
The equipment arrived at the site several months before the peak of sales. The maintenance service, of course, knows how and what to set up on the servers in order to introduce them into the production environment. But we needed to automate this and eliminate the human factor. In addition, the servers were replaced prior to the migration of a set of SAP systems critical to the company.
The commissioning of new servers was tightly tied to a deadline. And to move it would jeopardize both the shipping of the billion gifts and the migration of systems. Even a team consisting of Santa Claus and Santa Claus could not change the date - the SAP system for warehouse management can be transferred only once a year. From December 31 to January 1, the retailer's huge warehouses, a total of 20 football fields, stop their work for 15 hours. And this is the only period of time for the system to move. We did not have the right to make a mistake with entering the servers.
Let me explain right away: my story reflects the tools and configuration management process that our team uses.
The configuration management complex consists of several levels. The key component is the CMS system. In industrial exploitation, the absence of one of the levels would inevitably lead to unpleasant miracles.
OS installation management
The first level is a system for managing the installation of operating systems on physical and virtual servers. It creates basic OS configurations, eliminating the human factor.
With the help of this system, we received standard and suitable for further automation instances of servers with OS. When they were cast, they received a minimal set of local users and public SSH keys, as well as a consistent OS configuration. We could be guaranteed to manage the servers through the CMS and were sure that there were no surprises “below”, at the OS level.
The maximum target for the installation management system is to automatically configure servers from the BIOS / Firmware level to the OS. Much depends on the hardware and configuration tasks. For dissimilar equipment, consider the REDFISH API... If all the hardware is from one vendor, then it is often more convenient to use ready-made management tools (for example, HP ILO Amplifier, DELL OpenManage, etc.).
To install the OS on physical servers, we used the well-known Cobbler, which defines a set of installation profiles coordinated with the maintenance service. When adding a new server to the infrastructure, the engineer would bind the server's MAC address to the required profile in Cobbler. At the first boot over the network, the server received a temporary address and a fresh OS. Then it was transferred to the target VLAN / IP addressing and continued to work there. Yes, changing VLANs takes time and requires coordination, but it provides additional protection against accidental server installation in a production environment.
