
This article collects some common patterns to help engineers work with large-scale services that are being requested by millions of users.
In the author's experience, this is not an exhaustive list, but really effective tips. So, let's begin.
Translated with the support of Mail.ru Cloud Solutions .
First level
The measures listed below are relatively easy to implement, but yield high returns. If you haven't tried them before, you will be surprised by the significant improvements.
Infrastructure as code
The first piece of advice is to implement the infrastructure as code. This means you must have a programmatic way to deploy your entire infrastructure. It sounds tricky, but we're actually talking about the following code:
Deploy 100 virtual machines
- with Ubuntu
- 2 GB RAM each
- they will have the following code
- with such parameters
You can track and revert to infrastructure changes quickly using source control.
The modernist in me says that you can use Kubernetes / Docker to do all of the above, and he's right.
Alternatively, you can provide automation with Chef, Puppet, or Terraform.
Continuous integration and delivery
To create a scalable service, it is important to have a build and test pipeline for each pull request. Even if the test is the simplest, it will at least ensure that the code you deploy compiles.
Each time at this stage, you answer the question: will my assembly compile and pass tests, is it valid? This may sound like a low bar, but it solves a lot of problems.
There is nothing more beautiful than seeing these checkboxes.
For this technology, you can check out Github, CircleCI or Jenkins.
Load balancers
So, we want to start a load balancer to redirect traffic, and ensure that the load on all nodes is equal or that the service works in the event of a failure:
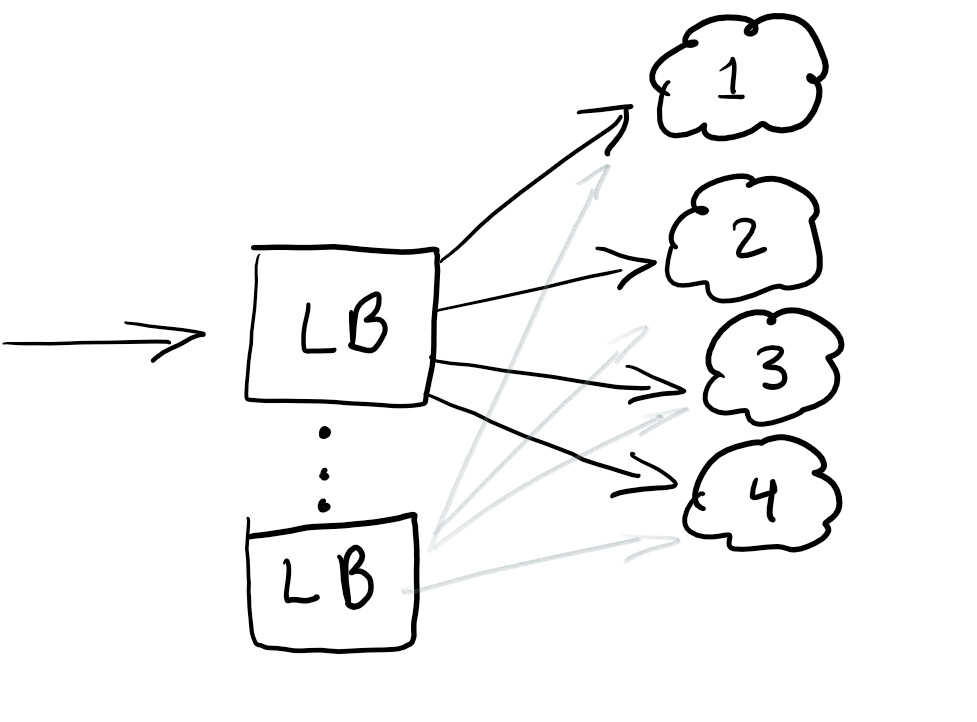
A load balancer is generally good at helping to distribute traffic. Best practice is to overbalance so you don't have a single point of failure.
Typically, load balancers are configured in the cloud that you are using.
RayID, Correlation ID or UUID for requests
Have you ever encountered an error in an application with a message like this: “Something went wrong. Save this id and send it to our support team ” ?
Unique identifier, correlation ID, RayID, or any of the variations, is a unique identifier that allows you to track a request throughout its life cycle. This allows you to track the entire path of the request in the logs.
