
Today I will tell you a little about my thoughts on the tarantool / cartridge failover. First, a few words about what cartridge is: this is a piece of lua code that works inside tarantool and combines tarantulas with each other into one conditional "cluster". This is due to two things:
- every tarantula knows the network addresses of all other tarantulas;
- tarantulas regularly "ping" each other via UDP to understand who is alive and who is not. Here I deliberately simplify a little, the ping algorithm is more complicated than just request-response, but this is not very important for parsing. If interested - google the SWIM algorithm.
Within a cluster, everything is usually divided into stateful (master / replica) and stateless (router) tarantulas. Stateless tarantulas are responsible for storing data, and stateless tarantulas are responsible for routing requests.
This is how it looks in the picture:
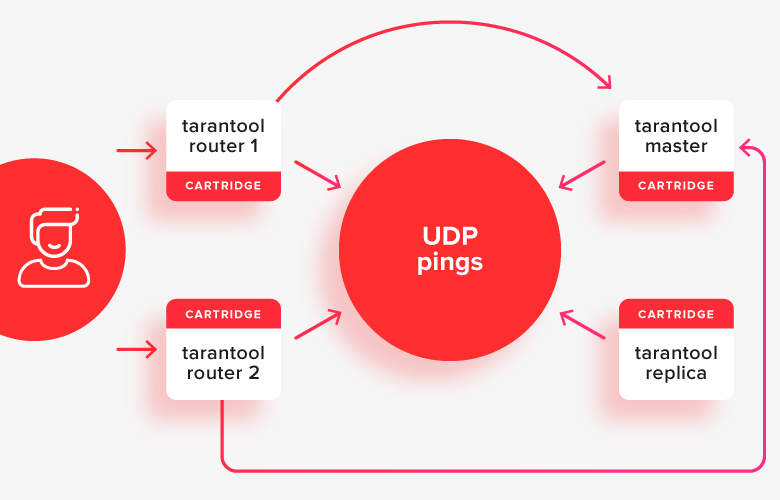
The client makes requests to any of the active routers, and they redirect requests to the one of the stores, which is now the active master. In the picture, these paths are shown with arrows.
Now I don't want to complicate things and introduce sharding into the conversation about choosing a leader, but the situation with him will be little different. The only difference is that the router still needs to decide which replica set to use from the store.
First, let's talk about how nodes learn each other's addresses. To do this, each of them has a yaml file on the disk with the cluster topology, that is, with information about the network addresses of all members, and who of them is who (with or without state). Plus potentially additional customization, but for now, let's leave that aside. The configuration files contain the settings for the entire cluster as a whole, and are the same for each tarantula. If changes are made to them, then they are made synchronously for all tarantulas.
Now configuration changes can be made through the API of any of the tarantulas in the cluster: it will connect to everyone else, send them a new version of the configuration, everyone will apply it, and everywhere there will be a new version, the same again.
Scenario - node failure, switchover
In a situation when a router fails, everything is more or less simple: the client just needs to go to any other active router, and he will deliver the request to the desired store. But what if, for example, the master of one of the Storaja fell?
Right now we have implemented a "naive" algorithm for such a case, which relies on UDP ping. If the replica does not “see” responses from the master to ping for a short period of time, it considers that the master has fallen and becomes the master itself, switching to read-write mode from read-only. Routers act the same way: if they don't see some ping response time from the master, they switch traffic to the replica.
This works relatively well in simple cases, except for a split brain situation, when half of the nodes are separated from another by some kind of network problem:
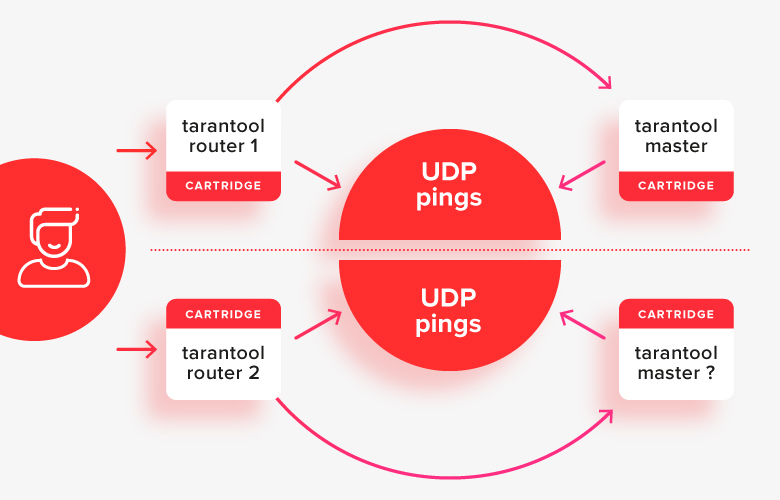
In this situation, the routers will see that the “other half” of the cluster is unavailable, and will consider their half as the main one, and it turns out that there are two masters in the system at the same time. This is the first important case to be solved.
Scenario - Edit Configuration on Failures
Another important scenario is replacing a failed tarantula in a cluster with a new one, or adding nodes to the cluster when one of the replicas or routers is unavailable.
During normal operation, when everything in the cluster is available, we can connect via API to any node, ask it to edit the configuration, and, as I said above, the node will "roll out" the new configuration to the entire cluster.
But when someone is unavailable, you cannot apply the new configuration, because when these nodes become available again, it will be unclear which of them in the cluster has the correct configuration and which does not. Still the inaccessibility of the nodes to each other may mean that there is a split brain between them. And editing the configuration is simply unsafe, because you can mistakenly edit it in different ways in different halves.