We created virtual servers based on templates prepared using HashiCorp Packer. The reason was the same: to prevent possible human errors when installing the OS. But, unlike physical servers, Packer allows you not to use PXE, network boot and VLAN change. This made it easier and easier to create virtual servers.
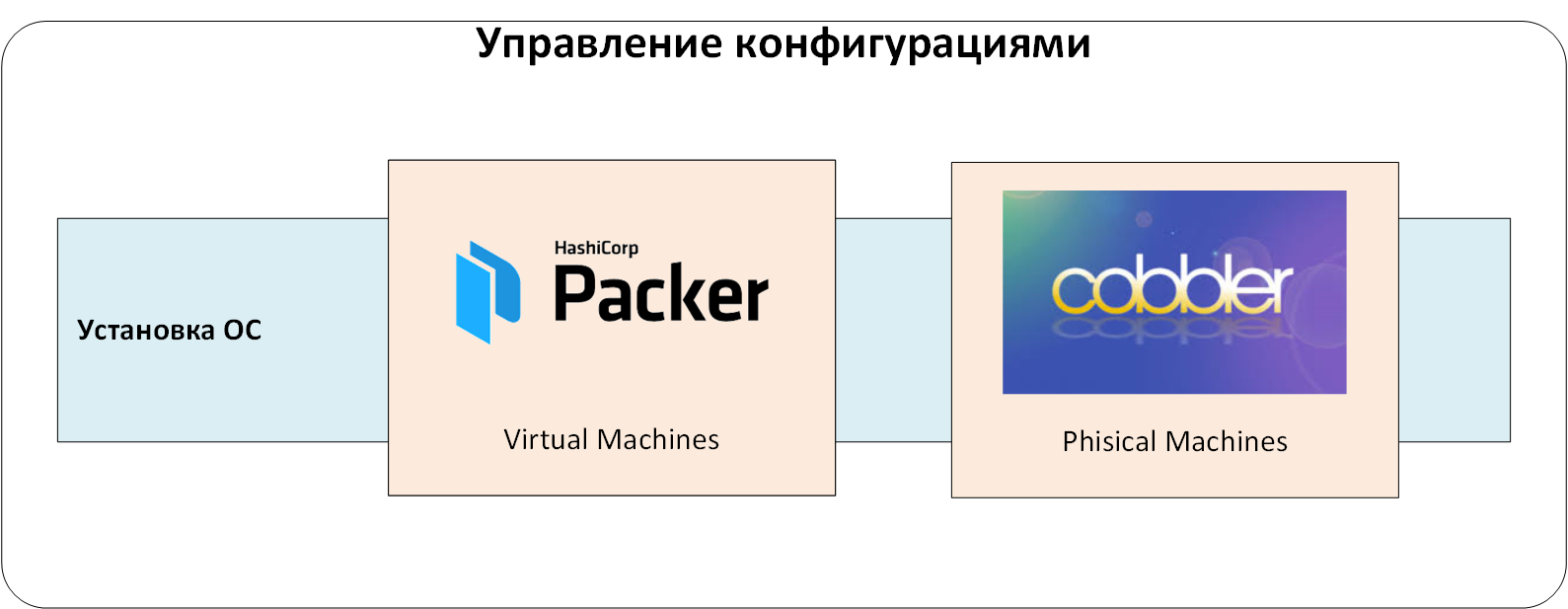
Figure: 1. Management of installation of operating systems.
Secret management
Any configuration management system contains data that should be hidden from ordinary users, but are needed to prepare the systems. These are passwords of local users and service accounts, certificate keys, various API Tokens, etc. Usually they are called "secrets".
If from the very beginning it is not determined where and how to store these secrets, then, depending on the severity of the IS requirements, the following storage methods are likely:
- right in the configuration management code or in files in the repository;
- in specialized configuration management tools (for example, Ansible Vault);
- in CI / CD systems (Jenkins / TeamCity / GitLab /, etc.) or in configuration management systems (Ansible Tower / Ansible AWX);
- also secrets can be transferred to "manual control". For example, they are laid out in an agreed place, and then they are used by configuration management systems;
- various combinations of the above.
Each method has its own drawbacks. The main one is the absence of policies for access to secrets: it is impossible or difficult to determine who can use certain secrets. Another disadvantage is the lack of access audit and a full life cycle. How to quickly replace, for example, a public key, which is written in the code and in a number of related systems?
We used the centralized HashiCorp Vault. This allowed us to:
- keep secrets safe. They are encrypted, and even if someone gains access to the Vault database (for example, by restoring it from a backup), they will not be able to read the secrets stored there;
- . «» ;
- . Vault;
- « » . , , . .
- , ;
- , , ..
Now let's move on to the central authentication and authorization system. You could do without it, but administering users in many related systems is too trivial. We have configured authentication and authorization through the LDAP service. Otherwise, the same Vault would have to continuously issue and keep records of authentication tokens for users. And deleting and adding users would turn into a quest "Have I created / deleted this UZ everywhere?"
