
These lakes ( data Lakes ) actually become the standard for businesses and corporations who are trying to use all the information available to them. Open source components are often an attractive option when developing large data lakes. We'll look at the general architectural patterns needed to create a data lake for cloud or hybrid solutions, and also highlight a number of critical details to watch out for when implementing key components.
Data flow design
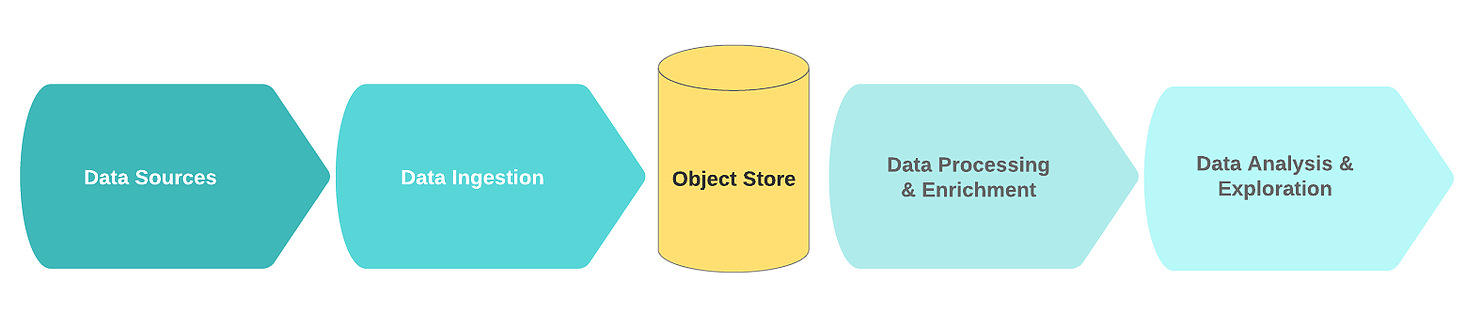
A typical logical data lake flow includes the following functional blocks:
- Data sources;
- Receiving data;
- Storage node;
- Data processing and enrichment;
- Data analysis.
In this context, data sources are typically streams or collections of raw event data (e.g., logs, clicks, IoT telemetry, transactions).
The key feature of such sources is that the raw data is stored in its original form. The noise in this data usually consists of duplicate or incomplete records with redundant or erroneous fields.
At the ingestion stage, raw data comes from one or more data sources. The receiving mechanism is most often implemented in the form of one or more message queues with a simple component aimed at primary cleaning and storing data. In order to build an efficient, scalable, and consistent data lake, it is recommended to distinguish between simple data cleaning and more complex data enrichment tasks. One good rule of thumb is that cleanup tasks require data from a single source within a sliding window.
Hidden text
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
After the data is received and cleaned up, it is stored in the distributed file system (to improve fault tolerance). Data is often written in tabular format. When new information is written to the storage node, the data catalog containing schema and metadata can be updated using an offline crawler. The launch of the crawler is usually triggered by event, for example, when a new object arrives in storage. Repositories are usually integrated with their catalogs. They unload the underlying schema so that the data can be accessed.
Then the data goes into a special area dedicated to the "gold data". From this point on, the data is ready for enrichment by other processes.
Hidden text
, , .
During the enrichment process, the data is additionally changed and cleaned in accordance with the business logic. As a result, they are stored in a structured format in a data warehouse or database that is used to quickly retrieve information, analytics, or a training model.
Finally, the use of data is analytics and research. This is where the extracted information is converted into business ideas through visualizations, dashboards, and reports. Also, this data is a source for forecasting using machine learning, the result of which helps to make better decisions.
Platform components
Data lake cloud infrastructure requires a robust, and in the case of hybrid cloud systems, a unified abstraction layer that can help deploy, coordinate, and run computational tasks without the constraints of API providers.
Kubernetes is a great tool for this job. It allows you to efficiently deploy, organize, and run various services and computational tasks of a data lake in a reliable and cost-effective manner. It offers a unified API that will work both on-premises and in any public or private cloud.
