
The full two-hour version can be viewed on the Hexlet YouTube channel .
Table of Contents:
Product and Company History
- RealtimeBoard → Miro
How product development works
- Work environment
- Stack, monolith
- Releases
Technology selection and evolution
- Flash → Canvas
- Angular → React
- Servers and databases
- Java
- Testing evolution
- Load growth and refactoring
Processes in development
- Technical solution and code review
- Performance Review
- How Hiring Engineers Works
- Junior positions
Product and company history
Miro is an online collaborative whiteboard platform for visual collaboration. The key word is collaboration, collaboration, respectively, the key metrics by which we measure our effectiveness are the number of collaboration boards and collaborative sessions that happen in the product.
We call ourselves a platform because we have already gone beyond just a product: we have an open API, a marketplace, a developer's office, so any company can expand the product for itself.
Our target audience is product teams that operate from the same or different offices. Most often, Miro is used for conducting workshops, strategic sessions, brainstorming, agile practices (planning, retrospectives).

I lead development at Miro. I grew up in Perm and continue to live here. Historically, the company appeared in Perm, where our founders come from. Most of our development department is now here, and in 2019 we launched and are actively developing a second engineering office - in Amsterdam.
Previously, I worked in custom development, starting by building analytical data warehouses as a developer, then designing them, and then leading large projects. He joined Miro in 2016 when the company employed 30 people. Since then, we have grown a lot: now we have five offices, 400 people, of which 140 are engineers.
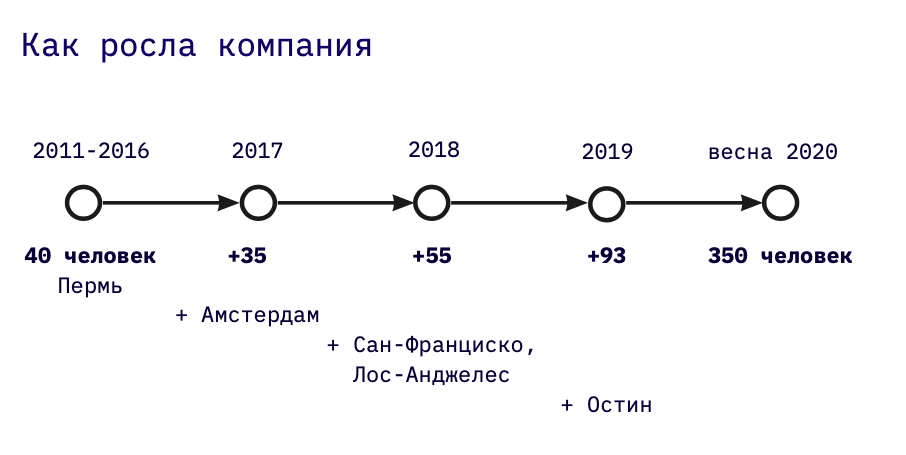
The company was founded in 2011. Our biggest function was and remains product development, which today accounts for about half of the company.
Name change
We thought about rebranding back in 2015, but ended up doing it in 2018. Our former name RealtimeBoard is long and complex. It was often mistaken, abbreviated to RTB, or, worst of all, forgotten altogether. Besides, it is unemotional, there is no story behind it. We wanted to make the new name short, capacious, speaking, memorable.
As a result, we were inspired by the works of the artist Joan Miró and chose his last name as the title. The research itself and the choice of the name took several months, and then a few more months we launched a new brand. Following in the footsteps of this project, there is a series of articles about how the work on the project was arranged, and a separate article about a small but non-trivial technical problem for seamless migration of authorized users from the old to the new domain.
Both we and users quickly got used to the new name. We are growing fast, so several million new users do not even know that we were called differently. A pleasant rebranding bonus was the awards from the European Design Awards for the identity, which we developed as part of the rebranding together with the European agency Vruchtvlees .
How product development works in Miro
The entire product development team of 170 people is located in Perm and Amsterdam: engineers, products, product designers, scrum masters.
