I am currently working at ManyChat. In fact, this is a startup - new, ambitious and rapidly growing. And when I first joined the company, the classic question arose: "What should a young startup take now from the DBMS and databases market?"
In this article, based on my talk at the RIT ++ 2020 online festival , I will answer this question. A video version of the report is available on YouTube .
Well-known databases of 2020
It's 2020, I looked around and saw three types of databases.
The first type is classic OLTP databases : PostgreSQL, SQL Server, Oracle, MySQL. They were written a long time ago, but are still relevant because they are familiar to the developer community.
The second type - bases from "zero" . They tried to move away from classic patterns by abandoning SQL, traditional structures and ACID, by adding built-in sharding and other attractive features. For example, these are Cassandra, MongoDB, Redis, or Tarantool. All these solutions wanted to offer the market something fundamentally new and occupied their niche, because in certain tasks they turned out to be extremely convenient. These bases will be denoted by the umbrella term NOSQL.
The "zero" ones are over, they got used to NOSQL databases, and the world, from my point of view, has taken the next step - to managed databases . These databases have the same core as classic OLTP databases or new NoSQL databases. But they have no need for DBA and DevOps and they run on managed hardware in the clouds. For a developer, this is "just a base" that works somewhere, but how it is installed on the server, who configured the server and who updates it, nobody cares.
Examples of such bases:
- AWS RDS is a managed wrapper over PostgreSQL / MySQL.
- DynamoDB is an AWS analog of a document based database, similar to Redis and MongoDB.
- Amazon Redshift is a managed analytics base.
At the core, these are old bases, but raised in a managed environment, without the need to work with hardware.
Note. The examples are taken for the AWS environment, but their counterparts also exist in Microsoft Azure, Google Cloud, or Yandex.Cloud.

So what is new? In 2020, none of this.
Serverless concept
What's really new on the market in 2020 are serverless or serverless solutions.
I'll try to explain what this means using the example of a regular service or backend application.
To deploy a regular backend application, we buy or rent a server, copy the code to it, publish the endpoint outside, and regularly pay for rent, electricity and data center services. This is the standard layout.
Is there any other way? With serverless services, you can.
What is the focus of this approach: there is no server, there is not even a virtual instance lease in the cloud. To deploy the service, copy the code (functions) to the repository and publish the endpoint outside. Then we just pay for each call of this function, completely ignoring the hardware where it is executed.
I will try to illustrate this approach in pictures.
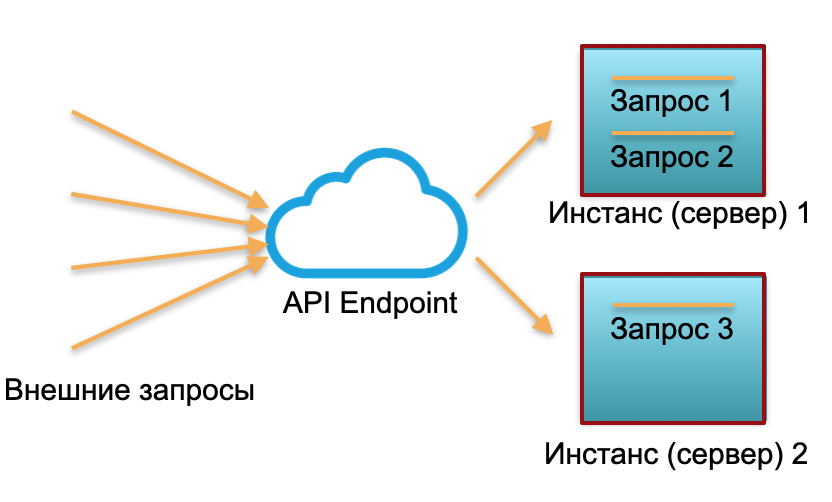
Classic deployment . We have a service with a certain load. We raise two instances: physical servers or instances in AWS. External requests are sent to these instances and processed there.
As you can see in the picture, the servers are utilized differently. One is 100% utilized, there are two requests, and one is only 50% partially idle. If not three requests come, but 30, then the whole system will not cope with the load and will start to slow down.

Serverless deployment... In a serverless environment, such a service has no instances or servers. There is a pool of warmed up resources - small prepared Docker containers with deployed function code. The system receives external requests and for each of them the serverless framework raises a small container with code: it processes this particular request and kills the container.
