In my talk at Y.Subbotnik Pro, I remembered what and how we finished in the assembly and architecture of the "standard modern project" and what results we got.
- For the last year and a half I have been working in the Serp architecture team. We develop runtime and assembly of new code in React and TypeScript there.
Let's talk about our common pain that this talk will address. When you want to make a small project in React, you just need to use a standard set of tools called three letters - CRA. This includes build scripts, scripts for running tests, setting up a dev environment, and everything has already been done for production. Everything is done very simply through NPM scripts, and everyone probably knows about it who has experience with React.
But suppose the project gets big, it has a lot of code, a lot of developers, production features appear, such as translations, about which Create React App knows nothing. Or you have some kind of complex CI / CD pipeline. Then the thoughts begin to make an eject to use Create React App as a basis and customize it for your own project. But it is absolutely not clear what awaits there, behind this eject. Because when you do an eject, it says that this is a very dangerous operation, it will not be possible to return it back and so on, very scary. Those who pressed eject know that a lot of configs are thrown out there, which you need to understand. In general, there are a lot of risks, and it is not clear what to do.
I'll tell you how it was with us. First, about our project. Our front-end project is the Serp, Search Engine Results Pages, Yandex search results pages that everyone has seen. Since 2018 we are not moving React and TypeScript. About 12 megabytes of code have already been written on Serpa last year. There are a few styles and a lot of TS and SCSS code. How many at the beginning, in 2018, there was, I did not write, there is very little, there was a very sharp jump.