Earlier it was difficult for me to imagine that so many people can work on one product. But today, I know there are thousands of engineers working on the same product at Uber, Slack, and Atlassian. We continue to grow and understand that we are clearly not enough now, and the next target point in my head is 300 people in development, and then we will continue to grow further. It's not just a number out of your head. We have strategic planning, we understand where we want to be in two years, in five years, and what we need to do for this.
In terms of organizational structure, there are guilds: frontend, backend, QA, and so on. To work on projects, they are combined into cross-functional teams.
Teams are distributed in key areas:
- Horizontal product is the main product functionality that all users see: stickers, text, shapes, frames, etc.
- Systems direction - responsible for the core platform and infrastructure.
- Growth is all about growing the number of users: activation, engagement, return, monetization.
- Enterprise — , . -, Miro, . -, SaaS-, . , , .
- — 2019 . API, , marketplace, — , , .
- — , . , , , Miro, : Meetings & Workshops, Ideation & Brainstorming, Research & Design, Agile Workflows, Strategy & Planning, Mapping & Diagramming.
: , , . , . , : - .
The main software of engineers: IntelliJ Idea, Jira, Slack, Zoom, Miro, Confluence. Most of the employees work on MacBooks, most of the engineers work on MacBook Pros, for some we buy more powerful machines if necessary.
We use our own product every day: internal meetings, workshops, brainstorming sessions, planning.This allows you to quickly test all the innovations in the product and greatly simplifies the adaptation of new developers who, from the very first day, work with the product not only in terms of code, but also as users. This is a significant part of our culture - we make a product that we ourselves should be comfortable and enjoyable to use.
Stack, monolith
The front is Typescript, React and AngularJS. The backend is Java. Databases - Redis, Postgres, for cluster communication - Hazelcast and ActiveMQ. We host in Amazon, in the same data center. There are about 400 servers in production. Application servers that process user boards can be up to 100, everything is automatically orchestrated.
We use a stack from Atlassian: Jira, Bitbucket, Bamboo and our own scripts that are bolted to Bamboo and allow everything to be rolled out to servers. So far, all releases are one big front release and one big back release. Now we are thinking about how to make more of these releases.
Our main application is a modular monolith: there is a module that is responsible for the API, for the board, for the service function. The monolith is deployed in modules to the required servers, and not in one large piece to all servers in a row, that is, we also have servers with different roles.
Within the application, there are many integrations and additional services that we immediately did separately and which the teams independently release separately from the rest of the front and back.
When you have a small company, it is much easier to start with a monolith and not fence the infrastructure for services. But now we have come to understand that one common monolith does not give us the ability to scale individual directions (horizontal product, platform, enterprise, etc.), so we are developing an approach to leave a single monolith.
Releases
The assembly itself takes 15-20 minutes, including the execution of unit tests. End-to-end tests can take up to 40 minutes. The whole process takes one and a half to two hours to bring the master to release. This is a long time, we still have something to work on here.
It's probably ideal to release every five minutes. But for this we have not yet such a large team and not such a large daily audience. A large audience is important for frequent releases, because it allows you to quickly make sure that everything is ok by rolling out changes to a small proportion of users.
Technology selection and evolution
I believe that the choice of technology should be treated like this: no matter what you choose, you still have to change it someday, especially if the company and the product grow. Therefore, the process of changing technologies is normal. Technology is important, but it needs to be treated differently at different stages of a company's development.
Small companies that are just starting out and looking for product market fit run fast, build MVPs quickly, and quickly throw them out. Finding a market is more important for them, rather than creating complex technical solutions. But when the market is found, technical solutions come to the fore, because they allow you to create a margin of safety for growth and security.
We first try to understand the problem that we want to solve by changing technologies. Then we do a lot of research, explore alternatives, test performance. This is done with any technical solutions that we are going to implement: "do not take the first thing you first heard about on the market, but research and study what is best suited for solving the problem."
In a large product and a team, a change in technology is an important strategic decision; it can lead to a partial or complete halt in product development, switching teams to new tasks, and so on. It is long and expensive, but if this is not done in time, the problems that appear can bring much more difficulties.
We've had a few big technology shifts, at the front and at the back. Here are some examples.
