- Embedded devices and IoT.
- Data analysis.
- Transferring data from one system to another.
- Data archiving and (or) packing data into containers.
- Data storage in an external or temporary database.
- A substitute for a corporate database used for demonstration or test purposes.
- Training, mastering by beginners of practical techniques of working with a database.
- Prototyping and researching experimental extensions of the SQL language.
You can find other reasons for using this database in the SQLite documentation . This article is about using SQLite in Python development. Therefore, it is especially important for us that this DBMS, represented by the module , is included in the standard library of the language. That is, it turns out that to work with SQLite from Python code, you do not need to install any client-server software, you do not need to support the operation of some service responsible for working with the DBMS. All you need to do is to import the module and start using it in the program, having received the relational database management system at your disposal.
sqlite3sqlite3
Module import
Above I said that SQLite is a DBMS built into Python. This means that in order to start working with it, it is enough to import the corresponding module without first installing it using a command like
pip install. The SQLite import command looks like this:
import sqlite3 as sl
Creating a connection to the database
To establish a connection to a SQLite database, you do not need to worry about installing drivers, preparing connection strings, and other such things. You can create a database and get at your disposal a connection object to it very simply and quickly:
con = sl.connect('my-test.db')
By executing this line of code, we will create a database and connect to it. The point here is that the database to which we are connecting does not exist yet, so the system automatically creates a new empty database. If the database has already been created (suppose this is
my-test.dbfrom the previous example), in order to connect to it, you just need to use exactly the same code.

Newly created database file
Creating a table
Now let's create a table in our new database:
with con:
con.execute("""
CREATE TABLE USER (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT,
age INTEGER
);
""")
This describes how to add a table
USERwith three columns to the database . As you can see, SQLite is a very simple database management system indeed, but it has all the basic capabilities that you would expect from a conventional relational database management system. We are talking about support for data types, including - types that allow a value null, support for primary key and autoincrement.
If this code functions as expected (the above command, however, does not return anything), we will have a table at our disposal, ready for further work with it.
Inserting records into a table
Let's insert some records into the table
USERwe just created. This, among other things, will give us proof that the table was indeed created by the above command.
Let's imagine that we need to add several records to the table with one command. It's very easy to do this in SQLite:
sql = 'INSERT INTO USER (id, name, age) values(?, ?, ?)'
data = [
(1, 'Alice', 21),
(2, 'Bob', 22),
(3, 'Chris', 23)
]
Here we need to define an SQL expression with question marks (
?) as placeholders. Given that we have a database connection object at our disposal, we, having prepared the expression and data, can insert records into the table:
with con:
con.executemany(sql, data)
After executing this code, no error messages are received, which means that the data has been successfully added to the table.
Executing Database Queries
Now it's time to find out if the commands we just ran have worked correctly. Let's execute a query to the database and try to get
USERsome data from the table . For example - we get records related to users whose age does not exceed 22 years:
with con:
data = con.execute("SELECT * FROM USER WHERE age <= 22")
for row in data:
print(row)
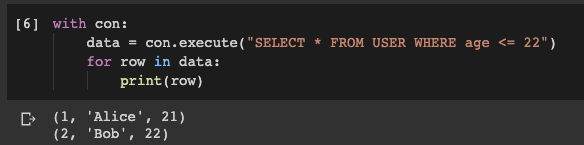
The result of executing a query to the database
As you can see, we managed to get what was needed. And it was very easy to do it.
In addition, even though SQLite is a simple DBMS, it has extremely broad support. Therefore, you can work with it using most SQL clients.
I am using DBeaver. Let's take a look at how it looks.
Connecting to SQLite database from SQL client (DBeaver)
I am using Google Colab cloud service and want to download a file
my-test.dbto my computer. If you are experimenting with SQLite on a computer, it means that you can connect to it using the SQL client without having to download the database file from somewhere.
In the case of DBeaver, to connect to the SQLite database, you need to create a new connection and select SQLite as the database type.
