
In 2020, machine learning on mobile platforms is no longer revolutionary. The integration of smart features into applications has become standard practice.
Fortunately, this does not mean that Apple has stopped developing innovative technologies.
In this post, I will briefly share the news regarding the Core ML platform and other artificial intelligence and machine learning technologies in the Apple ecosystem.
Core ML
Last year, the Core ML platform received a major update. This year, things are much more modest: several new types of layers have been added, support for encryption models and the ability to post model updates to CloudKit.
It looks like the decision was made to drop the version numbers. After last year's update, the platform became known as Core ML 3, but now it uses the name Core ML without a version number. However, the coremltools package has been updated to version 4.
Note . The internal specification of mlmodel is now version 5, which means new models will appear in Netron with the name "Core ML v5".
New layer types in Core ML
The following layers have been added:
Convolution3DLayer, Pooling3DLayer, GlobalPooling3DLayer: — Vision ( Core ML - , ).OneHotLayer: .ClampedReLULayer: ReLU ( ReLU6).- ArgSortLayer: . . , GatherLayer, argsort.
CumSumLayer: .SliceBySizeLayer: Several types of break layers are already available in Core ML. This layer allows you to pass a tensor containing the index from which the partition will start. At the same time, the sector size always remains fixed.
These types of layers can be used starting with version 5, that is, in iOS 14 and macOS 11.0 or later.
Another useful enhancement: 8-bit quantized operations for the following layers:
InnerProductLayerBatchedMatMulLayer
In previous versions of Core ML, weights were quantized, but after loading the model, they were converted back to floating point format. The new feature
int8DynamicQuantizeallows weights to be stored as 8-bit integer values and to perform actual calculations using integers as well.
Calculations using INT8 can be much faster than floating point operations. This provides some advantages to the CPU, but it is uncertain whether the performance of the GPUs will improve, since floating point operations are very efficient for them. Perhaps, in a future Neural Engine update, there will be built-in support for INT8 operations (after all, Apple recently acquired Xnor.ai ...).
In terms of CPUs, Core ML can now also use 16-bit floating point instead of 32-bit on them (on A11 Bionic and above). As we discussed in the video Explore numerical computing in Swift , Float16 is now Swift's first class datatype. With native support for 16-bit floating point operations, Core ML can double the speed!
Note . In Core ML, the Float16 datatype was already used on GPUs and the Neural Engine, so the differences will only be noticeable when used on the CPU.
Other (minor) changes:
UpsampleLayer. BILINEAR ( align-corners). , , .-
ReorganizeDataLayerParamsPIXEL_SHUFFLE. , . , . -
SliceStaticLayerSliceDynamicLayersqueezeMasks, . -
TileLayer, .
There seems to be no change with regards to local learning on devices: still only fully-connected and convolutional layers are supported. The class
MLParameterKeyin CoreML.framework now contains a configuration parameter for the RMSprop optimizer , however this enhancement is not yet included in NeuralNetwork.proto . Perhaps it will be added in the next beta.
The following new types of models have been added :
VisionFeaturePrint.Object- Feature extraction unit optimized for object recognition.
SerializedModel... I don't know exactly what this is for. This is a "private" definition and is "subject to change without notice or liability." Maybe this is how Apple embeds proprietary model formats into mlmodel?
Posting model updates to CloudKit

This new Core ML component allows you to update models separately from the application.
Instead of updating the entire application, you can simply load the deployed instances with the new version of the mlmodel. To be honest, this idea is not new, and some third party vendors have already developed corresponding SDKs. Besides, it is not difficult to create such a package yourself. The advantage of Apple's solution in this case is the ability to host models in the Apple Cloud .
Since an application can have multiple models, the new concept of a collection of models allows you to combine models in one package so that the application can update them all at the same time. Such collections can be created using the CloudKit dashboard.
The application uses the class to download and manage model updates
MLModelCollection. The WWDC video shows the code snippets to accomplish this task.
To prepare a Core ML model for deployment, the Create Model Archive button is now available in Xcode. Clicking on it writes to the .mlarchive file . This version of the model can be submitted to the CloudKit dashboard, and then added to the model collection (mlarchive looks like a regular ZIP archive with the contents of the mlmodelc folder added).