Flash → Canvas
Until 2015, the entire front was on Flash, then Flash began to die and we switched to HTML and Canvas. The stack change had a good effect on the performance and usability of the product, and led to a noticeable increase in the audience. The transition took about a year, it was a large and complex project. An article about the details of this project .
We are currently considering migrating to WebGL, but there is no clear evidence yet that it is worth it.
Angular → React
Over the past couple of years, we have been gradually moving from Angular JS to React. Main reasons:
- React allows for better typing, and later on it allows you to refactor your code better and ensures that nothing falls off.
- React . «» , Angular . Angular, React, .
- React , Angular JS .
In 2015, we switched from Hetzner leased servers to Amazon hosting. For more than a year, there has been a project to migrate the main database from Redis to PostgreSQL. We have articles about this: project management of data migration , creating a failover cluster .
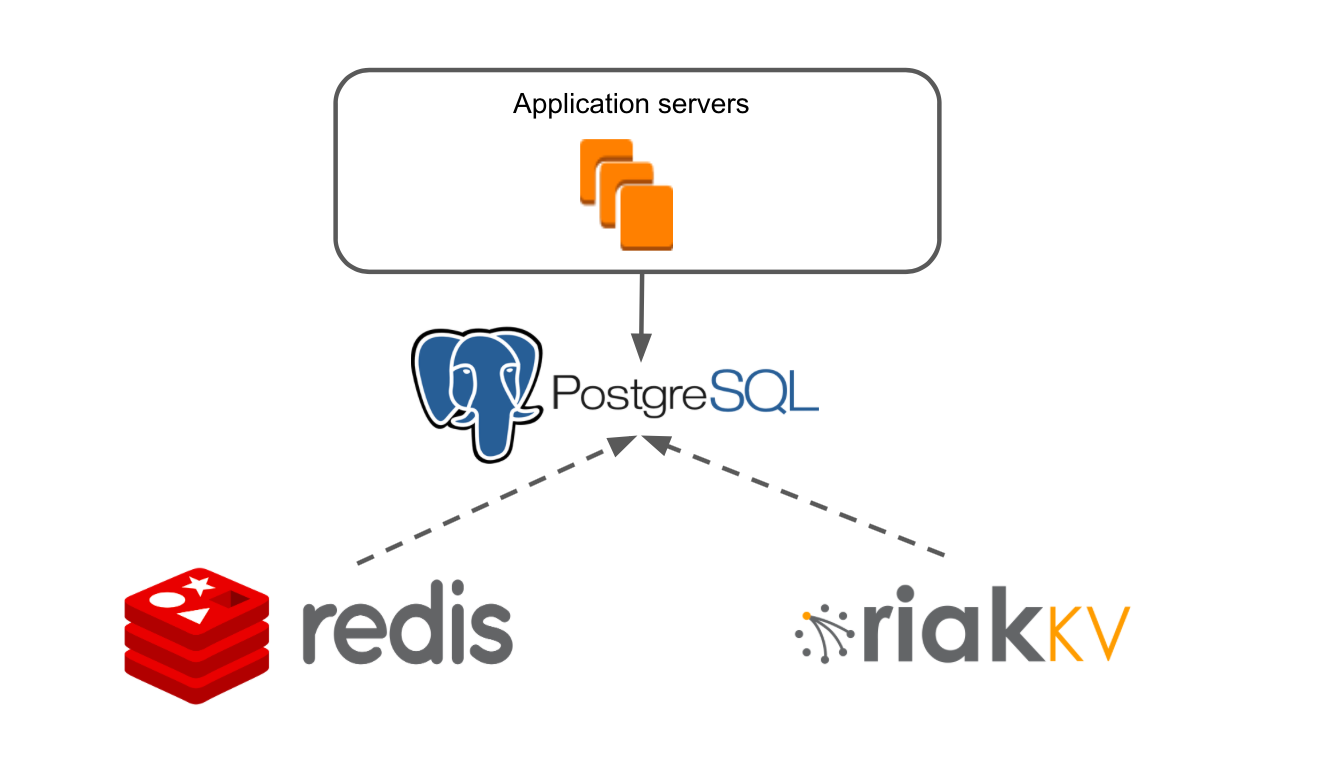
Our case is complicated by the fact that from the Key Value of the storage we are moving to a SQL database. There is a lot of refactoring. It is important to do everything so that the application does not stop. It's like changing the wheel of a driving car, because the database is the foundation on which the application stands. For the content of the boards, we actually did everything without maintenance. Yes, the transition process was delayed, but users did not notice anything, the product worked.
