"Slowing down programs is much faster than speeding up computers"
Since then, this statement has been considered Wirth's law . It effectively negates Moore's Law, which states that the number of transistors in processors has doubled since about 1965. Here is what Wirth writes in his article "Call for Slim Software" :
“About 25 years ago, an interactive text editor was only 8000 bytes, and a compiler was 32 kilobytes, while their modern descendants require megabytes. Has all this bloated software gotten faster? No, quite the opposite. If it were not for a thousand times faster hardware, then modern software would be completely unusable. "
It is difficult to disagree with this.
Obesity software
The problem of developing modern software is very acute. Wirth points out one important aspect: time. He suggests that the main reason for bloated software is the lack of development time.
Today there is another reason for software obesity - abstraction. And this is a much more serious problem. Developers have never written programs from scratch, but this has never been a problem before.
Dijkstra and Wirth tried to improve the quality of the code and developed the concept of structured programming. They wanted to take programming out of the crisis, and for some time programming was seen as a real craft for real professionals. The programmers cared about the quality of the programs, appreciated the clarity and efficiency of the code.
Those days are over.
With the rise of higher-level languages such as Java, Ruby, PHP and Javascript, programming became more abstract by 1995 when Wirth wrote his article. New languages made programming much easier and took on a lot. They were object oriented and came bundled with things like IDEs and garbage collection.
It became easier for programmers to live, but everything has to pay. The easier it is to live, the less to think. Around the mid-90s, programmers stopped thinking about the quality of their programs, writes developer Robin Martin in his article "Niklaus Wirth was right, and that's the problem . " At the same time, widespread use of libraries began, the functionality of which is always much more than necessary for a particular program.
Since the library is not built for one particular project, it probably has a little more functionality than it really needs. No problem, you say. However, things add up pretty quickly. Even people who love libraries don't want to reinvent the wheel. This leads to what is called dependency hell. Nicola Duza wrote a post about this issue in Javascript .
The problem doesn't seem like a big deal, but in reality it is more serious than you might think. For example, Nikola Dusa wrote a simple to-do list app. It works in your browser with HTML and Javascript. How many dependencies do you think it used? 13,000. Thirteen. Thousand. Proof .
The numbers are insane, but the problem will only grow. As new libraries are created, the number of dependencies in each project will also increase.
This means that the problem that Niklaus Wirth warned about in 1995 will only get worse over time.
What to do?
Robin Martin suggests that a good way to get started is to split the libraries. Instead of building one big library that does the best it can, just create many libraries.
Thus, the programmer only has to select the libraries that he really needs, ignoring the functionality that he is not going to use. Not only does it install fewer dependencies itself, but the libraries used will also have fewer dependencies.
End of Moore's Law
Unfortunately, the miniaturization of transistors cannot go on forever and has its physical limits. Perhaps sooner or later Moore's Law will cease to operate. Some say this has already happened. In the past ten years, the clock speed and power of individual processor cores have already stopped growing as they used to.
Although it is too early to bury him. There are a number of new technologies that promise to replace silicon microelectronics. For example, Intel, Samsung and other companies are experimenting with transistors based on carbon nanostructures (nanowires) , as well as photonic chips.

Evolution of transistors. Illustration: Samsung
But some researchers take a different approach. They propose new systems programming approaches to dramatically improve the efficiency of future software. Thus, it is possible to "restart" Moore's law by program methods, no matter how fantastic it sounds in the light of Nicklaus Wirth's observations on program obesity. But what if we can reverse this trend?
Software Acceleration Techniques
Recently, Science published an interesting article by scientists from the Computer Science and Artificial Intelligence Laboratory of the Massachusetts Institute of Technology (CSAIL MIT). They highlight three priority areas for further accelerating computation:
- the best software;
- new algorithms;
- more optimized hardware.
Lead author of the research paper Charles Leiserson confirms the obesity of software thesis . He says the benefits of miniaturizing transistors have been so great that for decades, programmers have been able to prioritize making code easier to write rather than speeding up execution. Inefficiency could be tolerated because faster computer chips always made up for software obesity.
“But nowadays, further advances in areas such as machine learning, robotics and virtual reality will require enormous computing power that miniaturization can no longer provide,” says Leiserson. "If we want to harness the full potential of these technologies, we must change our approach to computing."
In the software part, it is proposed to reconsider the strategy of using libraries with excessive functionality, because this is a source of inefficiency. The authors recommend concentrating on the main task - increasing the speed of program execution, and not on the speed of writing code.
In many cases, performance can indeed be increased thousands of times, and this is no exaggeration. As an example, the researchers cite the multiplication of two 4096 × 4096 matrices. They started with implementation in Python as one of the most popular high-level languages. For example, here's a four-line implementation in Python 2:
for i in xrange(4096):
for j in xrange(4096):
for k in xrange(4096):
C[i][j] += A[i][k] * B[k][j]The code contains three nested loops, and the solution algorithm is based on the school curriculum in algebra.