One request - one lifted container, 1000 requests - 1000 containers. And deployment on iron servers is already the work of a cloud provider. It is completely hidden by the serverless framework. In this concept, we pay for each call. For example, one call a day came - we paid for one call, a million came in a minute - we paid for a million. Or in a second, this also happens.
The concept of publishing a serverless function is appropriate for a stateless service. And if you need a (state) statefull service, then add a database to the service. In this case, when it comes to working with state, with state, each statefull function simply writes and reads from the database. Moreover, from a database of any of the three types described at the beginning of the article.
What is the general limitation of all these bases? These are the costs of a constantly used cloud or iron server (or multiple servers). It doesn't matter whether we use a classic database or managed, whether there are Devops and an admin or not, we still pay 24/7 for hardware, electricity and data center rent. If we have a classic base, we pay for master and slave. If a highly loaded sharded base - we pay for 10, 20 or 30 servers, and we pay constantly.
The presence of permanently reserved servers in the cost structure was previously perceived as a necessary evil. Ordinary databases also have other difficulties, such as limits on the number of connections, scaling limits, geo-distributed consensus - they can somehow be solved in certain databases, but not all at once and not ideal.
Serverless database - theory
2020 question: can the database be made serverless too? Everyone has heard about the serverless backend ... but let's try to make the database serverless too?
This sounds strange because a database is a statefull service, not very suitable for a serverless infrastructure. At the same time, the state of the database is very large: gigabytes, terabytes, and even petabytes in analytical databases. It is not so easy to lift it in lightweight Docker containers.
On the other hand, almost all modern databases are a huge amount of logic and components: transactions, integrity negotiation, procedures, relational dependencies, and a lot of logic. Quite a lot of the database logic is a fairly small state. Gigabytes and Terabytes are directly used by only a small portion of the database logic associated with directly executing queries.
Accordingly, the idea: if a part of the logic allows stateless execution, why not cut the base into Stateful and Stateless parts.
Serverless for OLAP solutions
Let's see how a database cut into Stateful and Stateless parts might look like with practical examples.
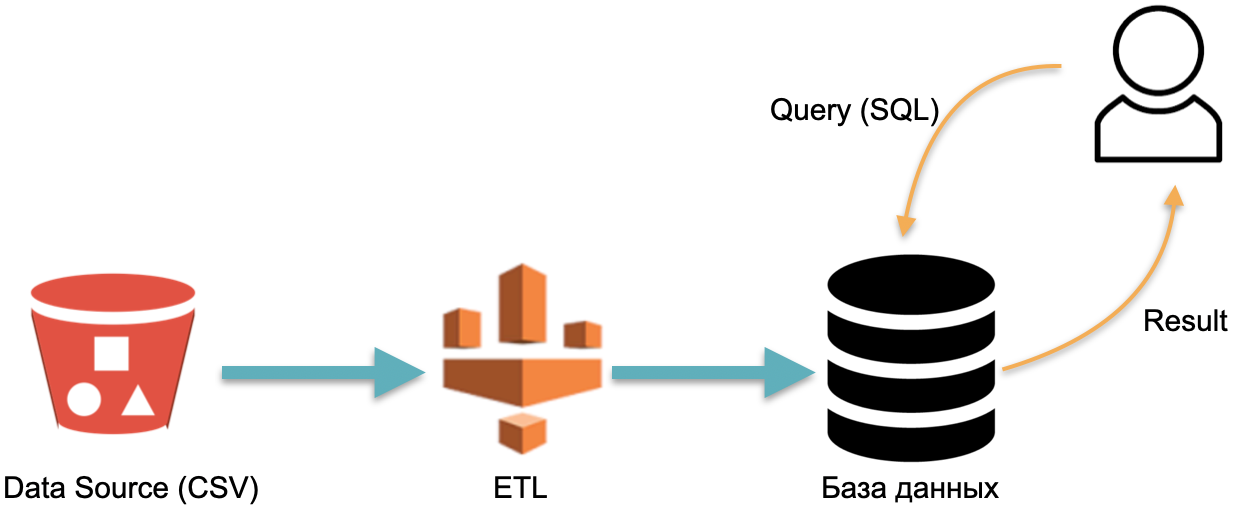
For example, we have an analytical database : external data (red cylinder on the left), an ETL process that loads data into the database, and an analyst that sends SQL queries to the database. This is the classic way a data warehouse works.