Product stability is a key focus. Users store a lot of content in Miro. Accordingly, if a user has scheduled a session or a meeting, prepared a content board for it, and the product is not available at that moment, this is a failure, the content cannot be used. While conditional Zoom can be quickly replaced with Hangouts, content cannot be quickly replaced. Therefore, one of our key tasks is to ensure that content for users is always available.
Java
Java helps us tremendously in terms of productivity and developer resources that we can find. I know that Booking is switching from Pearl to Java because they are tired of retraining their engineers.
Engineers from C ++ and .Net come to us and adapt normally. If you are an experienced developer, have tried different technologies and know how the system is built, then it is not so difficult to dive into a new language. The main thing is that the engineer comes up with the right solutions, and he will definitely be able to bury himself in the tongue, I believe in this.
Testing evolution
Initially, we only had manual testing. Releases were rolled out every two to three weeks, preparation for release took a week: you do regression testing in a few days → find critical bugs → correct → manual testing again. When there were several teams, it worked, but with twenty teams it is impossible to test everything manually.
So we started thinking about automation. First of all, we wrote autotests to completely get rid of regression testing. Now we are working on setting up the correct quality management processes throughout the entire development cycle. The sooner we think about quality, the earlier we will find edge cases, understand how to test them - this will ultimately reduce the cost and speed up the development process. A bug that you find on sale is not only worth the time and resources to roll back the release and fix it. The bug affects the overall user experience of the product, and it is very expensive to fix that experience.
We have a QA guild, in which engineers make decisions about what processes we need to implement now, develop a quality strategy, and then each QA engineer helps his teams implement these processes in their own country:
- QA- -, . QA , . .
- QA , .
- QA , , .
Canary releases are also a way of testing, when we roll out a feature to a small audience and check if we have missed something. We launch large new features through checkboxes, roll out to beta users who have expressed a desire to participate in beta testing (our product managers will find out about this during research interviews). The number of beta and alpha users necessarily includes our teams, we roll out absolutely all new functionality to ourselves in the first place.
A detailed description of all stages of our QA process .
Load growth and refactoring
Due to the massive shift to remote work in 2020, our number of users has grown dramatically and our annual infrastructure and application safety margin ran out in a few weeks. In the very first week of a sharp increase in load, we stopped all product development and reoriented teams to work on fault tolerance and performance.
The safety margin was needed not only on the backend, but also on the front-end and the client, as the number of synchronous jobs increased in the product. If earlier 20 people could work on one board at the same time, now it is 300 people. Our front-end engineers have done a lot and continue to tackle load performance. For example, we make the dashboard with the list of boards load separately from everything else and do it faster than before. And if the user goes directly to the board, not through the dashboard, then the code and content of the board should be loaded, without everything else.
We will refactor a lot so that the user gets feedback and content from the board faster, and then all the main functionality - scripts, the interface - slowly drives up. To do this, we switched to dividing the code into “lazy” modules. Thanks to this, we have accelerated by about a third, and in the next month we plan to double the speed in terms of loading.
It's the same in terms of performance on the board - there is a war over speed and resources on the computer the user is running on.Not everyone went online with good machines; someone pulled an old, low-performance home laptop off the shelf. But our product should work well on any laptop. This is another big trick that we are working on a lot right now.
Processes in development
Technical solution and code review
Any task begins with the preparation of a product solution. A product solution is an answer to the question “What are we going to do?”. A product manager based on product strategy and OKRs is doing a lot of research to find out what users are currently missing in our product. Based on the research, the product describes the solution. The food guild discusses the solution, revises it if necessary.