It is very convenient that you can deploy different collections of models to different users. For example, the iPhone camera is different from the iPad camera, so you might need to create two versions of the model and send one to iPhone users and one to iPad users.
You can define customization rules for different classes of devices (iPhone, iPad, TV, Watch), different operating systems and their versions, region codes, language codes and application versions.
There doesn't seem to be a mechanism for dividing users into groups based on other criteria, for example, for A / B testing of model updates or tuning for specific device types - iPhone X or earlier. However, this can still be done manually by creating collections with different names and then explicitly requesting from
MLModelCollectionproviding the appropriate collection by the specified name at runtime.
Deploying a new version of a model is not always fast . At some point, the application detects a new available model and automatically downloads and places it in the application's test environment. However, you are not given the ability to determine where and how this happens: Core ML can download in the background, for example, while you are not using your phone.
Because of this, it is recommended in all cases to add the built-in model to the application as a fallback - for example, a universal model that supports both iPhone and iPad.
While this handy solution allows users not to worry about self-hosting models, keep in mind that your application is now using CloudKit. As I understand it, model collections count towards the total storage quota, and model loads count towards network traffic quotas.
See also:
- Deploying Models and Securing Core ML (WWDC Video)
- Creating and deploying a collection of models
- Retrieving Expanded Model Collections
Note . The new update capability using CloudKit is unfortunately rather difficult to combine with local model personalization. There are no easy ways to transfer the knowledge gained by a personalized model to a new model or somehow combine them.
Encrypting the model
Until now, any attacker could easily steal your Core ML model and integrate it into their own application. Starting with iOS 14 / macOS 11.0, Core ML supports automatic encryption and decryption of models, limiting attackers' access to your mlmodelc folders. Encryption can be used in conjunction with the new deployment via CloudKit or separately.

Xcode encrypts the compiled models ( mlmodelc ), not the original mlmodel. The model is always encrypted on the user's device. And only when the application creates an instance of the model, Core ML automatically decrypts it. The decrypted version of the model only exists in memory and is not stored as a file.
First, you now need an encryption key. The good news is that you don't have to manage this key yourself! The Create Encryption Key button is now available in the Core ML Xcode Model Viewer(Create encryption key). When you click this button, Xcode generates a new encryption key and associates it with your Apple development team account. You don't have to deal with certificate signing requests and physical access keys.
This procedure creates a new .mlmodelkey file . The key is stored on Apple servers, however you also get a local copy to encrypt models in Xcode. You do not need to embed this encryption key into the application, especially since you shouldn't!
To encrypt a Core ML model, you can add a compiler flag
--encrypt YourModel.mlmodelkeyfor that model. And if you plan to deploy the model using CloudKit, you will need to specify the encryption key when creating the model archive.
To decrypt the model after the application has instantiated it, Core ML will need to retrieve the encryption key from Apple's servers over the network . This, of course, requires a network connection. Core ML only performs this procedure the first time you use the model.
If there is no network connection and the encryption key has not been loaded yet, the application cannot instantiate the Core ML model. For this reason, it is recommended to use the new function
YourModel.load(). It contains a final handler that allows you to respond to download errors. For example, the error code modelKeyFetchsays that Core ML was unable to download the encryption key from Apple servers.
This is a very useful feature if you are worried about someone stealing your patented technology. Plus, it's easy to integrate into your application.
See also:
- Deploying Models and Securing Core ML (WWDC Video)
- Generating a model encryption key
- Encrypting the model in the application
Note . According to the information provided in this developer forum post , encrypted models do not support local personalization. Sounds reasonable.
CoreML.framework
The iOS API for working with Core ML models has n't changed much. And yet I would like to note a couple of interesting points.
The only new class here is
MLModelCollectionone that is intended to be deployed with CloudKit.
As you already know, when you add an mlmodel file to your project, Xcode automatically generates a Swift or Objective-C source file that contains classes to make it easier to work with the model. You can notice a couple of changes in these generated classes:
-
init(). ,let model = YourModel().YourModel(configuration:)YourModel.load(), (, ). - ,
CVPixelBufferYourModelInput,CGImageURL-, PNG- JPG-, . ,cropAndScalecropRect. , , .
