Hello, Habr! In this article I will show you how to make a frequency analysis of the modern Russian Internet language and use it to decipher the text. Who cares, welcome under the cut!

Frequency analysis of the Russian Internet language
The social network Vkontakte was taken as a source from where you can get a lot of text with a modern Internet language, or to be more precise, these are comments on publications in various communities of this network. I chose real football as a community . For parsing comments, I used the Vkontakte API :
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passThe result was about 200MB of text. Now we count which character appears how many times:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequencyThe results obtained can be compared with the results from Wikipedia and displayed as:
1) comparison chart
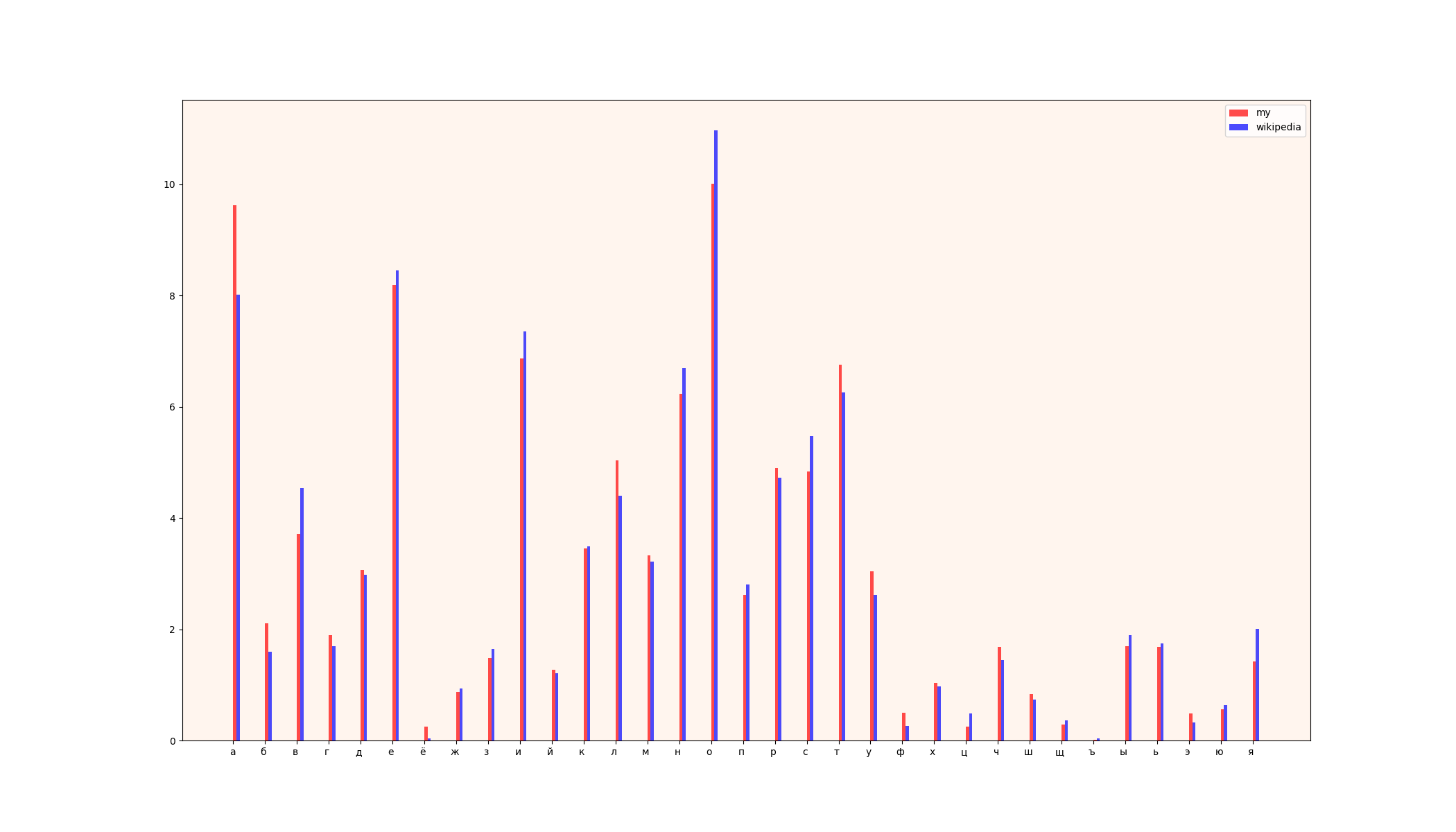
2) tables (left - wikipedia data, right - my data)
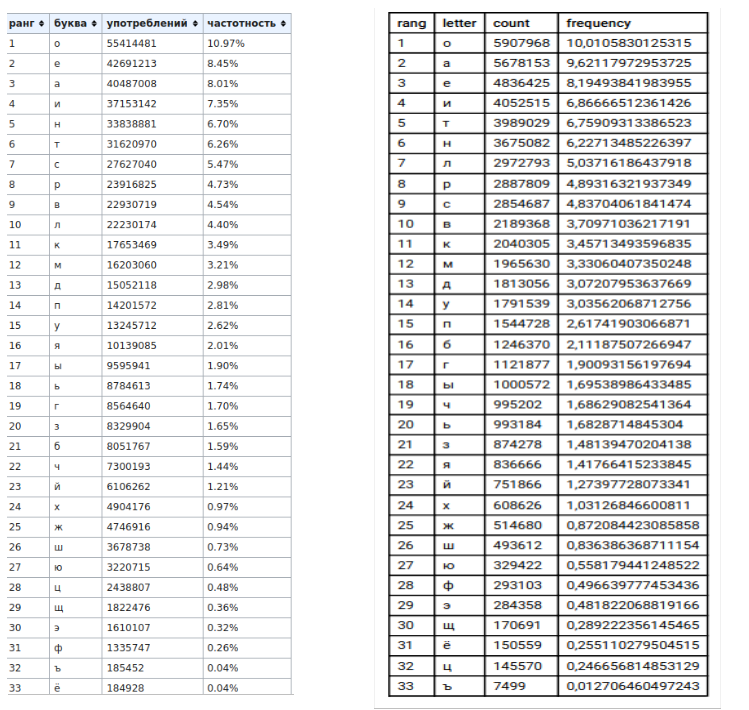
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
If you look at the decrypted text, you can guess where our algorithm went wrong: fights → does, vadio → radio, thenho → addition, overwhelm → people. Thus, it is possible to decipher the entire text, at least to grasp the meaning of the text. I also want to note that this method will be effective in decrypting only long texts that have been encrypted with symmetric encryption methods. The complete code is available on Github .