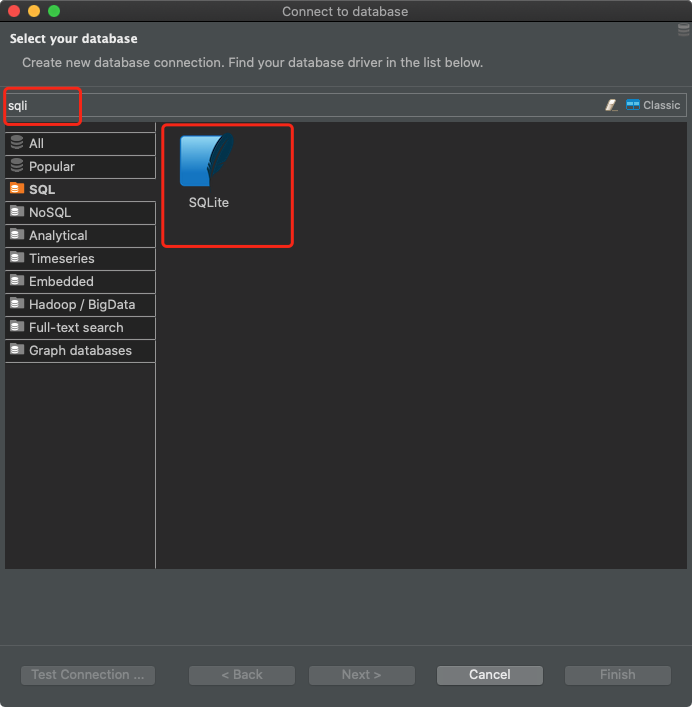
Preparing the connection in DBeaver
Next, you need to find the database file.
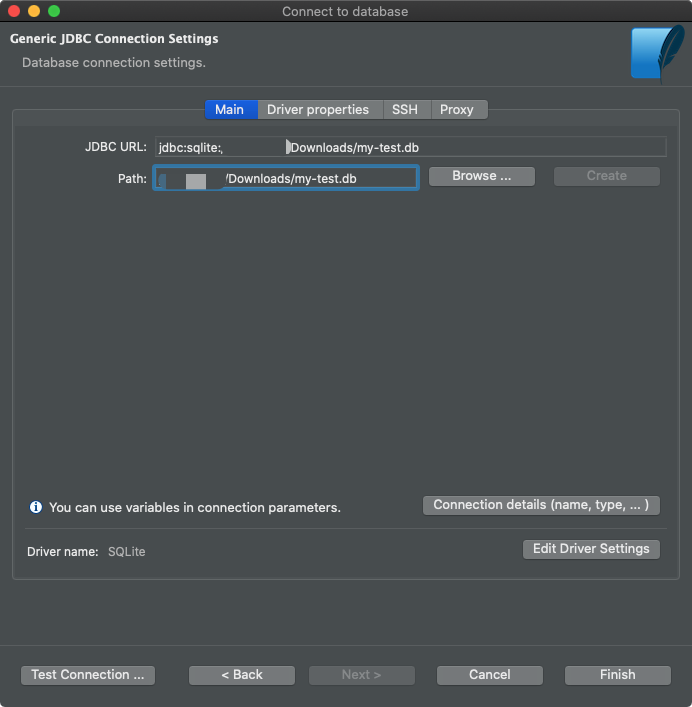
Connecting the database file
After that, you can execute SQL queries against the database. There is nothing special here, different from working with regular relational databases.
