, as a result we get the probability of the next word (word with the maximum probability)
- Pass the selected word as input to the decoder at the next time step and update the internal states
- Repeat steps 3 and 4 until we generate the "end" token
More details on the "encoder-decoder" architecture can be found here .
Implementing abstractive summarization
To build a more complex abstractive model for extracting summary content, both full news texts and their headlines are required. The headline of the news will act as a summary, since the model “does not remember well” long text sequences.
When cleaning the data, we use lowercase translation and discarding non-Russian-language characters. Lemmatization of words, removal of prepositions, particles and other uninformative parts of speech will have a negative impact on the final output of the model, since the relationship between words in a sentence will be lost.
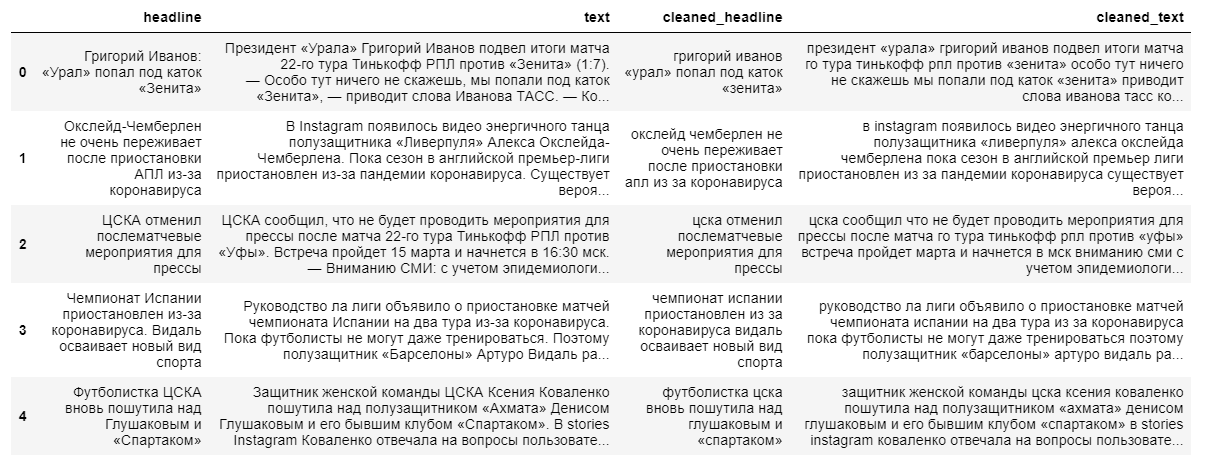
Next, we split the texts and their titles into training and test samples in a ratio of 9 to 1, after which we transform them into vectors (randomly).
At the next step, we create the model itself, which will read the vectors of words transmitted to it and carry out their processing using 3 recurrent layers of the LSTM encoder and 1 layer of the decoder.
After initializing the model, we train it using a cross-entropy loss function that shows the discrepancy between the real target title and the one predicted by our model.

Finally, we output the model result for the training set. As you can see in the examples, the source texts and summaries contain inaccuracies due to the discarding of rare words before building the model (we discard it in order to “simplify learning”).

Model output at this stage leaves much to be desired. The model “successfully remembers” some of the names of clubs and the names of football players, but practically did not catch the context itself.
Despite the more modern approach to resume extraction, this algorithm is still very inferior to previously created extractive models. Nevertheless, in order to improve the quality of the model, it is possible to train the model on a larger dataset, but, in my opinion, in order to get a really good model output, it is necessary to change or, possibly, completely change the very architecture of the neural networks used.
So which approach is better?
Summing up this article, I will list the main pros and cons of the reviewed approaches for extracting a summary:
1. Extractive approach:
Advantages:
- The essence of the algorithm is intuitive
- Relative ease of implementation
Disadvantages:
- Content quality can in many cases be worse than human handwritten content
2. Abstractive approach:
Advantages:
- A well-implemented algorithm is able to produce a result that is closest to manual resume writing
Disadvantages:
- Difficulties in perceiving the main theoretical ideas of the algorithm
- Large labor costs in the implementation of the algorithm
There is no definite answer to the question of which approach will best form the final resume. It all depends on the specific task and goals of the user. For example, an extractive algorithm is most likely better suited for generating the content of multi-page documents, where the extraction of relevant sentences can indeed correctly convey the idea of a large text.
In my opinion, the future belongs to abstractive algorithms. Despite the fact that at the moment they are poorly developed and at a certain level of output quality they can only be used to generate small summaries (1-2 sentences), it is worth expecting a breakthrough from neural network methods. In the future, they are able to form content for absolutely any size of texts and, most importantly, the content itself will be as close as possible to the manual drawing up of a resume by an expert in a particular field.
Veklenko Vlad, Systems Analyst,
Codex Consortium