
My name is Alexander Deulin, I work in the development department of my own development "Factory of Microservices" at MegaFon. And I want to tell you about the thorny path of the emergence of Tarantool caches in the landscape of our company, as well as how we implemented replication from Oracle. And I will immediately explain that in this case the cache means an application with a database.
Tarantool caches
We have already talked a lot about how we implemented Unified Billing at MegaFon , we will not dwell on this in detail, but now the project is at the completion stage. Therefore, just a little statistics:
With what we approached our task:
- 80 million subscribers;
- 300 million subscriber profiles;
- 2 billion transactional events to change the balance per day;
- 250 TB of active data;
- > 8 PB of archives;
- and all this is located on 5000 servers in different data centers.
That is, we are talking about a highly loaded system, in which each subsystem began to serve 80 million subscribers. If earlier we had 7 instances and conditional horizontal scaling, now we switched to the domain. There used to be a monolith, but now we have DDD. The system is well covered by the API, divided into subsystems, but not everywhere there is a cache. Now we are faced with the fact that subsystems create an ever-increasing load. In addition, new channels appear that require them to provide 5000 requests per second per operation with a latency of 50 ms in 95% of cases, and to ensure availability at the level of 99.99%.
In parallel, we started to create a microservice architecture.

We have a separate layer of caches into which data from each subsystem is raised. This makes it easy to assemble composites and isolate master systems from heavy reading workloads.
How to build a cache for closed subsystems?
We decided that we need to create caches ourselves, not relying on the vendor. Unified Billing is a closed ecosystem. It contains a lot of microservice patterns, which have numerous APIs and their own databases. However, due to the closed nature, it is impossible to modify anything.
We began to think about how we should approach our master systems. A very popular approach is event driven design, when we receive data from some kind of bus: either this is a Kafka topic, or exchange RabbitMQ. You can also get data from Oracle: by triggers, using CQN (a free tool from Oracle) or Golden Gate. Since we cannot integrate into the application, the write-through and write-behind options were not available to us.
Receiving data from the message dispatcher bus
We really like the option with queues and message managers. RabbitMQ and Kafka are already used in "Unified billing". We piloted one of the systems and got an excellent result. We receive all events from RabbitMQ and do cold loading, the amount of data is not very large.
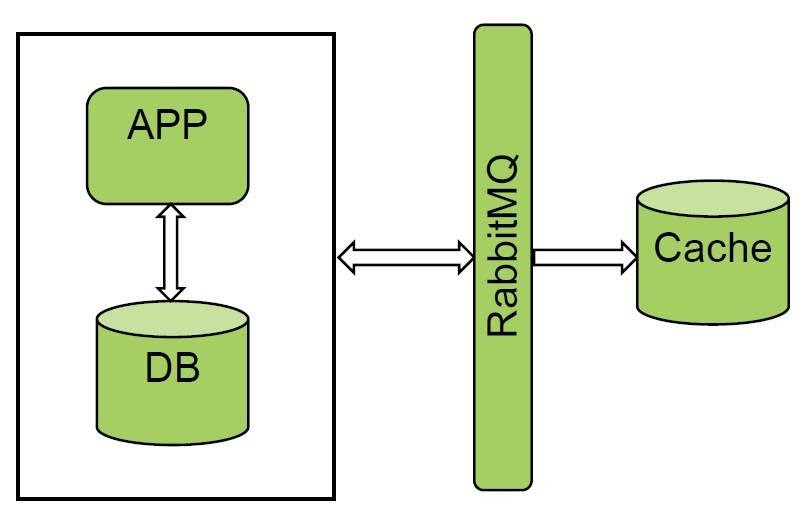
The solution works fine, but not all systems can notify buses, so this option did not work for us.
Retrieving data from the database: triggers
There was still a way to get data to fill the cache from the database.
The simplest option is triggers. But they are not suitable for high-load applications, because, firstly, we modify the master system itself, and secondly, this is an additional point of failure. If the trigger was suddenly unable to write to some kind of temporary plate, we get complete degradation, including the master system.