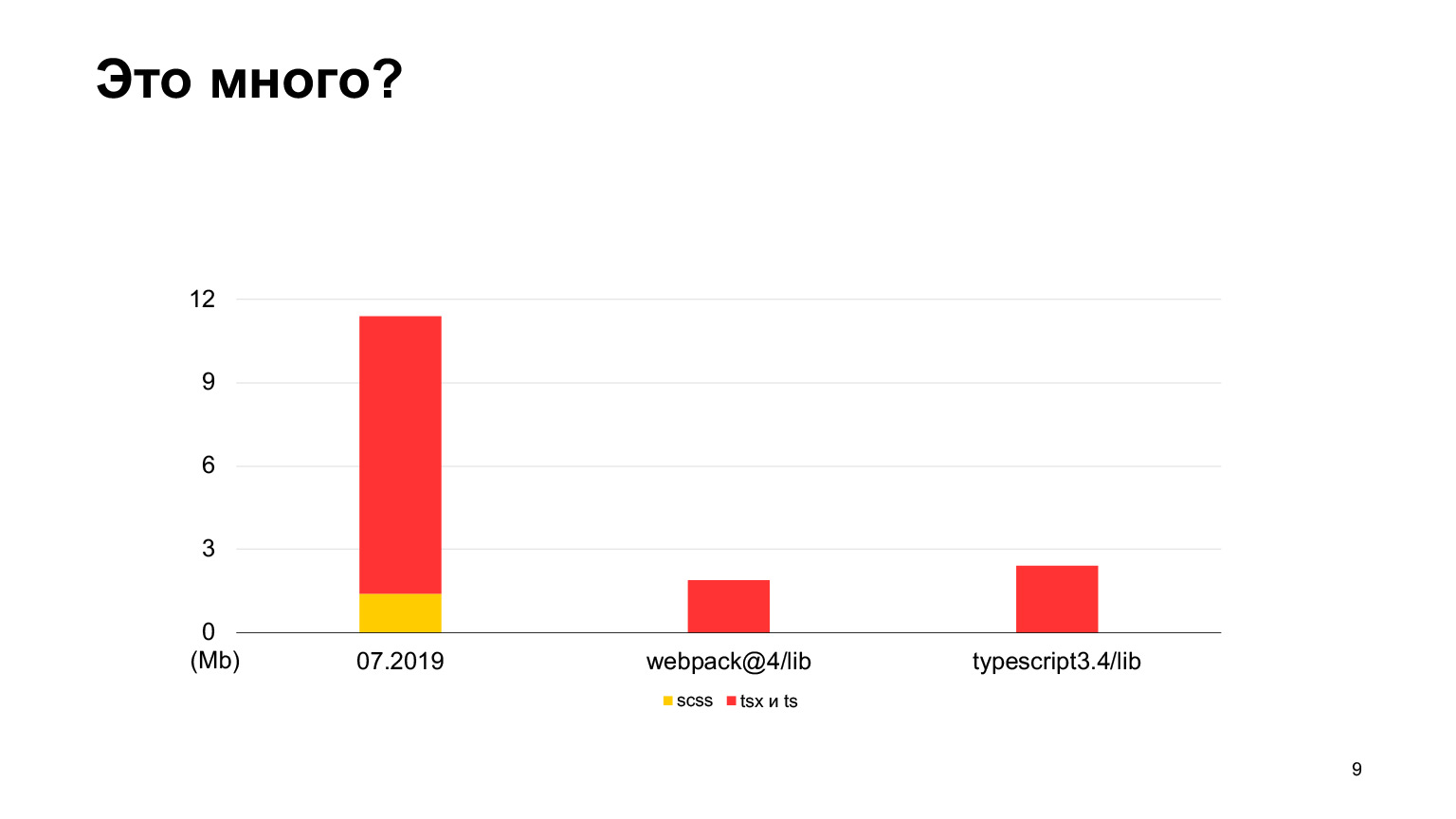
Let's see if this is a lot of code or not. Compared to the webpack-4 source code, there is much less code in webpack-4. Even the TypeScript repository has less code.
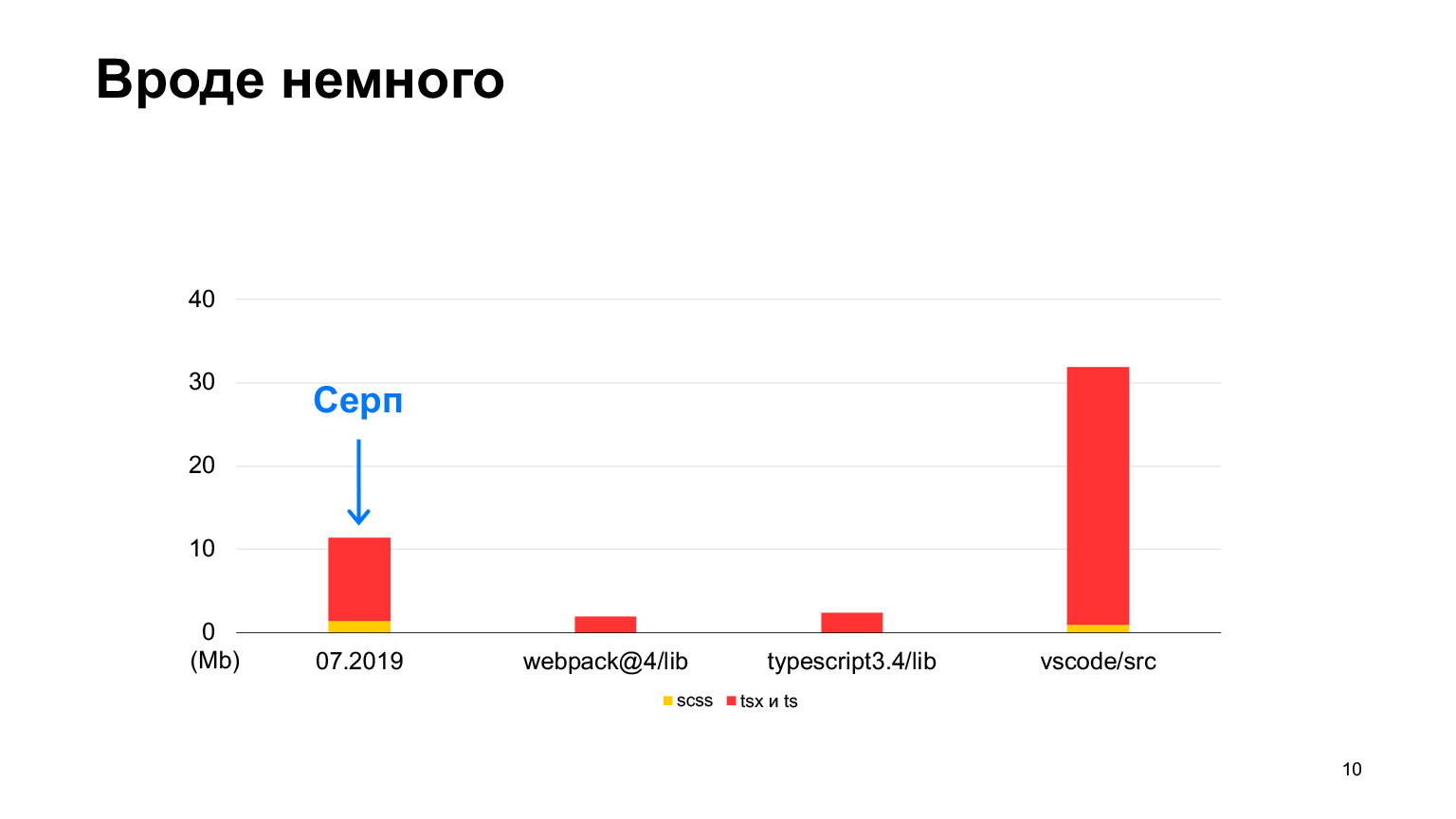
But vs-code has more code, a good project with as much as 30 megabytes of TypeScript code. Yes, it is also written in TypeScript, and the Sickle seems to be smaller. In 2018, we started, in 2019 there were 12 megabytes, and 70 of our developers worked, making 100 poured pull requests per week. In one year, they tripled this size, and received exactly 30 megabytes. I took measurements this month, in total we have 30 megabytes of code now, and this is already more than in vs-code.
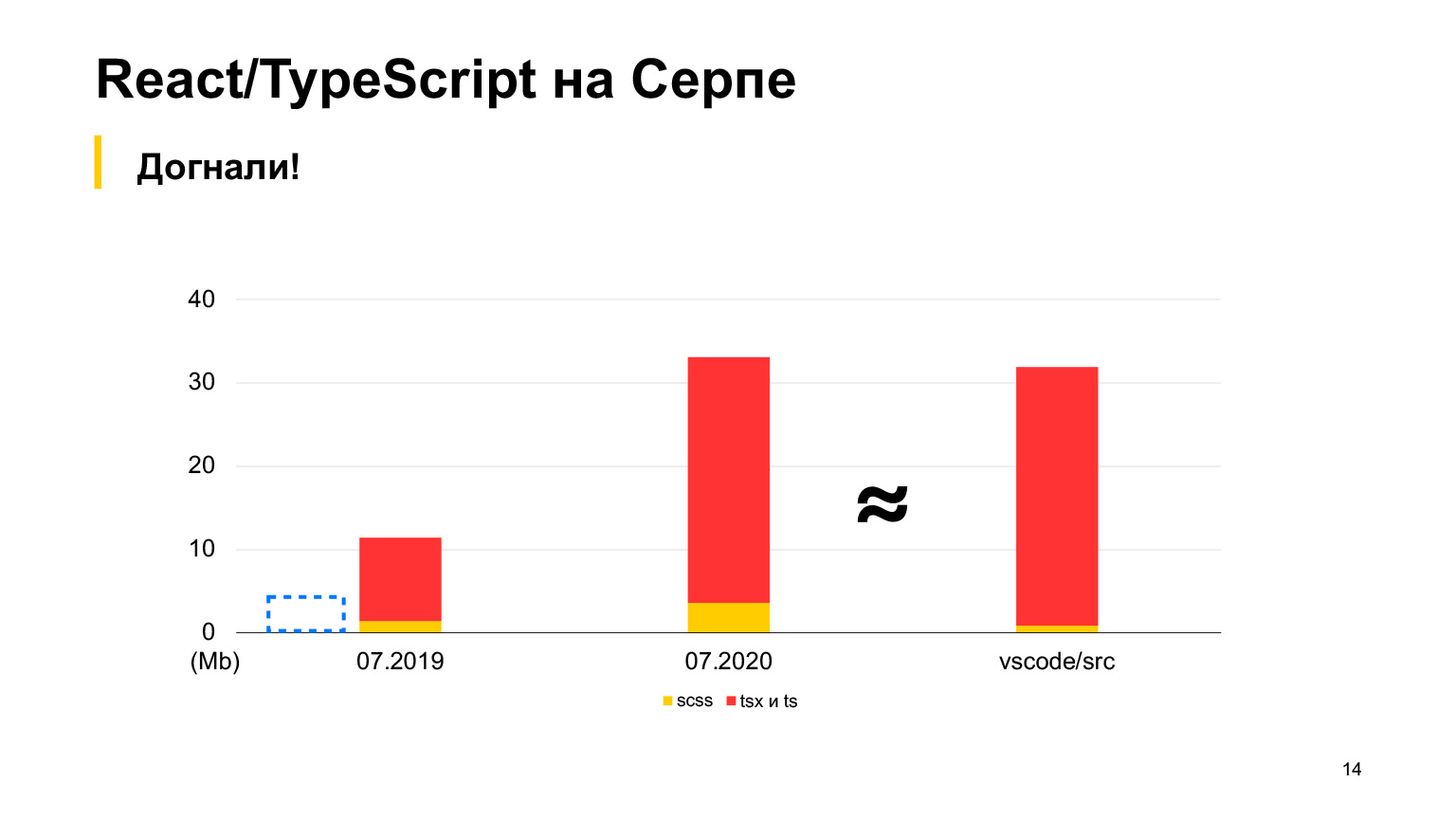
Approximately equal, but slightly more. This is the order of our project.
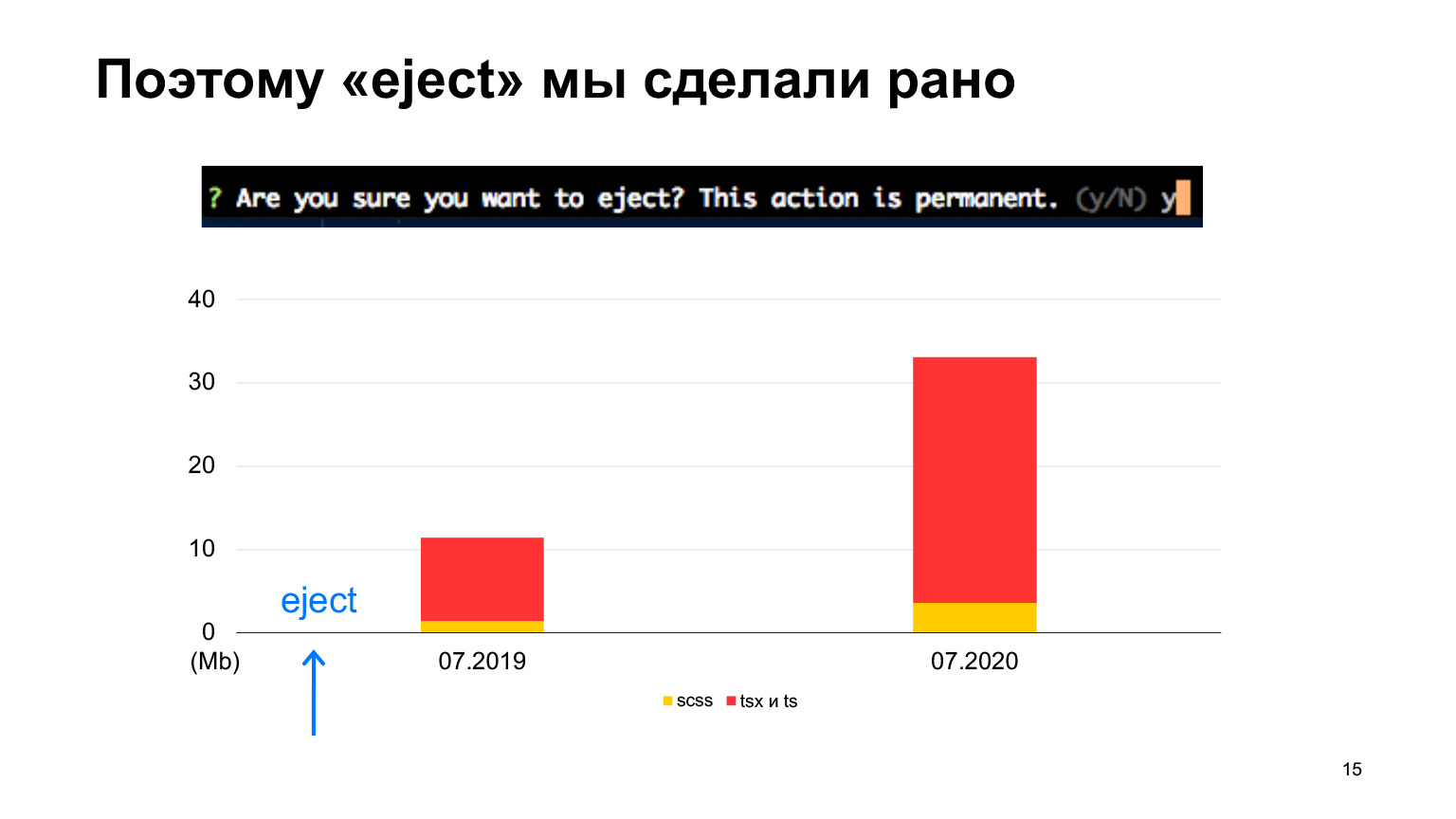
And we did eject at the very beginning, because we immediately knew that we would have a lot of code and, most likely, the initial configs that are in Create React App would not work for us. But we started the same way, with Create React App.
So that's what the story will be about. We want to share our experience, tell you what we had to do with Create React App to make Yandex Serp work properly on it. That is, how we got fast loading and initialization in the browser, and how we tried not to slow down the build, what settings, plugins and other things we used for this. And naturally, the results we have achieved will come at the end.

