Repeat, but every time in a new way - isn't this art?
Stanislav Jerzy Lec, from the book "Uncombed Thoughts"
The dictionary defines replication as the process of maintaining two (or more) sets of data in a consistent state. What is the "consistent state of datasets" is a separate big question, so let's reformulate the definition in a simpler way: the process of changing one dataset, called a replica, in response to changes in another dataset, called the master. The sets are not necessarily the same.

Database replication support is one of the most important tasks of an administrator: almost every database of any importance has a replica, or even more than one.
Replication tasks include at least
- support of the backup database in case of loss of the main one;
- reducing the load on the base due to the transfer of part of the requests to replicas;
- transfer of data to archival or analytical systems.
In this article I will talk about the types of replication and what tasks each type of replication solves.
There are three approaches to replication:
- Block replication at the storage system level;
- Physical replication at the DBMS level;
- Logical replication at the DBMS level.
Block replication
With block replication, each write operation is performed not only on the primary disk, but also on the backup. Thus, a volume on one array corresponds to a mirrored volume on another array, repeating the main volume with a byte precision:
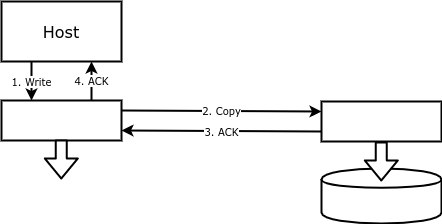
The advantages of such replication include ease of setup and reliability. Either a disk array or something (a device or software) between the host and the disk can write data to a remote disk.
Disk arrays can be supplemented with options to enable replication. The option name depends on the array manufacturer:
| Manufacturer | Trademark
|
|---|---|
| EMC | SRDF (Symmetrix Remote Data Facility) |
| IBM | Metro Mirror - synchronous replication
Global Mirror - asynchronous replication |
| Hitachi | TrueCopy |
| Hewlett-Packard | Continuous Access |
| Huawei | HyperReplication |
If the disk array is not capable of replicating data, an agent can be installed between the host and the array, which writes to two arrays at once. An agent can be either a standalone device (EMC VPLEX) or a software component (HPE PeerPersistence, Windows Server Storage Replica, DRBD). Unlike a disk array, which can only work with the same array, or at least with an array from the same manufacturer, an agent can work with completely different disk devices.
The main purpose of block replication is to provide fault tolerance. If the database is lost, you can restart it using the mirrored volume.
Block replication is great for its versatility, but versatility comes at a price.
First, no server can handle a mirrored volume, because its operating system cannot control writes to it; from the point of view of an observer, the data on the mirrored volume appears by itself. In the event of a disaster (failure of the primary server or the entire data center where the primary server is located), you should stop replication, unmount the primary volume, and mount the mirrored volume. As soon as possible, you should restart replication in the opposite direction.
In the case of using an agent, all these actions will be performed by the agent, which simplifies configuration, but does not reduce the switching time.
Secondly, the DBMS itself on the standby server can be started only after the disk is mounted. In some operating systems, for example, in Solaris, the memory for the cache is marked up during allocation, and the marking time is proportional to the amount of allocated memory, that is, the start of the instance will not be instantaneous. Plus, the cache will be empty after restart.
Thirdly, after starting on the backup server, the DBMS will find out that the data on the disk is inconsistent, and you need to spend a significant amount of time recovering using redo logs: first, repeat those transactions, the results of which were saved in the log, but did not have time to be saved to the data files, and then roll back the transactions that did not have time to complete at the time of the failure.
Block replication cannot be used for load balancing, and a similar scheme is used to upgrade the datastore with the mirrored volume on the same array as the primary. EMC and HP call this scheme BCV, only EMC stands for Business Continuance Volume, and HP stands for Business Copy Volume. IBM does not have a special trademark for this case, this scheme is called "mirrored volume".

Two volumes are created in the array and write operations are performed synchronously on both (A). At a certain time, the mirror breaks (B), that is, the volumes become independent. The mirrored volume is mounted to a server dedicated to storage upgrades and a database instance is raised on that server. The instance will take the same amount of time to take up as it would during a block replication restore, but this time can be significantly reduced by breaking the mirror during off-peak periods. The point is that breaking the mirror in its consequences is equivalent to an abnormal termination of the DBMS, and the recovery time in case of abnormal termination depends significantly on the number of active transactions at the time of the crash. The database intended for unloading is available for both reading and writing. All block identifiers,mirrors changed after the break, both on the main and on the mirrored volume, are saved in a special area of Block Change Tracking - BCT.
