
From the very beginning, I would like to clarify that in this case Oracle is presented as a collective SQL language. The groupings and how they are applied apply to the entire family of SQL (which is understood here as a structured query language) and is applicable to all queries, with corrections for the syntax of each language.
I will try to briefly and easily explain all the necessary information in two parts. The post will most likely be useful for novice developers. Who cares - welcome to cat.
Part 1: Offerings Order by, Group by, Having
Here we'll talk about sorting - Order by, grouping - Group by, filtering - Having, and query plan. But first things first.
Order by
The Order by operator sorts the output values, i.e. sorts the retrieved value by a specific column. Sorting can also be applied by a column alias that is defined using an operator.
The advantage of Order by is that it can be applied to both numeric and string columns. String columns are usually sorted alphabetically.
Ascending sort is applied by default. If you want to sort the columns in descending order, use the additional DESC operator.
Syntax:
SELECT column1, column2, … (indicates name)
FROM table_name
ORDER BY column1, column2 … ASC | DESC ;
Let's look at everything with examples:
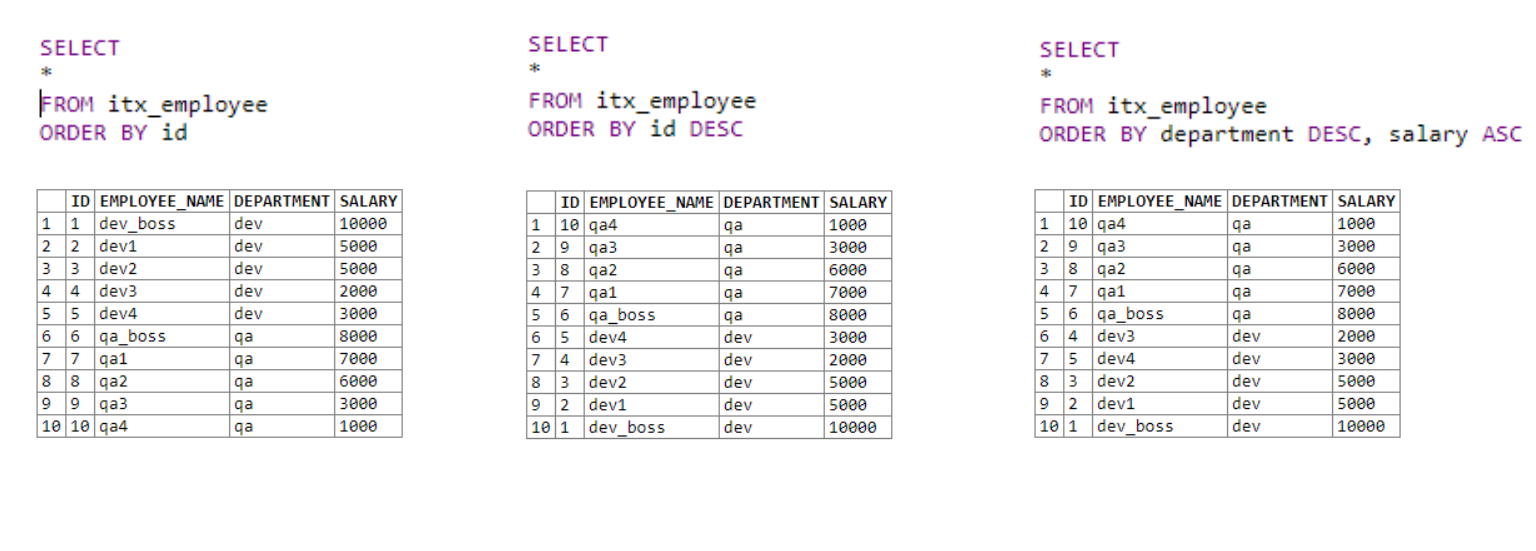
In the first table, we get all the data and sort it in ascending order by the ID column.
In the second, we also get all the data. Sort by the ID column in descending order using the DESC keyword .
The third table uses several sorting fields. First comes the sorting by department. If the first operator is equal for fields with the same department, the second sorting condition is applied; in our case, this is the salary.
It's pretty simple. We can specify more than one sorting condition, which allows us to sort the output lists more intelligently.
Group by
In SQL, the Group by clause collects data retrieved from a database in specific groups. Grouping divides all data into logical sets so that statistical calculations can be performed separately in each group.
This operator is used to combine the results of a selection by one or more columns. After grouping, there will be only one entry for each value used in the column.
