Part 2
Part 3
In this article, you will learn:
- What transfer learning is and how it works
- What semantic / instance segmentation is and how it works
- About what object detection is and how it works
Introduction
There are two methods for object detection tasks (see the source and more details here ):
- Two -stage methods, they are also "methods based on regions" (eng. Region-based methods) - an approach divided into two stages. At the first stage, regions of interest (RoI) are selected by selective search or using a special layer of the neural network - regions that contain objects with a high probability. At the second stage, the selected regions are considered by the classifier to determine the belonging to the original classes and by the regressor, which specifies the location of the bounding boxes.
- Single-stage method (Engl one-stage methods.) - approach, not using a separate algorithm to generate regions instead predicting coordinates certain amount of bounding boxes with different characteristics, such as the classification results and the degree of confidence, and further adjusting the location framework.
This article discusses one-step methods.
Transfer learning
Transfer learning is a method of training neural networks, in which we take a model already trained on some data for further additional training to solve another problem. For example, we have an EfficientNet-B5 model trained on an ImageNet dataset (1000 classes). Now, in the simplest case, we change its last classifier-layer (say, to classify objects of 10 classes).
Take a look at the picture below:
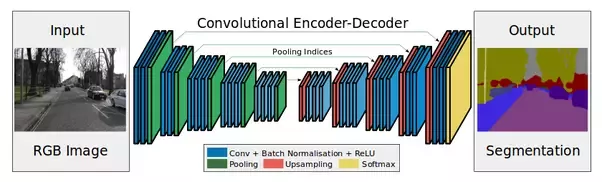
Encoder is subsampling layers (convolutions and pools).
Replacing the last layer in the code looks like this (framework - pytorch, environment - google colab):
Load the trained EfficientNet-b5 model and look at its classifier-layer:

Change this layer to another:
Decoder is needed, in particular, in the segmentation task (about this Further).
Transfer learning strategies
It should be added that by default all layers of the model that we want to train further are trainable. We can "freeze" the weights of some layers.
To freeze all layers:

The fewer layers we train, the less computing resources we need to train the model. Is this technique always justified?
Depending on the amount of data on which we want to train the network, and on the data on which the network was trained, there are 4 options for the development of events for transfer learning (under "little" and "a lot" you can take the conditional value 10k):
- You have little data , and it is similar to the data on which the network was trained before. You can try to train only the last few layers.
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
Semantic segmentation is when we feed an image as input, and at the output we want to get something like:

More formally, we want to classify each pixel of our input image - to understand which class it belongs to.
There are a lot of approaches and nuances here. What is only the architecture of the ResNeSt-269 network :)
Intuition - at the input the image (h, w, c), at the output we want to get a mask (h, w) or (h, w, c), where c is the number of classes (depends on data and model). Let's now add a decoder after our encoder and train them.
Decoder will consist, in particular, of upsampling layers. You can increase the dimension simply by "stretching" our feature map in height and width at one step or another. When pulling, you can usebilinear interpolation (in the code it will be just one of the method parameters).
Deeplabv3 + network architecture:
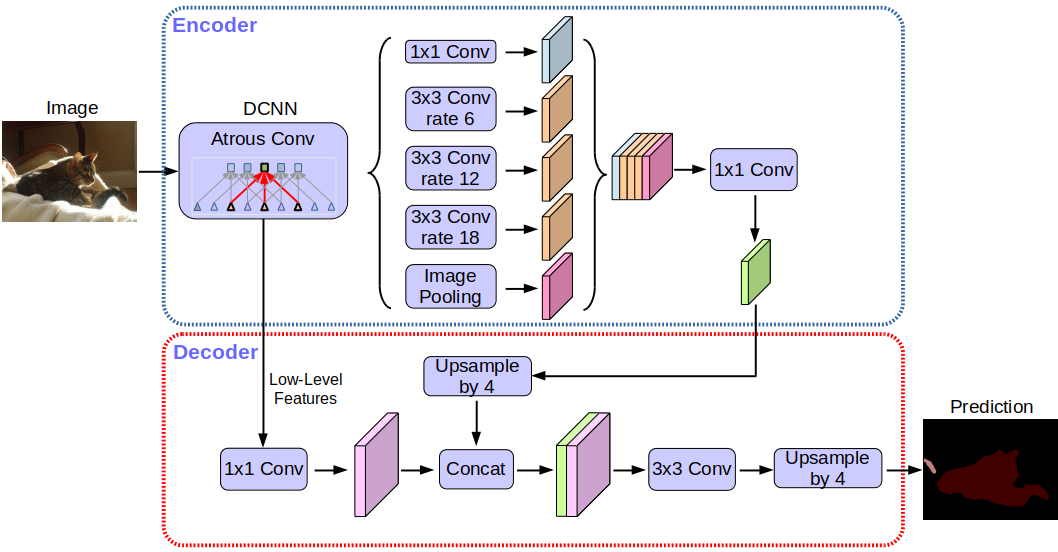
Without going into details, you will notice that the network uses the encoder-decoder architecture.