After the end of the upload, the mirrored volume is unmounted (C), the mirror is restored, and after a while the mirrored volume again catches up with the main one and becomes its copy.
Physical replication
Logs (redo log or write-ahead log) contain all changes that are made to the database files. The idea behind physical replication is that changes from the logs are re-committed to another database (replica), and thus the data in the replica replicates the data in the main database byte-by-byte.
The ability to use database logs to update a replica appeared in the release of Oracle 7.3, which was released in 1996, and already in the release of Oracle 8i, the delivery of logs from the main database to the replica was automated and was named DataGuard. The technology turned out to be so in demand that today the mechanism of physical replication is present in almost all modern DBMS.
| DBMS | Replication option
|
|---|---|
| Oracle | Active DataGuard |
| IBM DB2 | HADR |
| Microsoft SQL Server | Log shipping / Always On |
| PostgreSQL | Log shipping / Streaming replication |
| MySQL | Alibaba physical InnoDB replication |
Experience shows that if the server is used only to keep the replica up-to-date, then about 10% of the processing power of the server on which the main base is running is sufficient for it.
DBMS logs are not intended to be used outside of this platform, their format is not documented and may change without notice. Hence the quite natural requirement that physical replication is possible only between instances of the same version of the same DBMS. Hence, there are possible limitations on the operating system and processor architecture, which can also affect the format of the log.
Naturally, physical replication does not impose any restrictions on storage models. Moreover, the files in the replica database can be located in a completely different way than in the source database - you just need to describe the correspondence between the volumes on which these files are located.
Oracle DataGuard allows you to delete some of the files from the replica database - in this case, changes in the logs related to these files will be ignored.
Physical database replication has many advantages over storage replication:
- the amount of data transferred is less due to the fact that only logs are transferred, but not data files; experiments show a 5-7 times decrease in traffic;
- : - , ; , ;
- , . , .
The ability to read data from a replica was introduced in 2007 with the release of Oracle 11g, as indicated by the epithet "active" added to the name of DataGuard technology. Other DBMSs also have the ability to read from a replica, but this is not reflected in the name.
Writing data to a replica is impossible, since changes come to it byte-by-byte, and the replica cannot provide concurrent execution of its requests. Oracle Active DataGuard in recent releases allows writing to the replica, but this is nothing more than "sugar": in fact, the changes are performed on the main base, and the client is waiting for them to roll to the replica.
If a file in the main database is damaged, you can simply copy the corresponding file from the replica (carefully read the administrator's manual before doing this with your database!). The file on the replica may not be identical to the file in the main database: the fact is that when the file is expanded, new blocks are not filled with anything in order to speed up, and their contents are accidental. The base may not use all the space in the block (for example, there may be free space in the block), but the contents of the used space match up to byte.
Physical replication can be either synchronous or asynchronous. With asynchronous replication, there is always a certain set of transactions that have completed on the main base, but have not yet reached the standby base, and in the event of a transition to the standby base if the main base fails, these transactions will be lost. In synchronous replication, the completion of the commit operation means that all log records related to this transaction have been committed to the replica. It is important to understand that getting a log replica does not mean that the changes are applied to the data. If the main database is lost, transactions will not be lost, but if the application writes data to the main database and reads it from the replica, then it has a chance to get the old version of this data.
In PostgreSQL, it is possible to configure replication so that commit completes only after the changes are applied to the replica data (option
synchronous_commit = remote_apply), while in Oracle, you can configure the entire replica or individual sessions so that queries are executed only if the replica does not lag behind the main database ( STANDBY_MAX_DATA_DELAY=0). However, it is still better to design the application so that writing to the main database and reading from replicas are performed in different modules.
When looking for an answer to the question of which mode to choose, synchronous or asynchronous, Oracle marketers come to our aid. DataGuard provides three modes, each of which maximizes one of the parameters - data safety, performance, availability - at the expense of the others:
- Maximum performance: replication is always asynchronous;
- Maximum protection: ; , commit ;
- Maximum availability: ; , , , .
Despite the undeniable advantages of database replication over block replication, administrators in many companies, especially those with old traditions of reliability, are still very reluctant to abandon block replication. There are two reasons for this.
First, in the case of replication using a disk array, traffic does not go through the data transmission network (LAN), but through the storage area network. Often, in infrastructures built a long time ago, SANs are much more reliable and performant than data networks.