The use of the SQL Group by statement is closely related to the use of aggregate functions and the SQL Having statement. An aggregate function in SQL is a function that returns a single value over a set of column values. For example: COUNT (), MIN (), MAX (), AVG (), SUM ()
Syntax:
SELECT column_name (s)
FROM table_name
WHERE condition
GROUP BY column_name (s)
ORDER BY column_name (s);
Group by appears after the WHERE clause in the SELECT query . You can optionally use ORDER BY to sort the output values.
So, based on the table from the previous example, we need to find the maximum salary for employees of each department. The final sample should include the name of the department and the maximum salary.
Solution 1 (without using grouping):
SELECT DISTINCT
ie.department
ie.slary
FROM itx_employee ie
WHERE ie.salary = (
SELECT
max(ie1.salary)
FROM itx_employee ie1
WHERE ie.department = ie1.department
)
Solution 2 (using grouping):
SELECT
department,
max(salary)
FROM itx_employee
GROUP BY department
In the first example, we solve the problem without using grouping, but using a subselect, i.e. put the second in one select. In the second solution, we use grouping.
The second example is shorter and more readable, although it performs the same functions as the first.
How Group by works for us: first, it splits two departments into qa and dev groups. Then he looks for the maximum salary for each of them.
Having
Having is a filtering tool. It indicates the result of performing aggregate functions. Having clause is used in SQL where WHERE cannot be used.
If the WHERE clause defines a predicate for filtering rows, then Having is used after grouping to define a logical predicate that filters the group by the values of the aggregate functions. The clause is necessary to test values obtained using aggregate functions from row groups.
Syntax:
SELECT column_name (s)
FROM table_name
WHERE condition
GROUP BY column_name (s)
HAVING condition
First, we display the departments with an average salary greater than 4000. Then we display the maximum salary using filtering.
Solution 1 (without using GROUP BY and HAVING):
SELECT DISTINCT
ie.department AS "DEPARTMENT",
(
(SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department)
) AS "AVG SALARY"
FROM itx_employee ie
where (SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department) > 4000
Solution 2 (using GROUP BY and HAVING):
SELECT
department,
AVG(salary)
FROM itx_employee
GROUP BY department
HAVING AVG(salary) > 4000
The first example uses two subselects, one to find the maximum salary, and the other to filter the average salary. The second example, again, came out much simpler and more concise.
Request plan
Quite often there are situations when a request takes a long time, consuming significant resources of memory and disks. To understand why a query is running long and inefficiently, we can look at the query plan.
A query plan is the intended execution plan for a query, i.e. how the DBMS will execute it. The DBMS will describe all the operations that will be performed within the subquery. After analyzing everything, we will be able to understand where the weaknesses are in the request and using the query plan we can optimize them.
Execution of any SQL statement in Oracle retrieves the so-called "execution plan". This query execution plan is a description of how Oracle will fetch data according to the SQL statement being executed. A plan is a tree that contains the order of steps and the relationship between them.
The tools that allow you to get the estimated execution plan of a query include Toad, SQL Navigator, PL / SQL Developer , etc. They give a number of indicators of the resource consumption of a query, among which the main ones are: cost - cost of execution and cardinality (or rows ) - cardinality (or quantity lines).
The higher the value of these indicators, the less efficient the query.