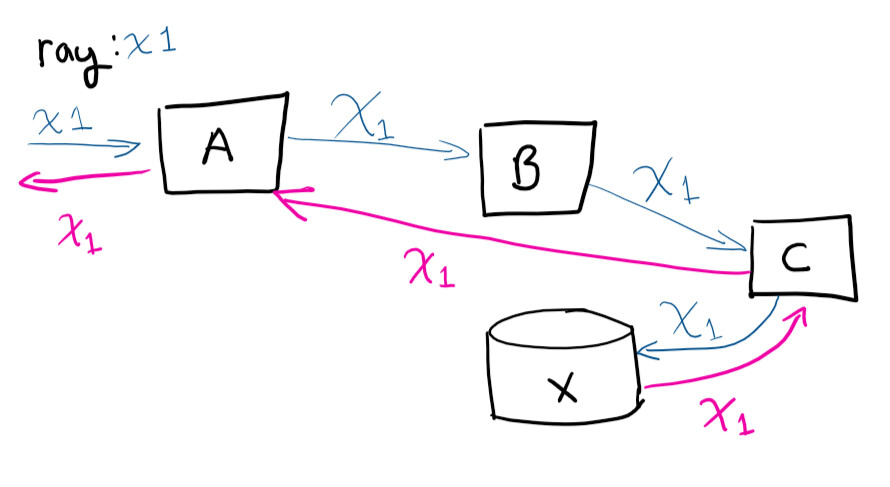
The user makes a request to system A, then A contacts B, that contacts C, saves to X, and then the request returns to A
If you were to remotely connect to virtual machines and try to trace the request path (and manually correlate which calls are occurring), you would go crazy. Having a unique identifier makes life much easier. This is one of the easiest things to do to save time as your service grows.
Middle level
The advice here is more complex than the previous ones, but the right tools make the task easier, providing a return on investment even for small and medium-sized companies.
Centralized logging
Congratulations! You have deployed 100 virtual machines. The next day, the CEO comes in and complains about an error he received while testing the service. It reports the corresponding ID that we talked about above, but you'll have to look through the logs of 100 machines to find the one that caused the crash. And she needs to be found before tomorrow's presentation.
While this sounds like a fun adventure, it's best to make sure you have the ability to search all the magazines from one place. I solved the problem of centralizing logs with the built-in functionality of the ELK stack: it supports searchable log collection. This will really help solve the problem with finding a specific log. As a bonus, you can create diagrams and other fun stuff like that.
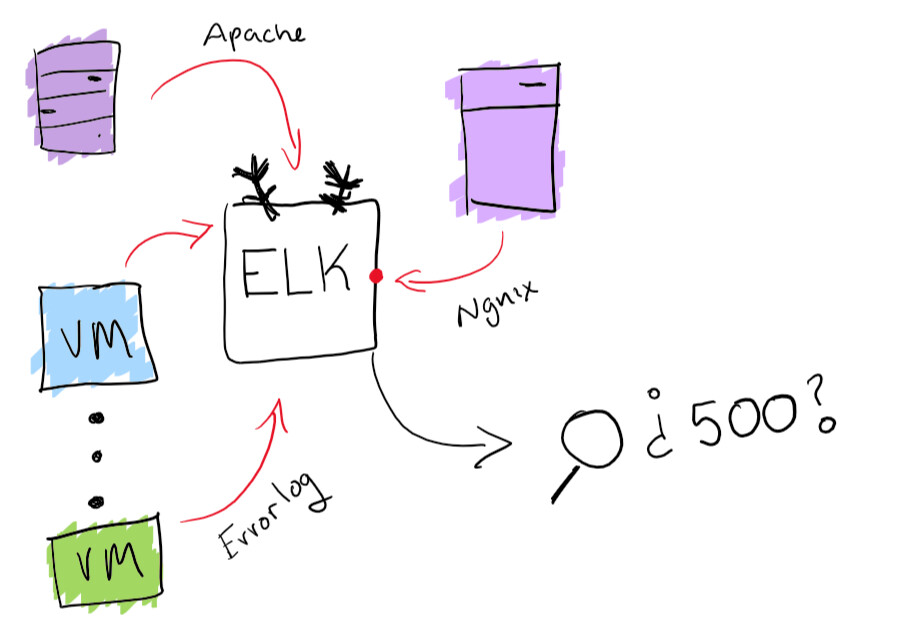
ELK stack functionality
Monitoring agents
Now that your service is up and running, you need to make sure it runs smoothly. The best way to do this is to run multiple agents that run in parallel and verify that it is up and running for basic operations.