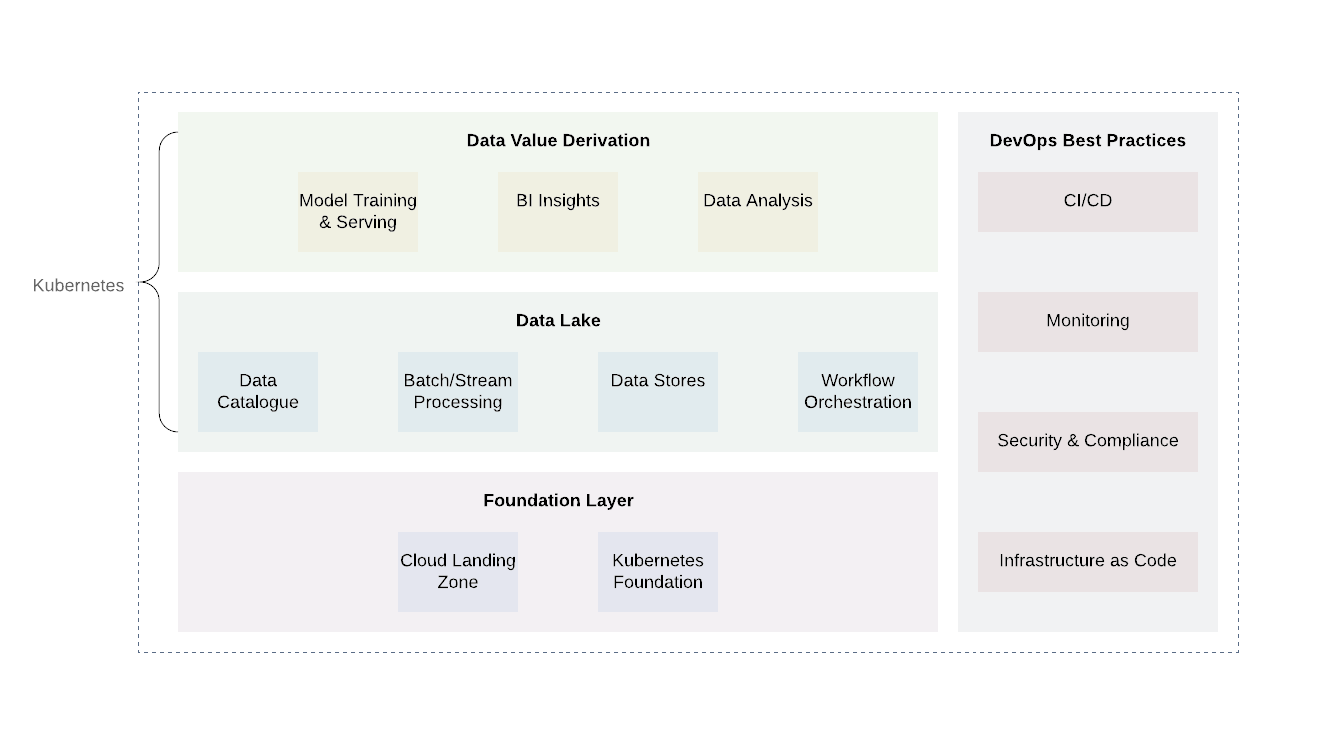
The platform can be roughly divided into several layers. The base layer is where we deploy Kubernetes or its equivalent. The base layer can also be used to handle computational tasks outside the domain of the data lake. When using cloud providers, it would be promising to use the already established practices of cloud providers (logging and auditing, designing minimal access, vulnerability scanning and reporting, network architecture, IAM architecture, etc.) This will achieve the necessary level of security and compliance with other requirements ...
There are two additional levels above the base level - the data lake itself and the value output level. These two layers are responsible for the core of the business logic as well as for data processing. While there are many technologies for these two tiers, Kubernetes will again prove to be a good option because of its flexibility to support a variety of compute tasks.
The data lake layer includes all the necessary services for receiving ( Kafka , Kafka Connect ), filtering, enriching and processing ( Flink and Spark ), workflow management ( Airflow ). In addition, it includes data storage and distributed file systems ( HDFS) as well as RDBMS and NoSQL databases .
The topmost level is getting data values. Basically, this is the level of consumption. It includes components such as visualization tools for understanding business intelligence, data mining tools ( Jupyter Notebooks ). Another important process that takes place at this level is machine learning using training samples from a data lake.
It is important to note that an integral part of every data lake is the implementation of common DevOps practices: infrastructure as code, observability, auditing, and security. They play an important role in solving day-to-day problems and must be applied at every individual level to ensure standardization, security and ease of use.
, — , opensource-.