Secondly, synchronous replication by means of a DBMS has become reliable relatively recently. In Oracle, the breakthrough occurred in the 11g release, which came out in 2007, and in other DBMSs, synchronous replication appeared even later. Of course, 10 years by the standards of the information technology sphere is not that short, but when it comes to data security, some administrators are still guided by the principle of “whatever happens” ...
Logical replication
All changes in the database occur as a result of calls to its API - for example, as a result of executing SQL queries. The idea of running the same sequence of queries on two different bases seems very tempting. There are two rules to follow for replication:
- , , . D, A B.
- , , . B , , C.
Replication of commands (statement-based replication) is implemented, for example, in MySQL. Unfortunately, this simple scheme does not result in identical datasets for two reasons.
First, not all APIs are deterministic. For example, if the now () or sysdate () function is encountered in an SQL query, which returns the current time, then it will return different results on different servers - due to the fact that the queries are not executed simultaneously. In addition, different states of triggers and stored functions, different locales affecting sort order, and much more can cause differences.
Second, parallel command-based replication cannot be paused and restarted gracefully.
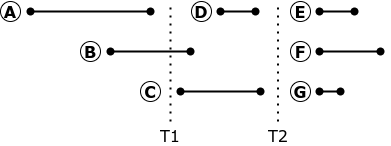
If replication is stopped at time T1, transaction B should be aborted and rolled back. When you restart replication, the execution of transaction B can bring the replica to a state different from the state of the source database: at the source, transaction B started before transaction A ended, which means that it did not see the changes made by transaction A.
Replication of requests can be stopped and restarted only at time T2, when there are no active transactions in the database. Of course, there are no such moments on a heavily loaded industrial base.
Typically, logical replication uses deterministic queries. The determinism of the request is provided by two properties:
- the query updates (or inserts, or deletes) a single record, identifying it by its primary (or unique) key;
- all request parameters are explicitly set in the request itself.
Unlike statement-based replication, this approach is called row-based replication.
Suppose we have an employee table with the following data:
| ID | Name | Dept | Salary
|
|---|---|---|---|
| 3817 | Ivanov Ivan Ivanovich | 36 | 1800 |
| 2274 | Petrov Petr Petrovich | 36 | 1600 |
| 4415 | Kuznetsov Semyon Andreevich | 41 | 2100 |
The following operation was performed on this table:
update employee set salary = salary*1.2 where dept=36;In order to correctly replicate data, the following queries will be executed in the replica:
update employee set salary = 2160 where id=3817;
update employee set salary = 1920 where id=2274;Queries produce the same result as on the original base, but they are not equivalent to executed queries.
The replica base is open and available not only for reading, but also for writing. This allows the replica to be used to execute part of the queries, including for building reports that require the creation of additional tables or indexes.
It is important to understand that a logical replica will be equivalent to the original base only if no additional changes are made to it. For example, if in the example above, in the replica, Sidorov's department is added to 36, then he will not receive a promotion, and if Ivanov is transferred from department 36, he will receive a promotion, no matter what.
Logical replication provides a number of capabilities not found in other types of replication:
- setting up a set of replicated data at the table level (for physical replication - at the file and table space level, for block replication - at the volume level);
- building complex replication topologies - for example, consolidating several databases into one or bi-directional replication;
- decrease in the amount of transmitted data;
- replication between different versions of a DBMS or even between DBMSs from different manufacturers;
- data processing during replication, including changing the structure, enrichment, preservation of history.
There are also disadvantages that do not allow logical replication to supplant physical replication:
- all replicated data must have primary keys;
- logical replication does not support all data types - for example, there may be problems with BLOBs.
- : , ;
- ;
- , , – , .
The last two disadvantages significantly limit the use of a logical replica as a fault tolerance tool. If one query in the main database changes many rows at once, the replica can lag significantly. And the ability to change roles requires remarkable efforts from both developers and administrators.
There are several ways to implement logical replication, and each of these methods implements one part of the capabilities and does not implement the other:
- replication by triggers;
- using DBMS logs;
- use of CDC (change data capture) software;
- applied replication.
Trigger replication
Trigger is a stored procedure that is automatically executed upon any action to modify data. The trigger, which is called when each record changes, has access to the key of that record, as well as the old and new field values. If necessary, the trigger can save new row values to a special table, from where a special process on the replica side will read them. The amount of code in triggers is large, so there is special software that generates such triggers, for example, "merge replication" - a component of Microsoft SQL Server or Slony-I - a separate product for PostgreSQL replication.
Strengths of Trigger Replication:
- independence from the versions of the main base and the replica;
- extensive data conversion capabilities.