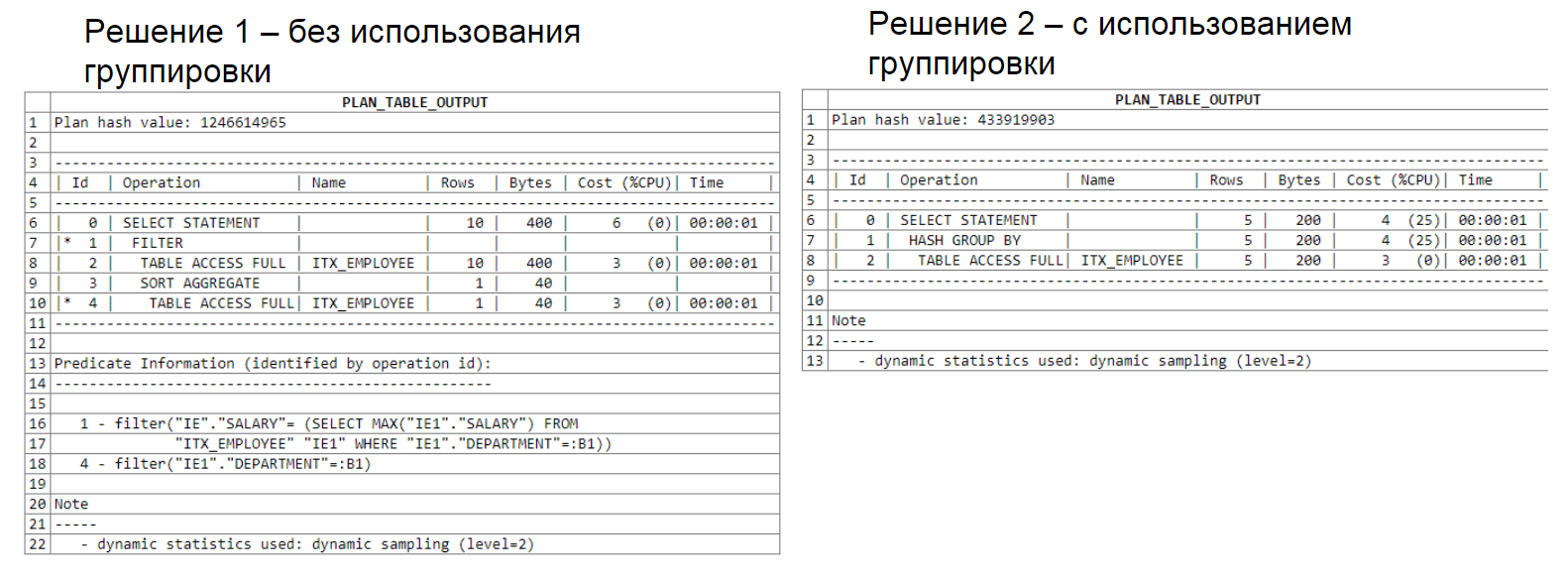
Below you can see the analysis of the query plan. The first solution uses a sub-select, the second uses a grouping. Note that the first solution processed 22 rows, the second processed 15.
Query plan analysis:
Another query plan analysis that uses two subselects:
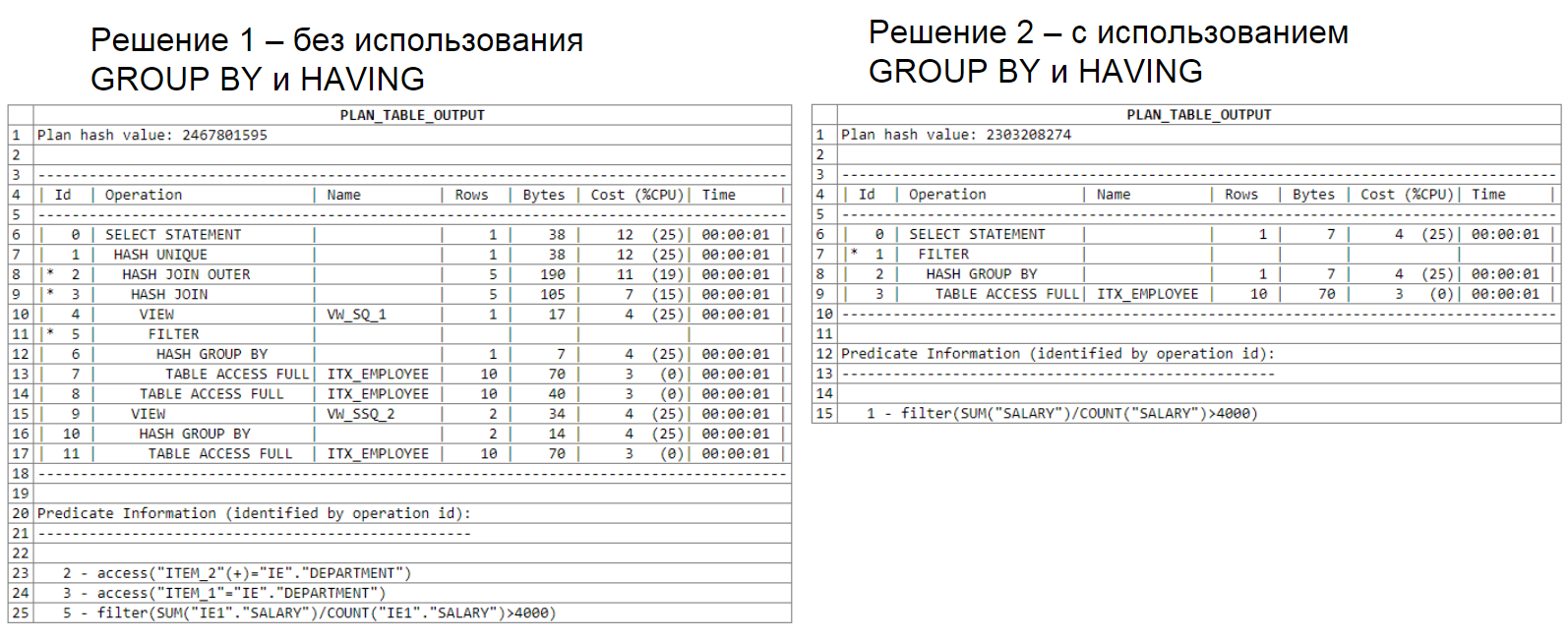
This example is presented as a variant of inefficient use of SQL tools and I do not recommend that you use it in your queries.