How did we reason? The original idea was that our Sickle is a page that needs to render very quickly, because, basically, there are very simple textual results, so we need server-side templating, because this is the only way to get fast rendering. That is, we have to draw something even before something starts to be initialized on the client.
At the same time, I wanted to make the minimum size of the statics, so as not to load anything superfluous and the initialization was also fast. That is, we want the first render to be fast and the initialization fast.

What does Create React App offer us? Unfortunately, it doesn't offer us anything about server rendering.
It directly says that server rendering is not supported in Create React App. In addition, Create React App has only one entry for the entire application. That is, by default, one large bundle is collected for all your huge variety of pages. This is a lot. It is clear that out of 30 megabytes, about half are TS types, but still a lot of code will go straight to the browser.
At the same time, Create React App has some good settings, for example, the webpack runtime goes there in a separate chunk. It is loaded separately, can be cached because it does not change normally.
In addition, modules from node_modules are also collected in separate chunks. They also rarely change, and therefore they are also cached by the browser, this is great, this must be saved. But at the same time, Create React App has nothing about translations.
Let's put together our list of how in our case the list of capabilities of our platform should look like. First, we want northerly rendering, as I said, to do a quick render. In addition, we would like to have a separate entry file for each search result.

If, for example, Serpa has a calculator, then we would like the bundle with the calculator to be delivered, and the bundle with the translator does not need to be delivered quickly. If all this is collected in one big bundle, then everything will always go, even if half of these things are not on a specific issue.
Further, I would like to supply common modules in separate chunks so as not to load what has already been loaded.
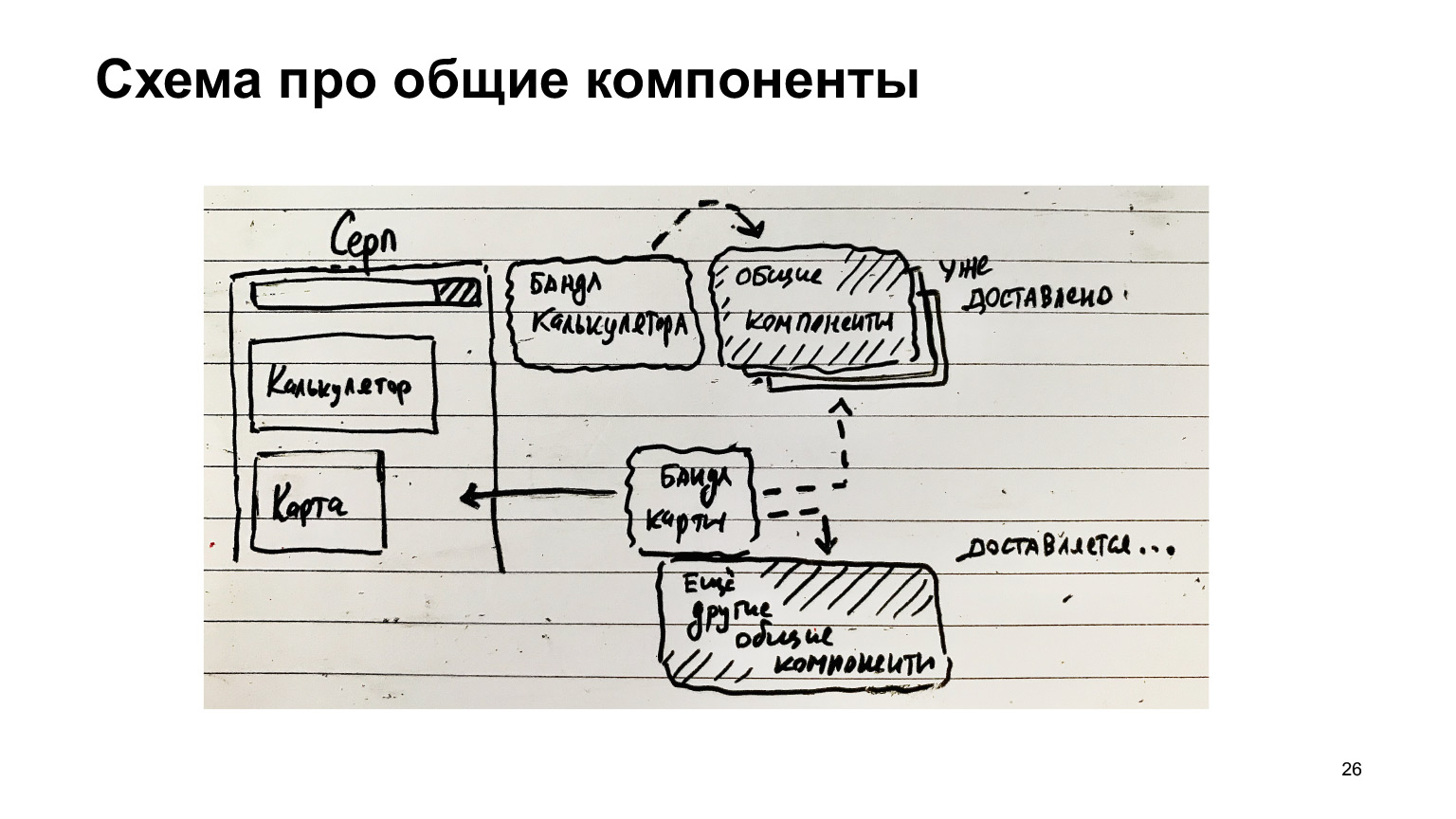
Here's another example with the Sickle. It has a calculator, there is a calculator bundle. There are common components. They were delivered to the client. Then another feature appeared - a map. Drove a bundle of maps, and drove other common components, minus those that have already been delivered.
If the common components are collected separately, then there is such a great opportunity for optimization and only what is needed is delivered, only diff. And the most popular modules that are always on the page, for example, the webpack runtime, which is always needed by this entire infrastructure, it must always be loaded.
Therefore, it makes sense to collect in a separate chunk. That is, these common components can also be broken down into those components that are not always needed, and components that are always needed. They can be collected in a separate file and always loaded, and also cached, because these common components, such as buttons / links, do not change very often, in general, get a profit from caching.

And at the same time, you need to make a decision about assembling translations.

Everything is clear enough here. If we go to Turkish Serp, we would like to download only Turkish translations, and not download all other translations, because this is an extra code.
What did we do? First, about the server code. Regarding it, we will have two directions - building for production and launching for dev.
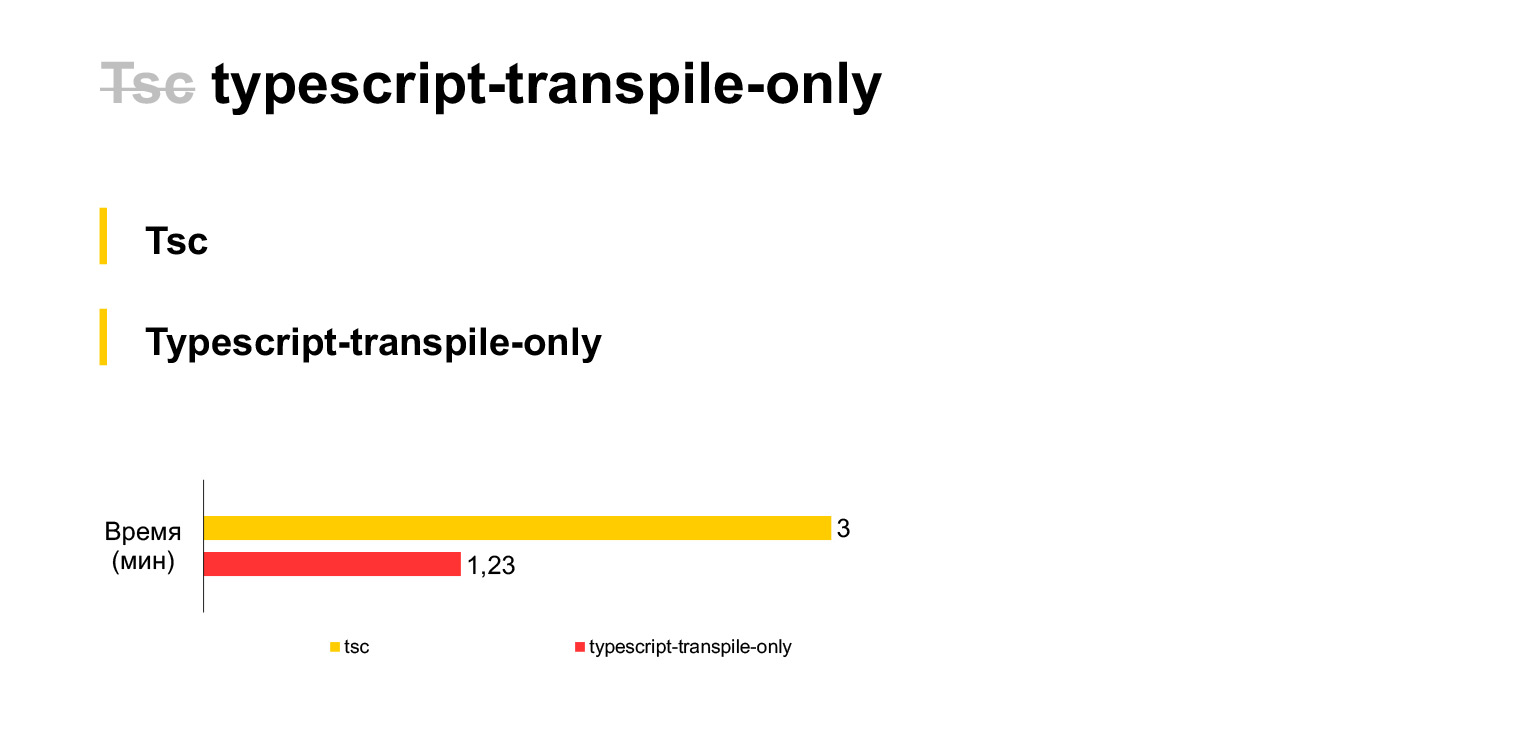
In general, you need to make such a separate statement about TypeScript first. Usually projects, as I've heard, use babel. But we immediately decided to use the standard TypeScript compiler, because we believed that new TypeScript features would reach it faster. Therefore, we immediately abandoned babel and used tsc.
So, this our current code size, our 30 megabytes, are compiled on a laptop in three minutes. Quite a bit of. If you refuse to type checking and use a tsc fork during each compilation (unfortunately, TSC does not have a setting that would disable type checking, you had to fork), then you can save twice the time. Compilation of our code will take only one and a half minutes.
Why can we not compile-time type checking? Because we, for example, can check them in pre-commit hooks. Make a linter that will only run type checking, and the assembly itself can be done without type checking. We made this decision.
How do we run in dev? Dev usually uses a bundle of babel with webpack, but we use a tool like ts-node.

