
Photo from the Unsplash website . By Sasha • Stories
Scikit-learn is one of the most widely used Python machine learning libraries. Its simple, standard interface allows data preprocessing, training, optimization, and model evaluation.
This project, designed by David Cournapeau, was born as part of the Google Summer of Code program and was released in 2010. Since its inception, the library has evolved into a rich infrastructure for building machine learning models. New features allow you to solve even more tasks and improve usability. In this article, I will introduce ten of the most interesting features you might not know about.
1. Built-in datasets
In the scikit-learn API, you can find embedded datasets containing both generated and real -world data . You can use them with just one line of code. Such data is extremely useful if you are just learning or just want to quickly test something.
Also, using a special tool, you can generate synthetic data yourself for regression
make_regression(), clustering make_blobs()and classification tasks make_classification().
Each method produces data already broken down into X (features) and Y (target variable) so that they can be used directly to train the model.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. Access to third-party public datasets
If you want to access a variety of public datasets directly through scikit-learn, check out the handy feature that lets you import data directly from openml.org . This site contains over 21,000 different datasets that can be used in machine learning projects.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. Ready classifiers for training baseline models
When creating a machine learning model for a project, it is wise to create a baseline model first. It is a dummy model that always predicts the most common class. This will give you benchmarks for benchmarking your more complex model. In addition, you can be sure of the quality of its work, for example, that it produces more than just a set of randomly selected data.
The scikit-learn library has one
DummyClassifier()for classification problems and DummyRegressor()for working with regression.
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. Own API for visualization
Scikit-learn has a built- in visualization API that allows you to visualize how your model works without importing any other libraries. It provides the following options: dependency plots, error matrix, ROC curves and Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()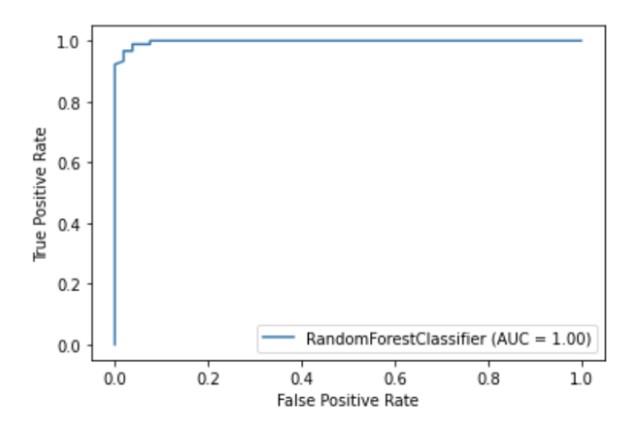
Author's illustration
5. Built-in methods of feature selection
One of the ways to improve the quality of the model is to use only the most useful features in training or remove the least informative ones. This process is called feature selection.
Scikit-learn has a number of methods for performing feature selection , one of which is
SelectPercentile(). This method selects the X-percentile of the most informative features based on the specified statistical method of estimation.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. Pipelines for connecting stages in the process of machine learning
In addition to being able to use a huge list of machine learning algorithms, scikit-learn also provides a number of preprocessing and data transformation functions. To ensure reproducibility and accessibility in the process of machine learning in scikit-learn were created Pipeline , which brings together the different steps and preprocessing stage of training model.
The pipeline stores all stages of the workflow as a single object that can be called by the fit and predict methods. When you run the fit method on a pipeline object, the preprocessing and model training steps are performed automatically.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer to vary preprocessing methods for different features
Many datasets contain different types of features, which require several different stages to preprocess. For example, you might be confronted with a mix of categorical and numeric data, and you might want to scale numeric columns and convert categorical features to numeric using one-hot encoding.
The scikit-learn pipeline is equipped with a ColumnTransformer function , which allows you to easily indicate the most appropriate preprocessing method for specific columns through indexing or by specifying the column names.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. Easily get an HTML image of your pipeline
Pipelines often get quite complex, especially when working with real data. Therefore, it is very convenient that you can use scikit-learn to output an HTML diagram of your pipeline steps.
from sklearn import set_config
set_config(display='diagram')
lr
Author's illustration
9. Plotting function for visualizing decision trees
The function
plot_tree()allows you to create an outline of the steps present in the decision tree model.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. Many third-party libraries that extend scikit-learn functions
There are many third party libraries that are compatible with and extend scikit-learn.
For example, the Category Encoders library , which provides a wider choice of preprocessing methods for categorical features, or the ELI5 library , for more detailed model interpretation.
Both resources can also be accessed directly through the scikit-learn pipeline.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))Thank you for attention!