All of the above features will make your life easier when writing queries and increase the quality and readability of your code.
Part 2: Window Functions
Window functions date back to Microsoft SQL Server 2005. They perform calculations on a given range of rows within a Select clause. In short, a "window" is a set of lines within which a calculation takes place. "Window" allows you to reduce the data and process it better. This feature allows you to split the entire dataset into windows.
Windowing has a huge advantage. There is no need to form a data set for calculations, which allows you to save all the rows of the set with their unique ID. The result of the window functions is added to the resulting selection in one more field.
Syntax:
SELECT column_name (s)
Aggregate function (column to be calculated)
OVER ([ PARTITION BYcolumn to group]
FROM table_name
[ ORDER BY column to sort]
[ ROWS or RANGE expression to restrict rows within a group])
OVER PARTITION BY is a property for setting the window size. Here you can specify additional information, give service commands, for example, add a line number. The window function syntax fits right into the column selection.
Let's look at everything with an example: another department has been added to our table, now there are 15 rows in the table. We will try to withdraw employees, their salary, as well as the maximum salary of the organization.
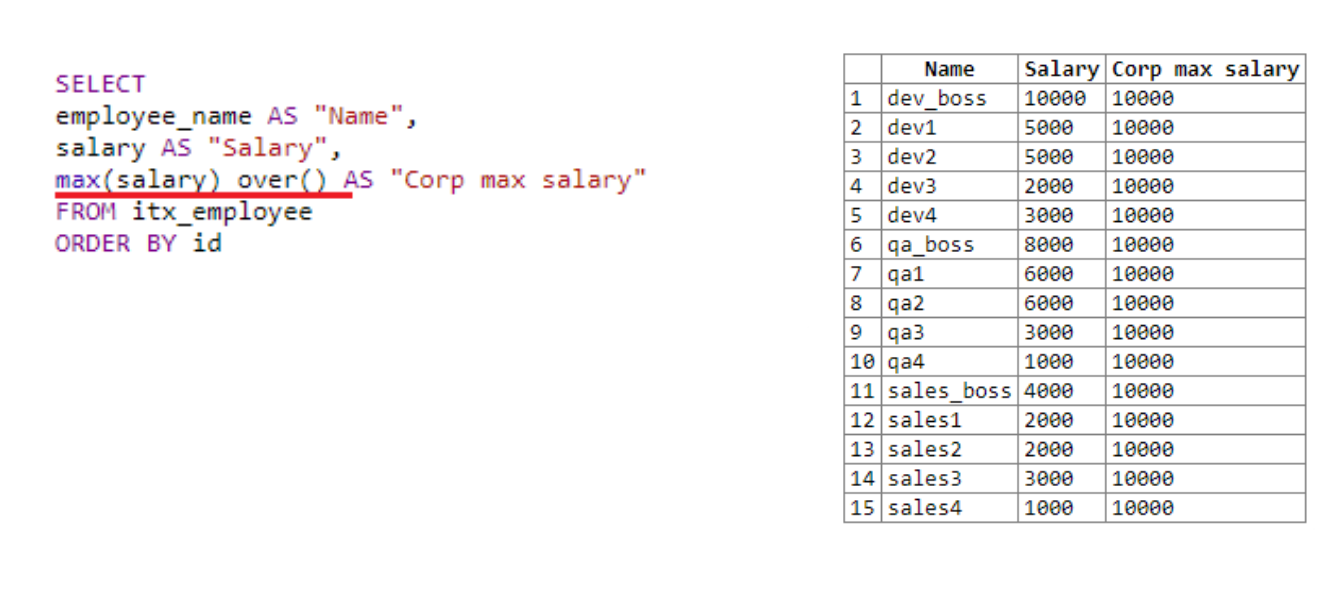
In the first field we take the name, in the second - the salary. Next, we use the window function over ()... We use it to get the maximum salary throughout the organization, since the size of the "window" is not indicated. Over () with empty parentheses applies to the entire selection. Therefore, everywhere the maximum salary is 10,000. The result of the action of the window function is added to each line.