Retrieving data from the database: CQN
The second option for getting data from the database. We use Oracle, and the vendor currently supports only one free tool for obtaining data from the database - CQN.
This mechanism allows you to subscribe to DDL or DML operation change notifications. Everything is quite simple there. There are JDBC and PL / SQL style notifications.
JDBC means that we notify the advanced queue and this event is sent to the external system. In fact, an external OSI connector is needed. We didn't like this option, because if we lose our connection with Oracle, we can't read our message.
We chose PL / SQL because it allows us to intercept the notification and store it in a temporary table in the same Oracle database. That is, in this way you can provide some transactional integrity.
Everything worked fine in the beginning until we piloted a fairly loaded base. The following shortcomings appeared:
- Transactional load on the base. When we intercept a message from the notification queue, we need to put it in the base. That is, the write load doubles.
- It also uses an internal advanced queue. And if your master system also uses it, then competition for the queue can arise.
- We got an interesting error on partitioned tables. If one commit closes more than 100 changes, then CQN does not catch such changes. We opened a ticket in Oracle, changed the system parameters - it didn't help.
For heavy applications, CQN is definitely not suitable. It is good for small installations, for working with some kind of dictionaries, reference data.
Retrieving data from the database: Golden Gate
The good old Golden Gate remains. Initially, we did not want to use it, since it is an old-fashioned solution, we were intimidated by the complexity of the system itself.

In GG itself, there were two additional instances that needed to be maintained, and we don't have much Oracle knowledge. Initially, it was quite difficult, although we really liked the possibilities of the solution.
The SCN + XID combination allowed us to control transactional integrity. The solution turned out to be universal, it has a low impact on the master system, from which we can receive all events. Although the solution requires the purchase of a license, this was not a problem for us since the license was already available. Also, the disadvantages of the solution include a complex implementation and the fact that GG is an additional subsystem.
conclusions
What conclusions can be drawn from the above?
If you have a closed system, then you need to research the nature of your load and the ways of use, and select the appropriate solution. The optimal, in our opinion, is event driven design, when we notify a topic in Kafka and the message broker becomes the master system. A topic is a golden record, the rest of the data is taken by the system. For closed systems in our landscape, GG turned out to be the most successful solution.
PIM - food showcase
And now, using the example of one of the products, I will tell you how we applied this solution. PIM is a SID-based product showcase. That is, these are all the subscriber's products that are currently connected to him. On their basis, expenses are calculated and the logic of work is built.
Architecture
Let me remind you that in this article, "cache" means a combination of an application and a database, this is the main use pattern for Tarantool.
The peculiarity of the PIM project is that the original Oracle master system is "small", only 10 billion records. It must be read. And the biggest problem we solved was cache warming up.
Where did we start?

The main 10 tables give 10 billion records. We wanted to read them head-on. Since we raise only hot data to the cache, and Oracle stores, among other things, historical data, we had to set a where clause and pull out these 10 billion. A non-trivial task. Oracle told us that this should not be done: raised the processor load to 100%. We decided to go the other way.
But first, a few words about the cluster architecture.
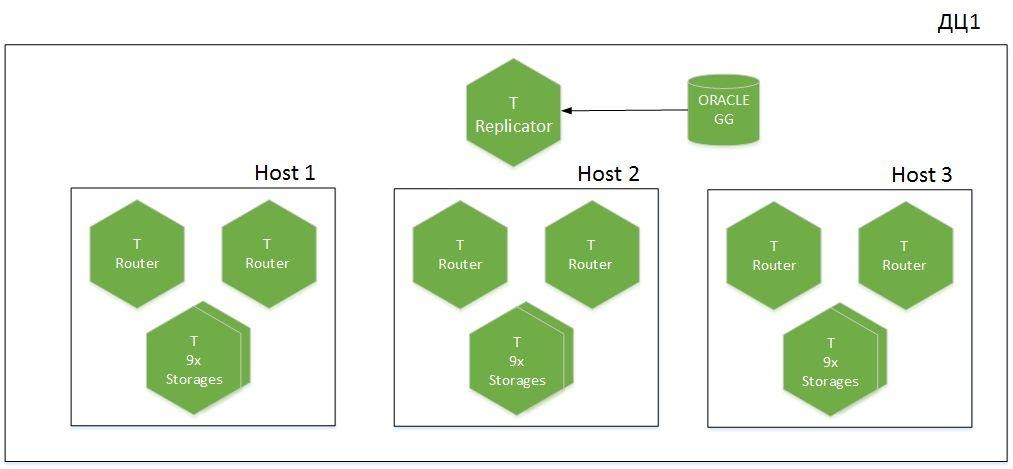
This is a sharded application, 9 shards in 6 hosts, distributed over two data centers. We have Tarantool with the role of Replicator, which receives data from Oracle, and another instance called Importer is used for cold boot. A total of 1.1 TB of hot data is raised in the cache.
Cold boot
How did we solve the cold boot problem? Everything turned out to be quite trivial.

