 Many people know that ABBYY is engaged in processing and extracting data from various documents. But our products have other interesting possibilities as well. In particular, using the ABBYY Intelligent Search solution, you can quickly and conveniently search for meaningful information in electronic documents from corporate systems. This is already being used by large Russian companies, for example, NPO Energomash , a manufacturer of rocket engines .
Many people know that ABBYY is engaged in processing and extracting data from various documents. But our products have other interesting possibilities as well. In particular, using the ABBYY Intelligent Search solution, you can quickly and conveniently search for meaningful information in electronic documents from corporate systems. This is already being used by large Russian companies, for example, NPO Energomash , a manufacturer of rocket engines .
Long-term practice shows that the time it takes to bring space engines to the market from the start of work is 5 to 7 years. At the same time, in order to maintain the leading position, it is necessary to reduce the development and production time to 3 - 4 years. In addition, the intensification of competition has led to the need to significantly reduce the cost of manufactured engines by 30-50%.
These indicators cannot be achieved without the introduction of modern digital technologies. The most advanced companies use innovative approaches not only at all stages of production, but also at all stages of the life cycle of their products. The more companies go digital, the more acute the question becomes: how to use big data with maximum benefit for themselves?
Over 90 years of work NPO Energomash has accumulated a century-old volume of documents (both paper and electronic) with valuable information about the developments of testers and designers. Most of the documents are already stored in the company's information systems (IS). According to IDC research, on average, employees of large organizations use 5-6 internal ISs. On average, about 36% of the time is spent searching for information - in a large company, this is thousands of working hours per day.
Today we will tell you how we helped NPO Energomash create a corporate intelligent information retrieval system (KIIPS) based on ABBYY Intelligent Search - as convenient and fast as popular search engines.
What does Energomash do and what does Gagarin have to do with it
 Since the day of its foundation, on May 15, 1929, Energomash has manufactured more than 12 thousand engines for launch vehicles not only in Russia, but also abroad. These "motors" were used to launch the first artificial Earth satellite, went into space "Vostok-1" with the first cosmonaut Yuri Gagarin on board, flew the spaceplane "Buran" and the American launch vehicles Atlas and Antares are still being launched. For example, March 26, 2020 rocket Atlas V, equipped with Russian engines, brought into orbit a US military strategic satellite communications system. In the first half of 2020, engines developed by Energomash successfully worked in 11 space launches, which is 24.4% of all launches in the world.
Since the day of its foundation, on May 15, 1929, Energomash has manufactured more than 12 thousand engines for launch vehicles not only in Russia, but also abroad. These "motors" were used to launch the first artificial Earth satellite, went into space "Vostok-1" with the first cosmonaut Yuri Gagarin on board, flew the spaceplane "Buran" and the American launch vehicles Atlas and Antares are still being launched. For example, March 26, 2020 rocket Atlas V, equipped with Russian engines, brought into orbit a US military strategic satellite communications system. In the first half of 2020, engines developed by Energomash successfully worked in 11 space launches, which is 24.4% of all launches in the world.
Today Energomash is a part of the state corporation Roscosmos and heads the integrated structure of rocket propulsion, which includes the leading enterprises in this industry.
In recent years, the company has been actively introducing large-scale IT solutions that make extensive use of data analysis, machine learning and all the capabilities of natural language processing technologies. The company has set a strategic goal of fully digital manufacturing by 2021.
For example, within the framework of the project " Digital design and production technologies»One of the key tasks was the implementation of a PLM system (automated product lifecycle management system). Its goal is to ensure the creation of electronic design documentation (ECD) and modeling on its basis the operation of the engine and other work processes in the technological and production departments of NPO Energomash and the readiness for the exchange of ECD between the industry enterprises.
Why was it necessary to search the universe of Energomash
To achieve the strategic goal of creating digital production, the company is carrying out a whole range of projects based on work with large amounts of data. One of them is a project to create a corporate intelligent information retrieval system.
The goal of the project is to preserve, increase and put into the service of digital production the knowledge and competence of the enterprise, accumulated over decades of work.
Within the framework of the project, two tasks were solved:
1). Make it easier for designers and engineers to find useful information in documents from past years.
Many developments were created in the USSR, but not all were implemented, because investments were not always allocated for them or the level of technology development did not allow completing the plan. In our time, such developments can find a second life. To do this, the company asks experienced designers to share their research work and drawings, which are still on paper. This will help to digitize valuable data, preserve it for many years and transfer knowledge to the younger generation of scientists and engineers.