Disadvantages:
- load on the main base;
- high replication latency.
Using DBMS Logs
The DBMS themselves can also provide logical replication capabilities. Logs are the source of data, just like for physical replication. The information about the byte change is also supplemented with information about the changed fields (supplemental logging in Oracle,
wal_level = logicalin PostgreSQL), as well as the value of the unique key, even if it does not change. As a result, the volume of database logs is increasing - according to various estimates, from 10 to 15%.
Replication capabilities depend on the implementation in a particular DBMS - if you can build a logical standby in Oracle, then in PostgreSQL or Microsoft SQL Server you can deploy a complex system of mutual subscriptions and publications using the built-in platform tools. In addition, the DBMS provides built-in monitoring and control of replication.
The disadvantages of this approach include an increase in the volume of logs and a possible increase in traffic between nodes.
Using CDC
There is a whole class of software designed to organize logical replication. This software is called CDC, change data capture. Here is a list of the most famous platforms of this class:
- Oracle GoldenGate (acquired by GoldenGate in 2009);
- IBM InfoSphere Data Replication (formerly InfoSphere CDC; even earlier, DataMirror Transformation Server, acquired by DataMirror in 2007);
- VisionSolutions DoubleTake / MIMIX (formerly Vision Replicate1);
- Qlik Data Integration Platform (formerly Attunity);
- Informatica PowerExchange CDC;
- Debezium;
- StreamSets Data Collector ...
The task of the platform is to read the database logs, transform information, transfer information to a replica and apply. As in the case of replication by means of the DBMS itself, the log should contain information about the changed fields. Using an additional application allows you to perform complex transformations of the replicated data on the fly and build fairly complex replication topologies.
Strengths:
- the ability to replicate between different DBMS, including loading data into reporting systems;
- the widest possibilities of data processing and transformation;
- minimal traffic between nodes - the platform cuts off unnecessary data and can compress traffic;
- built-in capabilities to monitor the status of replication.
There are not many disadvantages:
- increase in the volume of logs, as with logical replication by means of a DBMS;
- new software is difficult to configure and / or with expensive licenses.
It is CDC platforms that are traditionally used to update corporate data warehouses in near real time.
Applied replication
Finally, another way of replication is the formation of change vectors directly on the client side. The client must issue deterministic queries that affect a single record. This can be achieved by using a special database library such as the Borland Database Engine (BDE) or Hibernate ORM.
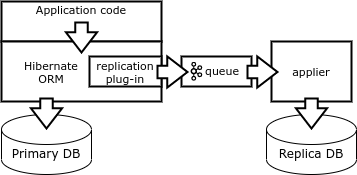
When the application completes the transaction, the Hibernate ORM plugin writes the change vector to the queue and executes the transaction on the database. A special replicator process subtracts vectors from the queue and performs transactions in the replica base.
This mechanism is good for updating reporting systems. It can also be used to provide fault tolerance, but in this case, the application must implement control of the replication state.
Traditionally - strengths and weaknesses of this approach:
- the ability to replicate between different DBMS, including loading data into reporting systems;
- the ability to process and transform data, condition monitoring, etc .;
- minimal traffic between nodes - the platform cuts off unnecessary data and can compress traffic;
- complete independence from the database - both from the format and from the internal mechanisms.
The advantages of this method are undeniable, but there are two very serious disadvantages:
- restrictions on application architecture;
- a huge amount of native replication code.
So which is better?
There is no unequivocal answer to this question, as well as to many others. But I hope that the table below will help you make the right choice for each specific task:
| Storage block replication | Block replication by agent | Physical replication | Logical DBMS replication | CDC |
|
||
|---|---|---|---|---|---|---|---|
| X | X | X/7..X/5 | X/7..X/5 | ≤X/10 | ≤X/10 | ≤X/10 | |
| 5 … | 5 … | 1..10 | 1..10 | 1..2 | 1..2 | 1..2 | |
| + | + | +++ | + | ∅ | ∅ | ∅ | |
| ∅ | ∅ | RO | R/W | R/W | R/W | R/W | |
| - | -
broadcast |
-
broadcast |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
-
broadcast * p2p* |
|
| ∅ | ∅ | – | – – | – – – | – – | ∅ | |
| + + + | + + | + + | + + | – | + | – – – | |
| – – | – – | – | – | ∅ | – – – | ∅ | |
| ∅ | + | + + | + + | + + | + + + | + + + |
- , ; .
- , .
- , .
- .
- , , .
- CDC , / .
- .