Recently, colleagues in the "shop" independently of each other began to ask me: how to get all Bluetooth channels from one SDR receiver simultaneously? The bandwidth allows, there is SDR with an output bandwidth of 80 MHz or more. You can, of course, do it on FPGA, but the development time will be quite long. I have known for a long time that it is quite easy to do this on a GPU, but that's it!
The Bluetooth standard defines the physical layer in two versions: Classic and Low Energy. The specification is here . The document is terribly large; reading it in its entirety is dangerous for the brain. Fortunately, large instrumentation companies have the means to create visual documents on a topic. Tektronix and National Instruments , for example. I have absolutely no chance of competing with them in terms of the quality of the presentation of the material. If you are interested, please follow the links.
All I need to know about the physical layer to create a multichannel filter is the frequency grid step and modulation rate. They are tabulated in one of the following documents:
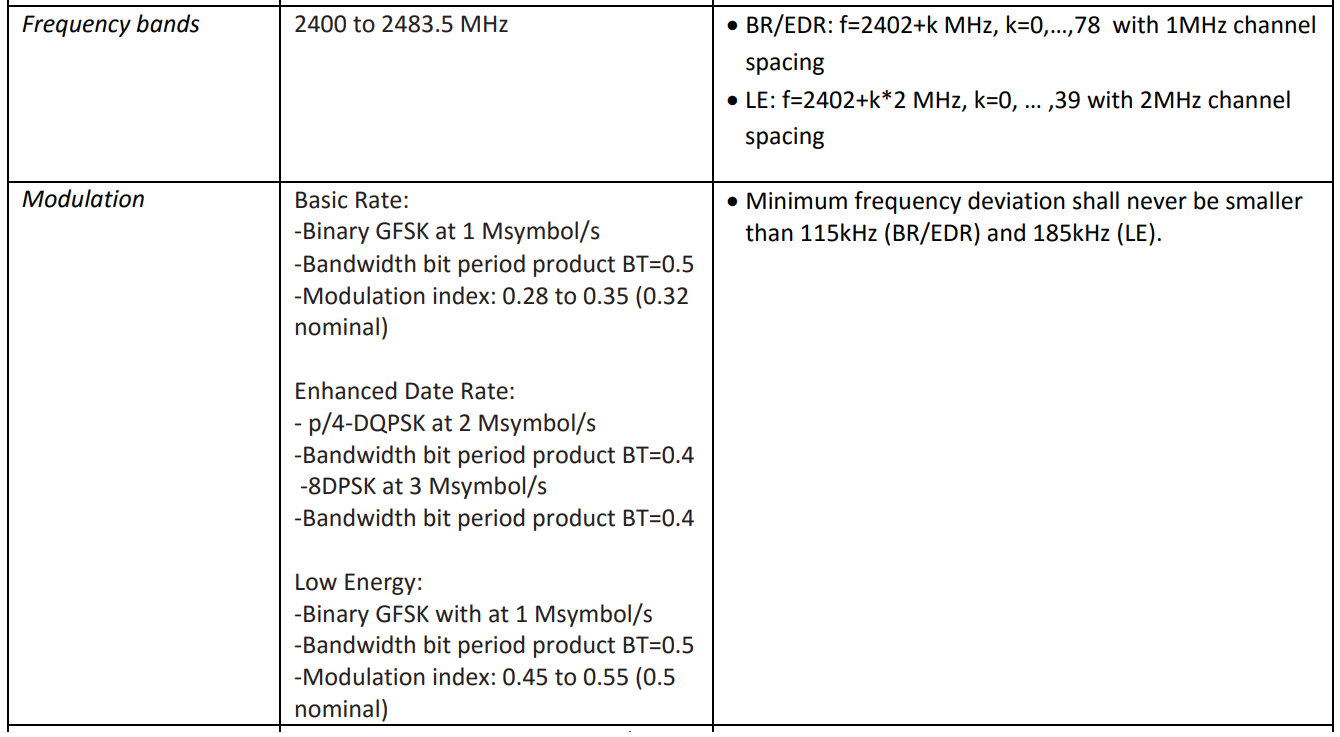
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
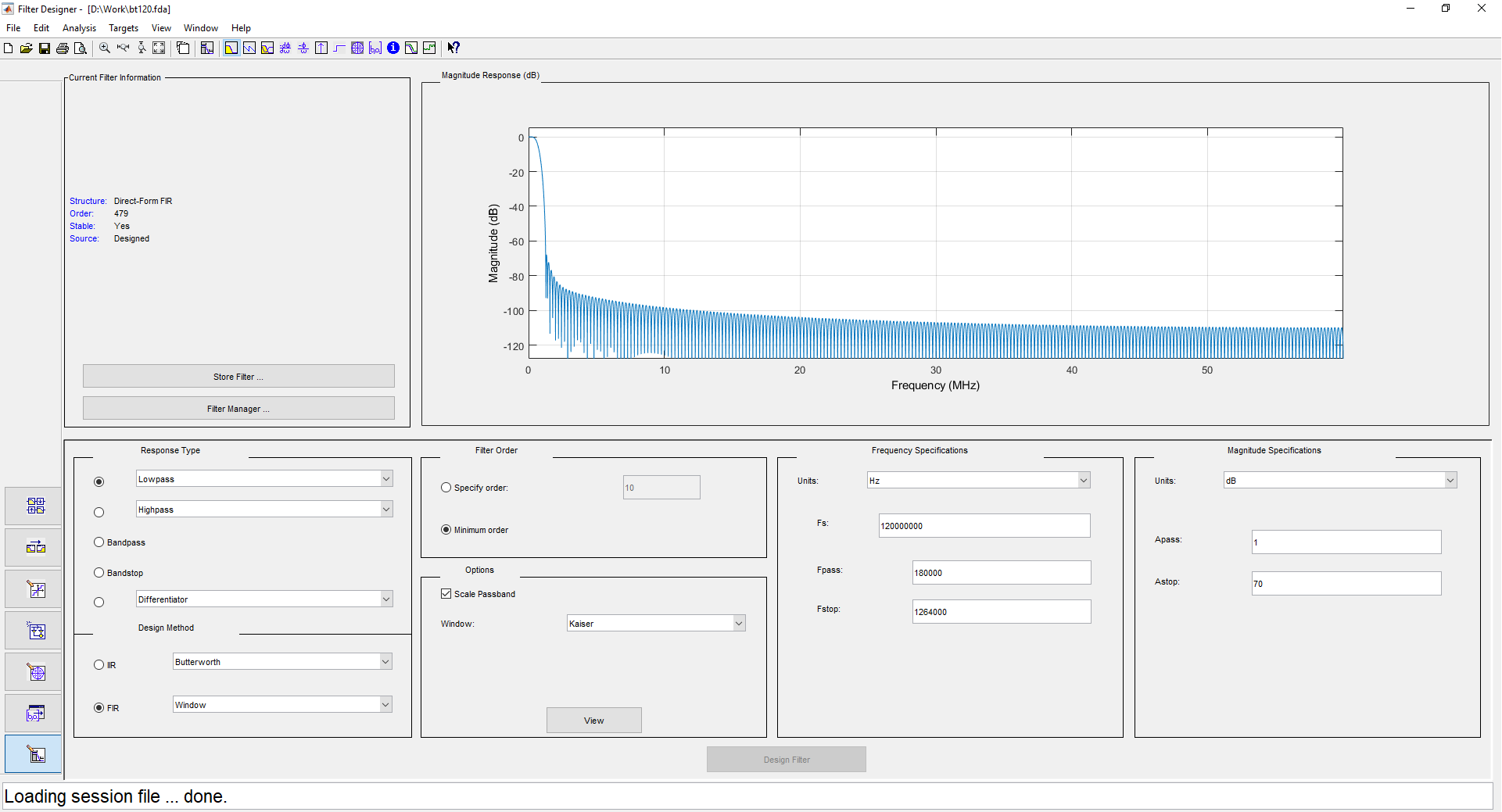
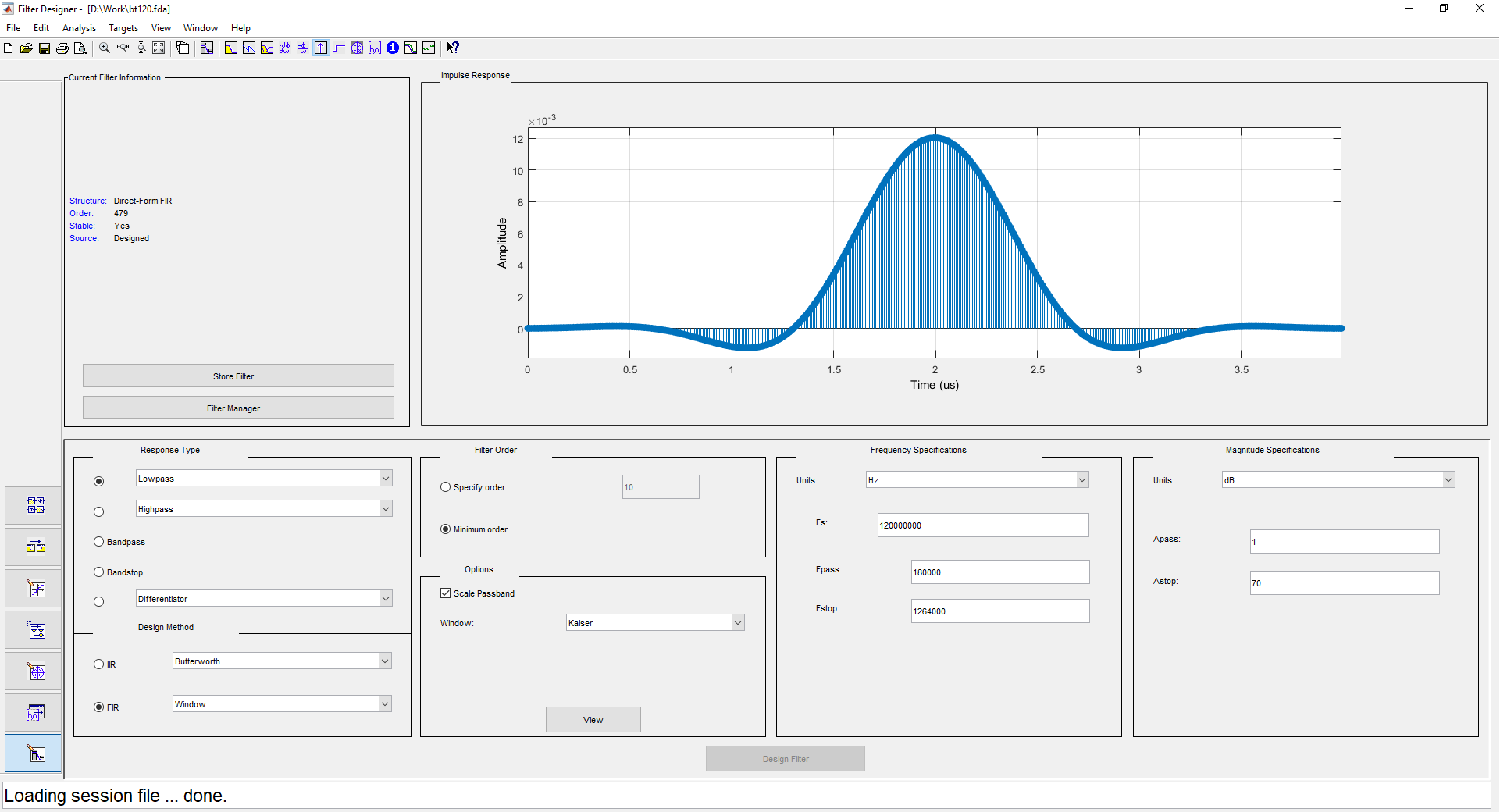
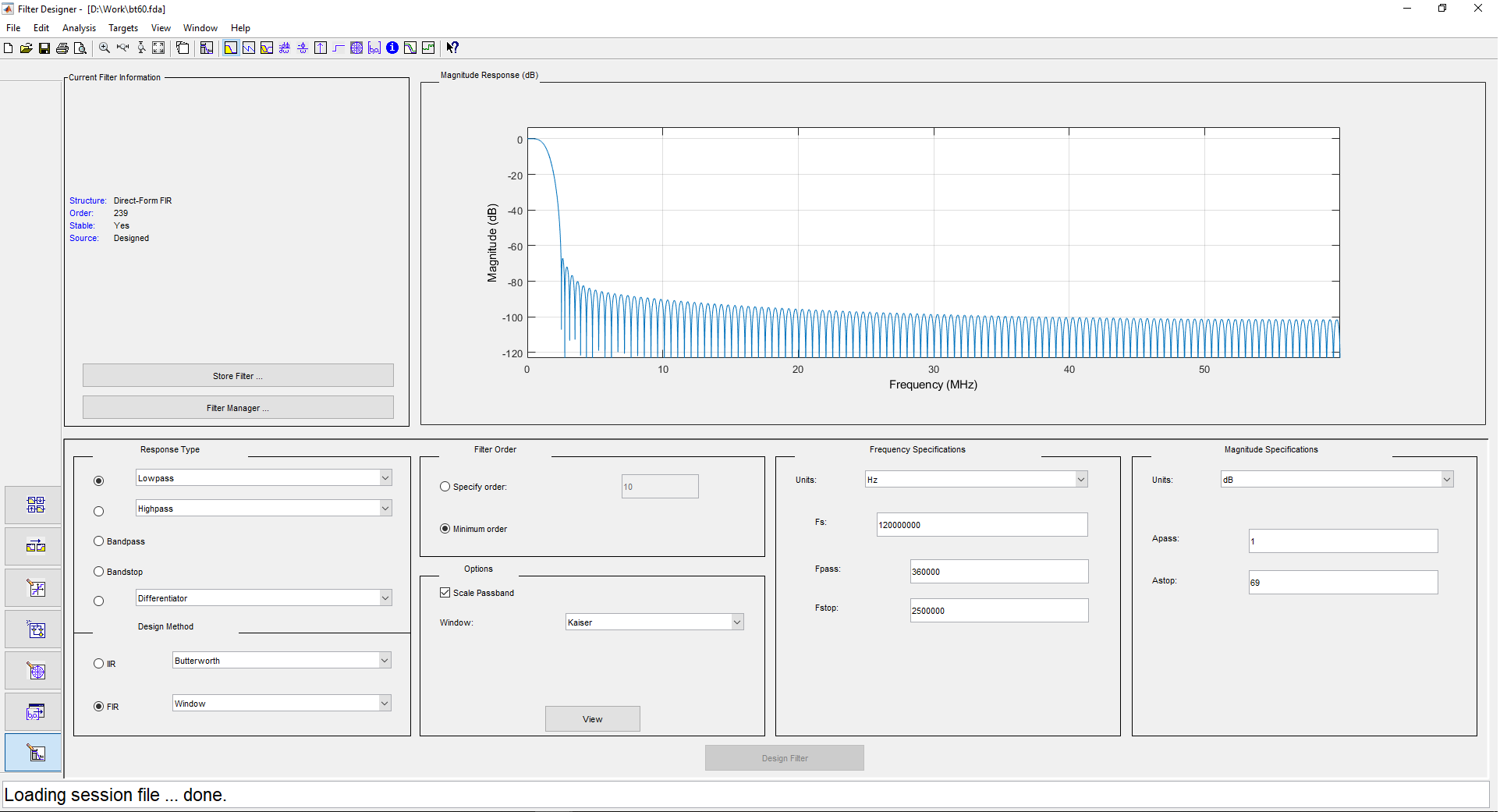