At this point, you verify that the running assembly is doing well and is working fine .
For small to medium projects, I recommend Postman for monitoring and documenting APIs. But in general, you just need to make sure that you have a way to know when a failure has occurred and receive timely alerts.
Autoscaling based on load
It's very simple. If you have a virtual machine serving requests and it is close to 80% memory use, you can either increase its resources or add more virtual machines to the cluster. The automatic execution of these operations is excellent for elastic power changes under load. But you should always be careful about how much money you spend and set reasonable limits.
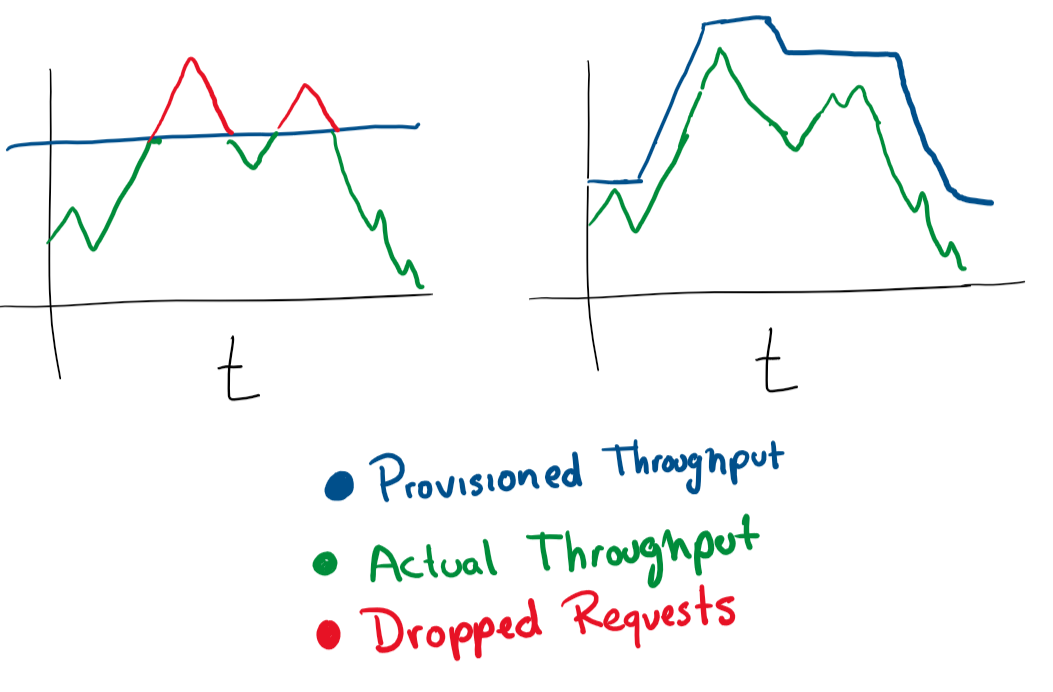
In most cloud services, you can configure auto-scaling with more servers or more powerful servers.
Experiment system
A good way to safely deploy updates is to be able to test something for 1% of users within an hour. You've certainly seen such mechanisms in action. For example, Facebook shows parts of the audience a different color or changes the font size to see how users perceive the change. This is called A / B testing.
Even releasing a new feature can be run as an experiment and then figured out how to release it. You also get the ability to "remember" or change the configuration on the fly, taking into account the function that causes the degradation of your service.
Advanced level
Here are some tips that are quite difficult to implement. You will probably need a little more resources, so it will be difficult for a small to medium-sized company to handle this.
Blue-green deployments
This is what I call the "Erlang" deployment method. Erlang was widely used when the telephone companies came along. Soft switches have been used to route telephone calls. The main focus of the software on these switches was not to drop calls during system upgrades. Erlang has a great way to load a new module without crashing the previous one.
This step depends on the presence of a load balancer. Let's say you have version N of your software and then you want to deploy version N + 1.
You could just stop the service and deploy the next version at a time that is convenient for your users and get some downtime. But suppose you havereally strict SLA terms. So, SLA 99,99% means that you can go offline only 52 minutes per year.
If you really want to achieve this, you need two deployments at the same time:
- the one that is right now (N);
- next version (N + 1).