This is a very simple tool. In order to run it, it is enough to write such a require (ts-node) in the input JavaScript file, and it will override the require-s of the entire TS-code later in the process. And if a TS code is loaded into this process along the way, it will be compiled on the fly. A very simple thing.
Naturally, there is a small overhead associated with the fact that if the file has not yet been loaded in this process, then it must be recompiled. But in practice, this overhead is minimal and generally acceptable.
In addition, there are some more interesting lines in this listing. The first is to ignore styles, because we don't need styles for server-side templating. We only need to get HTML. Therefore, we also use such a module - ignore-styles. And besides, we turn off the type checking (transpile-only) exactly as we did in TSC in order to speed up the work of ts-node.
Moving on to the client code. How do we collect ts code in webpack? We use ts-loader and the transpileOnly option, that is, roughly the same bundle. Instead of babel-loader, more or less standard ts-loader and transpileOnly tools.
Unfortunately, incremental build does not work in ts-loader. That is, after all, ts-loader is not quite a standard tool, and it is not made by the same guys who do TypeScript. Therefore, not all compiler options are supported there. For example, incremental build is not supported.
An incremental build is one thing that can be very useful in development. Likewise, you can add these caches to the pipeline. In general, when your changes are small, you can not completely recompile everything, all TypeScript, but only what has changed. It works quite effectively.
In general, to do without an incremental build, we use the cache-loader. This is the standard solution from webpack. Everything is quite clear. When the TypeScript code tries to connect during a webpack build, it is processed by the compiler, added to the cache, and the next time, if there were no changes in the source files, the cache-loader will not run ts-loader and will take it from the cache. That is, everything is quite simple here.
It can be used for anything, but specifically for TypeScript, this is a handy thing, because ts-loader is a rather heavy loader, so the cache-loader is very appropriate here.

But the cache-loader has one drawback - it works with file modification time. Here is a snippet of the source code. And it didn't work for us.

We had to fork and redo the caching algorithm based on the hash from the file content, because it didn't suit us for using the cache-loader in the pipeline.
The fact is that when you want to reuse the build results between several pull requests, this mechanism will not work. Because if the assembly was, for example, a long time ago. Then you try to make a new pull request, which doesn't change the files that were collected the previous time.
But their mtime is more recent. Accordingly, the cache-loader will think that the files have been updated, but in fact, not, because this is not a modification time, but a checkout time. And if you do it like this, then the hashes from the content will be compared. The content has not changed, the old result will be used.
It should be noted here that if we were using babel, babel-loader has a caching mechanism inside by default, and it is already made on hashes from the content, not on mtime. Therefore, maybe we will think a bit more and look towards babel.
Now about the assembly of chunks.

Let's talk a little about what webpack does by default. If we have an input index file, components are connected to it. They also have components, etc. In addition, common modules are connected: React, React-dom and lodash, for example.
So, by default, webpack, as everyone probably knows, but just in case, I repeat, collects all the dependencies into one big bundle.
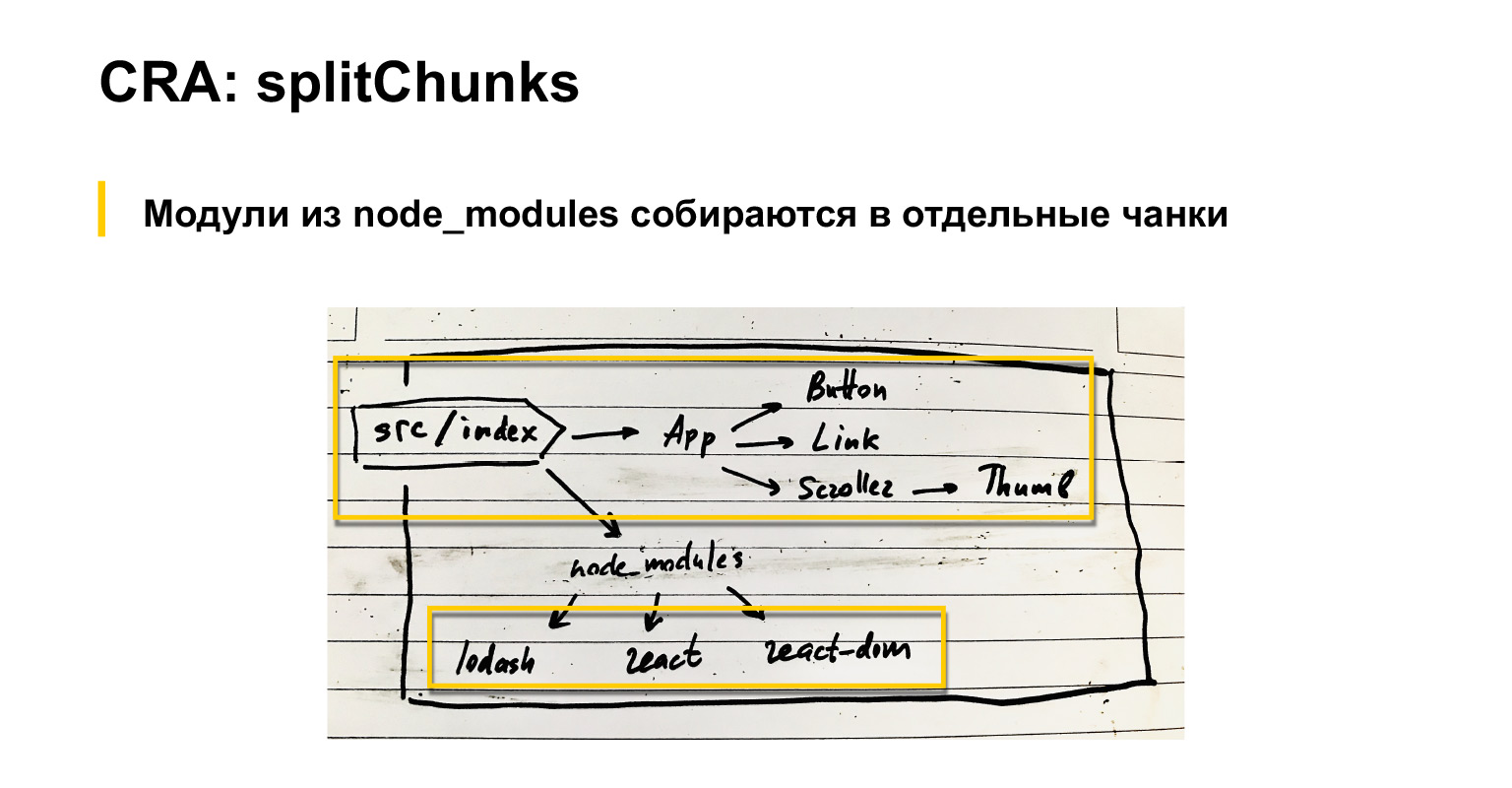
At the same time, everything that is connected via node_modules can be assembled either as externals, loaded with separate scripts, or in a separate chunk by setting up a special optimization.splitChunks setting in webpack. In my opinion, even by default, these vendor modules are collected in a separate chunk. CRA has a slightly tweaked version of this splitChunks.

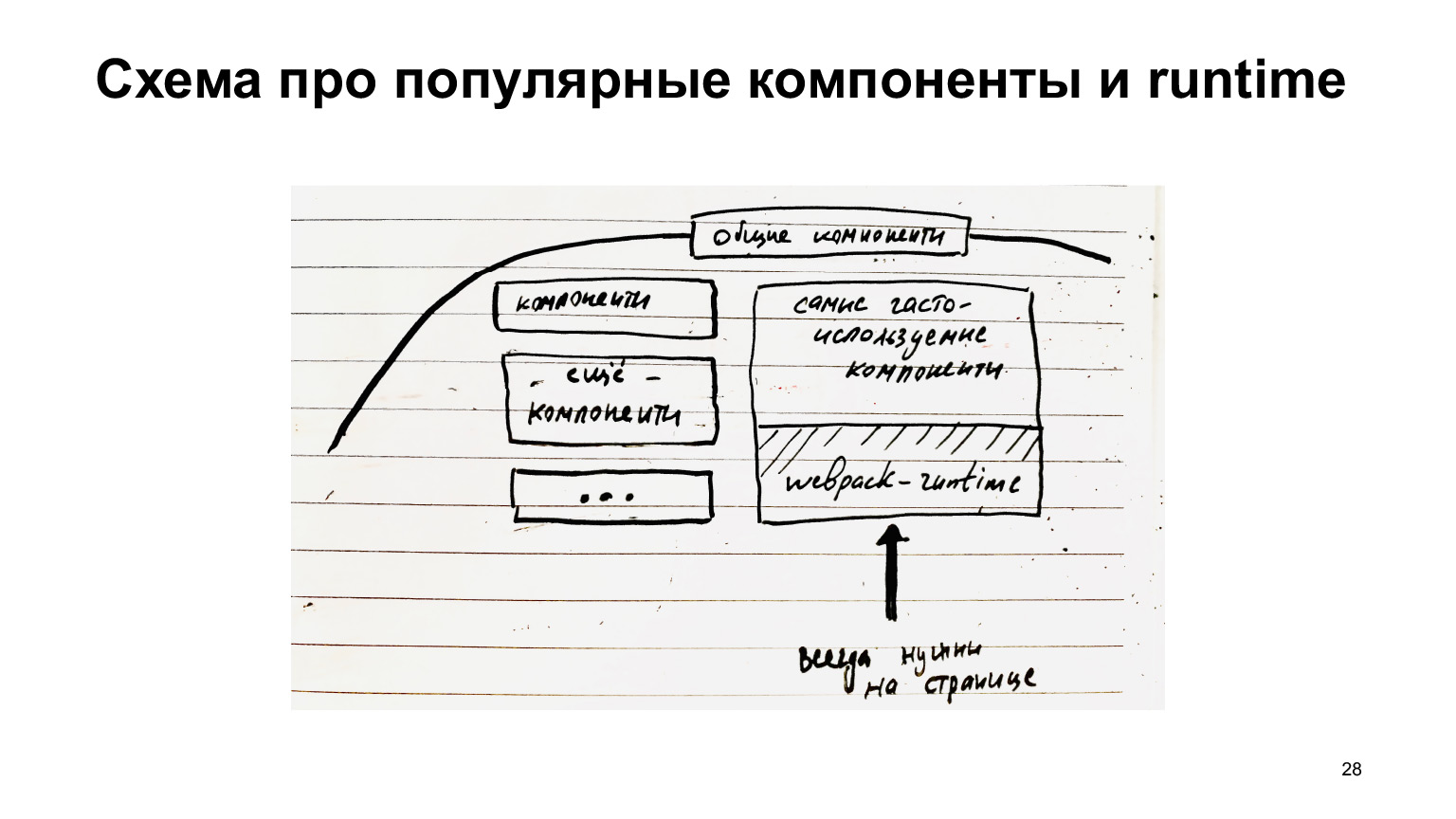
Let's remember what runtimeChunks are. I mentioned him. This is the kind of code that contains such a “header” of loading scripts and functions that ensure the operation of the modular system on the client. And then an array (or cache), which, in fact, contains the modules.

