If you've been designing backend applications or databases for a while, then you've probably written code to execute paginated queries. For example - like this:
SELECT * FROM table_name LIMIT 10 OFFSET 40
The way it is?
But if this is how you did pagination, I regret to note that you did not do it in the most efficient way.
Do you want to argue with me? You don't have to waste time . Slack , Shopify, and Mixmax are already using the tricks I want to talk about today.
Name at least one developer backend, which never used
OFFSETand LIMITto perform queries with pagination. In MVP (Minimum Viable Product, minimum viable product) and in projects that use small amounts of data, this approach is quite applicable. It just works, so to speak.
But if you need to create reliable and efficient systems from scratch, you should take care in advance about the efficiency of queries to the databases used in such systems.
Today we will talk about the problems associated with widely used (sorry it is) implementations of paginated query execution engines, and how to achieve high performance when executing such queries.
What's wrong with OFFSET and LIMIT?
As it has been said,
OFFSETand LIMITperfectly show itself in projects that do not need to work with large amounts of data.
The problem arises when the database grows to such a size that it ceases to fit in the server's memory. However, while working with this database, you must use paginated queries.
In order for this problem to manifest itself, it is necessary that a situation arises in which the DBMS resorts to an inefficient Full Table Scan operation when executing each query with pagination (at the same time, data insertion and deletion operations can occur , and we don't need outdated data!).
What is a "full table scan" (or "sequential table scan", Sequential Scan)? This is an operation during which the DBMS sequentially reads each row of the table, that is, the data contained in it, and checks them against a given condition. This type of table scan is known to be the slowest. The fact is that when it is executed, many I / O operations are performed that use the server's disk subsystem. The situation is aggravated by the delays associated with working with data stored on disks, and the fact that transferring data from disk to memory is a resource-intensive operation.
For example, you have records of 100,000,000 users and you are running a query with the construction
OFFSET 50000000... This means that the DBMS will have to load all these records (and we don't even need them!), Place them in memory, and only after that take, say, 20 results reported in LIMIT.
Let's say it might look like "select lines 50,000 to 50020 out of 100,000." That is, the system will first need to load 50,000 rows to execute the query. See how much unnecessary work she has to do?
If you don't believe me, take a look at the example I created using db-fiddle.com .

Example at db-fiddle.com
There, on the left, in the box
Schema SQL, there is code to insert 100,000 rows into the database, and on the right, in the boxQuery SQL, two queries are shown. The first, slow, looks like this:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
And the second, which is an effective solution to the same problem, like this:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
In order to fulfill these requests, just click on the button
Runat the top of the page. Having done this, let's compare the information about the query execution time. It turns out that the execution of an inefficient query takes at least 30 times longer than the execution of the second (this time differs from launch to launch, for example, the system may report that the first request took 37 ms to complete, and execution of the second - 1 ms).
And if there is more data, then everything will look even worse (in order to verify this, take a look at my example with 10 million rows).
What we've just discussed should give you some insight into how database queries are actually handled.
Keep in mind that the greater the value
OFFSET - the longer the request will take.
What should be used instead of a combination of OFFSET and LIMIT?
Instead of a combination
OFFSET, LIMITit is worth using a structure built according to the following scheme:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
This is the execution of a Cursor based pagination query.
Instead of locally stored current
OFFSETand LIMITand send them to each request, it is necessary to store the last received primary key (usually - a ID) and LIMIT, as a result and will be prompted resembling the above-stated.
Why? The fact is that by explicitly specifying the identifier of the last read line, you tell your DBMS where it needs to start looking for the data it needs. Moreover, the search, thanks to the use of the key, will be carried out efficiently, the system will not have to be distracted by lines that are outside the specified range.
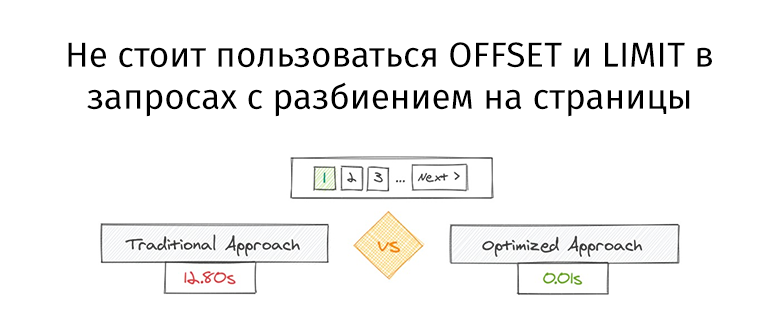
Let's take a look at the following performance comparison of different queries. Here's an ineffective query.
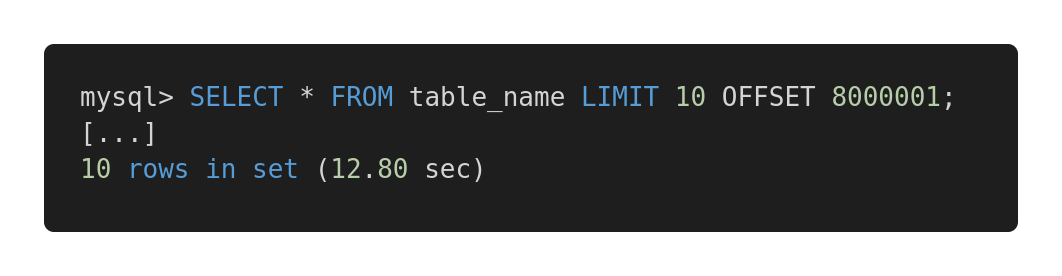
Slow Query
And here is an optimized version of this query.

Quick Query
Both queries return exactly the same amount of data. But the first takes 12.80 seconds, and the second takes 0.01 seconds. Do you feel the difference?
Possible problems
For the proposed query execution method to work efficiently, the table must have a column (or columns) containing unique, sequential indexes, such as an integer identifier. In some specific cases, this can determine the success of using such queries in order to increase the speed of working with the database.
Naturally, when designing queries, you need to take into account the peculiarities of the architecture of the tables, and choose those mechanisms that will best show themselves on the existing tables. For example, if you need to work in queries with large amounts of related data, you might find this article interesting .
If we are faced with the problem of the absence of a primary key, for example, if we have a table with a many-to-many relationship, then the traditional approach of using
OFFSETand LIMITis guaranteed to work for us. But its application can lead to the execution of potentially slow queries. In such cases, I would recommend using an autoincrementing primary key, even if you only need it to organize paginated queries.
If you are interested in this topic - here , here and here - some useful materials.
Outcome
The main conclusion that we can draw is that it is always necessary to analyze the speed of query execution, whatever the size of the databases. Nowadays, scalability of solutions is extremely important, and if you design everything correctly from the very beginning of work on a certain system, this, in the future, can save the developer from many problems.
How do you analyze and optimize database queries?