You tell the load balancer to redirect a percentage of your traffic to the new version (N + 1) while you actively track regressions yourself.
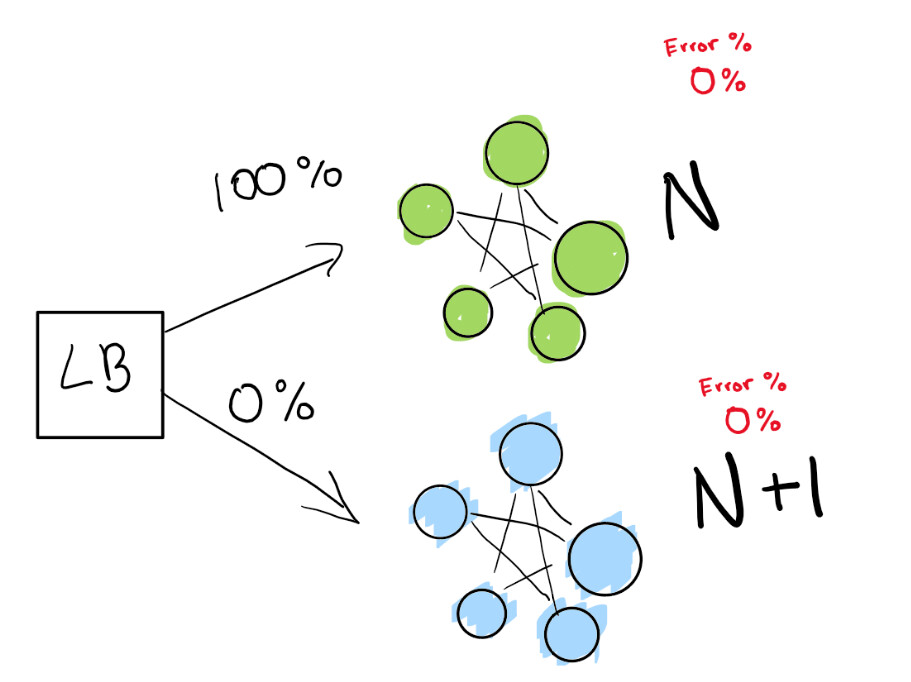
Here we have a green deployment N that works fine. We're trying to move on to the next version of this deployment
First, we send a really small test to see if our N + 1 deployment works with little traffic:
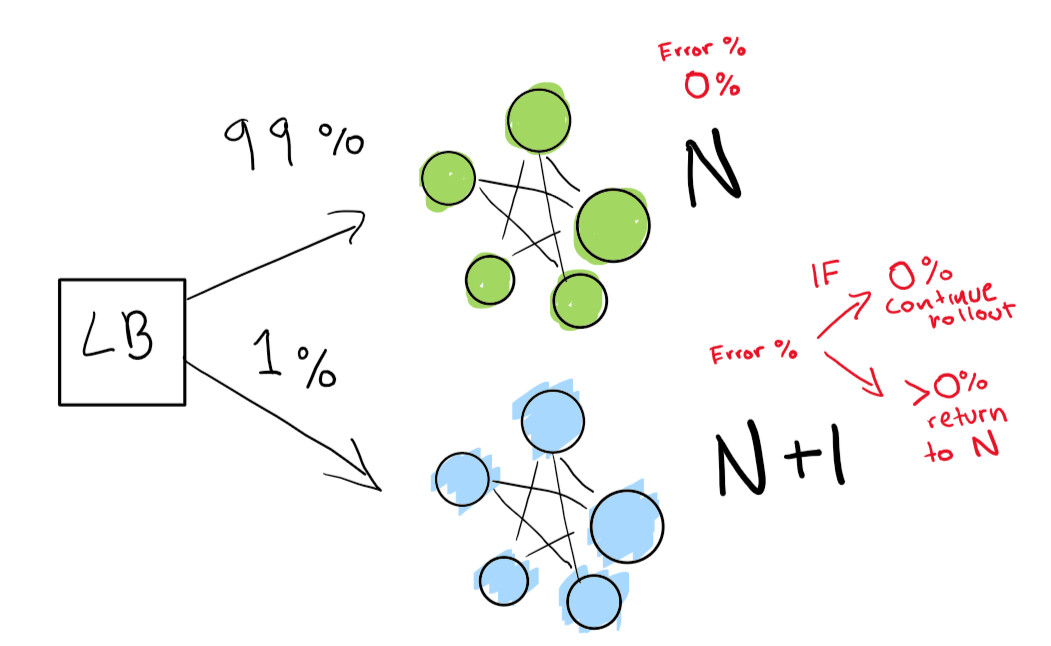
Finally, we have a set of automated checks that we end up running until our deployment is complete. If you are very, very careful, you can also keep your N deployment forever for a quick rollback in case of bad regression:
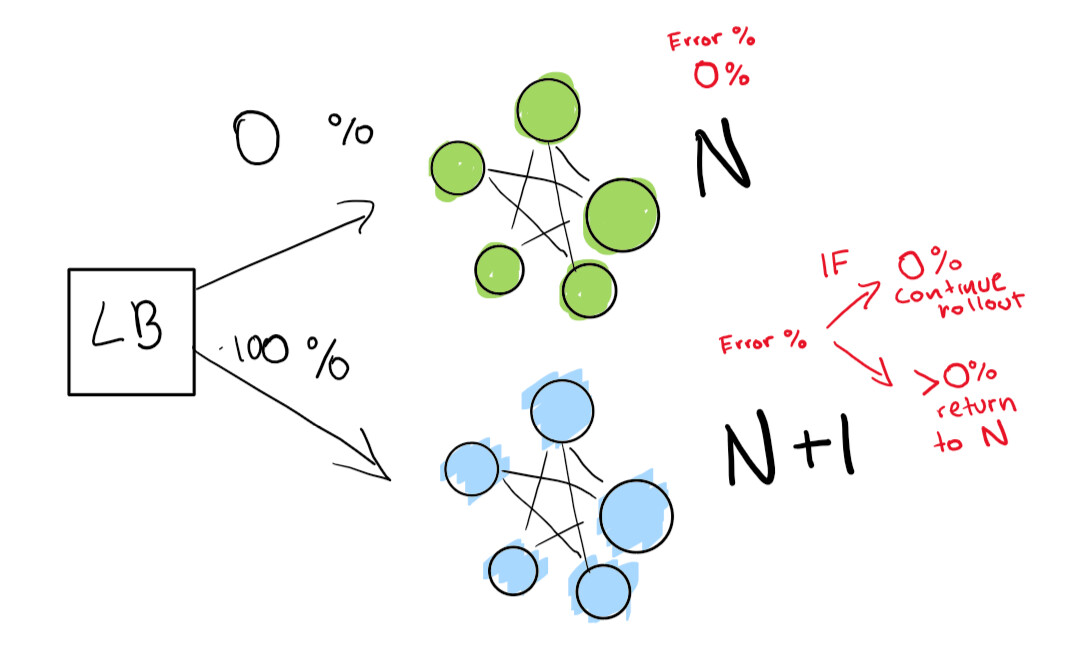
If you want to go to an even more advanced level, let everything in the blue-green deploy be done automatically.
Anomaly detection and automatic mitigation