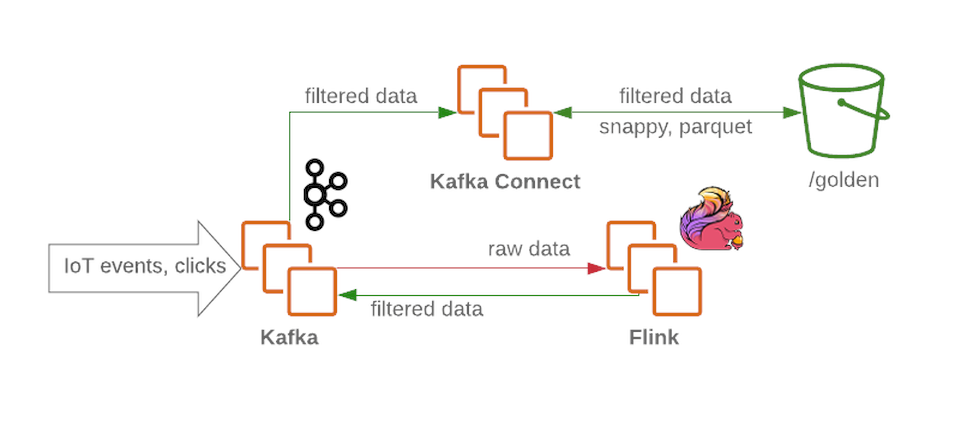
The Kafka cluster will receive unfiltered and unprocessed messages and will function as a receive node in the data lake. Kafka provides high throughput messages in a reliable manner. A cluster usually contains several sections for raw data, processed (for streaming), and undelivered or malformed data.
Flink accepts a message from a raw data node from Kafka , filters the data and pre-enriches the data if necessary. The data is then passed back to Kafka (in a separate section for filtered and rich data). In the event of a failure, or when the business logic changes, these messages can be called again, because that they are saved inKafka . This is a common solution for streaming processes. Meanwhile, Flink writes all malformed messages to another section for further analysis.
Using Kafka Connect, we get the ability to save data to the required data storage backends (like the gold zone in HDFS ). Kafka Connect scales easily and will help you quickly increase the number of concurrent processes by increasing throughput under heavy workload:
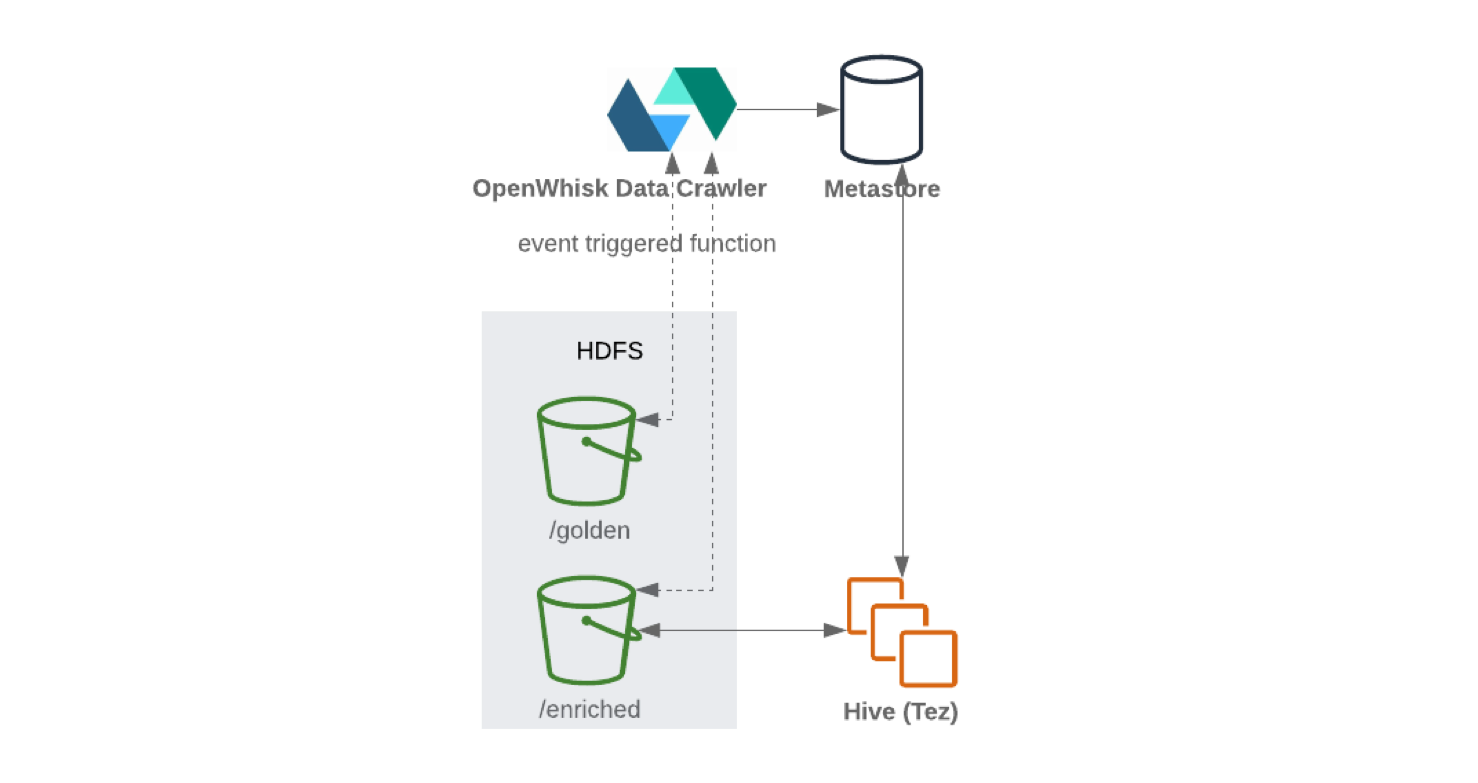
When writing from Kafka Connect to HDFS, it is recommended to perform content splitting for efficient data handling (the less data to scan, the fewer requests and responses). After the data has been written to HDFS , the serverless functionality (like OpenWhisk or Knative ) will periodically update the metadata and schema parameter store. As a result, the updated schema can be accessed through an SQL-like interface (for example, Hive or Presto ).
Apache Airflow can be used for subsequent data-flows and management of the ETL process . It allows users to run multi-step piplines using Python and Directed Acyclic Graph ( DAG ) objects . The user can define dependencies, program complex processes, and track tasks through a graphical interface. Apache Airflow can also handle all external data. For example, to receive data through an external API and store it in persistent storage. Spark powered by Apache Airflow
through a special plugin, it can periodically enrich the raw filtered data in accordance with business objectives, and prepare the data for research by data scientists and business analysts. Data Scientists can use JupyterHub to manage multiple Jupyter Notebooks . Therefore, it is worth using Spark to configure multiuser interfaces for working with data, collecting and analyzing it.