There is a new warning in the MLModel documentation :
Use an MLModel instance in only one thread or one send queue. To do this, you can serialize method calls to the model, or create a separate instance of the model for each thread and dispatch queue.
Oh, I'm sorry. It seemed to me that inside the MLModel a sequential queue was used to process requests, but I could be wrong - or something changed. In any case, it is best to stick to this recommendation in the future.
The
MLMultiArrayimplemented new initializerinit(concatenating:axis:dataType:), which creates a new multi-array by combining several existing multi-arrays. They must all have the same shape except for the specified axis along which the union is performed. It looks like this feature was added specifically for making predictions from video data, as in the new action classifier models in Create ML. Conveniently!
Note . The enumeration
MLMultiArrayDataTypenow contains static properties .floatand .float64. I don't know exactly what they are for, because this enumeration already has properties .float32and .double. Beta bug?
Xcode Model Viewer
Xcode now displays a lot more information about models, such as class labels and any added custom metadata. It also displays statistics about the types of layers in the model.
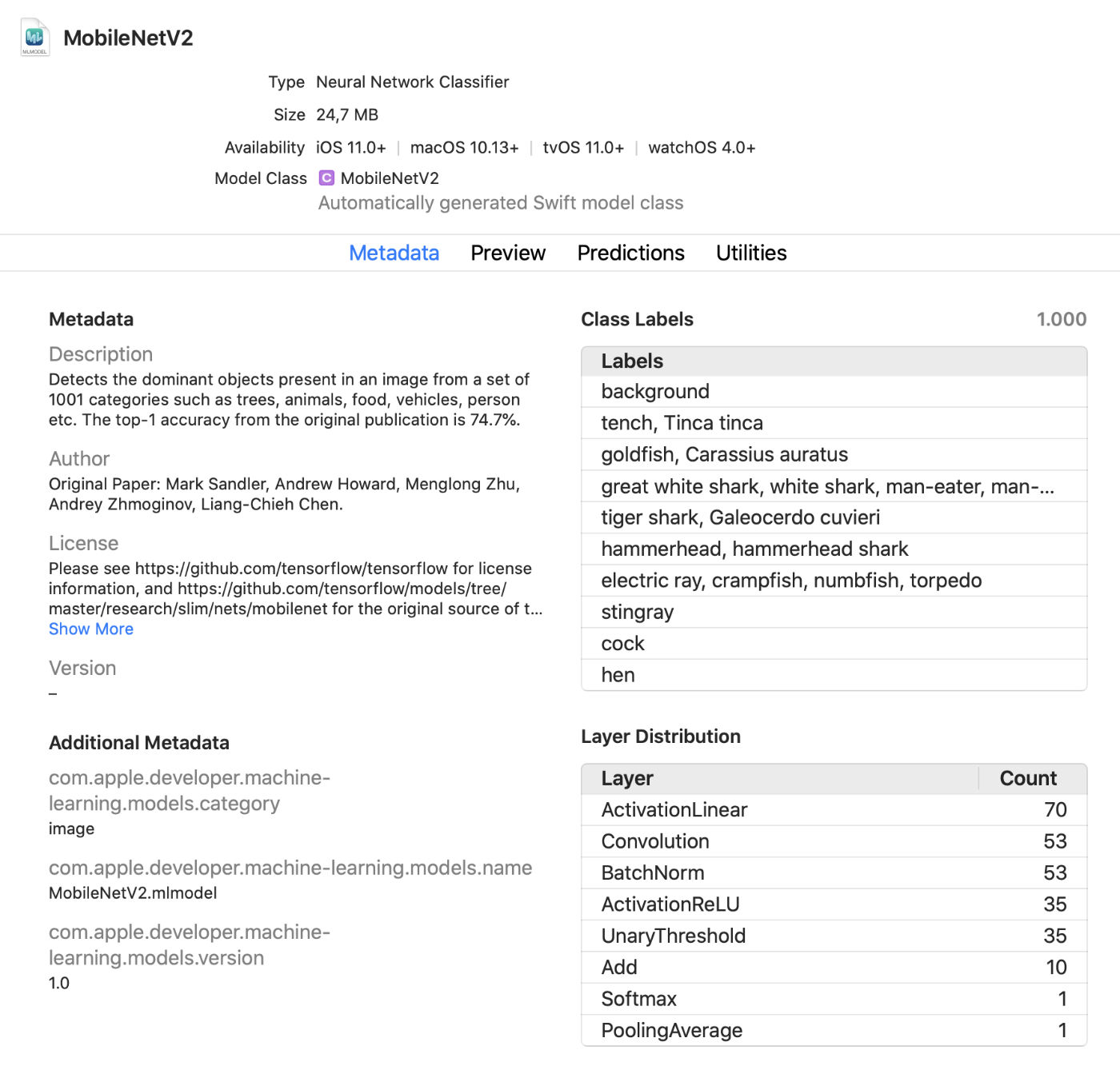
It is a handy live viewer that allows you to make changes to the model in test mode without running the application. You can drag images, videos, or text into this preview window and view model predictions immediately. Great update!