In this scheme, by convention, ETL is executed once. Then you need to pay all the time for the servers running the database with data flooded with ETL, so that you have something to throw requests.
Let's look at an alternative approach implemented in AWS Athena Serverless. There is no permanently dedicated hardware on which the downloaded data is stored. Instead of this:
- SQL- Athena. Athena SQL- (Metadata) , .
- , , ( ).
- SQL- , .
- , .
In this architecture, we only pay for the request execution process. No requests - no costs.
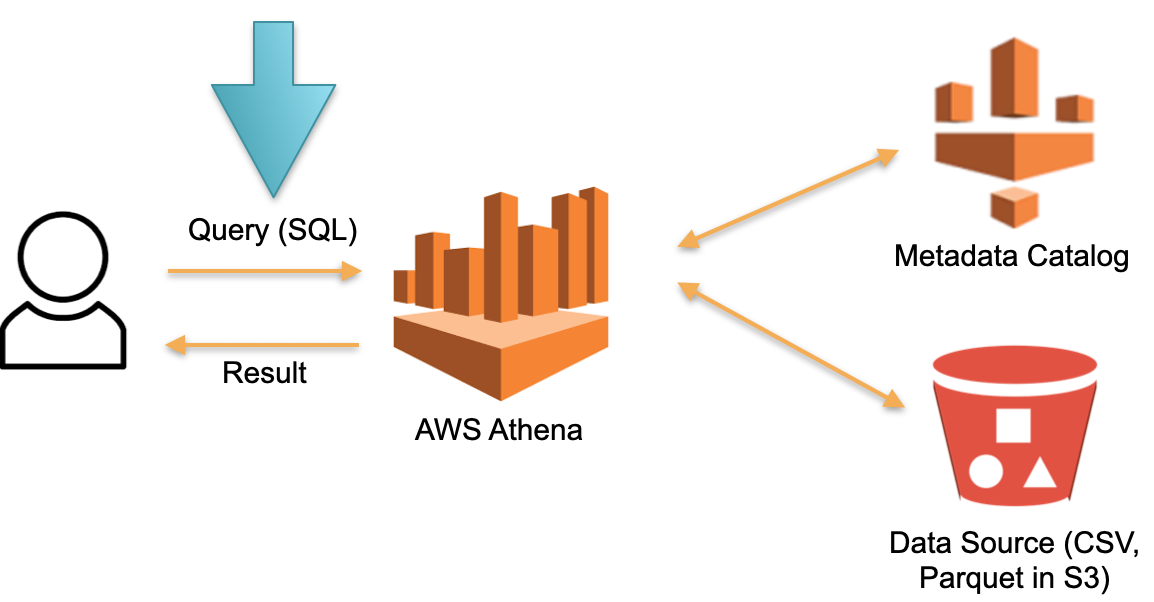
This is a working approach and is implemented not only in Athena Serverless but also in Redshift Spectrum (in AWS).
Athena's example shows that the Serverless database works on real queries with tens and hundreds of Terabytes of data. Hundreds of Terabytes will require hundreds of servers, but we don't have to pay for them - we pay for requests. The speed of each request is (very) slow compared to specialized analytics databases like Vertica, but we do not pay for downtime.
Such a database is useful for rare ad-hoc analytic queries. For example, when we spontaneously decide to test a hypothesis on some gigantic amount of data. Athena is perfect for these cases. For regular inquiries, such a system is expensive. In this case, cache the data in some specialized solution.
Serverless for OLTP solutions
In the previous example, OLAP tasks (analytical) were considered. Now let's look at OLTP tasks.
Imagine scalable PostgreSQL or MySQL. Let's raise a regular managed instance PostgreSQL or MySQL on minimal resources. When more load arrives on the instance, we will connect additional replicas to which we will distribute part of the reading load. If there are no requests and no load, we turn off the replicas. The first instance is the master, and the rest are replicas.
This idea is implemented in a database called Aurora Serverless AWS. The principle is simple: requests from external applications are accepted by proxy fleet. Seeing an increase in load, it allocates computing resources from pre-warmed minimum instances - the connection is as fast as possible. Disconnecting instances is the same.