How does the whole mechanism work? We removed the where clause and read everything. First, we start the redo-log stream to actually receive online changes from the database. By full scanning we go through subsections, taking data in batches with normalization and filtration. We save the changes, in parallel, we start cold warming up the cache and put everything in CSV files. There are 10 Importer instances running in the cache, which, after being read from Oracle, send data to Tarantool instances. To do this, each Importer calculates the required shard and puts the data in the necessary storage itself, without loading the routers.
After loading all the data from Oracle, we play the stream of trails from GG that have accumulated during this time. When SCN + XID reaches acceptable values with the master system, we consider that the cache is warmed up, and include the load on reading from external systems.
Some statistics. At Oracle, we have about 2.5 TB of raw data. We read them for 5 hours, import them into CSV. Loading into Tarantool with filtering and normalization takes 8 hours. And for six hours we play the accumulated logs that come to us from the trail. Peak speed from 600 thousand records / s. up to 1 million in peaks. Tarantool inserts 1.1 TB of data at 200K records / s.
Now, cold warming up the cache at large volumes has become commonplace for us, because we do not have much impact on Oracle.

Instead of the base, we load the I / O and the network, so we must first make sure that we have a sufficient margin of network bandwidth, in our peaks it reaches 400 Mbps.
How the replication chain from Oracle to Tarantool works
When designing the cache, we decided to save memory. We removed all redundancy, combined five tables into one, and got a very compact storage scheme, but lost control over consistency. We came to the conclusion that it is necessary to repeat the DDL from Oracle. This allowed us to control SCN + XIDs by storing them in a separate technological space for each plate. By checking them periodically, we can understand where the replication broke down, and in case of problems, we reread the archiving logs.
Sharding
A little about logical data storage. To eliminate Map Reduce, we had to introduce additional data redundancy and decompose dictionaries into our own storages. We went for this deliberately, because our cache works mainly for reading. We cannot integrate it into the master system, since this application isolates the load of external channels from the master system. We read all data on subscribers from one storage. In this case, we lose in write performance, but it is not so important for us, dictionaries are updated infrequently.
What happened in the end?
We have created a cache for our closed system. There were some filtering errors, but we have already fixed them. We have prepared for the emergence of new high-load consumers. Last summer, a new system appeared, which added 5-10 thousand requests per second, and we did not let this load into the "Unified Billing". We also learned how to prepare replication from Oracle to Tarantool, worked out the transfer of large amounts of data without loading the master system.
What do we still have to do?
These are mainly operational scenarios:
- Automatic control of data consistency.
- Work out the Oracle Active-Standby switching scenario, both switchover and failover.
- Playing archive logs from GG.
- — DDL- -. , DDL , .
- «»: ? https://habr.com/ru/article/470842/
- : Tarantool https://habr.com/ru/company/mailru/blog/455694/
- Telegram Tarantool https://t.me/tarantool_news
- Tarantool - https://t.me/tarantoolru