We add one more level to our system: management of secrets and central authentication / authorization:
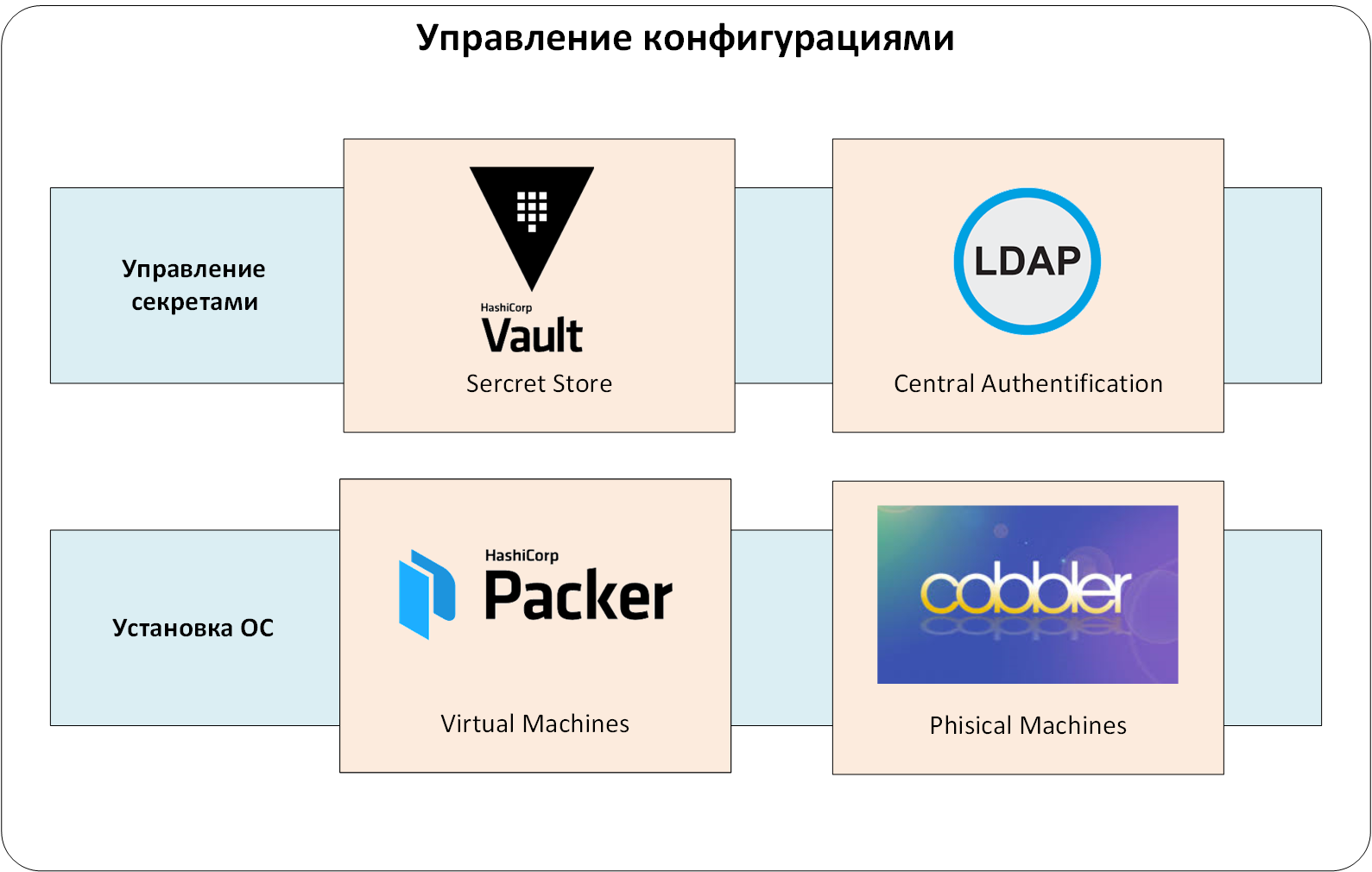
Figure: 2. Management of secrets.
Configuration management
We got to the core - to the CMS system. In our case, this is a bunch of Ansible and Red Hat Ansible AWX.
Chef, Puppet, SaltStack can act instead of Ansible. We chose Ansible for several reasons.
- First, it is versatility. The set of ready-made modules for control is impressive . And if you don't have enough, you can search on GitHub and Galaxy.
- Secondly, there is no need to install and maintain agents on controlled equipment, to prove that they do not interfere with the load, and to confirm the absence of "bookmarks".
- Third, Ansible has a low barrier to entry. A competent engineer will write a working playbook literally on the first day of working with the product.
But Ansible alone was not enough for us in an industrial environment. Otherwise, there would be many problems with restricting access and auditing the actions of administrators. How to differentiate access? After all, each division needed to manage (read - run the Ansible playbook) "its" set of servers. How can I only allow specific employees to run specific Ansible playbooks? Or how to track who launched a playbook without running many local KMs on Ansible servers and hardware?
Red Hat Ansible Tower , or its open-source upstream project Ansible AWX, solves the lion's share of such issues . Therefore, we preferred it for the customer.