In addition, you can now use Core ML models in an interactive environment . Xcode automatically generates a class for this, which you can use normally. This is another way to interactively test models before adding them to the application.
coremltools 4
Creating your own models for simple projects is convenient with Create ML, but TensorFlow and PyTorch are much more commonly used for training. To use such a model in Core ML, you must first convert it to mlmodel format. This is what the coremltools toolbox is used for.
Great news: the documentation is much better . I recommend that you familiarize yourself with it. Hopefully, the user manual will be updated regularly, because the documentation wasn't always up to date.
Note . Unfortunately, the sample Jupyter notebooks are gone. They are now included in the user manual, but not as notebooks.
The way of transforming models has changed dramatically... Previously used neural network converters are outdated and have been replaced by newer and more flexible versions.
There are three types of converters available today:
- Modern converters for TensorFlow (both 1.x and 2.x), tf.keras and PyTorch. All of these converters are based on the same technologies and use the so-called intermediate model language (MIL). You no longer need to use tfcoreml or onnx-coreml for such models.
- Old converters for Keras 1.x, Caffe and ONNX neural networks. A specialized converter is provided for each of them. Their further development has been discontinued, and only fixes are planned for the future. It is no longer recommended to use ONNX for converting PyTorch models.
- Converters for non-neural network models such as scikit-learn and XGBoost.
A new uniform conversion API is used to transform TensorFlow 1.x, 2.x, PyTorch, or tf.keras models . It is applied as follows:
import coremltools as ct
class_labels = [ "cat", "dog" ]
image_input = ct.ImageType(shape=(1, 224, 224, 3),
bias=[-1, -1, -1],
scale=2/255.)
model = ct.convert(
keras_model,
inputs=[ image_input ],
classifier_config=ct.ClassifierConfig(class_labels)
)
model.save("YourModel.mlmodel")
The function
ct.convert()checks the model file to determine its format and then automatically selects the appropriate converter. The arguments are slightly different from those used before: preprocessing arguments are passed using an object ImageType, classifier labels are passed using an object , ClassifierConfigand so on.
The new transformation API converts the model to an intermediate representation - the so-called. MIL . There are currently converters available to convert TensorFlow 1.x to MIL, TensorFlow 2.x to MIL (including tf.keras) and PyTorch to MIL. If the new deep learning platform gains popularity, it will receive its own converter to MIL.

After converting the model to MIL format, it can be optimized according to general rules, for example, remove unnecessary operations or combine several different layers. The model is then converted from MIL to mlmodel format.
I haven't studied all of this in detail yet, but the new approach gives me hope that coremtools 4 will be able to create more efficient mlmodel files than before - especially for TF 2.x graphs.
In the MIL, I especially like the ability for the converter to handle layers that it hasn't analyzed yet . If your model contains a layer that is not directly supported in Core ML, you may need to subdivide it into simpler MIL operations such as matrix multiplication or other arithmetic operations.