A more classic version, the architecture of the U-net network:
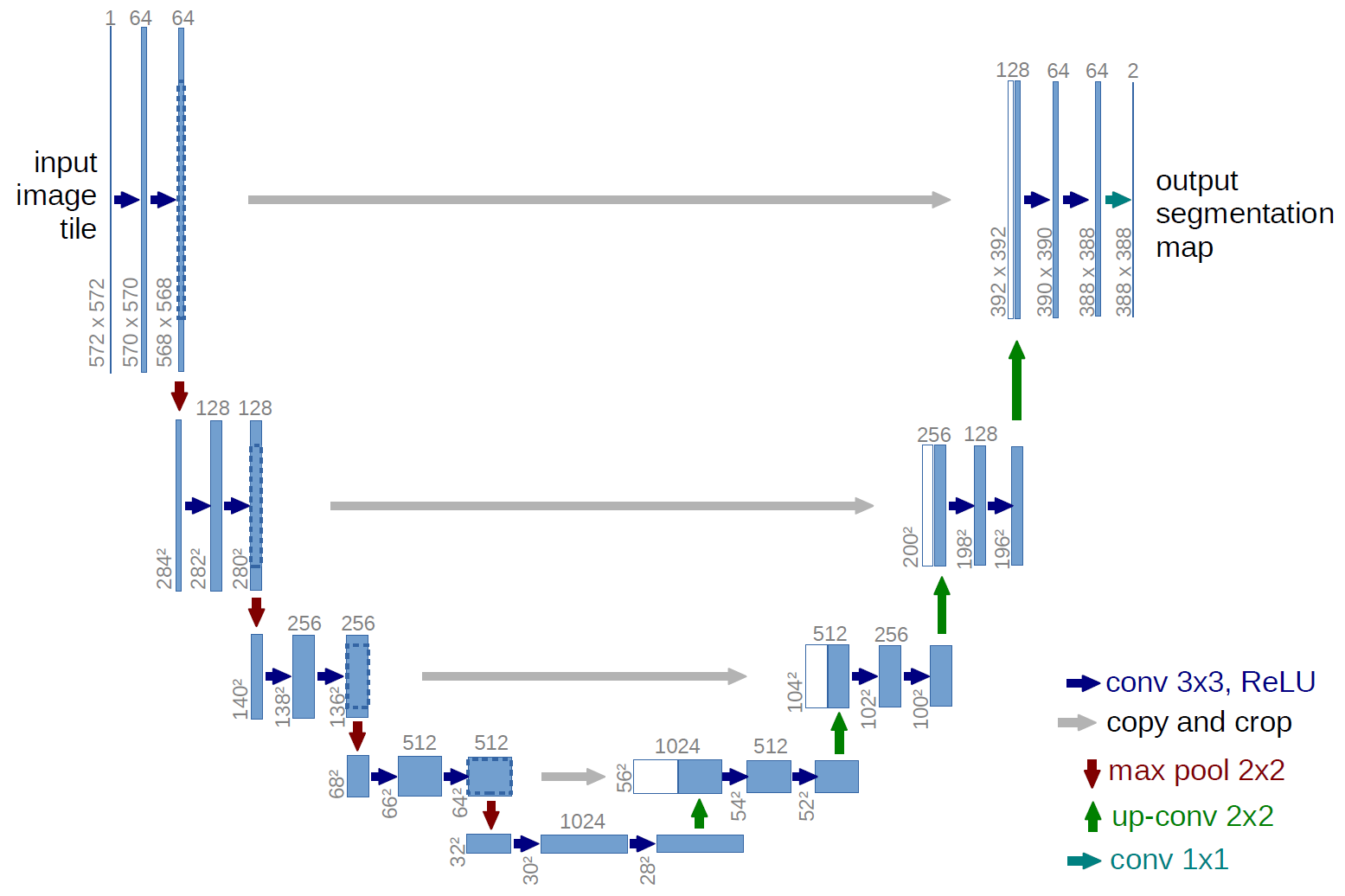
What are these gray arrows? These are the so-called skip connections. The point is that the encoder “encodes” our input image lossy. In order to minimize such losses, they use skip connections.