And one more touch to the portrait of our CMS system. Ansible playbook must be stored in code repository management systems. We have this GitLab CE .
So, the configurations themselves are managed by the bundle from Ansible / Ansible AWX / GitLab (see Fig. 3). Of course, AWX / GitLab is integrated with the unified authentication system, and the Ansible playbook is integrated with the HashiCorp Vault. Configurations enter the production environment only through Ansible AWX, in which all the "rules of the game" are set: who and what can configure, where to get the configuration management code for the CMS, etc.
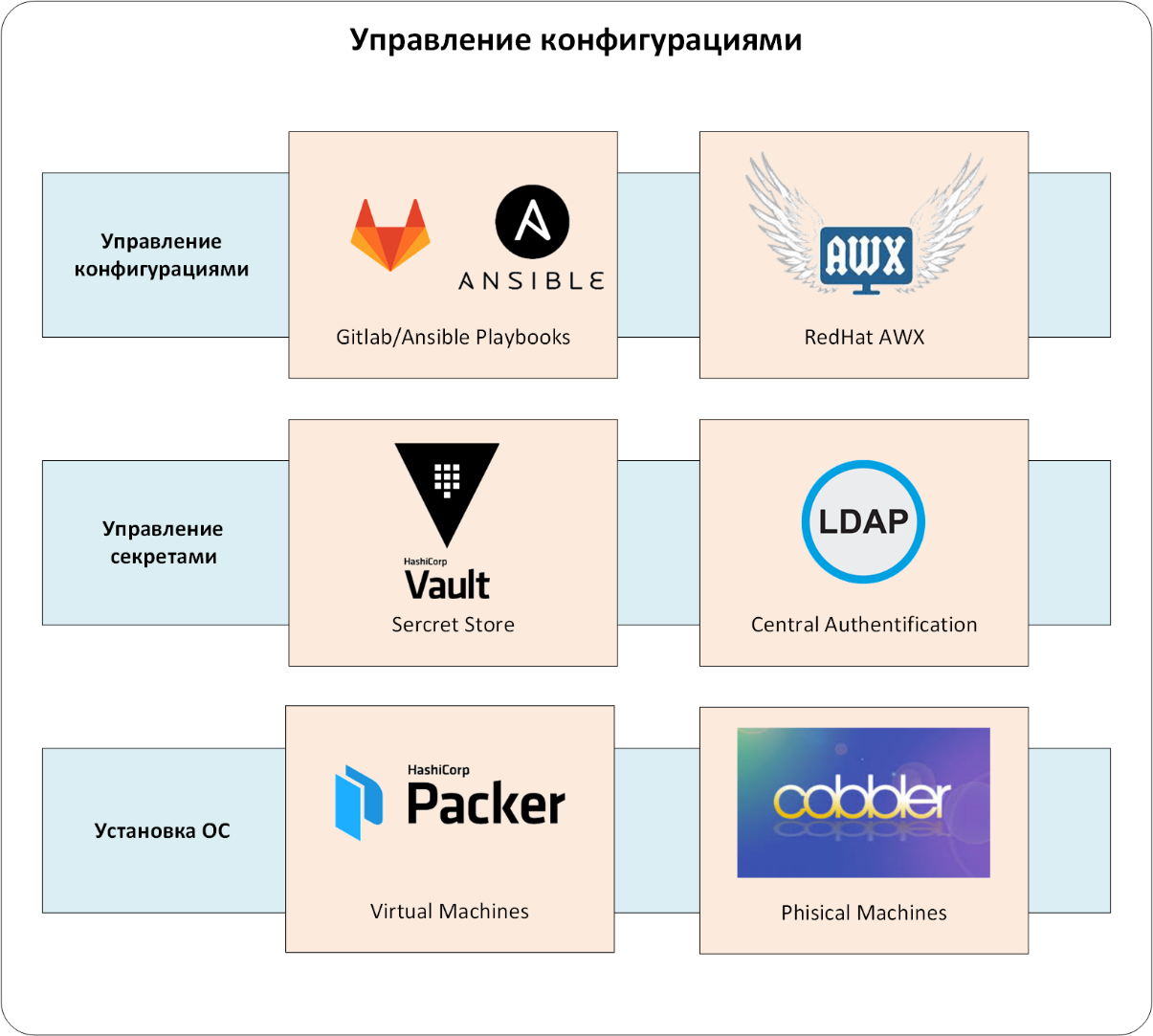
Figure: 3. Configuration management.