After that, the converter will be able to use the so-called "compound operations" for all layers of this type. This is much easier than adding unsupported operations using custom layers, although it is possible. The documentation provides a good example of using such compound operations.
See also:
- Get models on device using Core ML Converters (WWDC video)
- Coremltools documentation
Other Apple Platforms Using Machine Learning
Several other high-level frameworks in the iOS and macOS SDKs are also used for machine learning tasks. Let's see what's new in this area.
Vision
The Vision computer vision platform has received a number of new functions.
The Vision platform has already used models for recognizing faces, distinctive features and human bodies. The new version adds the following features:
Hand position recognition (
VNDetectHumanHandPoseRequest) Multiple person pose
recognition ( ) It's great that Apple has included pose recognition functions in the OS. Several open source models support this feature, but they are nowhere near as efficient or fast. Commercial solutions are expensive. High-quality pose recognition tools are now available for free! Now, in contrast to viewing static images, more attention is paid to
VNDetectHumanBodyPoseRequest
recognition of objects on video recording both offline and in real time. For convenience, you can use objects
CMSampleBufferdirectly from the camera using request handlers.
Also,
VNImageBasedRequesta subclass has been added to the class VNStatefulRequest, which is responsible for the prompt confirmation of the discovery of the desired object. Unlike the standard class, VNImageBasedRequestit reuses a stateful query that spans multiple frames. This request performs analysis every N frames of the video.
When the target is found, a final handler is called that contains the object
VNObservation, which now has a property timeRangethat indicates the start and stop times for video surveillance.
The class is
VNStatefulRequestnot used directly . It is an abstract base class and is currently subclassed only by query VNDetectTrajectoriesRequestfor path recognition purposes. This allows for the recognition of shapes moving along a parabolic path, such as when throwing or kicking a ball (this seems to be the only built-in video related task at the moment).
For offline video analysis, you can use
VNVideoProcessor.This object adds a URL to a local video and makes one or more Vision requests every N frames or N seconds.
One of the most important traditional computer vision techniques for analyzing video recordings is the optical flow... A query is now available in Vision
VNGenerateOpticalFlowRequestthat calculates the direction in which each pixel moves from one frame to another (dense optical flow). As a result, an object is created VNPixelBufferObservationcontaining a new image, in which each pixel corresponds to two 32-bit or 16-bit floating point values.
In addition, a new query has been added
VNDetectContoursRequestfor recognizing the outlines of objects in an image. Such paths are returned as vector paths. VNGeometryUtilsprovides auxiliary tools for further processing of recognized contours, for example, simplifying them to basic geometric shapes.
And the last innovation in Vision is a new version of the built-in feature extractor VisionFeaturePrint. IOS has already implemented the blockVisionFeaturePrint.Scene , which is especially handy for creating image classifiers. In addition, a new VisionFeaturePrint.Object model is now available, which is optimized for highlighting features used in object recognition.
This model supports 299x299 input images and returns two multi-arrays of the shape (288, 35, 35) and (768, 17, 17), respectively. This is not yet a clear limiting framework, but only "raw" features. For full-fledged object recognition, you need to add logic that converts these features into bounding boxes and class labels. Create ML performs this task if you are training an object recognition tool using training transfer.
See also:
- Explore Computer Vision APIs (WWDC video)
- Detect Body and Hand Pose with Vision (WWDC video)
- Explore the Action & Vision app (WWDC video)
Natural language processing
For natural language processing tasks, you can use the Natural Language platform. She actively uses the models trained in Create ML.
Very few new features have been added this year:
NLTaggerandNLModelnow find multiple tags and predict their validity. Previously, the validity of a tag was determined only by the number of points scored.- Inserting sentences. Word insertion could have been used before, but now
NLEmbeddingsupports whole sentences.
When inserting sentences, a built-in neural network is used to encode the entire sentence into a 512-dimensional vector. This allows you to get the context in which words are used in a sentence (word insertion does not support this feature).
See also:
- Make apps smarter with Natural Language (WWDC video)
Analysis of speech and sounds
There were no changes in this area.