Within Aurora, there is the concept of the Aurora Capacity Unit, ACU. This is (conditionally) an instance (server). Each specific ACU can be master or slave. Each Capacity Unit has its own RAM, processor and minimum disk. Accordingly, one master, the rest are read only replicas.
The number of these Aurora Capacity Units in operation is configurable. The minimum quantity can be one or zero (in this case, the base does not work if there are no requests).

When the base receives requests, the proxy fleet raises Aurora CapacityUnits, increasing the system's productive resources. The ability to increase and decrease resources allows the system to "juggle" resources: automatically display individual ACUs (replacing them with new ones) and roll up all relevant updates to the removed resources.
The Aurora Serverless base can scale the read load. But the documentation doesn't say it directly. It might feel like they might be raising a multi-master. There is no magic.
This base is well suited not to spend a lot of money on systems with unpredictable access. For example, when building MVP or business card marketing sites, we usually don't expect a steady load. Accordingly, in the absence of access, we do not pay for instances. When a load arises unexpectedly, for example, after a conference or an advertising campaign, crowds of people visit the site and the load increases dramatically, Aurora Serverless automatically takes over this load and quickly connects the missing resources (ACU). Then the conference goes on, everyone forgets about the prototype, the servers (ACU) go out, and the costs drop to zero - it's convenient.
This solution is not suitable for stable high highloads because it cannot scale the writing load. All these connections and disconnections of resources occur at the moment of the so-called "scale point" - the moment in time when the database is not held by the transaction, temporary tables are not kept. For example, during a week, the scale point may not happen, and the base works on the same resources and simply cannot expand or shrink.
There is no magic - this is regular PostgreSQL. But the process of adding cars and disconnecting is partially automated.
Serverless by design
Aurora Serverless is an old base rewritten for the cloud to take advantage of the individual benefits of Serverless. And now I'll tell you about the base, which was originally written for the cloud, for the serverless approach - Serverless-by-design. It was developed straight away without the assumption that it runs on physical servers.
This base is called Snowflake. It has three key blocks.
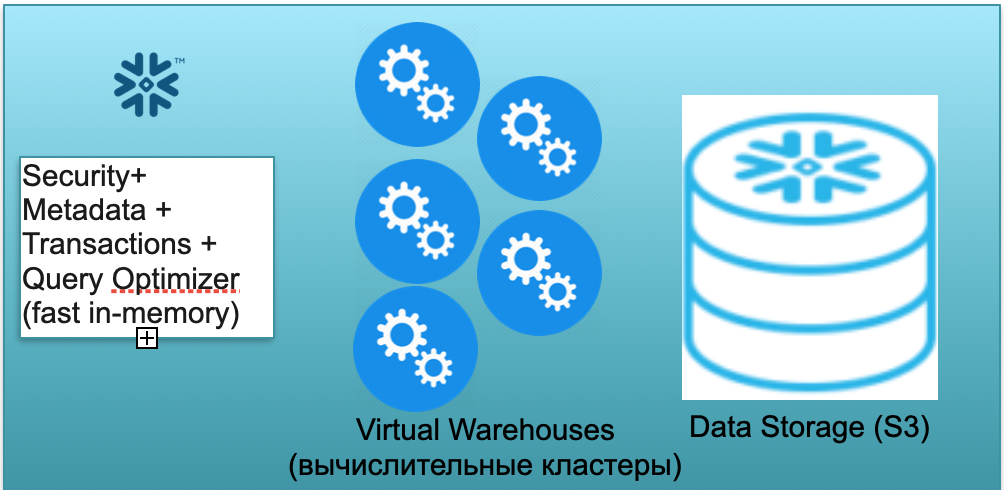
The first is a block of metadata. It is a fast in-memory service that solves issues with security, metadata, transactions, query optimization (in the illustration on the left).
The second block is a set of virtual computational clusters for calculations (in the illustration - a set of blue circles).
The third block is an S3-based storage system. S3 is AWS's dimensionless object storage, akin to the dimensionless Dropbox for business.