Test management
Our configuration is presented as a code. Therefore, we are forced to play by the same rules as software developers. We needed to organize the development processes, continuous testing, delivery and application of configuration code to production servers.
If this was not done right away, then the written roles for configuration would either cease to be maintained and modified, or would stop running in production. The cure for this pain is known, and it paid off in this project:
- each role is covered by unit tests;
- tests are run automatically whenever there is any change in the configuration management code;
- changes in the configuration management code enter the production environment only after successfully passing all tests and code review.
Code development and configuration management are calmer and more predictable. To organize continuous testing, we used the GitLab CI / CD toolkit, and we took Ansible Molecule as a framework for organizing tests .
For any change in the configuration management code, GitLab CI / CD calls Molecule:
- it checks the syntax of the code,
- lifts the Docker container,
- applies the modified code to the created container,
- checks the role for idempotency and runs tests for this code (the granularity here is at the ansible role level, see Fig. 4).
We delivered configurations to the production environment using Ansible AWX. The operational engineers applied configuration changes through predefined templates. AWX independently "requested" the latest version of the code from the GitLab master branch every time it was used. This way we excluded the use of untested or outdated code in the production environment. Naturally, the code got into the master branch only after testing, review and approval.
Figure: 4. Automatic testing of roles in GitLab CI / CD.