On the basis of a product solution, a technical solution is formed that answers the question "How are we going to do this?" It is developed by the engineers of the team that will implement the functionality. The technical solution goes through several review processes:
- with teams with which there are intersections in functionality;
- security review of the components that we will touch on in the architecture;
- how we will deploy the result.
After that, the development itself begins. It is important that the code review does not slow down the development, so recently, instead of the obligatory receipt of two code reviews, we introduced personal responsibility at the component level. Now, at the code level, we always know who is responsible for this piece, which greatly facilitates communication during development. Accordingly, as soon as you have made changes to the code, the reviewer is automatically assigned, the owner of this code. If the code is yours, then the review is done by a member of your team.
Why did we introduce personal responsibility? Before, there were several people, “oldies”, who knew how the whole product worked and could check any piece of code. But as the product grew, the capabilities of these people began to be lacking, they could no longer know about everything that was happening in the development.The code review process began to slow down the rest of the process, it was not clear who to go to for code review. Then we began to carry all the necessary competence for specific product blocks to the team that is working on them. So the teams were able to conduct code reviews on their own. At one time, this helped us to speed up a lot.
Performance Review
The company has grades, thanks to which we understand who has what competencies, what grade they correspond to and, most importantly, what everyone needs to do to move on. Performance Review takes place twice a year, helps to capture a picture of where each person is now, and get personalized feedback.
Based on this picture, the team lead forms personal development plans with each team member: the employee himself says where he wants to develop, and the Performance Review highlights his strengths and gaps.
Then, regularly, once every one to two weeks, the team lead and the employee hold 1: 1 meetings, where, among other things, they discuss and track the movement in the planned direction. In a year and a half, on the basis of the results of this movement, there is an increase in grade and salary.
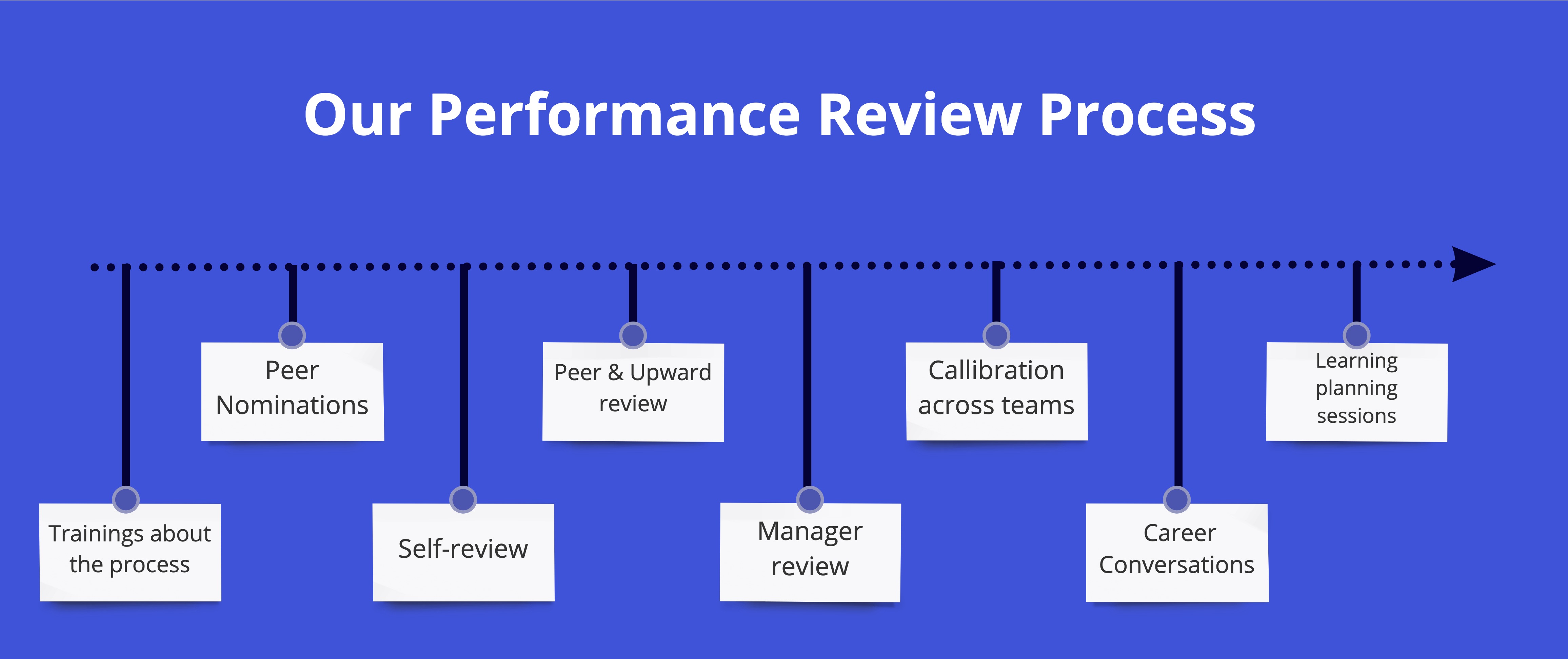
Everything is exactly the same with team leaders, in addition there is external training and external mentoring for them.