Let's take a look at how Snowflake works under the cold start assumption. That is, the database is there, the data is loaded into it, there are no working queries. Accordingly, if there are no queries to the database, then we have raised a fast in-memory Metadata service (first block). And we have S3 storage, where table data is stored, divided into so-called micropartitions. For simplicity: if the table contains deals, then micro-lots are the days of deals. Every day is a separate micro-batch, a separate file. And when the database works in this mode, you pay only for the space occupied by the data. Moreover, the rate per seat is very low (especially given the significant compression). The metadata service also works constantly, but you don't need a lot of resources to optimize queries, and the service can be considered shareware.
Now let's imagine that a user comes to our database and throws an SQL query. The SQL query is immediately sent to the Metadata service for processing. Accordingly, upon receiving a request, this service analyzes the request, available data, user authority and, if all is well, draws up a request processing plan.
Next, the service initiates the launch of the computational cluster. A compute cluster is a cluster of servers that perform computations. That is, this is a cluster that can contain 1 server, 2 north, 4, 8, 16, 32 - as many as you want. You throw a request and the launch of this cluster instantly starts under it. It really takes seconds.
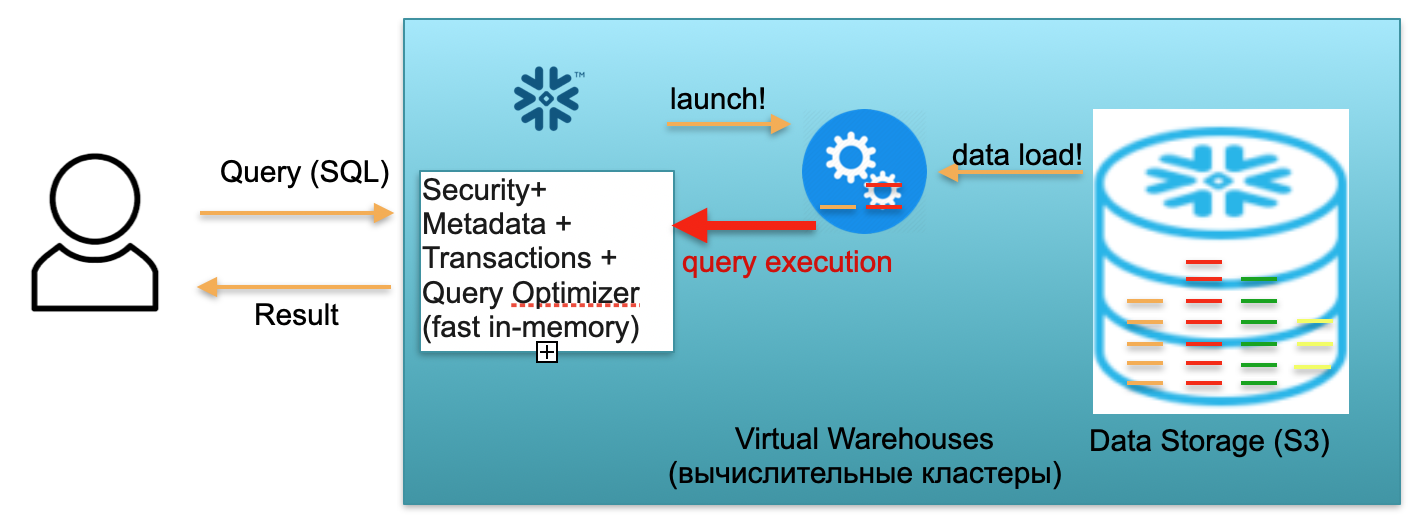
Further, after the cluster has started, micropartitions are copied from S3 to the cluster, which are necessary to process your request. That is, imagine that to execute an SQL query, you need two partitions from one table and one from the second. In this case, only the three necessary partitions will be copied to the cluster, and not all tables as a whole. That is why and precisely because everything is within the framework of one data center and is connected by very fast channels, the entire pumping process takes place very quickly: in seconds, very rarely - in minutes, if we are not talking about some monstrous requests ... Accordingly, micropartitions are copied to the computational cluster, and, upon completion, an SQL query is executed on this computational cluster. The result of this query can be one line, several lines or a table - they are sent out to the user,so that it can be downloaded, displayed in its BI tool, or used in some other way.
Each SQL query can not only read aggregates from previously loaded data, but also load / form new data in the database. That is, it can be a query that, for example, inserts new records into another table, which leads to the appearance of a new partition on the computational cluster, which, in turn, is automatically stored in a single S3 storage.