There is also a problem related to the operation of production systems. In real life, it is very difficult to make configuration changes through CMS code alone. Abnormal situations arise when an engineer must change the configuration "here and now" without waiting for code editing, testing, approval, etc.
As a result, due to manual changes, discrepancies appear in the configuration on the same type of equipment (for example, on the nodes of the HA-cluster different configuration of sysctl settings). Or the actual configuration on the hardware is different from the one set in the CMS code.
Therefore, in addition to continuous testing, we check production environments for configuration discrepancies. We chose the simplest option: running the CMS configuration code in the "dry run" mode, that is, without applying changes, but with notification of all discrepancies between the planned and real configuration. We have implemented this by periodically running all Ansible playbooks with the "--check" option on production servers. Ansible AWX, as always, is responsible for the launch and relevance of the playbook (see Fig. 5):
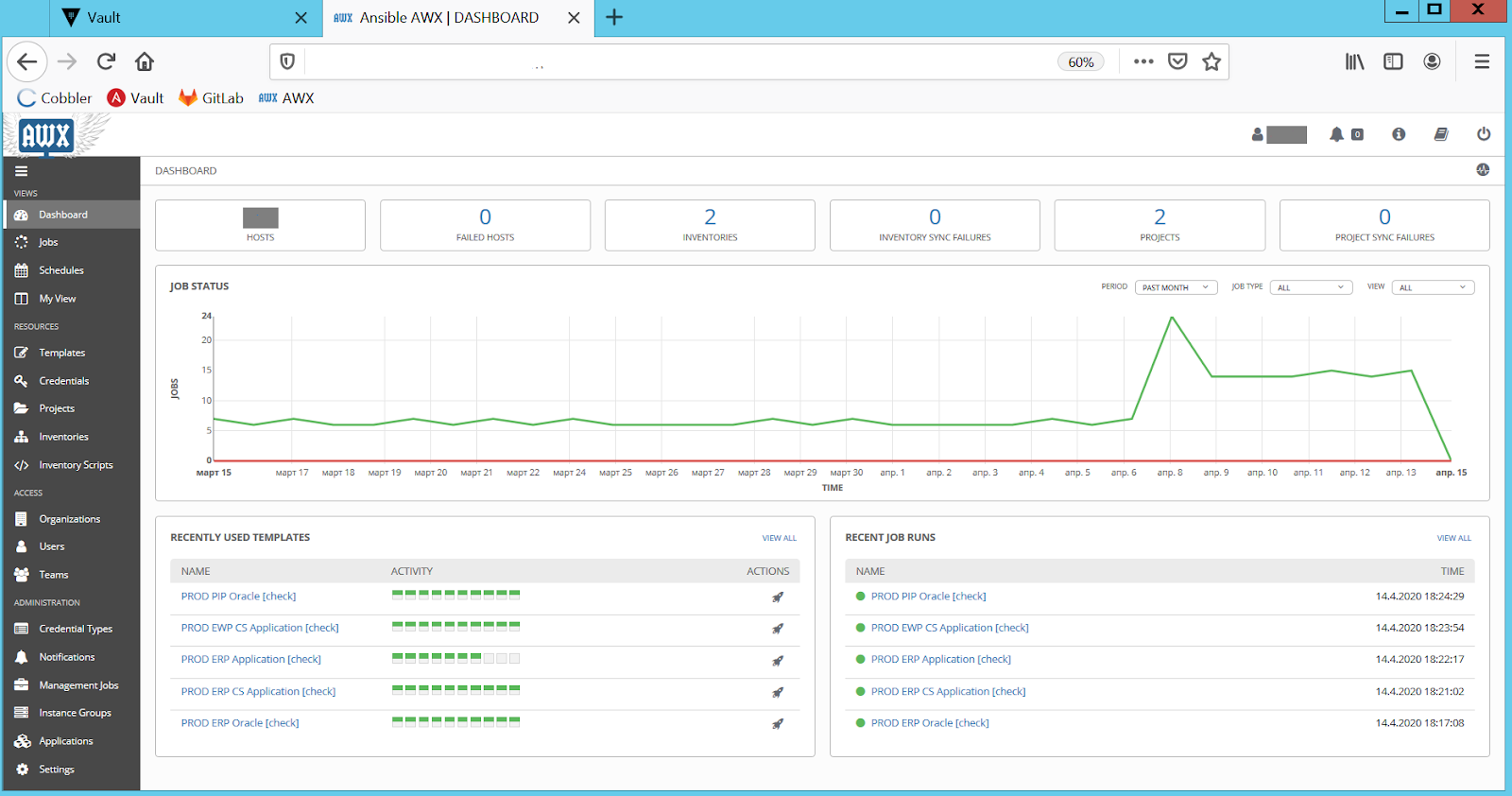
Figure: 5. Checks for configuration discrepancies in Ansible AWX.
After checks, AWX sends a discrepancy report to administrators. They study the problem configuration and then fix it through the adjusted playbook. This way we maintain the configuration in the production environment and the CMS is always up-to-date and synchronized. This eliminates the nasty "miracles" when CMS code is applied on "production" servers.
We now have an important testing layer consisting of Ansible AWX / GitLab / Molecule (Figure 6).
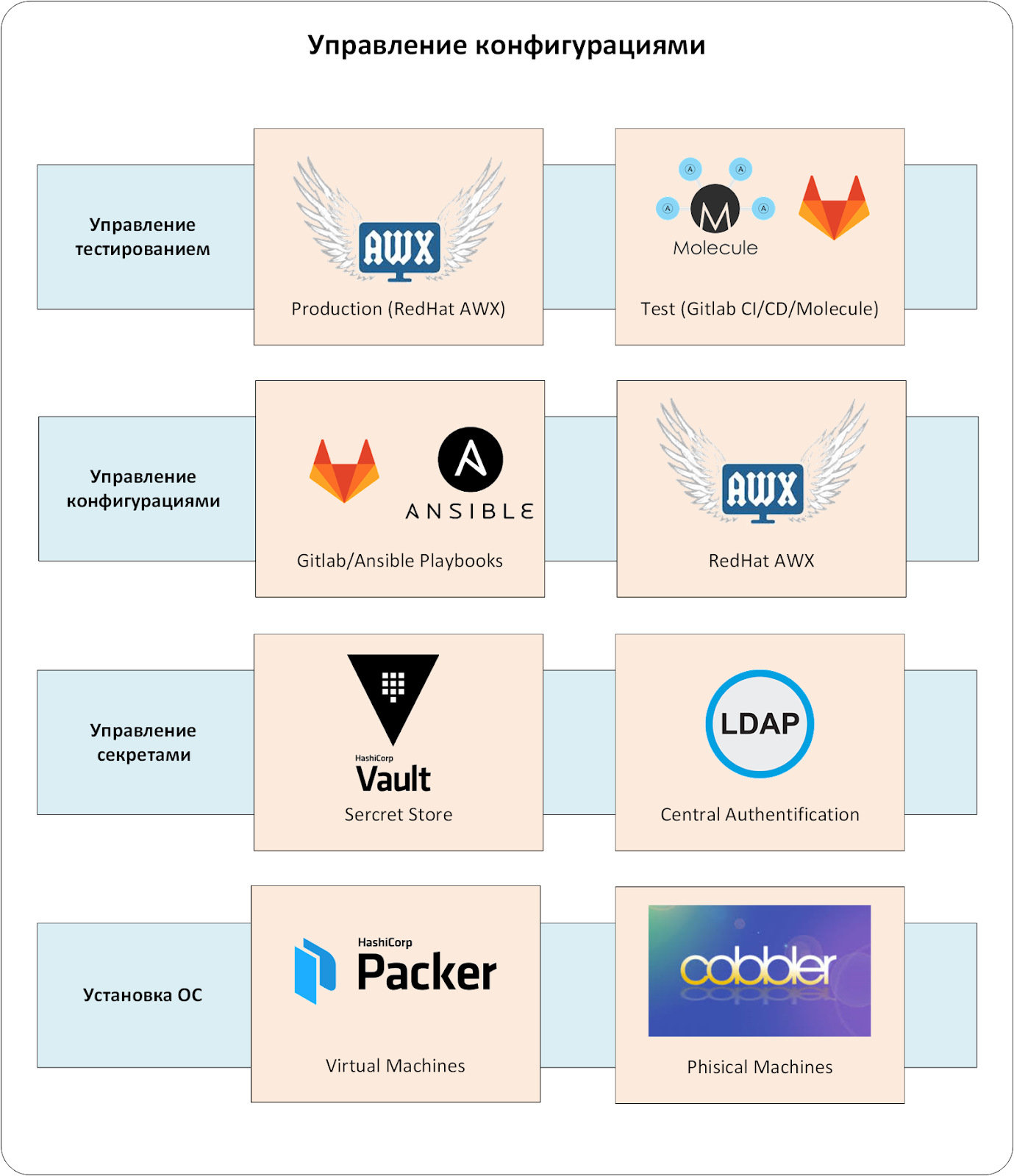
Figure: 6. Test management.