Model training
Train models using Apple APIs first became available in iOS 11.3 and on the Metal Performance Shaders platform. Over the past few years, many new training APIs have been added, and this year was no exception: according to my calculations, we now have as many as 7 different APIs for training neural networks on iOS and macOS platforms!
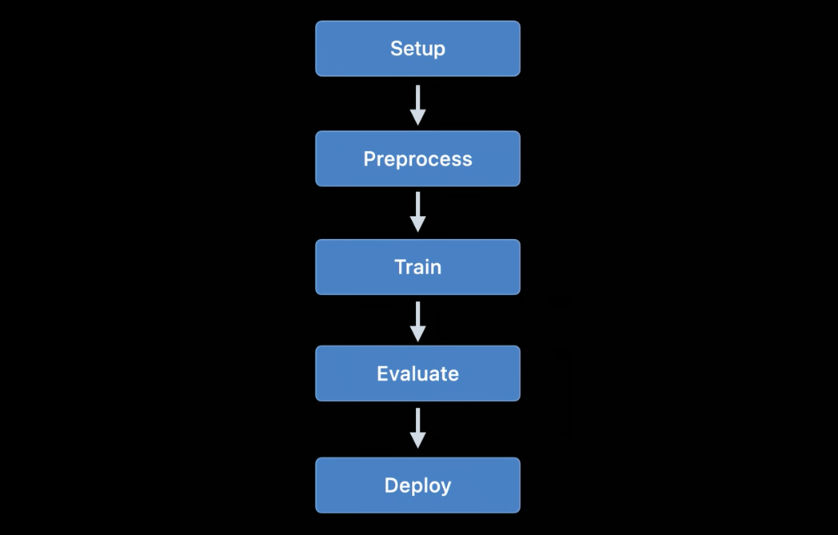
Currently, the following Apple APIs can be used to train machine learning models - in particular neural networks - on iOS and macOS:
- Local learning in Core ML.
- Create ML : This interface may be known to you as an application, but it is also a platform available on macOS.
- Metal Performance Shaders : API for inference and training on a GPU. In fact, these are two different APIs, quite difficult to use if you are new to Metal. In addition, a new Metal Performance Shaders Graph framework is also available and looks set to replace these legacy APIs.
- BNNS : Part of the Accelerate platform. Previously, only inference routines were available in BNNS, but training support has also been added this year.
- ML Compute : A fundamentally new platform that looks very promising.
- Turi Create : This is actually the Python version of Create ML. Recently, its creators have forgotten about it, although support for the platform has not yet been terminated.
Let's take a closer look at the innovations in these APIs.
Local learning in Core ML
In fact, there are no major changes here. Update support could have been added for several more layer types, but I haven't seen any documentation on this yet.
One of the important innovations to be expected in a future beta is the RMSprop optimizer. It is not included in the current beta version.
Create ML
The Create ML platform was initially only available for macOS. It can be run in the Swift Playground so that it can be used to train models with just a couple of lines of code.

Last year, Create ML was transformed into a fairly limited application, and I am pleased to see significant improvements this year. That being said, Create ML remains a platform that can still be used from the code-behind. In fact, the application is just a convenient graphical interface for working with the platform.
In the previous version of Create ML, you could train a model just once. To change something, you had to re-train it from scratch, and this took a lot of time.
The new version of Xcode 12 allowspause training and resume later , save model checkpoints (snapshots), and view previews of model training. We now have significantly more tools to manage the learning process. With this update, Create ML is really useful!
New APIs are also available on the CreateML.framework platform for setting up training sessions, handling model breakpoints, and more. I suppose most people will just use the Create ML application, but it's still nice to see that this feature is now available on the platform.
New Create ML features (both on the platform and in the app):
- Transferring a Style for Pictures and Videos
- Classification of human actions in videos
Let's take a closer look at the new action classification model. It uses the posture recognition model available on the Vision platform. An action classifier is a neural network that takes the form (
window_size, 3, 18) as input , with the first value representing the duration of the video fragment, indicated in the number of frames (usually fragments of about 2 seconds are used), and (3, 18) represent the key points of the pose.