Why did I tell you about this? Because Create React App still uses a setting that collects this runtimeChunks into a separate file. This file will not be stuck into the original healthy bundle, but into a separate file. It can be cached in the browser and all that.
So what doesn't work for us in Create React App?

This splitChunks, which is used there by default, collects only node_modules into separate chunks. But, in fact, there are common components, common libraries, that are at the project level. I would also like to collect them in separate chunks, because they, perhaps, also rarely change. Why do we limit ourselves only to what is in node_modules?
In addition, regarding runtimeChunks, we can also say that it would be great, as we originally discussed, besides the runtime itself, to also collect modules there, in the same chunk, which are always needed. Same buttons / links. There are always links on Serp. I would always like to collect links. That is, not only the webpack runtime, but also some super popular components.
This is not present in Create React App. How did we do it with us?

We tweaked splitChunks in such a way that we disabled all standard behavior and asked to collect into common code not only what is in node_modules, but also what is the common components of our project and the library code of our project, what is in src / lib , src / components contains.
In addition, we collect into separate chunks what is connected via dynamic imports, and what is usually called asynchronous chunks.
Here you need to pay attention to two options. One is enforce and the other is initial. In general, enforce is such a convenient enough setting that it disables any complex heuristics in splitChunks.
By default, splitChunks tries to understand how much modules are in demand and take these statistics into account in the split. But it is difficult to follow this, and the demand for the module can change from time to time, and the module will "jump" between chunks. From the general chunk to the feature bundle and back. That is, this is a very unpredictable behavior, so we disable it.
That is, we always say everything that satisfies the conditions in the test field, we get into the common chunks. We do not want any heuristics.
But chunks: initial is also a good thing, it is about the fact that these synchronous modules, modules that are connected via dynamic imports, they can be connected in different places in different ways. That is, you can connect the same module either by dynamic import or by regular import.
And the initial value allows the same module to be built in two ways. That is, it is assembled, both asynchronous and synchronous, thus allowing it to be used both ways. Convenient enough. This slightly inflates the size of the collected statics, but it allows you to use any imports.
From the documentation, by the way, this is quite difficult to understand. I recently re-read the webpack documentation and nothing normal is written about initial.

This is what we did with splitChunks. Now what have we done with runtimeChunks. Instead of collecting only runtime in runtimeChunks, we want to add more super popular components there.
We have written our own plugin called MainChunkPlugin. And it has a very trivial setting. There is just a list of modules that need to be collected there, which we considered popular.
Just using our A / B testing tools, various offline tools, we realized which components are most often in the search results. That's where they were written just in such a flat list. And in the end, our plugin collects these components from the list, as well as libraries, as well as the webpack runtime that collects this standard optimization.splitChunks.

Here, by the way, is a piece of code that glues the runtime. Also not so trivial to show that it is not so easy to write plugins, but then let's see what it gave.

It should also be noted that generally speaking, webpack has a standard mechanism for doing this, called DLLPlugin. It also allows you to collect a separate chunk according to the list of dependencies. But it has a number of disadvantages. For example, it doesn't include runtimeChunks. That is, runtimeChunks you will always have a separate chunk, and there will be a chunk assembled by DLLPlugin. This is not very convenient.
Also DLLPlugin requires a separate assembly. That is, if we wanted to build this separate chunk with the most percussive components using DLLPlugin, we would have to run two assemblies.
That is, one assembled this separate chunk with the manifest file, and the rest of the assembly would collect everything else, simply by subtracting through the manifest file, it would not collect what has already entered the chunk with popular components. And this slows down the build, because the DLLPlugin implementation took us seven seconds locally. That's a lot. And it cannot be optimized because it has strict sequential execution.
In addition, at a certain moment we needed to build this main chunk of ours with popular components without CSS, only JS. DLLPlugin doesn't do that. It always collects whatever is available through require through imports. That is, if you include CSS, it always hits too. It was uncomfortable for us. But if this is not a problem for you, and you don't want to write such tricky code, then DLLPlugin is quite a normal solution. He solves the main problem. That is, it delivers the most popular components in a separate file. It can be used.
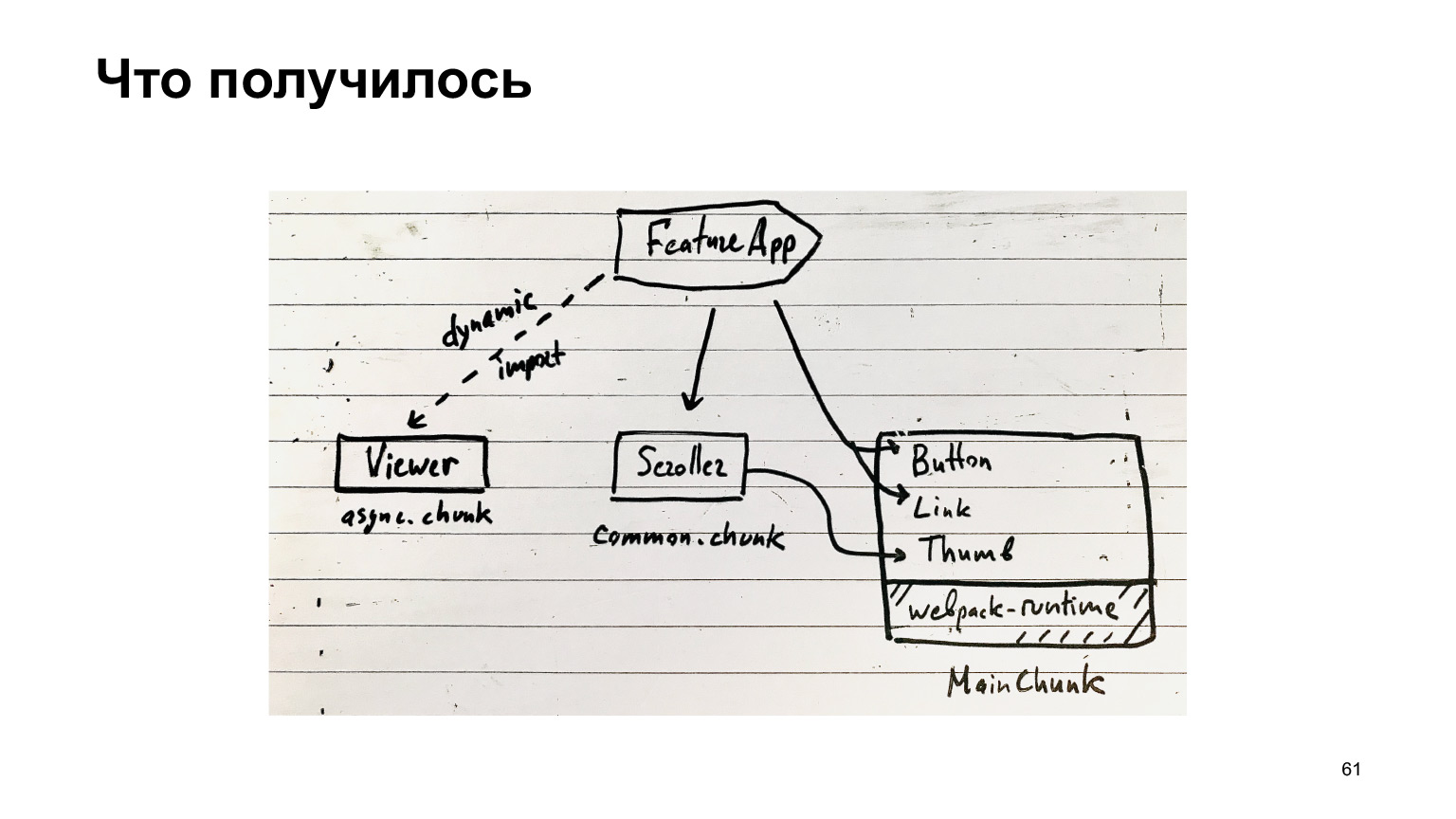
So what did we get? Our feature can use super popular components from our MainChunk, which are assembled by a special plugin of the same name. In addition, there are common chunks, which include all sorts of common components, and there are asynchronous chunks, which are loaded through dynamic imports.
The rest of the code is in the feature bundles. In principle, this is your chunk structure.
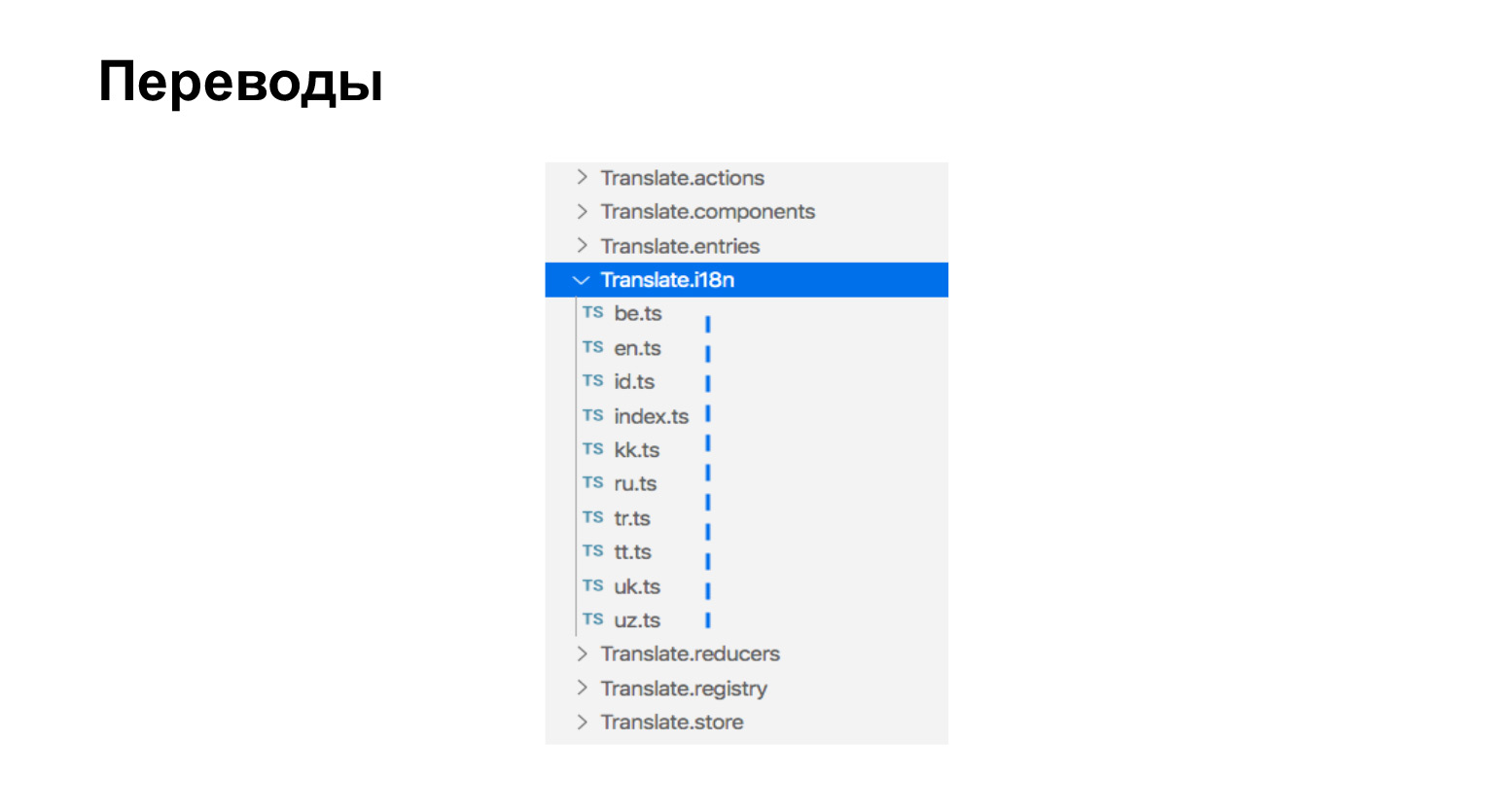
About assembling translations. Our translations are just ts files that are next to the components that need translations. Here we have nine languages, here are nine files.