But it turns out that this naive approach is too inefficient for computing power. On a modern computer, it will run for about seven hours, as shown in the table below.
| Version | Implementation | Execution time (s) | GFLOPS | Absolute acceleration | Relative acceleration | Percentage of peak performance |
|---|---|---|---|---|---|---|
| 1 | Python | 25552.48 | 0.005 | 1 | - | 0.00 |
| 2 | Java | 2372.68 | 0.058 | eleven | 10.8 | 0.01 |
| 3 | C | 542.67 | 0.253 | 47 | 4.4 | 0.03 |
| 4 | Parallel loops | 69.80 | 1.97 | 366 | 7.8 | 0.24 |
| five | Divide and Conquer Paradigm | 3.80 | 36.18 | 6727 | 18.4 | 4.33 |
| 6 | + vectorization | 1.10 | 124.91 | 23224 | 3.5 | 14.96 |
| 7 | + intristics AVX | 0.41 | 337.81 | 52806 | 2.7 | 40.45 |
The transition to a more efficient programming language already dramatically increases the speed of code execution. For example, a Java program will run 10.8 times faster, and a C program another 4.4 times faster than Java. Thus, switching from Python to C means a 47x faster program execution.
And this is just the beginning of optimization. If you write the code taking into account the peculiarities of the hardware on which it will be executed, then you can increase the speed by another 1300 times. In this experiment, the code was first run in parallel on all 18 CPU cores (version 4), then used the processor cache hierarchy (version 5), added vectorization (version 6), and applied specific Advanced Vector Extensions (AVX) instructions in version 7. Latest optimized version the code takes only 0.41 seconds, not 7 hours, that is, more than 60,000 times faster than the original Python code.
What's more, on an AMD FirePro S9150 graphics card, the same code runs in just 70ms, 5.4 times faster than the most optimized version 7 on a general-purpose processor, and 360,000 times faster than version 1.
In terms of algorithms, the researchers propose a three-pronged approach that involves exploring new problem areas, scaling algorithms and adapting them to better take advantage of modern hardware.
For example, Strassen's algorithm for matrix multiplication by an additional 10% speeds up the fastest version of code number 7. For other problems, the new algorithms provide even more performance gain. For example, the following diagram shows the progress made in the efficiency of algorithms for solving the maximum flow problem between 1975 and 2015. Each new algorithm increased the speed of calculations by literally several orders of magnitude, and in subsequent years it was still optimized.
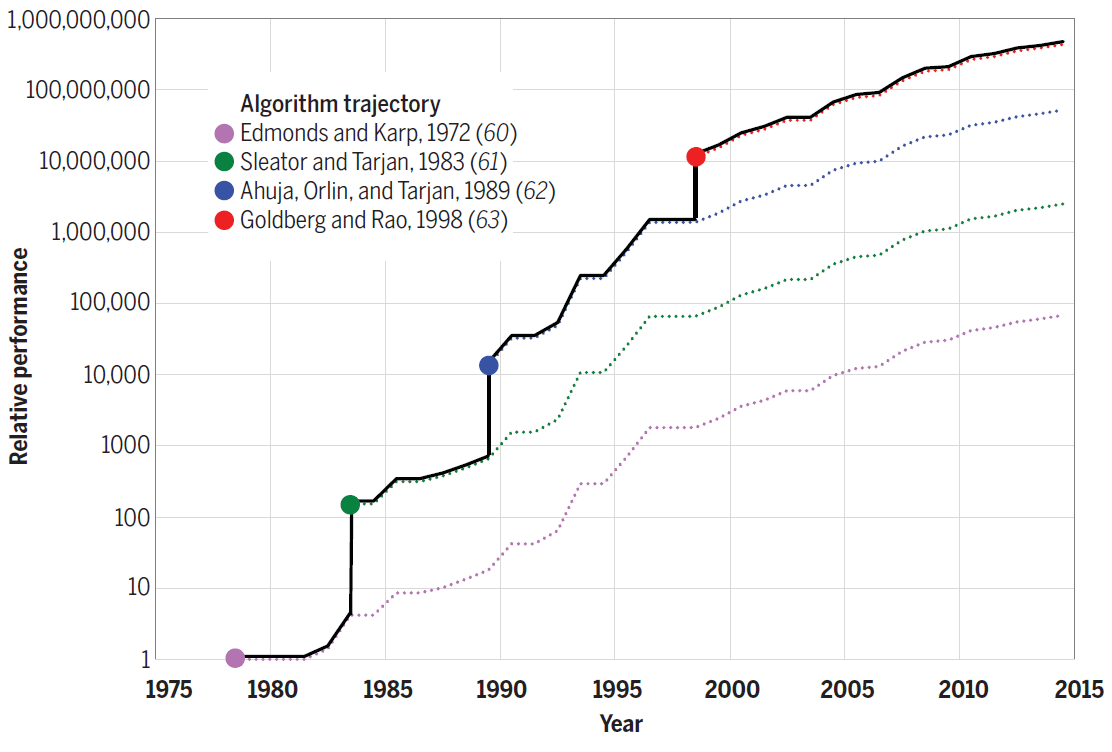
Efficiency of algorithms for solving the problem of maximum flow on a graph with n = 10 12 vertices and m = n 11 edges
Thus, improving the algorithms also contributes to "emulating" Moore's law programmatically.