Instead of repeating layers, the neural network uses one-dimensional convolutions. This is most likely a variation of a Space Time Graph Convolutional Network (STGCN) - a type of model specifically designed for time series forecasting. These details shouldn't worry you when using such models in an application. However, I always want to know how it all works.
As for the object recognition models, you can choose to train the entire network based on TinyYOLOv2, or use the new training transfer mode, which uses the new VisionFeaturePrint.Object feature extraction unit . The rest of the model still resembles YOLO and SSD, but thanks to the port, its training will be much faster than training the entire YOLO-based model.
See also:
- Build an Action Classifier with Create ML (WWDC video)
- Build Image and Video Style Transfer models in Create ML (WWDC video)
- Control training in Create ML with Swift ( Create ML Swift) ( WWDC)
Metal Performance Shaders
Metal Performance Shaders (MPS) is a platform based on the performance computing cores of Metal, which is mainly used for image processing, but since 2016 also offers support for neural networks. I've blogged about this a lot already.
Today, most users will choose Core ML over MPS. Of course, Core ML still uses the power of MPS when running models on the GPU. However, MPS can also be used directly, especially if the user plans to conduct training on his own (by the way, a new platform ML Compute is now available, which is recommended to use instead of MPS. Its description is given below).
There are few new features in MPSCNN this year, but several improvements have been made to existing ones.
Added new classes
MPSImageCannyfor edge recognition and MPSImageEDLines for line segment recognition. They are very useful when working on computer vision problems.
A number of other changes are also worth noting:
- A
MPSCNNConvolutionDataSourcenew property has been addedkernelWeightsDataTypethat allows you to use a different data type for the weighting coefficients than that used for convolution. Interestingly, the weights cannot be of the INT8 datatype, even though Core ML allows this datatype to be used for individual layers. - If
kernelWeightsDataTypereturns.float32, convolutional and fully connected layers are performed using 32-bit floating point instead of 16-bit. Previously, only 16-bit was supported. - Loss functions can now use a parameter
reduceAcrossBatch.
You can still use MPSCNN if Metal doesn't scare you. However, a new platform is now available that greatly simplifies the creation and execution of such graphs: MPS Graph.
Note . The WWDC video states that MPSNDArray is a new API, but in fact it came out last year. It is a much more flexible data structure than MPSImage as not all tensors in your model can be images.
New: Metal Performance Shaders Graph

An API has been available in MPS for a long time
MPSNNGraph, but such graphs, in fact, describe only neural networks. However, not all graphs have to be neural networks, and in this case the Metal Performance Shaders Graph platform will be useful.
This new platform can be used to create general purpose GPU compute graphs. The MPS Graph platform does not depend on Metal Performance Shaders, although it was built on its basis.
In the previous version of the deprecated API
MPSNNGraph, it was impossible to add custom operations to the graph. The new platform is much more flexible in this regard. However, you cannot add your own Metal cores. You will need to express all calculations using the existing primitives.
Luckily the compiler
MPSGraphsupports the integration of such primitives into a single computational core, which ensures the most efficient operation on the graphics processor. However, this scheme will not work if it is impossible or difficult to use the provided primitives for some operation. I just don’t understand why Apple, when creating a new API like this, never allows for full custom functions! But nothing can be done.
The new platform
MPSGraphis a fairly simple and logical structure that describes the relationship between operations in a set MPSGraphOperationsusing tensorsMPSGraphTensorscontaining the results of operations. In addition, you can define control dependencies to force individual nodes to start before others. After configuring the graph, it must be executed or transferred to the command buffer, and then wait for the result.
MPSGraphprovides a whole set of instance methods that allow you to add any mathematical or neural network operations to the graph.
In addition, training is supported, which involves adding a loss processing operation to the graph and then performing the gradient operations for all layers in the reverse order - as in the legacy one
MPSNNGraph. For convenience, an automatic differentiation mode is also available, within which it MPSGraphautomatically performs gradient operations for the graph. This saves a lot of effort.
I love that there is now a new, simple and straightforward API for creating such computational graphs. It is much easier to use than previous versions. And you don't need to be a Metal expert to work with it. By the way, it is in many ways similar to TensorFlow 1.x graphs, but at the same time it has a great advantage in terms of optimization, which allows you to minimize costs. And yet, there is not enough opportunity to add arbitrary computational cores to the graph.