In this task, we can use transfer learning - for example, we can take a network with an already trained encoder, add a decoder and train it.
On what data and what models perform best in this task at the moment - you can see here...
Instance segmentation
A more complex version of the segmentation problem. Its essence is that we want not only to classify each pixel of the input image, but also to somehow select different objects of the same class:
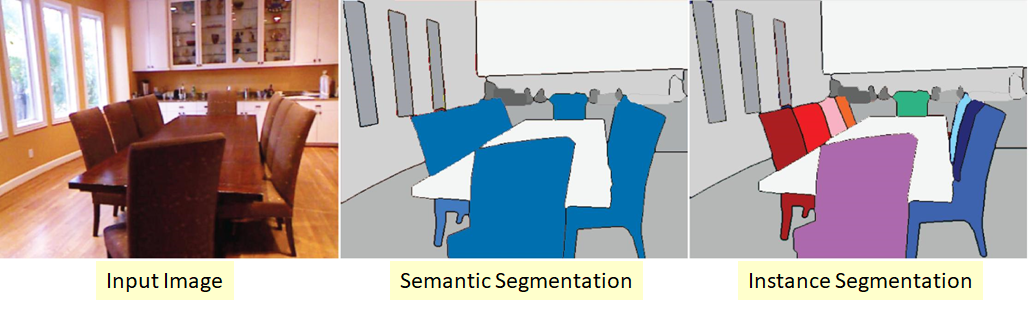
It so happens that classes are "sticky" or there is no visible border between them, but we want to delimit objects of the same class apart.
There are also several approaches here. The simplest and most intuitive is that we train two different networks. We teach the first one to classify pixels for some classes (semantic segmentation), and the second one to classify pixels between class objects. We get two masks. Now we can subtract the second from the first and get what we wanted :)
On what data and which models perform best in this task at the moment - you can see here...
Object detection
We send an image to the input, and at the output we want to see something like:

The most intuitive thing that can be done is to “run” over the image with different rectangles and, using an already trained classifier, determine if there is an object of interest to us in this area. There is such a scheme, but it is obviously not the best one. After all, we have convolutional layers that somehow interpret the feature map "before" (A) in the feature map "after" (B). In this case, we know the dimensions of the convolution filters => we know which pixels from A to which pixels B were converted.