Of course, the search for documents in electronic systems existed in Energomash before, but it was not easy for employees to find the information they needed for work.
Below the spoiler, we will tell you in more detail how this process was arranged earlier.
7 . , - , , - – , , . , , :
, , , , . , , : . , .
:
. « » () , . , « », , , , , , . , , . - , «».
, , , , , .
- ;
- ;
- , , .
, , , , . , , : . , .
:
- . , , ;
- , , .
. « » () , . , « », , , , , , . , , . - , «».
, , , , , .
2). Simplify and speed up the search for data for service departments: accounting departments, lawyers and other specialists who compose, edit, coordinate documents in accounting systems and exchange information.
The company wanted employees to be able to collect and analyze the financial, manufacturing, and other relevant information they need to do their jobs from disparate corporate systems by simply entering queries in one search string. It was necessary to create a single point of access to the data stored in the company's information systems, with the provision of delimited access to information, depending on the user's authority in each system.
Why is it important? In 7 years, more than half of all data in the world will be stored in corporate systems, it follows fromSeagate and IDC Data age report . To always have the necessary information at hand, you need to find it quickly. Thus, according to a study by IDC and ABBYY "The Market for Artificial Intelligence in Russia", representatives of IT (48%) and business units (33%) see great opportunities in using AI for corporate search and document classification in the next two years.
To cope with these tasks, the company needed a convenient end-to-end search across numerous IPs. Energomash considered several search engines, but in the end decided to try ABBYY Intelligent Search. The choice was influenced, firstly, by the availability of natural language processing technologies that allow finding documents that are relevant to search queries by meaning, and not just by keywords. Secondly, the ability to differentiate user access rights to search results. We will tell you more about this a little later, and now - about how we started.
The first "exit" to the search
Energomash decided to check the work of intelligent search on 3 thousand documents from the information database (IDB) of research, design and calculation works.
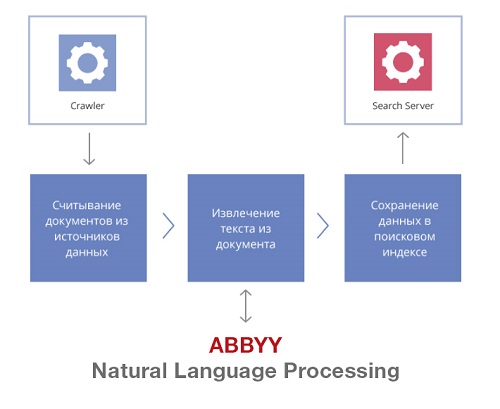
For this, ABBYY has developed a prototype of a connector to the IDB, which linked ABBYY Intelligent Search to the document database. A connector is a java program that is used to load documents into an index. How it works?
1). First we build a full-text search index
A full-text index is, roughly speaking, a list of all words in a document and its metadata (document number, title, creation date). The full-text index is created quite quickly and allows you to search for the information you need by keywords - those that occur in the text.


To build a full-text index, you need a connector. It connects the search solution to a specific information system and collects (“indexes”) the characteristics of each document, for example:
- the name of the IP where the file is stored,
- date of the last modification of the document,
- the version of the document in the source,
- document format,
- language codes in which the document is drawn up,
- path to the document in the IS,
- date of the last indexing of the document
- and etc.
These characteristics in the future will help not only to speed up the search for a document, but also to simplify the logic of working with them for the connector. In particular, the connector analyzes different versions of the same document in order to put only the last one in the index. The connector also receives information about documents that have been removed from the source.
A crawler (search robot) built into ABBYY Intelligent Search helps to create a search index. At regular intervals, he polls the connectors, checks whether new documents have appeared in the IS, which documents have been deleted, how the access rights to documents have changed. Accordingly, the index is updated at a given frequency.
Not only text documents are indexed, but also graphic files. For example, it can be scanned copies of drawings in JPEG or PDF without a text layer. When working with images, the search solution first automatically recognizes the text and adds it to the search index.
In addition, the system can handle ZIP, RAR, TAR archive files - provided that they are not password protected. The archives are unpacked, images from them are recognized, the text is indexed.

The search index contains an arbitrary set of fields, which can also be used to filter search results (document author, creation date, product number, etc.).