The translations look like this. It is simply an object that contains a key phrase and the meaning of the translated phrase.

This is how translations are connected to the component, and then a special helper is used.

How could these translations be collected? We think: we need to collect translations, look on the Internet, what they write, how we can do it.
They say on the Internet: use multicompilation. That is, instead of running one webpack build, just run the webpack build for each language. But, they say, everything will be fine, because there is a cache-loader, it is all this general work with TypeScript, or whatever you have, will be cached, and therefore it will not be long.
Don't be discouraged, don't think that this will be nine real webpack runs. It will not be so, it will be good.
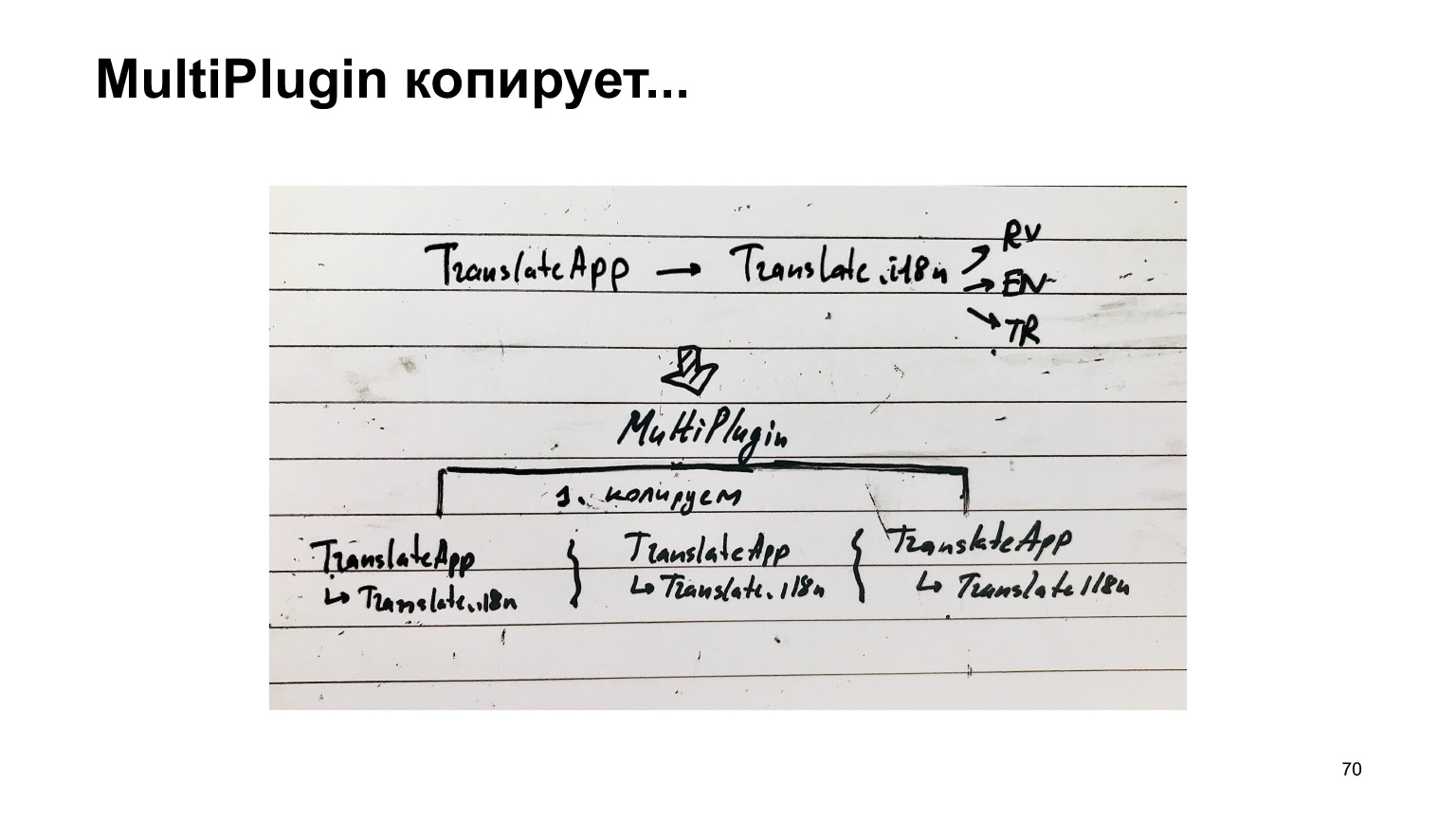
The only thing that needs to be corrected is to add the ReplacementPlugin module, which, instead of an index file that connects all languages, will replace it with a specific language. Everything is quite trivial, and yes, the output needs to be fixed. Now we, it turns out, need to collect a separate bundle for each language.

The diagram for this recipe is as follows. There was a translator. He connected translations of the translator. He connected languages, and we, instead of collecting this one structure, we replicated it for each language, got a separate one, and collect each as a separate compilation.
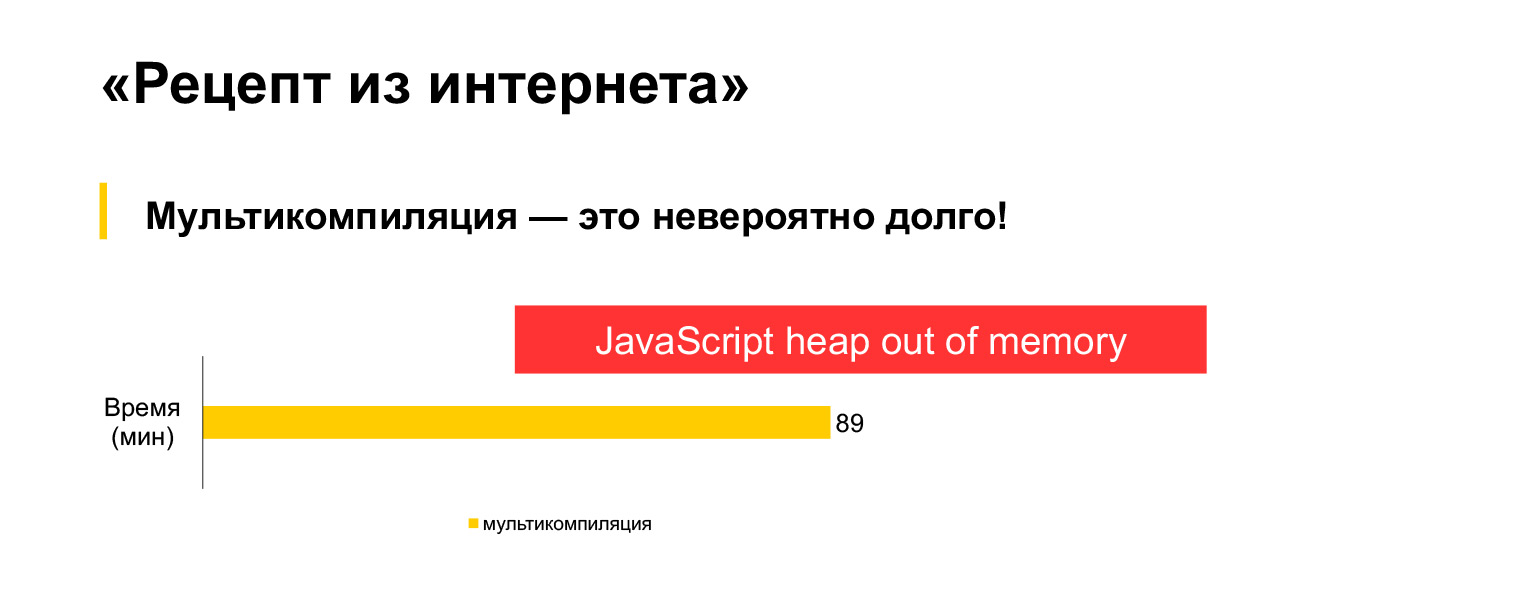
Unfortunately, it doesn't work. I tried running this multicompilation option for our current 30MB code, and waited an hour and a half, and got this error.