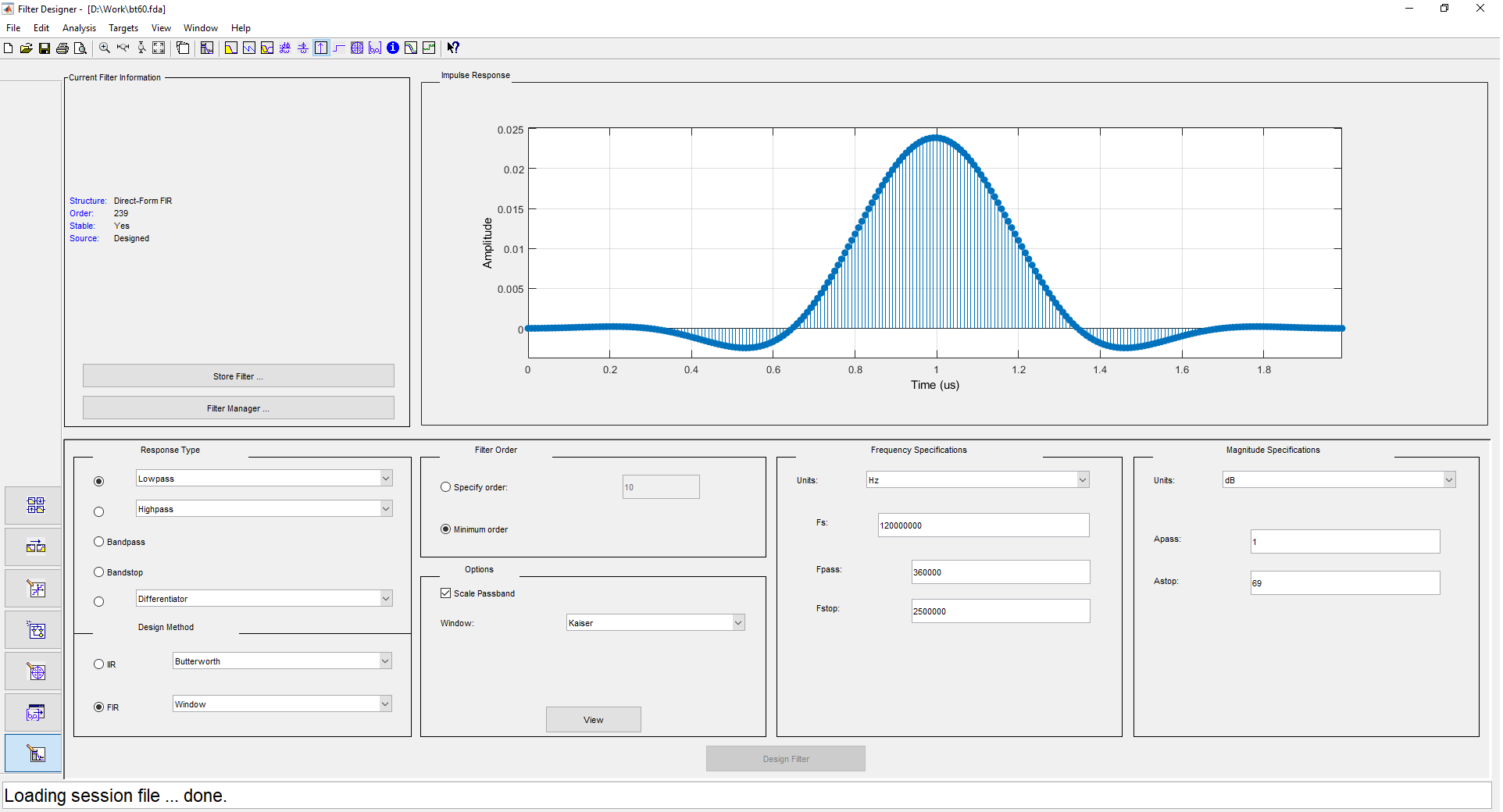
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
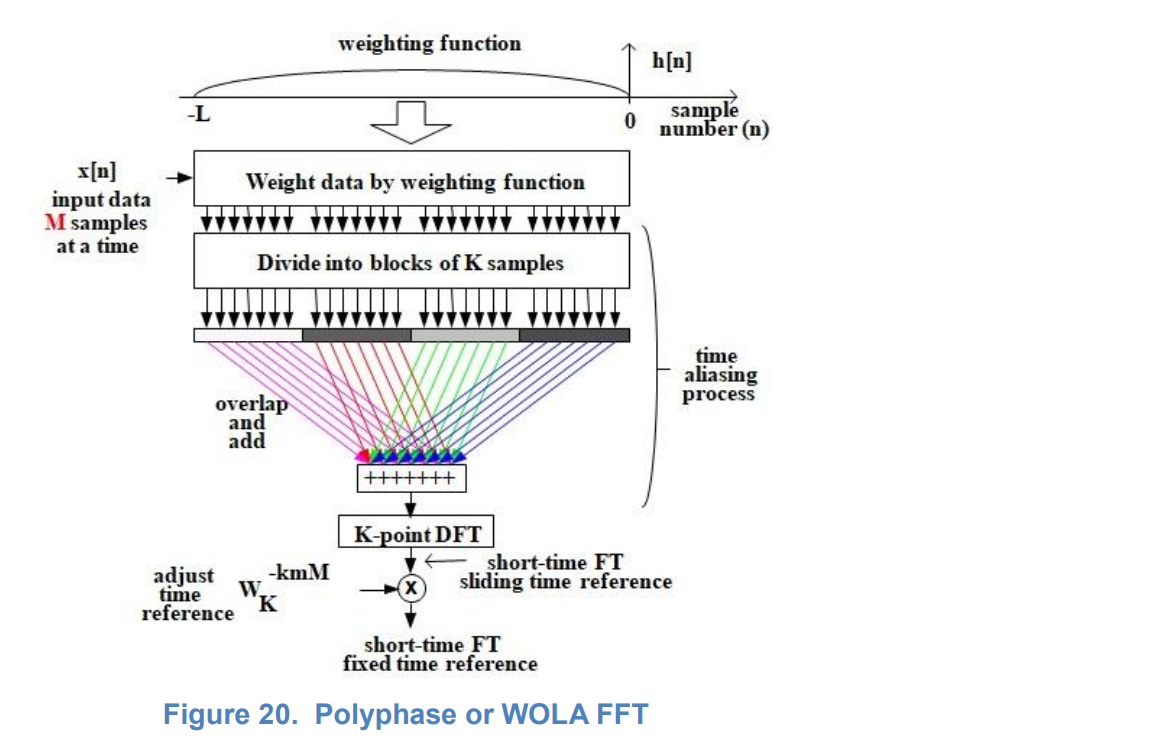
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
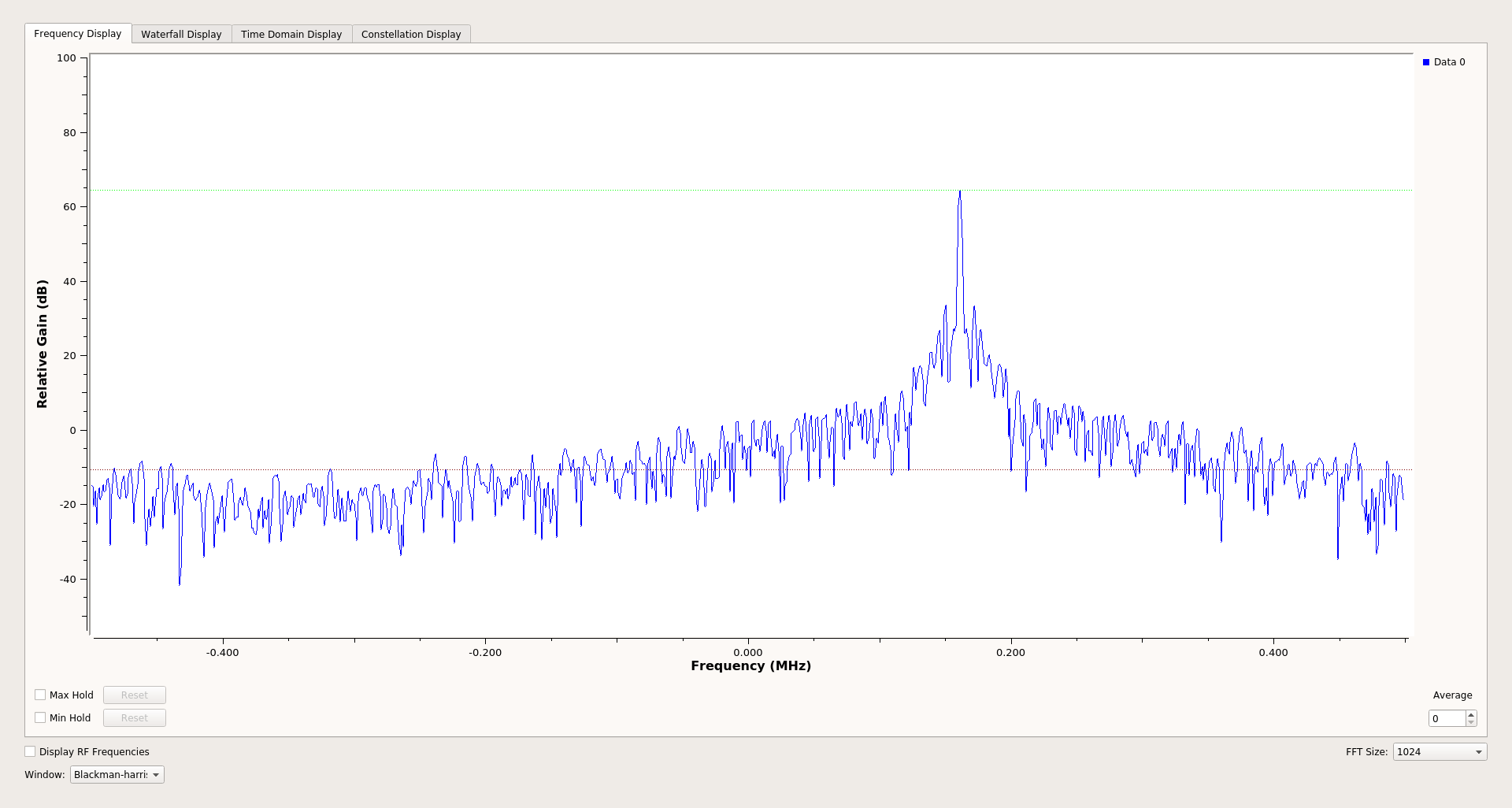
: XRTX , - .
gaudima, !