Given that you have centralized logging and good log collection, you can already set higher goals. For example, proactively predicting failures. On monitors and in logs, functions are tracked and various diagrams are built - and you can predict in advance what will go wrong:
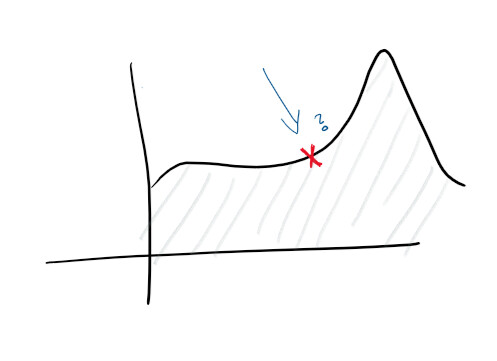
With the discovery of anomalies, you begin to study some of the clues that the service issues. For example, a spike in CPU utilization might suggest that a hard drive is failing, while a spike in requests means that you need to scale. This kind of statistics allows us to make the service proactive.
With this insight, you can scale in any dimension, proactively and reactively change the characteristics of machines, databases, connections and other resources.
That's all!
This list of priorities will save you a lot of trouble if you are bringing up a cloud service.
The author of the original article invites readers to leave their comments and make changes. The article is distributed as open source, the author accepts pull requests on Github .
What else to read on the topic: