
Hello, Khabrovites. Today we are going to talk about RxJava. I know that a wagon and a small cart have been written about her, but it seems to me that I have a couple of interesting points worth sharing. First, I'll tell you how we use RxJava together with the VIPER architecture for Android applications, and at the same time look at the "classic" way of using it. After that, let's go over the main features of RxJava and dwell in more detail on how the schedulers work. If you have already stocked up on snacks, then welcome under cat.
An architecture that suits everyone
RxJava is an implementation of the ReactiveX concept and was created by Netflix. Their blog has a series of articles on why they did it and what problems they solved. Links (1, 2) can be found at the end of the article. Netflix used RxJava on the server side (backend) to parallelize the processing of one large request. Although they suggested a way to use RxJava on the backend, this architecture is suitable for writing different types of applications (mobile, desktop, backend, and many others). The Netflix developers used RxJava in the service layer in such a way that each method of the service layer returns an Observable. The point is that elements in an Observable can be delivered synchronously and asynchronously. This allows the method to decide for itself whether to return the value immediately synchronously, (for example,if available in the cache) or first get these values (for example, from a database or remote service) and return them asynchronously. In any case, control will return immediately after calling the method (either with or without data).
/**
* , ,
* , ,
* callback `onNext()`
*/
public Observable<T> getProduct(String name) {
if (productInCache(name)) {
// ,
return Observable.create(observer -> {
observer.onNext(getProductFromCache(name));
observer.onComplete();
});
} else {
//
return Observable.<T>create(observer -> {
try {
//
T product = getProductFromRemoteService(name);
//
observer.onNext(product);
observer.onComplete();
} catch (Exception e) {
observer.onError(e);
}
})
// Observable IO
// /
.subscribeOn(Schedulers.io());
}
}
With this approach, we get one immutable API for the client (in our case, the controller) and different implementations. The client always interacts with the Observable in the same way. It doesn't matter at all whether the values are received synchronously or not. At the same time, API implementations can change from synchronous to asynchronous, without affecting the interaction with the client in any way. With this approach, you can completely not think about how to organize multithreading, and focus on the implementation of business tasks.
The approach is applicable not only in the service layer on the backend, but also in the architectures MVC, MVP, MVVM, etc. For example, for MVP, we can make an Interactor class that will be responsible for receiving and saving data to various sources, and make everything its methods returned Observable. They will be a contract for interaction with Model. This will also enable Presenter to leverage the full power of the operators available in RxJava.
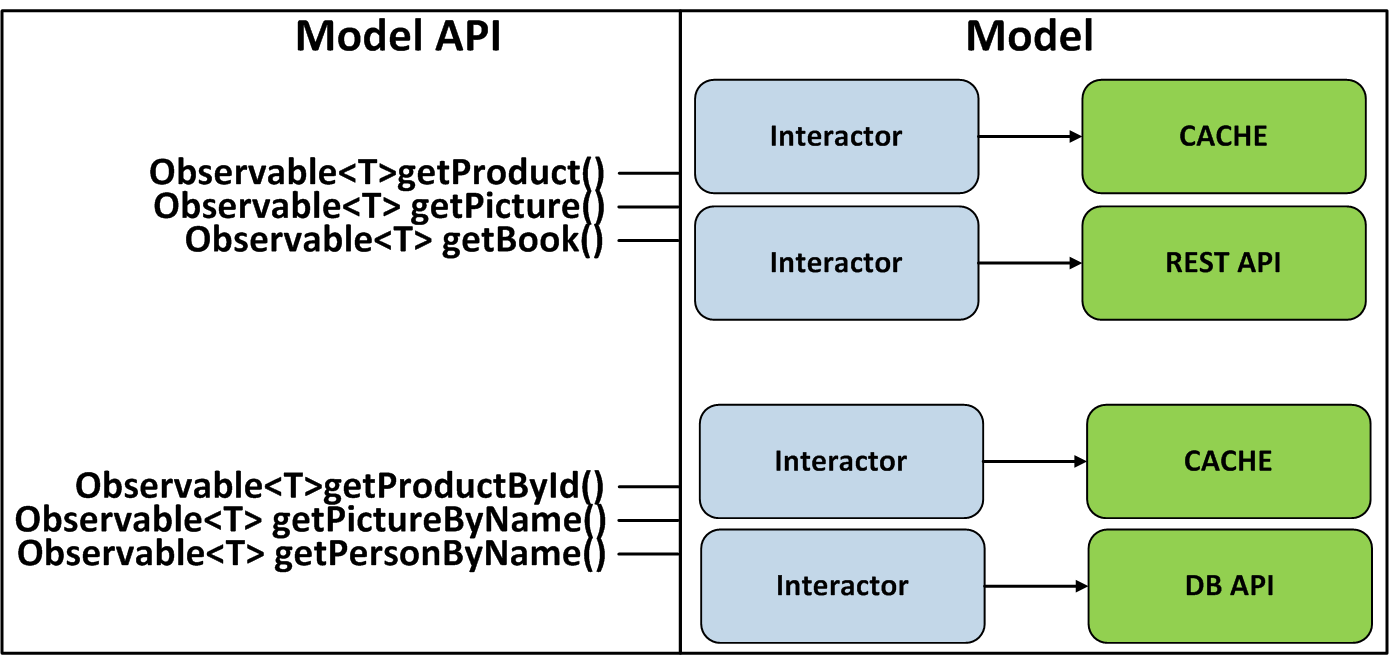
We can go further and make the Presenter a reactive API, but for this we need to correctly implement the unsubscribe mechanism that allows all Views to simultaneously unsubscribe from the Presenter.
Next, let's look at an example of how this approach is applied for the VIPER architecture, which is an enhanced MVP. It is also worth remembering that you cannot make Observable singleton objects, because subscriptions to such Observable will generate memory leaks.
Experience in Android and VIPER
In most of the current and new Android projects, we use the VIPER architecture. I met her when I joined one of the projects in which she was already used. I remember being surprised when I was asked if I was looking towards iOS. “IOS in an Android project?” I thought. Meanwhile, VIPER came to us from the iOS world and in fact is a more structured and modular version of MVP. VIPER is very well written in this article (3).
At first everything seemed fine: correctly divided, not overloaded layers, each layer has its own area of responsibility, clear logic. But after some time, one drawback began to appear, and as the project grew and changed, it even began to interfere.
The fact is that we used Interactor in the same way as our colleagues in our article. Interactor implements a small use case, for example, "download products from the network" or "take a product from the database by id", and performs actions in the workflow. Internally, the Interactor performs operations using an Observable. To "run" the Interactor and get the result, the user implements the ObserverEntity interface along with its onNext, onError, and onComplete methods and passes it along with parameters to the execute (params, ObserverEntity) method.
You've probably already noticed the problem - the structure of the interface. In practice, we rarely need all three methods, often using one or two of them. Because of this, empty methods may appear in your code. Of course, we can mark all methods of the interface as default, but such methods are rather needed to add new functionality to the interfaces. Plus, it's weird to have an interface where all of its methods are optional. We can also, for example, create an abstract class that inherits an interface and override the methods we need. Or, finally, create overloaded versions of the execute (params, ObserverEntity) method that accept one to three functional interfaces. This problem is bad for the readability of the code, but, fortunately, it is quite easy to solve. However, she is not the only one.
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
// ,
//
}
@Override
public void onError(Throwable throwable) {
//
// -
}
@Override
public void onComplete() {
//
// -
}
});
Besides empty methods, there is a more annoying problem. We use Interactor to perform some action, but almost always this action is not the only one. For example, we can take a product from a database, then get reviews and a picture about it, then save it all to another place and finally go to another screen. Here, each action depends on the previous one, and when using Interactors, we get a huge chain of callbacks, which can be very tedious to trace.
private void checkProduct(int id, Locale locale) {
getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale), new ObserverEntity<Product>() {
@Override
public void onNext(Product product) {
getProductInfo(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void getProductInfo(Product product) {
getReviewsByProductIdInteractor.execute(product.getId(), new ObserverEntity<List<Review>>() {
@Override
public void onNext(List<Review> reviews) {
product.setReviews(reviews);
saveProduct(productInfo);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
// -
}
});
getImageForProductInteractor.execute(product.getId(), new ObserverEntity<Image>() {
@Override
public void onNext(Image image) {
product.setImage(image);
saveProduct(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void saveProduct(Product product) {
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
goToSomeScreen();
}
});
}
Well, how do you like this macaroni? At the same time, we have simple business logic and single nesting, but imagine what would happen with more complex code. It also makes it difficult to reuse the method and apply different schedulers for the Interactor.
The solution is surprisingly simple. Do you feel like this approach is trying to mimic the behavior of an Observable, but does it wrong and creates weird constraints itself? As I said before, we got this code from an existing project. When fixing this legacy code, we will use the approach that the guys from Netflix bequeathed to us. Instead of having to implement an ObserverEntity every time, let's make the Interactor just return an Observable.
private Observable<Product> getProductById(int id, Locale locale) {
return getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale));
}
private Observable<Product> getProductInfo(Product product) {
return getReviewsByProductIdInteractor.execute(product.getId())
.map(reviews -> {
product.set(reviews);
return product;
})
.flatMap(product -> {
getImageForProductInteractor.execute(product.getId())
.map(image -> {
product.set(image);
return product;
})
});
}
private Observable<Product> saveProduct(Product product) {
return saveProductInteractor.execute(product);
}
private doAll(int id, Locale locale) {
//
getProductById (id, locale)
//
.flatMap(product -> getProductInfo(product))
//
.flatMap(product -> saveProduct(product))
//
.ignoreElements()
//
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
//
.subscribe(() -> goToSomeScreen(), throwable -> handleError());
}
Voila! So we not only got rid of that cumbersome and unwieldy horror, but also brought the power of RxJava to Presenter.
Concepts at the heart
I quite often saw how they tried to explain the concept of RxJava using functional reactive programming (hereinafter FRP). In fact, it has nothing to do with this library. FRP is more about continuous dynamically changing meanings (behaviors), continuous time, and denotational semantics. At the end of the article, you can find a couple of interesting links (4, 5, 6, 7).
RxJava uses reactive programming and functional programming as its core concepts. Reactive programming can be described as sequential transfer of information from the observed object to the observer object in such a way that the observer object receives it automatically (asynchronously) as this information arises.
Functional programming uses the concept of pure functions, that is, those that do not use or change external state; they are completely dependent on their inputs to get their outputs. The absence of side effects for pure functions makes it possible to use the results of one function as input parameters to another. This makes it possible to compose an unlimited chain of functions.
Tying these two concepts together, along with the GoF Observer and Iterator patterns, allows you to create asynchronous data streams and process them with a huge arsenal of very handy functions. It also makes it possible to use multithreading very simply, and most importantly safely, without thinking about its problems such as synchronization, memory inconsistency, thread overlapping, etc.
Three whales of RxJava
The main three components on which RxJava is built are Observable, operators and schedulers.
Observable in RxJava is responsible for implementing the reactive paradigm. Observables are often referred to as streams because they implement both the concept of data streams and propagation of changes. Observable is a type that achieves a reactive paradigm implementation by combining two patterns from the Gang of Four: Observer and Iterator. Observable adds two missing semantics to Observer, which are in Iterable:
- The ability for the producer to signal the consumer that there is no more data available (the foreach loop on the Iterable ends and just returns; the Observable in this case calls the onCompleate method).
- The ability for the producer to inform the consumer that an error has occurred and the Observable can no longer emit elements (Iterable throws an exception if an error occurs during iteration; Observable calls onError on its observer and exits).
If the Iterable uses the "pull" approach, that is, the consumer requests a value from the producer, and the thread blocks until that value arrives, then the Observable is its "push" equivalent. This means that the producer only sends values to the consumer when they become available.