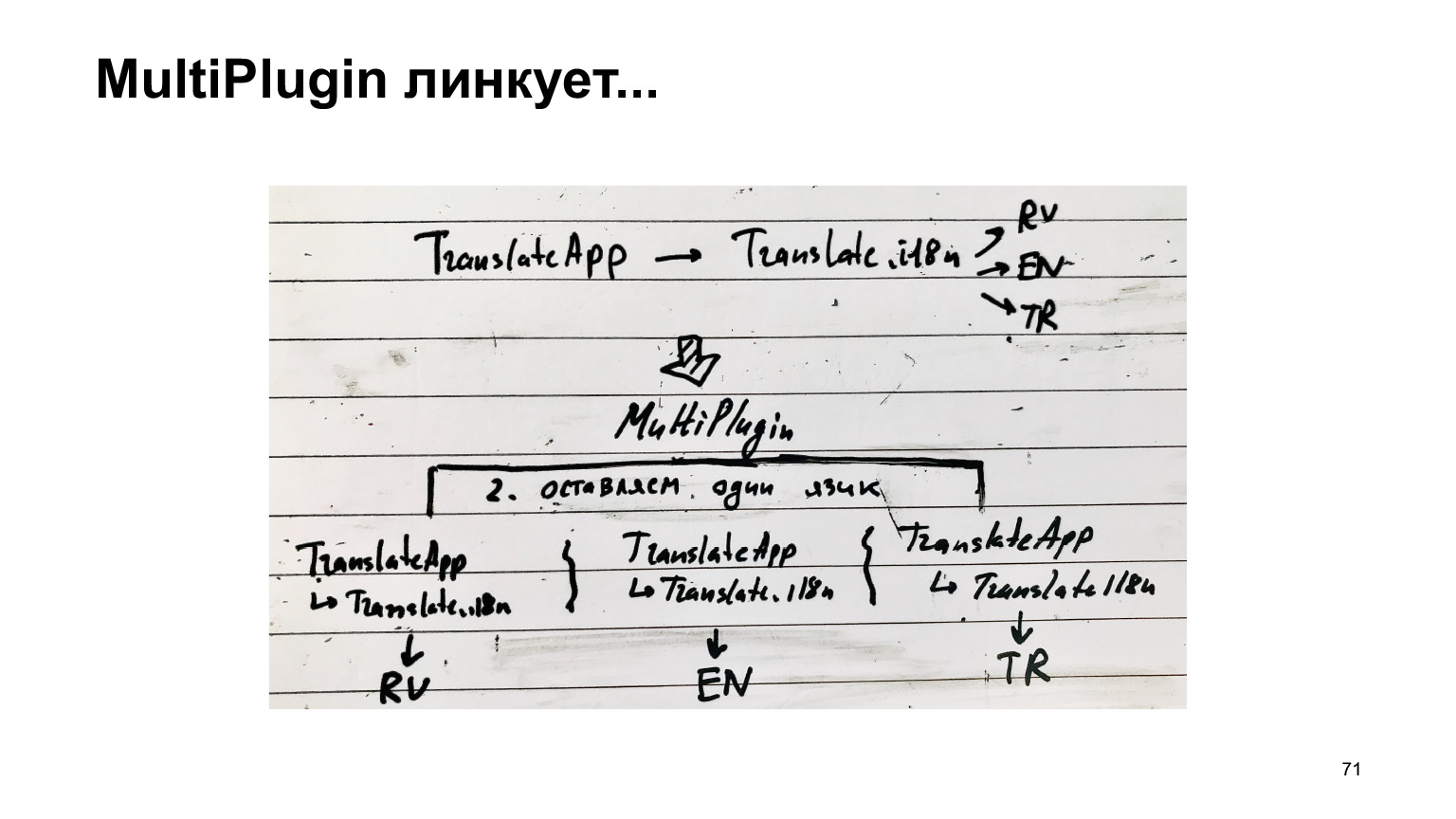
It is very long and impossible. What have we done with this? We've made another plugin. We take the same structure and wedge ourselves into the work of webpack when it is about to save the output files to disk. We copy this structure as many times as we have languages, and glue one language to each. And only then we create the files.

At the same time, the main work that webpack does to bypass compilation dependencies is not repeated. That is, we wedge in at the very last stage, and therefore we can hope that it will be fast.

But the plugin code turned out to be complicated. This is literally one eighth of our plugin. I'm just showing how difficult it is. And there we regularly find small, unpleasant bugs there. But it was not easier to implement it. But it works very well.
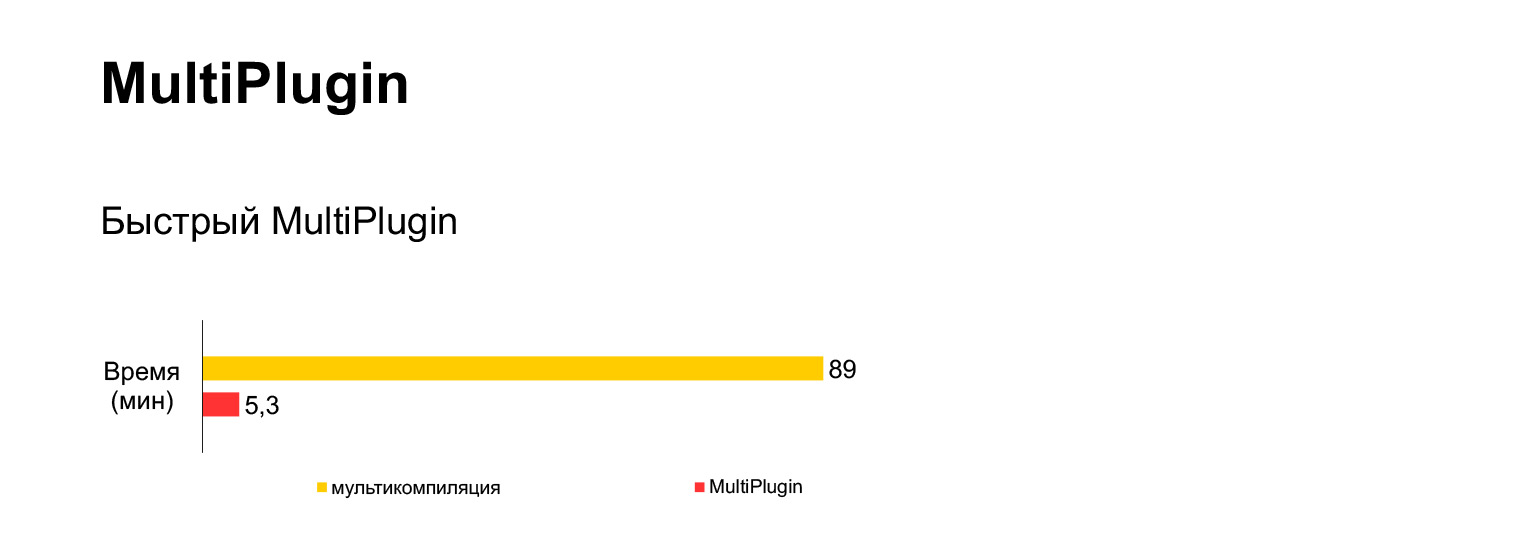
That is, instead of an hour and a half with an error, we get five minutes of assembly with this plugin.
Now delivery and initialization.

Delivery and initialization is simple. What we load in separate resources, we use preload, just like everyone else, I guess. Then we include CSS, JS, actually HTML for our components, and load these our resources, but without async.
We experimented. If you use async, then the timing of the onset of interactivity is removed, which we would not want. So just use preload and load at the end of the page. In general, nothing special.

At the same time, we inline everything else. That is, this is our MainChunk, we inline its CSS. General components, styles, in general, everything that is written on the slide, we will inline. This was also a series of experiments that showed that "inline" gives the best result for the first render and the onset of interactivity.
And now to the numbers. To talk about numbers, you need to say two words about metrics.

We have a dedicated speed team that aims to make all front-end code work efficiently. This concerns server-side templating, and loading resources, and initialization on the client, in general, all this.
We have a whole bunch of metrics that are sent from production to our special logging system. We can control this in A / B experiments. We have offline tools, in general, we are very actively following this all.
And we used these tools when we implemented this new code of ours in React and TypeScript.

Let's now track with the help of offline tools (because I could not put together an honest online experiment that would use all of our metrics). Let's see what happens if we rollback from our current solution to Create React App on these key metrics.
The tool works very simply. A slice of requests is taken, in this case, a request with features in React is taken, because not all Serp has been rewritten in React yet. Then our templates are fired at, measurements are collected, inserted into a special utility that compares and finds these results and metrics. In this case, only statistically significant results remain. In general, everything is reasonable there.
Let's see what happens.