If we remove the mention of the window function from the fourth line of the query, i.e. only max (salary) remains , the request will not work. The maximum salary simply could not be calculated. Since the data would be processed line by line, and at the time of calling max (salary) there would be only one number in the current line, i.e. current employee. This is where you can see the advantage of the window function. At the time of the call, it works with the entire window and with all available data.
Let's look at another example where you need to display the maximum salary of each department:
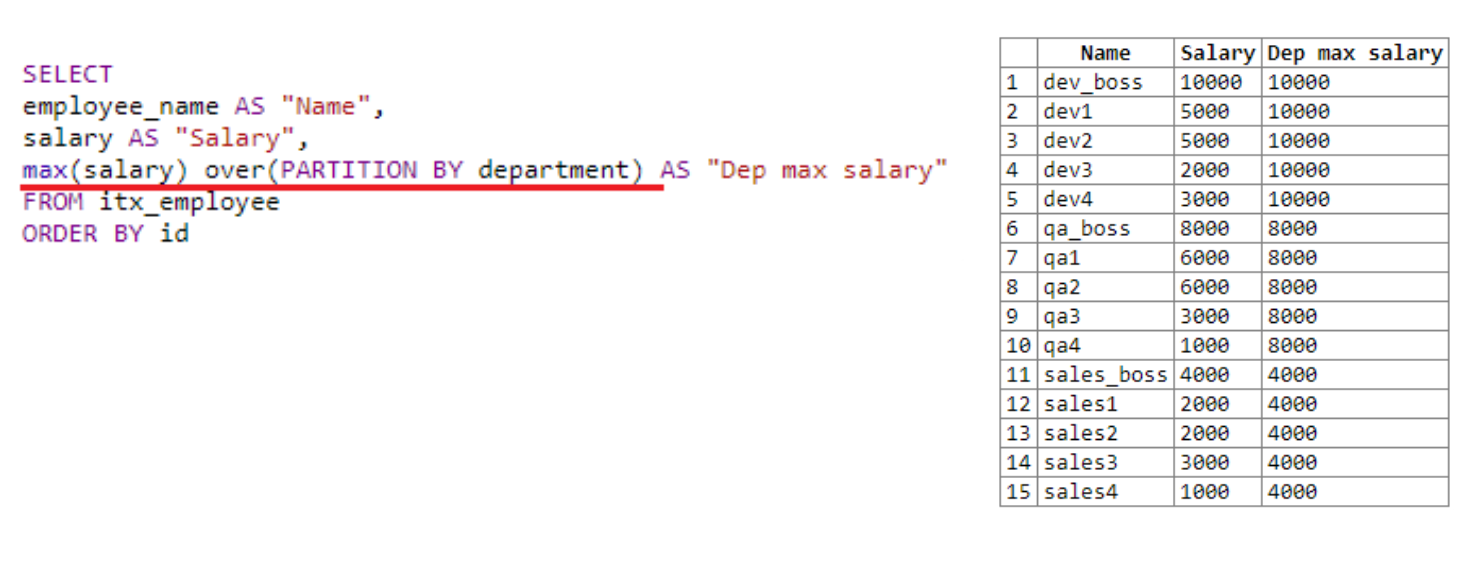
In fact, we set the frame for the "window", dividing it into departments. We use department as a ranking example. We have three departments: dev, qa and sales.
"Window" finds the maximum salary for each department. As a result of the selection, we see that it found the maximum salary first for dev, then for qa, then for sales. As mentioned above, the result of the window function is written to the fetch result of each row.
In the previous example, the parentheses after over were not specified. Here we used PARTITION BY, which allowed us to set the size of our window. Here you can specify some additional information, send service commands, for example, line number.
Conclusion
SQL is not as simple as it seems at first glance. Everything described above is the basic functionality of window functions. With their help, you can “simplify” our requests. But there is a lot more potential hidden in them: there are utility operators (for example ROWS or RANGE) that can be combined to add more functionality to queries.
I hope the post was useful for everyone interested in this topic.