Finally, in terms of hardware architecture, the researchers advocate optimizing the hardware so that problems can be solved with fewer transistors. Optimization involves the use of simpler processors and the creation of hardware tailored to specific applications, like the GPU is adapted for computer graphics.
“Equipment tailored to specific areas can be much more efficient and use far fewer transistors, allowing applications to run tens or hundreds of times faster,” says Tao Schardl, co-author of the research paper. "More generally, hardware optimization will further stimulate parallel programming by creating additional areas on the chip for parallel use."
The trend towards parallelization is already visible. As shown in the diagram, in recent years, CPU performance has increased solely due to the increase in the number of cores.
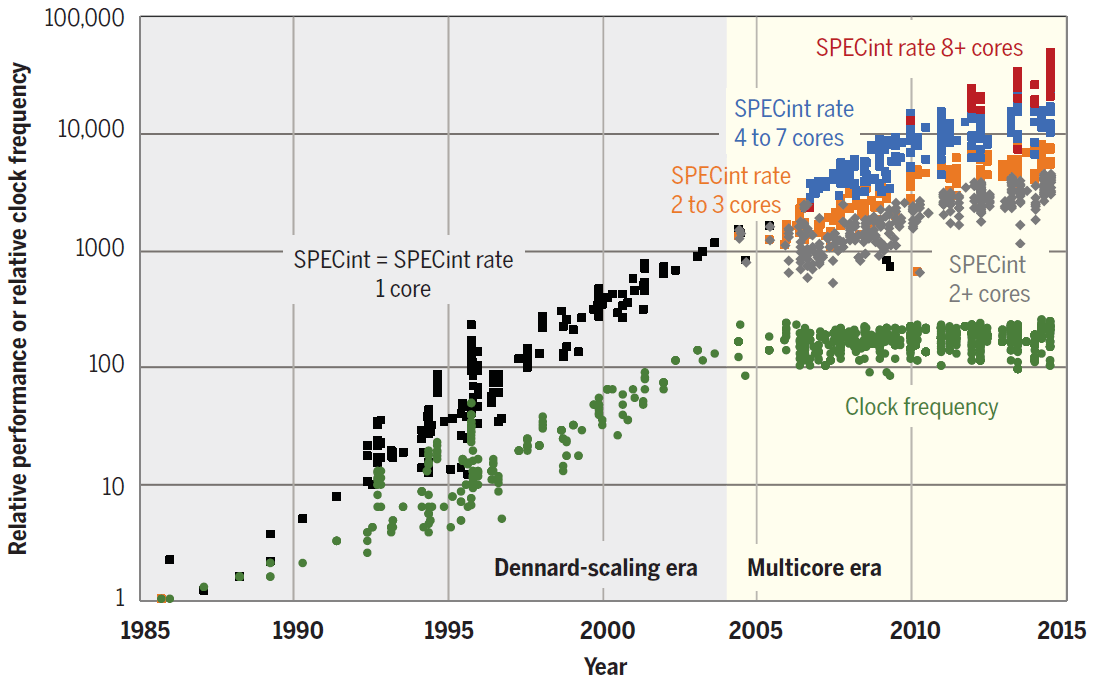
SPECint performance of individual cores and single and multi-core processors from 1985 to 2015. The base unit is a 1985 80386 DX microprocessor
For data center operators, even the smallest improvement in software performance can translate into large financial gains. Not surprisingly, companies such as Google and Amazon are now leading initiatives to develop their own specialized CPUs. The first released Google TPU tensor (neural) processors , and AWS Graviton chips are running in Amazon data centers .
Over time, the industry leaders may be followed by the owners of other data centers, so as not to lose to competitors in efficiency.
The researchers write that in the past, explosive performance gains in general-purpose processors have limited the scope for the development of specialized processors. Now there is no such limitation.
“Productivity gains will require new tools, programming languages, and hardware to enable more efficient design with speed in mind,” said Professor Charles Leiserson, research co-author. "It also means that programmers need to better understand how software, algorithms, and hardware fit together, rather than looking at them in isolation."
On the other hand, engineers are experimenting with technologies that can further boost CPU performance. These are quantum computing, 3D layout, superconducting microcircuits, neuromorphic computing, the use of graphene instead of silicon, etc. But so far these technologies are at the stage of experiments.
If CPU performance really stops growing, then we will find ourselves in a completely different reality. Perhaps we really have to reconsider our programming priorities, and assembler specialists will be worth their weight in gold.
Advertising
Need a powerful server ? Our company offers epic servers - virtual servers with AMD EPYC CPU, CPU core frequency up to 3.4 GHz. The maximum configuration will impress anyone - 128 CPU cores, 512 GB RAM, 4000 GB NVMe.