For machine learning, you can use frameworks like Kubeflow , taking advantage of Kubernetes' scalability . The resulting training models can be returned to the system.
If we put the puzzle together, we get something like this:

Operational excellence
We've said that the principles of DevOps and DevSecOps are essential components of any data lake and should never be overlooked. With a lot of power comes a lot of responsibility, especially when all the structured and unstructured data about your business is in one place.
The basic principles will be as follows:
- Restrict user access;
- Monitoring;
- Data encryption;
- Serverless solutions;
- Using CI / CD processes.
The principles of DevOps and DevSecOps are essential components of any data lake and should never be overlooked. With a lot of power comes a lot of responsibility, especially when all the structured and unstructured data about your business is in one place.
One of the recommended methods is to allow access only for certain services by distributing the appropriate rights, and to deny direct user access so that users cannot change data (this also applies to commands). Full monitoring by logging actions is also important to protect data.
Data encryption is another mechanism for protecting data. Stored data can be encrypted using a key management system ( KMS). This will encrypt your storage system and current state. In turn, transmission encryption can be done using certificates for all interfaces and endpoints of services like Kafka and ElasticSearch .
And in the case of search engines that may not comply with security policy, it is better to give preference to serverless solutions. It is also necessary to abandon manual deployments, situational changes in any component of the data lake; each change must come from source control and go through a series of CI tests before being deployed to a product data lake ( smoke testing, regression, etc.).
Epilogue
We have covered the basic design principles of an open source data lake architecture. As is often the case, the choice of approach is not always obvious and may be dictated by different business, budget and time requirements. But leveraging cloud technology to create data lakes, whether it's a hybrid or all-cloud solution, is an emerging trend in the industry. This is due to the sheer number of benefits this approach offers. It has a high level of flexibility and does not restrict development. It is important to understand that a flexible work model brings significant economic benefits, allowing you to combine, scale and improve the applied processes.