Observable is just the beginning of RxJava. It allows you to fetch values asynchronously, but the real power comes with "reactive extensions" (hence ReactiveX) - operatorswhich allow you to transform, combine, and create sequences of elements emitted by an Observable. This is where the functional paradigm comes to the fore with its pure functions. Operators make full use of this concept. They allow you to safely work with the sequences of elements that an Observable emits, without fear of side effects, unless of course you create them yourself. Operators allow multithreading without worrying about issues such as thread safety, low-level thread control, synchronization, memory inconsistency errors, thread overlays, etc. Having a large arsenal of functions, you can easily operate with various data. This gives us a very powerful tool. The main thing to remember is that operators modify the items emitted by the Observable, not the Observable itself.Observables never change since they were created. When thinking about threads and operators, it is best to think in charts. If you do not know how to solve the problem, then think, look at the entire list of available operators and think again.
While the concept of reactive programming itself is asynchronous (not to be confused with multithreading), by default all items in an Observable are delivered to the subscriber synchronously, on the same thread on which the subscribe () method was called. To introduce the same asynchrony, you need to either call the onNext (T), onError (Throwable), onComplete () methods yourself in another thread of execution, or use schedulers. Usually everybody analyzes their behavior, so let's take a look at their structure.
Plannersabstract the user from the source of parallelism behind their own API. They guarantee that they will provide specific properties regardless of the underlying concurrency mechanism (implementation), such as Threads, event loop, or Executor. Schedulers use daemon threads. This means that the program will terminate with the termination of the main thread of execution, even if some computation occurs inside the Observable operator.
RxJava has several standard schedulers that are suitable for specific purposes. They all extend the abstract Scheduler class and implement their own logic for managing workers. For example, the ComputationScheduler, at the time of its creation, forms a pool of workers, the number of which is equal to the number of processor threads. The ComputationScheduler then uses workers to perform Runnable tasks. You can pass the Runnable to the scheduler using the scheduleDirect () and schedulePeriodicallyDirect () methods. For both methods, the scheduler takes the next worker from the pool and passes the Runnable to it.
The worker is inside the scheduler and is an entity that executes Runnable objects (tasks) using one of several concurrency schemes. In other words, the scheduler gets the Runnable and passes it to the worker for execution. You can also independently get a worker from the scheduler and transfer one or more Runnable to him, independently of other workers and the scheduler itself. When a worker receives a task, he puts it on the queue. The worker guarantees that tasks are executed sequentially in the order in which they were submitted, but the order can be disturbed by pending tasks. For example, in the ComputationScheduler, the worker is implemented using a single-thread ScheduledExecutorService.
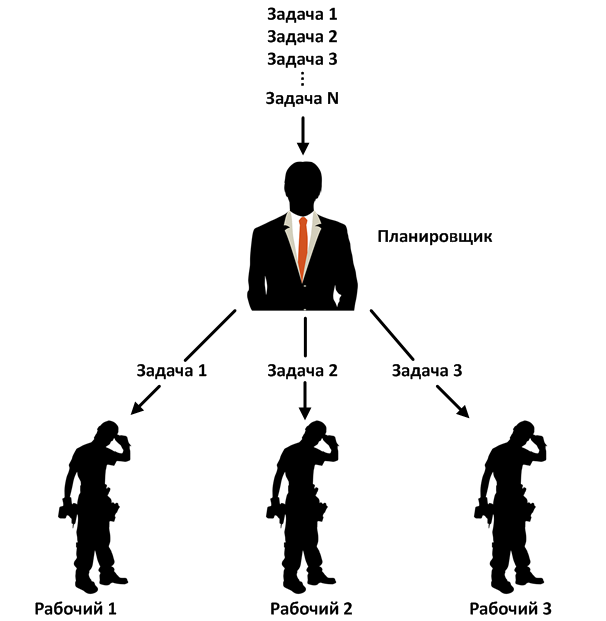
Thus, we have abstract workers that can implement any parallelism scheme. This approach gives many advantages: modularity, flexibility, one API, different implementations. We saw a similar approach in ExecutorService. Plus, we can use schedulers separate from Observable.
Conclusion
RxJava is a very powerful library that can be used in a wide variety of ways across many architectures. The ways to use it are not limited to existing ones, so always try to adapt it for yourself. However, remember about SOLID, DRY and other design principles, and do not forget to share your experience with colleagues. I hope you were able to learn something new and interesting from the article, see you!
- Reasons why Netflix started using ReactiveX
- RxJava Presentation to the Internet Community
- VIPER
- Conal Elliot