For these reasons, we now prohibit editing the configuration via the API when someone is not available. It can be corrected only on disk, through text files (manually). Here you must understand well what you are doing and be very careful: automation will not help you in any way.
This makes operation inconvenient, and this is the second case to be solved.
Scenario - stable failover
Another problem with the naive failover model is that switching from master to replica in case of master failure is not recorded anywhere. All nodes make the decision to switch on their own, and when the master comes to life, traffic will switch to it again.
This may or may not be a problem. Before turning on the master, the master will "catch up" with the transactional logs from the replica, so there will most likely not be a big data lag. The problem will be only in the case when there are network problems, and there is a loss of packets: then most likely there will be periodic "flashing" of the master (flapping).
The solution is a "strong" coordinator (etcd / consul / tarantool)
In order to avoid problems with a split brain, and to make it possible to edit the configuration when the cluster is partially unavailable, we need a strong coordinator that is resistant to network segmentation. The coordinator should be distributed over 3 data centers so that if any of them fails, it remains operational.
There are now 2 popular RAFT-based coordinators that use etcd and consul for this. When synchronous replication appears in tarantool, it can also be used for this.
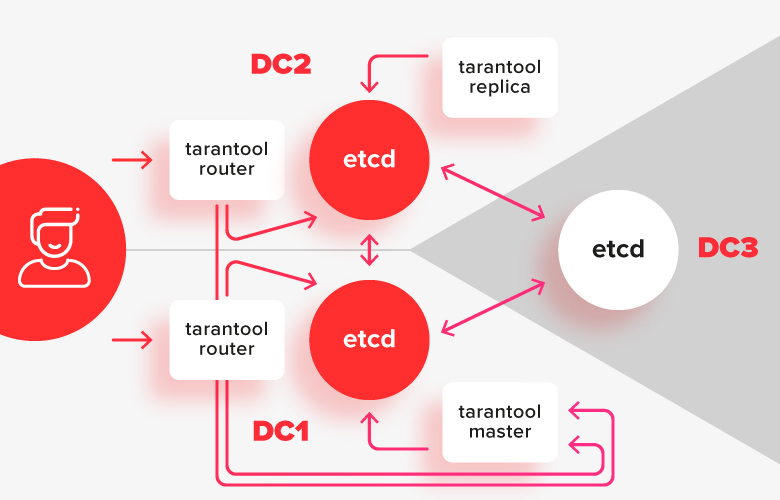
In this scheme, the tarantula installations are divided into two data centers, and are connected to their local etcd installation. An instance of etcd in the third datacenter serves as an arbiter so that in the event of a failure of one of the datacenters, it is precisely which of them remained in the majority.
Configuration management with a strong coordinator
As I said above, in the absence of a coordinator and the failure of one of the tarantulas, we could not edit the configuration centrally, because then it is impossible to say which configuration on which of the nodes is correct.
In the case of a strong coordinator, everything is simpler: we can store the configuration on the coordinator, and each instance of the tarantula will contain a cache of this configuration on its file system. Upon successful connection to the coordinator, it will update its copy of the configuration to the one in the coordinator.
Editing the configuration also becomes easier: it can be done through the API of any tarantula. It will take the lock in the coordinator, replace the desired values in the configuration, wait until all nodes apply it, and release the lock. Well, or as a last resort, you can edit the configuration manually in etcd, and it will apply to the entire cluster.
It will be possible to edit the configuration even if some tarantulas are not available. The main thing is that most of the coordinator nodes are available.
Failover with a strong coordinator
Reliable switching of nodes with a coordinator is solved due to the fact that in addition to configuration, we will store in the coordinator information about who is the current master in the replica and where the switches were made.
The failover algorithm changes as follows:
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
Flapping protection is also possible with a coordinator. In the coordinator, you can record the entire history of switching, and if during the last X minutes the master switched to a replica, then the reverse switching is done only explicitly by the administrator.
Another important point is the so-called "Fencing". Tarantulas that are cut off from other datacenters (or connected to a coordinator who has lost their majority) should assume that most likely the rest of the cluster, to which access is lost, has a majority. And that means, within a certain time, all nodes cut off from the majority must go to read-only.
Coordinator unavailability problem
While we were discussing approaches to working with the coordinator, we received a request to make sure that if the coordinator falls, but all the tarantulas are intact, do not translate the entire cluster into read only.
At first it seemed that it was not very realistic to do this, but then we remembered that the cluster itself monitors the availability of other nodes via UDP pings. This means that we can target them and not trigger re-election of the master inside the replica set, if it is clear through UDP pings that the entire replica set is alive.
This approach will help you worry less about the availability of the coordinator, especially if you need to reboot it for example to update.
Implementation plans
Now we are collecting feedback and starting implementation. If you have something to say - write in the comments or in a personal.
The plan is something like this:
- Make etcd support in tarantool [done]
- Failover using etcd as coordinator, stateful [done]
- Failover using tarantula as coordinator, latching [done]
- Storing configuration in etcd [in progress]
- Writing CLI tools for cluster repair [in progress]
- Storing the configuration in the tarantula
- Cluster management when part of the cluster is unavailable
- Fencing
- Flapping protection
- Failover using consul as coordinator
- Storing configuration in consul
In the future, we will almost certainly ditch the cluster entirely without a strong coordinator. This will most likely coincide with the RAFT-based implementation of synchronous replication in the tarantula.
Acknowledgments
Thanks to Mail.ru developers and admins for the feedback, criticism and testing provided.