Hard? I do not argue. But such a configuration management complex has become a comprehensive answer to many questions related to the automation of server configuration. Now the retailer always has a strictly defined configuration for standard servers. CMS, unlike an engineer, will not forget to add the necessary settings, create users and perform tens or hundreds of required settings.
There are no "secret knowledge" in the settings of servers and environments today. All the necessary features are reflected in the playbook. No more creativity and vague instructions: “ put it like a regular Oracle, but there you need to register a couple of sysctl settings, and add users with the required UID. Ask the guys from the operation, they know . "
The ability to detect configuration discrepancies and correct them in advance gives peace of mind. Without a CMS, this usually looks different. Problems accumulate until one day they are "shot" in production. Then debriefing is carried out, configurations are checked and corrected. And the cycle repeats again
And of course, we have accelerated the launch of servers in production from a few days to hours.
Well, on New Year's Eve itself, when children happily unwrapped gifts and adults made wishes while the chimes chimed, our engineers migrated the SAP system to new servers. Even Santa Claus will say that the best miracles are well prepared ones.
PS Our team is often faced with the fact that customers want to solve the problem of configuration management as easily as possible. Ideally, as if by magic - with one tool. But in life, everything is more complicated (yes, again, silver bullets were not delivered): you have to create a whole process using tools convenient for the customer's team.
Author: Sergey Artemov, architect of DevOps-solutions department of Jet Infosystems