Disabling MultiPlugin, which, in fact, collects all translations instead of just the required translation, showed no statistically significant changes.
At first I was a little upset, then I realized that, in fact, this is not a problem, because now we do not have many features that have many translations translated into React. Therefore, when there are more such features, these significant changes will definitely appear. It's just that now there are features that are mainly shown in Russia and they do not have translations. And the amount of code contained in the components greatly exceeds the amount of translations. Therefore, it is imperceptible that all translations are on the way.
Perhaps it would be noticeable in more honest experiments, if an honest experiment was carried out. But the offline tool didn't show these changes.

If we disable the MainChunkPlugin, then the time for the onset of interactivity slows down, and the HTML loading also slows down a lot. Therefore, the thing is quite necessary.
Why is loading HTML slowing down, because all the code that used to be loaded in this separate chunk by a separate resource is now inlined in HTML. It's like we inline it all, but the interactivity also slows down. In principle, quite expected.
And now the question: what would happen if you put everything in one bundle, do not use any chunks with common components? It turns out that this is not a happy picture at all.

The first render slows down dramatically. Interactivity, too, almost doubled. This makes the HTML smaller as all the code begins to be delivered in a separate resource. But interactivity, as you can see, it doesn't help.
And assembly. Last slides.
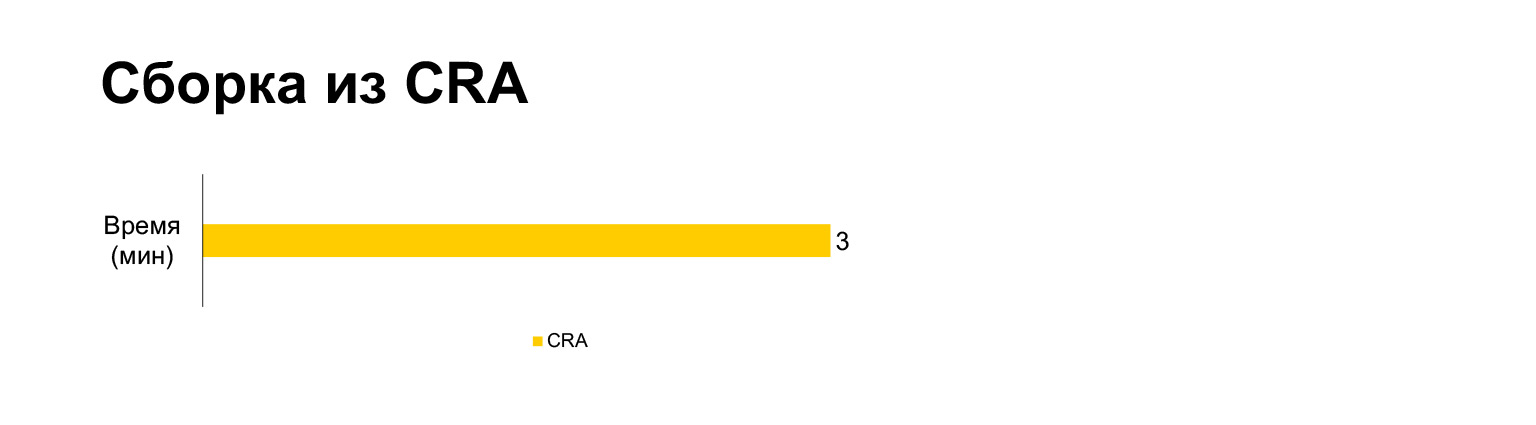
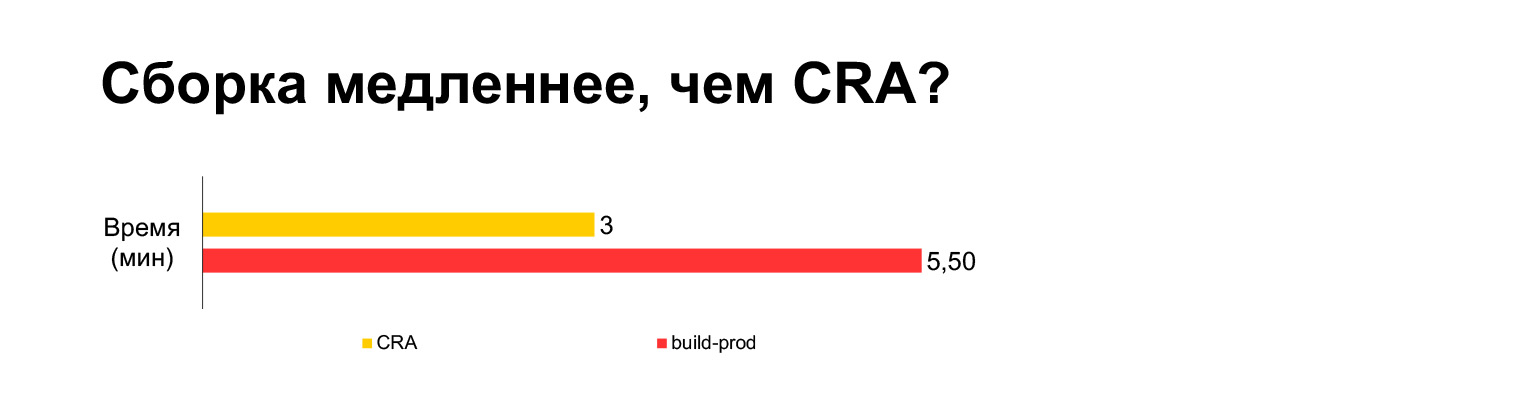
The Create React App build time for the current project takes three minutes on a laptop. And with all our bells and whistles - five minutes. Long?
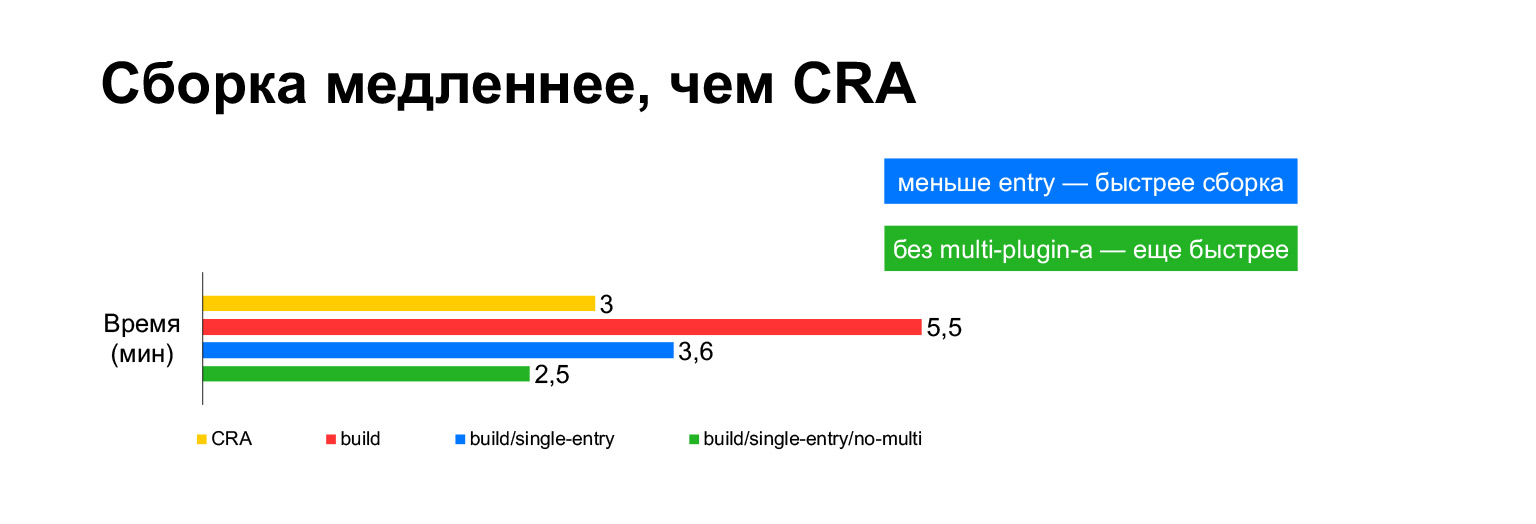
However, in fact, if you put together in one bundle, it turns out to be three minutes. Build without MultiPlugin makes it even faster than Create React App. But as I showed in the previous slides, we cannot refuse these modifications to the original build scripts, because without them, the speed metrics will become very bad.
Now let's go over what is useful to learn from this report.

Babel isn't the only way to work with TypeScript. TSC, ts-node and ts-loader can be used. It works quite well.
However, TypeScript checks, type checking, do not have to be performed every time you build. This slows down a lot - as you remember, twice. Therefore, it is better to place such things in separate checks, pre-commit hooks, for example.
It is better to collect frequently used components in a separate chunk. It is also desirable to collect common components in separate chunks, because this allows you to load only what is needed, only diff.
The most important thing is that if you do not have all the code used on all pages, you need to break it down into separate entries, collect separate bundles and load as the user sees the corresponding types of search results. Download only the files you need. This, as you have seen, gives the greatest result. Pretty obvious thing, but I'm not sure if everyone does this, because they still remain on Create React App.
Multicompilation is very long. Do not believe if someone says that multicompilation is okay and caches somewhere inside can handle all this. Using preload and inline also gives results.
A few links about the Sickle:
- clck.ru/PdRdh and clck.ru/PdRjb - two reports that are about rewriting Serp in React, this is the first stage, about how we came to this and why we started doing it. The second report is about how we planned and did all this from a managerial point of view, what the stages were.
- clck.ru/PdRnr - report about our speed metrics. It is for those who suddenly wondered what else is there, how online tools work.
Thanks to all.