See also:
- Build customized ML models with the Metal Performance Shaders Graph (WWDC video)
- Adding Custom Functions to Shader Graph
BNNS (Basic Neural Network Subroutines)
If Core ML is running on a CPU, then it uses BNSS routines that are part of the Accelerate platform. I have already written about BNNS in this article . Most of these BNNS features are now largely discontinued and replaced with a new feature set.
Previously, only fully connected layers, folding, grouping and activation functions were supported. This update adds support to BNNS for n-dimensional arrays, virtually all types of Core ML layers, and backward compatibility versions of such training layers (including layers that currently do not support Core ML training, such as LSTM).
It is also worth noting the presence of a layer of multiple attention.... These layers are often used in Transformer models such as BERT. Another interesting point is tensor convolutions.
You may not be using these BNNS features yourself - just like you would not be using MPS for GPU training. Instead, a higher level ML Compute platform is now available that abstracts the processor used. ML Compute is based on BNNS and MPS, but developers don't have to worry about such little things.
See also: BNNS platform documentation
New: ML Compute
ML Compute is a fundamentally new platform for training neural networks on a CPU or GPU (but apparently not on Neural Engine processors). On a Mac Pro with multiple GPUs, this platform can automatically use them all to train.
I was slightly surprised by the presence of another learning platform, but this platform really simplifies everything, because it allows you to hide low-level components from BNNS and MPS, and in the future, maybe from the Neural Engine.
Best of all, ML Compute is also supported by iOS systems, not just Mac. It's funny that Core ML is not mentioned anywhere. ML Compute seemed to be created completely separately. This framework cannot be used to create Core ML models.
From my own experience, I can say that the task of ML Compute is, first of all, to speed up the work of third-party deep learning tools . You don't have to write any code to work directly with ML Compute. It looks like it is supposed (or the developers are hoping so) that tools like TensorFlow will start using this platform to enable hardware-accelerated learning support on the Mac.
Roughly the same set of layers available as in BNNS. The layers must be added to the graph, and then executed (here, the "busy waiting" mode is not used).
To create a graph, you must first instantiate an object
MLCGraphand add nodes to it. A node is a subclass MLCLayer. Nodes are connected to each other through objectsMLCTensorthat contain the output of other layers.
Interestingly, the operations of division, concatenation, reformatting and transfer are not separate types of layers, but operations directly on the graph.
Excellent debug feature -
summarizedDOTDescription. It returns a DOT description for the graph, from which you can then create a graph using, for example, Graphviz or OmniGraffle (by the way, Keras generates model graphs this way).
ML Compute distinguishes between inference graphs and learning graphs. The latter contains additional nodes, for example, a loss layer and an optimizer.
It looks like there are no ways to create custom layers here, so you only have to get by with the types available in ML Compute.
It's strange that there were no WWDC sessions on this new platform, and the documentation is also quite scattered. Anyway, I will continue to follow its development, because it seems that this is the API that is best suited for training models on Apple devices.
See also: ML Compute Platform Documentation
Conclusion
The Core ML added a number of useful new features, such as automatic updating of models and encryption. The new layer types are really not really needed, because the layers added last year can solve almost any problem. Overall, I like this update.
In coremltools 4 added important improvements - the new converter architecture and built-in support TensorFlow 2 and PyTorch. I'm glad we no longer have to use ONNX to transform PyTorch models.
In Visionadded many new handy features. And I love that Apple has added video analysis functionality. Although machine learning systems can be applied to individual frames of video, in this case, time is not counted. Since mobile devices are fast enough today to perform machine learning based on video data in real time, I believe video will play a more important role in the development of computer vision technologies in the near future.
With regard to training... not sure if we need seven different APIs for this task. I guess Apple just didn't want to retire the outdated interfaces until the new ones were fully refined. Little is known about the ML Compute platform. However, at the time of this writing, only the first beta version has been released. Who knows what lies ahead ...
The lecture picture uses the Freepik icon from flaticon.com.