The scenario described above, from the arrival of a user to raising the cluster, loading data, executing queries, obtaining results, is paid at the rate per minutes of using the raised virtual computing cluster, virtual warehouse. The rate varies by AWS zone and cluster size, but on average it is a few dollars per hour. A cluster of four cars is twice as expensive as a cluster of two cars, and of eight cars is twice as expensive. Available options from 16, 32 cars, depending on the complexity of the requests. But you pay only for the minutes when the cluster actually works, because when there are no requests, you kind of take your hands off, and after 5-10 minutes of waiting (a configurable parameter) it will go out by itself, free up resources and become free.
The scenario is quite real when you throw a request, the cluster pops up, relatively speaking, in a minute, it counts another minute, then five minutes to shutdown, and you pay as a result for seven minutes of this cluster's operation, and not for months and years.
The first scenario described using Snowflake in a single-user scenario. Now let's imagine that there are many users, which is closer to a real scenario.
Suppose we have a lot of analysts and Tableau reports that are constantly bombarding our database with a lot of simple analytical SQL queries.
In addition, let's say that we have ingenious Data Scientists who are trying to do monstrous things with data, operate on tens of terabytes, analyze billions and trillions of rows of data.
For the two types of load described above, Snowflake allows you to lift several independent compute clusters of different capacities. Moreover, these computational clusters operate independently, but with common consistent data.
For a large number of light queries, you can raise 2-3 small clusters, conventionally in size, 2 machines each. This behavior is realizable, among other things, using automatic settings. That is, you say, “Snowflake, raise a small cluster. If the load on it grows more than a certain parameter, raise a similar second, third. When the load starts to subside - extinguish the extra ones. " So that no matter how many analysts come and start looking at the reports, everyone has enough resources.
At the same time, if the analysts are asleep and no one is looking at the reports, the clusters can completely go out, and you stop paying for them.
At the same time, for heavy queries (from Data Scientists), you can raise one very large cluster per conditional 32 machines. This cluster will also be billed only for the minutes and hours when your giant request is running there.
The feature described above allows to divide into clusters not only 2, but also more types of load (ETL, monitoring, materialization of reports, ...).
Let's summarize the Snowflake. The base combines a beautiful idea and a workable implementation. At ManyChat, we use Snowflake to analyze all the data we have. We have not three clusters, as in the example, but from 5 to 9, of different sizes. We have conditional 16-machine, 2-machine, there are also super-small 1-machines for some tasks. They successfully distribute the load and allow us to save a lot.
The base successfully scales the reading and writing workload. This is a huge difference and a huge breakthrough in comparison with the same "Aurora", which pulled only the reading load. Snowflake allows these compute clusters to scale and write workloads. That is, as I mentioned, we use several clusters in ManyChat, small and super-small clusters are mainly used for ETL, for loading data. And analysts already live on medium-sized clusters that are absolutely not affected by the ETL load, so they work very quickly.
Accordingly, the base is well suited for OLAP tasks. At the same time, unfortunately, it is not yet applicable for OLTP workloads. Firstly, this base is columnar, with all the ensuing consequences. Secondly, the approach itself, when for each request, if necessary, you raise a computational cluster and spill it with data, unfortunately, for OLTP workloads it is still not fast enough. Waiting seconds for OLAP tasks is normal, but for OLTP tasks it is unacceptable, 100ms would be better, and even better - 10ms.
Outcome
Serverless database is possible by separating the database into Stateless and Stateful parts. You must have noticed that in all the examples given, the Stateful part is, relatively speaking, storing micropartitions in S3, and Stateless is an optimizer, working with metadata, handling security issues that can be raised as independent lightweight Stateless services.
Executing SQL queries can also be thought of as light-state services that can pop up in serverless mode, like Snowflake compute clusters, download only the data you need, execute the query, and “go out”.
Serverless production-level databases are already available for use, they are working. These serverless databases are already ready to handle OLAP tasks. Unfortunately, they are used for OLTP tasks ... with nuances, since there are limitations. On the one hand, this is a minus. But on the other hand, this is an opportunity. Perhaps some of the readers will find a way to make the OLTP base completely serverless, without the limitations of Aurora.
Hope you found it interesting. Serverless is the future :)