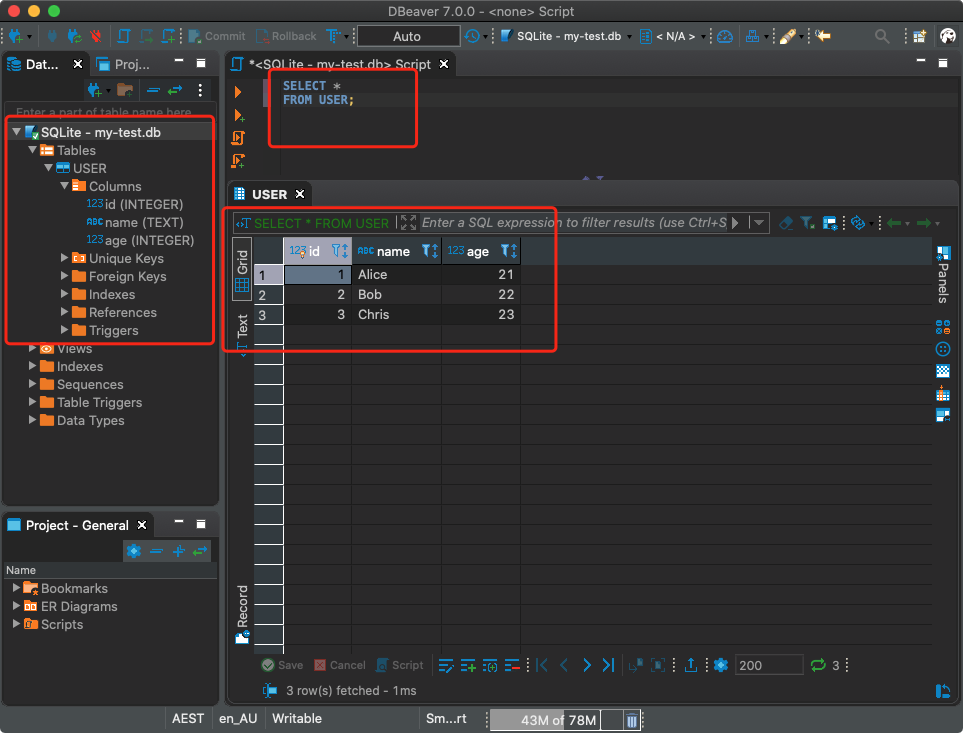
Executing Database Queries
Integration with pandas
Do you think this is where we wrap up our conversation about SQLite support in Python? No, we still have a lot to talk about. Namely, because SQLite is a standard Python module, it integrates easily with pandas data frames.
Let's declare the dataframe:
df_skill = pd.DataFrame({
'user_id': [1,1,2,2,3,3,3],
'skill': ['Network Security', 'Algorithm Development', 'Network Security', 'Java', 'Python', 'Data Science', 'Machine Learning']
})
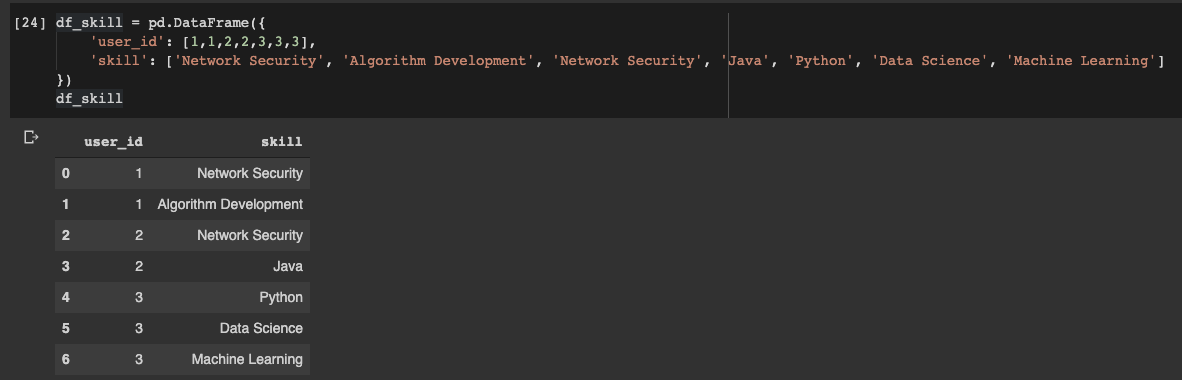
Pandas dataframe
To save a dataframe to the database, you can simply use its method
to_sql():
df_skill.to_sql('SKILL', con)
That's all! We don't even need to create a table beforehand. The data types and characteristics of the fields will be configured automatically based on the characteristics of the dataframe. Of course, you can customize everything yourself if needed.