2). Then we apply natural language processing technologies
In the background, the search index is enriched with semantic information . To do this, we used the semantic-linguistic ontology we already have - in other words, descriptions of objects and phenomena of the real world. We have already talked about how we created this model on Habré here and here .
Using machine learning and natural language processing technologies, each document analyzes the syntax of sentences, morphology and semantic meanings of literally every word in the text. This information supplements the search index and makes it possible to search not by keywords, but by synonyms, hyponymsand other constructs that convey the same meaning but in different expressions. Thus, the search engine more accurately searches for information in corporate sources.


This is very convenient if a peer of ours has formulated a search query in his own words, and wants to find documents 40 years ago, where, perhaps, the subject he needed was called by other terms. For example, for the query "frame defect", the system will select all possible semantic expressions associated with this term. The results may include " deflection ", " hole ", " kink " or "the fact of violation of design technological documentation ."
Here's another example:

The search results for “ thrust fluctuations ” will also display texts that contain the phrase “ thrust variance ”.
Natural language processing technologies also help the search engine automatically correct spelling errors in the text of the query. For example, the system will understand that there are errors in the word "bearing" and will immediately search for documents that mention "bearing".
Results of the first launch
To evaluate the work of an intelligent search engine, Energomash specialists completed about 30 queries for IDB documents using the search engine built into the IDB and using ABBYY Intelligent Search . Then they compared the search results: which documents were found by both systems, which phrases were highlighted in snippets. As a result, the search built into the IDB did not return results for some queries, since it is able to detect only key words, not related words. ABBYY Intelligent Search has returned documents relevant to all queries.
As for the speed, while meeting the requirements for the hardware platformsearch response did not exceed a fraction of a second, like popular search engines. The most complex queries took up to a maximum of 3 seconds.
After a successful pilot project, Energomash decided to use the ABBYY Intelligent Search solution at the heart of the Corporate Intelligent Information Search System.
Let's go further
Energomash connected 7 corporate sources to the search: LanDocs electronic document management system, file storage, IDB, TeamCenter product lifecycle support system, Galaktika ERP and AMM resource management system, and project management information system. A separate index has been created for each information system. This makes the search engine flexible in administration and makes it possible to rebuild the index for each system separately, setting new conditions. Access to the Corporate Search System is organized through the company's internal portal on the main page. The project was implemented jointly with a partner, LANIT , the largest Russian diversified group of IT companies.
The main modules of the corporate search system:
- main page of search queries and search results;
- admin panel (setting up indexes, filters, metadata for each information system);
- statistics of the number of documents (displays the number of documents in the index for each information system for the period).
The corporate search system has been put into commercial operation since July 1, 2020. At the time of launch, 500 thousand documents were indexed. It is expected that by the end of the year, with the active use of the system and the connection of new information sources, the number of documents in the index will reach more than 1 million.
How to ensure safety
Like any large business, NPO Energomash has documents that are not intended for access by all employees. The key security requirement when launching the project was to provide access to documents in accordance with the role model of each information system. For this was done:
1). Local storage of information
The ABBYY search solution is deployed on a separate server in the internal circuit of NPO Energomash. All search indexes and their backups in case of loss and their settings are stored there.
2). Role model of the information system
For security, the differentiation of user access rights to search results for each information system is organized. All corporate systems connected to ABBYY Intelligent Search support domain authorization. The user logs into the system under a domain account, executes a request, and sees the document in the search results, taking into account the document preview settings for each information system and the access level made directly in the corporate search system itself, and taking into account access to the document in the source information system itself ... If the user has rights to work with the document in the source system, then the transition to the original document can be made directly from the corporate search system by clicking on the link.
Plans for the future
According to Energomash's idea, intelligent information retrieval will help to simplify and speed up business processes at the enterprise, for example, indirectly accelerate the entry of new products to the market, improve their quality and reduce costs. Ideas and projects that have been preserved in old documents can be used in modern developments of the enterprise. For example, create something completely new on the basis of developments and stay ahead of competitors in the global market.
Let us also mention our plans for the future:
- In the future, it is planned to connect information sources of other enterprises that are part of the Energomash structure to the corporate search system. In this case, the search index can expand to 2 million documents.
- , , – . , - . , , : , - , . , , . , , .
- Energomash also plans to explore the possibility of building complex analytical reports using the search function.
In your opinion, what other tasks can you solve using corporate search?