Let's take a look at YOLO v3:
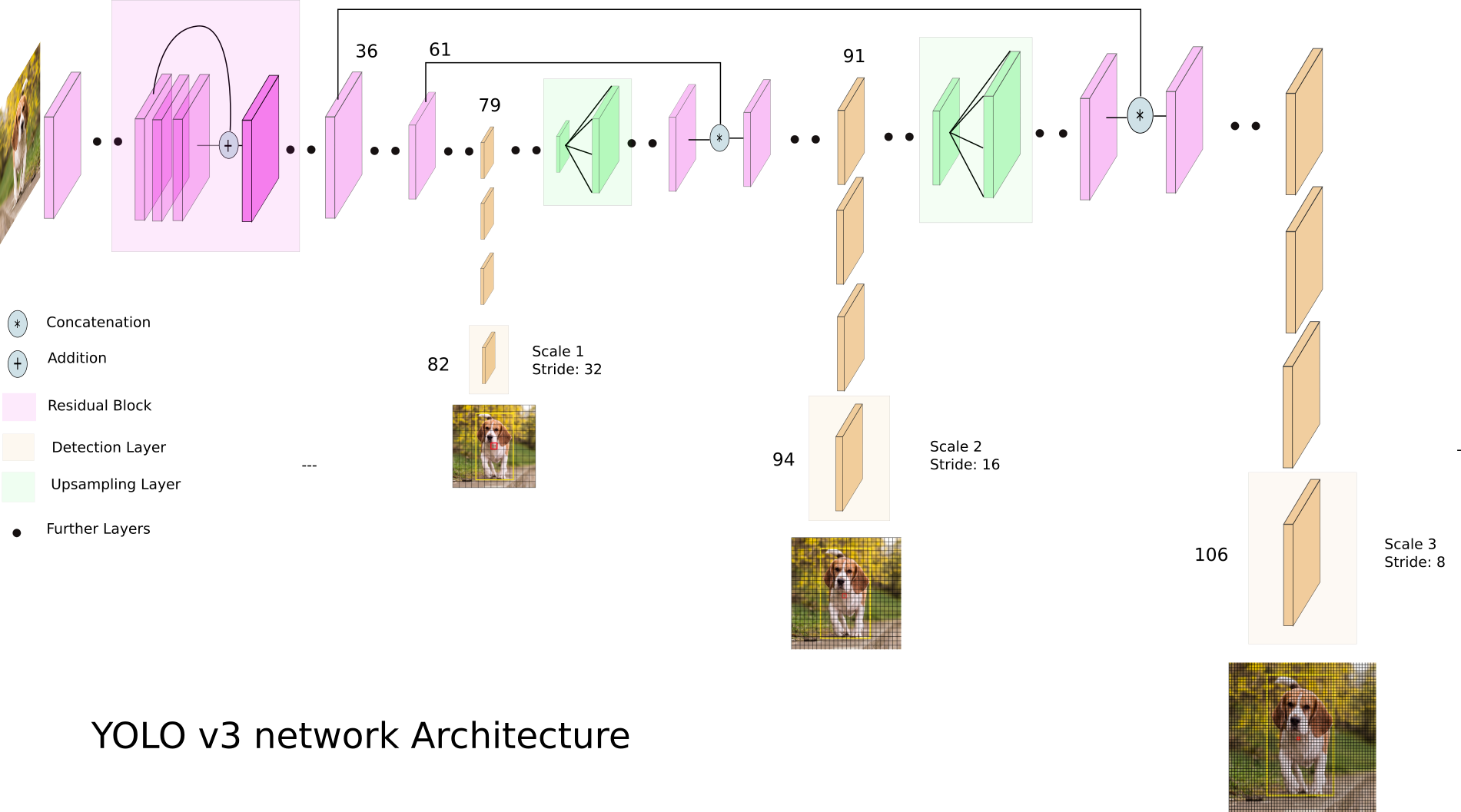
YOLO v3 uses different dimensioned feature maps. This is done, in particular, in order to correctly detect objects of different sizes.
Next, all three scales are concatenated:
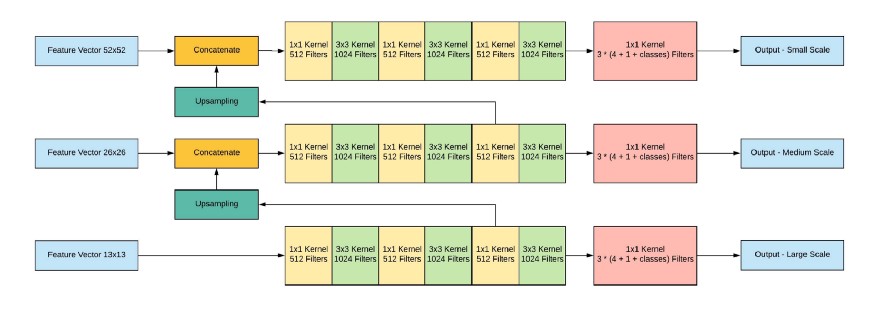
Network output, with an input image of 416x416, 13x13x (B * (5 + C)), where C is the number of classes, B is the number of boxes for each region (YOLO v3 has 3 of them). 5 - these are parameters such as: Px, Py - coordinates of the center of the object, Ph, Pw - height and width of the object, Pobj - the probability that the object is in this region.
Let's look at the picture, so it will be a little more clear:

YOLO filters out prediction data initially by objectness score by some value (usually 0.5-0.6), and then by non-maximum suppression .
On what data and what models perform best in this task at the moment - you can see here .
Conclusion
There are a lot of different models and approaches to the tasks of segmentation and localization of objects these days. There are certain ideas, understanding which, it will become easier to disassemble that zoo of models and approaches. I tried to express these ideas in this article.
In the next articles, we'll talk about style transfers and GANs.