Now suppose we need to get the union of the tables
USERand SKILL, and write the data in datafreym pandas. It's very simple too:
df = pd.read_sql('''
SELECT s.user_id, u.name, u.age, s.skill
FROM USER u LEFT JOIN SKILL s ON u.id = s.user_id
''', con)
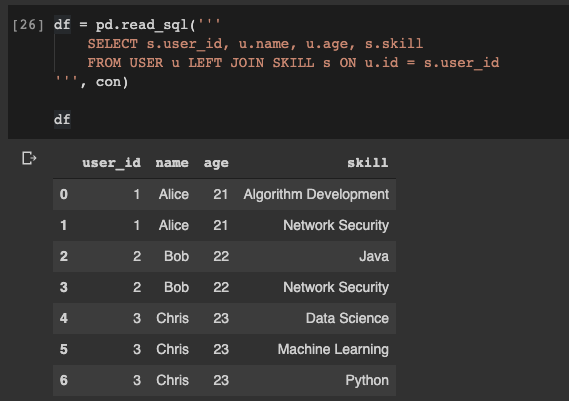
Reading data from a database into a pandas dataframe
Great! Now let's write what we got to a new table called
USER_SKILL:
df.to_sql('USER_SKILL', con)
Of course, you can work with this table using the SQL client.
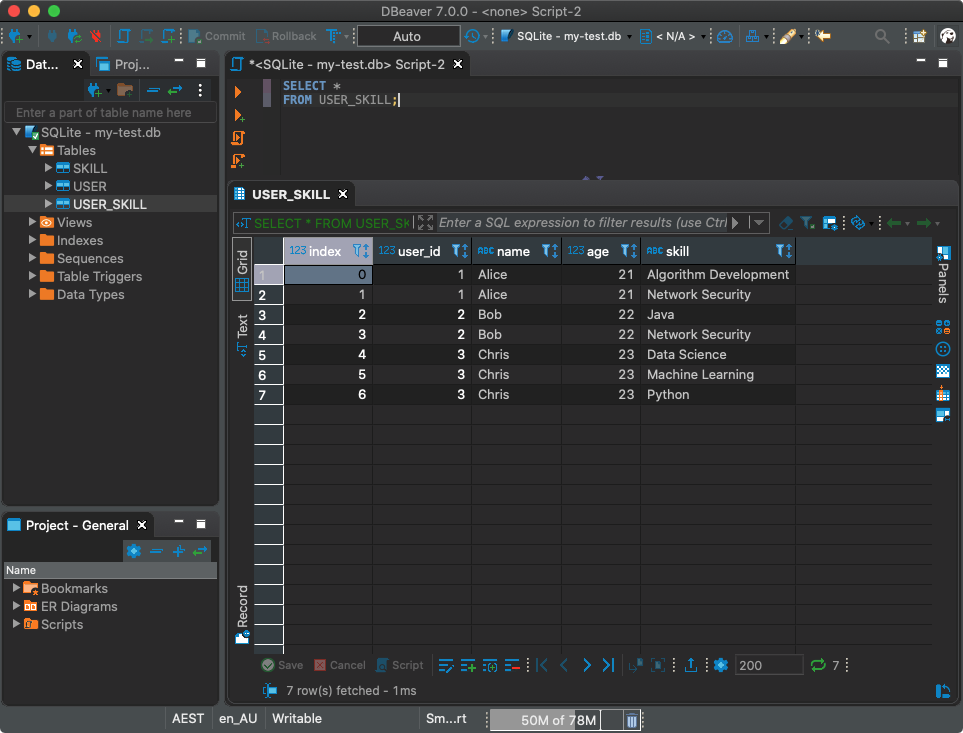
Using a SQL client to work with a database
Outcome
There are certainly many pleasant surprises in Python that, unless you specifically look for them, you might not notice. Nobody hid such features specially, but due to the fact that a lot of things are built into Python, you can simply not pay attention to some of these features, or, having learned about them from somewhere, just forget about them.
Here I talked about how to use the built-in Python library
sqlite3to create and work with databases. Of course, such databases support not only the operation of adding data, but also operations of changing and deleting information. I suppose you, having learned about sqlite3, will experience it all yourself.
The very important thing is that SQLite does a great job with pandas. It is very easy to read data from a database by placing it in dataframes. The operation of saving the contents of dataframes to a database is no less simple. This makes SQLite even easier to use.
I invite everyone who has read this far to do their own research looking for interesting Python features!
The code I have demonstrated in this article can be found here .
Do you use SQLite in your Python projects?