Unfortunately, people often don't grow as fast as the company - that's okay. We are ready to invest a lot in training, because the growth of a company directly depends on the growth of employees. We have compensation for external courses, we have recommended courses and mentors. We compensate for compulsory training 100% (for example, English), we try to compensate for the rest 50 to 50, so that there is mutual responsibility for the results.
We rarely go to conferences. We try to choose those that talk about technologies and cases that are currently relevant to us and for which we do not have enough knowledge.
How Hiring Engineers Works
Our recruitment chain is standard for Russia and Europe. In Russia, the hiring funnel is already narrow, so the first interview can be conducted not by a recruiter, but immediately by a hiring manager (usually the team lead of the team in which we hire a person) after the recruiter has processed the resume and weeded out vacancies that are not suitable for the requirements.
I have a feeling that in Russia much fewer engineers are actively looking for work, compared to Europe, because they do not want to take risks. And when many companies entered the risk zone due to isolation, people became even less inclined to take risks and change jobs.
Either way, the hiring chain starts with a screening phone interview with a candidate, which is conducted by a recruiter or hiring manager. The purpose of the screening is to quickly understand how a candidate fits the key requirements of the vacancy.
After screening, a test task, then a technical interview, which includes, among other things, a discussion of the test task. Then - a meeting with the team in which the candidate will work. For us, this is a mandatory step, because it helps first of all to understand the culture fit of the candidate, and not his technical skills.
After all the interviews, we collect feedback from the participants, put up an offer.
To evaluate the test tasks, we use a point system, then we rank the results and thus see the best results. In senior positions, we sometimes cancel a test task if the candidate has a good public repository.
Junior positions
Before moving to remote work, we started working with junior specialists: we hired Juns, graduates, though not very actively. Now we have completely frozen this story, because it is very difficult to onboard them at a remote location, and we have very little experience in this so far. Therefore, we focus on middles with at least 3-4 years of experience.
But even when we worked with the Juns, it was important for us that they could grow to middle ones in a year, so that they learn and adapt very quickly.
High hiring requirements
There is a legend that it is very difficult for us to get a job because of the very high requirements. This is not entirely true.
We are often interviewed by candidates with the position of Team Lead, who, according to our internal criteria, are middle. This happens because, in pursuit of positions, they come to companies that are ready to give positions above their current competencies by several steps, just to hire a person. As a result, the result is a disservice: the person has not yet pumped to the required level, but he already occupies a high position; then he will hardly be able to just leave the company, because he will not be hired for the same position in other companies.
The biggest blocker in hiring is English. Previously, we could hire without knowledge of English, but now this is impossible, and it is impossible to pump it in a few months: from the first weeks of work, an engineer will need to read the documentation in English, correspond in English with colleagues, attend general meetings, most of which are held in English language.
The product is growing, new interesting tasks appear, so we always have a lot of open positions in engineering both in Perm and in Amsterdam.