I would like to share my experience in implementing fashionable neural networks in our company. It all started when we decided to build our own Service Desk. Why and why your own, you can read my colleague Alexei Volkov (cface) here .
I'll tell you about a recent innovation in the system: a neural network to help the dispatcher of the first line of support. If interested, welcome to cat.

Clarification of the task
A headache for any help desk manager is a quick decision to assign to an incoming customer request. Here are the requests:
Good afternoon.
I understand correctly: in order to share the calendar to a specific user, you need to open access to your calendar on the PC of the user who wants to share the calendar and enter the mail of the user whom he wants to give access to?
According to the regulations, the dispatcher must respond within two minutes: register an application, determine the urgency and appoint a responsible unit. In this case, the dispatcher chooses from 44 divisions of the company.
The dispatchers' instructions describe a solution for most common queries. For example, providing access to a data center is a simple request. But service requests include many tasks: installing software, analyzing a situation or network activity, finding out the details of the billing of solutions, checking all kinds of access. Sometimes it is difficult to understand from the request to which of the responsible to send the question:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
There were situations when the application went to the wrong unit. The request was taken to work and then reassigned to other performers or sent back to the dispatcher. This increased the speed of the solution. The time for resolving requests is written in the agreement with the client (SLA), and we are responsible for meeting the deadlines.
Inside the system, we decided to create an assistant for dispatchers. The main goal was to add prompts that help the employee make a decision on the application faster.
Most of all, I did not want to succumb to the newfangled trend and put the chatbot on the first line of support. If you have ever tried to write to such technical support (who already does not sin with this), you understand what I mean.
Firstly, he understands you very poorly and does not answer at all for atypical requests, and secondly, it is very difficult to reach a living person.
In general, we definitely did not plan to replace dispatchers with chat bots, since we want customers to still communicate with a live person.
At first, I thought of getting off cheap and cheerful and tried the keyword approach. We compiled a dictionary of keywords manually, but this was not enough. The solution coped only with simple applications, with which there were no problems.
During the work of our Service Desk, we have accumulated a solid history of requests, on the basis of which we can recognize similar incoming requests and assign them immediately to the correct executors. Armed with Google and some time, I decided to dive deeper into my options.
Learning theory
It turned out that my task is a classical classification task. At the input, the algorithm receives the primary text of the application, at the output it assigns it to one of the previously known classes - that is, the divisions of the company.
There were a great many solutions. This is a "neural network", and "naive Bayesian classifier", "nearest neighbors", "logistic regression", "decision tree", "boosting" and many, many other options.
There would be no time to try all the techniques. Therefore, I settled on neural networks (I have long wanted to try working with them). As it turned out later, this choice was fully justified.
So, I started my dive into neural networks from here . Studied learning algorithmsneural networks: with a teacher (supervised learning), without a teacher (unsupervised learning), with partial involvement of a teacher (semi-supervised learning) or “reinforcement learning”.
As part of my task, the teaching method with a teacher came up. There is more than enough data for training: over 100k of solved applications.
Choice of implementation
I chose the Encog Machine Learning Framework library for implementation . It comes with accessible and understandable documentation with examples . In addition, implementation for Java, which is close to me.
Briefly, the mechanics of work looks like this:
- The framework of the neural network is pre-configured: several layers of neurons connected by synapse connections.

- A set of training data with a predetermined result is loaded into memory.
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
I tried various examples of the framework, I realized that the library copes with numbers at the input with a bang. So, the example with the definition of a class of irises by the size of the bowl and petals ( Fisher's Irises ) worked well .
But I have some text. This means that the letters must somehow be turned into numbers. So I moved on to the first preparatory stage - "vectorization".
The first option for vectorization: by letter
The easiest way to turn text into numbers is to take the alphabet on the first layer of the neural network. It turns out 33 letters-neurons: ABVGDEOZHZYKLMNOPRSTUFHTSCHSHSCHYEYUYA.
Each is assigned a number: the presence of a letter in a word is taken as one, and the absence is considered zero.
Then the word "hello" in this encoding will have a vector:

Such a vector can already be given to the neural network for training. After all, this number is 001001000100000011010000000000000 = 1216454656 Going deeper
into the theory, I realized that there is no particular point in analyzing letters. They do not carry any semantic meaning. For example, the letter "A" will be in every text of the proposal. Consider that this neuron is always on and will not have any effect on the result. Like all other vowels. And in the text of the application there will be most of the letters of the alphabet. This option is not suitable.
The second variant of vectorization: by dictionary
And if you take not letters, but words? Let's say Dahl's explanatory dictionary. And to count as 1 already the presence of a word in the text, and the absence - as 0.
But here I ran into the number of words. The vector will turn out to be very large. A neuron with 200k input neurons will take forever and will want a lot of memory and CPU time. You have to make your own dictionary. In addition, there is an IT-specificity in the texts that Vladimir Ivanovich Dal did not know.
I turned to theory again. To shorten the vocabulary when processing texts, use the mechanisms of N-grams - a sequence of N elements.
The idea is to split the input text into some segments, compose a dictionary from them, and feed the neural network the presence or absence of a phrase in the original text as 1 or 0. That is, instead of a letter, as in the case of the alphabet, not just a letter, but a whole phrase will be taken as 0 or 1.
The most popular are unigrams, bigrams and trigrams. Using the phrase "Welcome to DataLine" as an example, I will tell you about each of the methods.
- Unigram - the text is split into the words: "good", "welcome", "v", "DataLine".
- Bigram - we break it into pairs of words: "welcome", "welcome to", "to DataLine".
- Trigram - similarly, 3 words each: "welcome to", "welcome to DataLine".
- N-grams - you get the idea. How many N, so many words in a row.
- N-. , . 4- N- : «»,« », «», «» . . .
I decided to limit myself to the unigram. But not just a unigram - the words still turned out to be too much.
The algorithm "Porter's Stemmer" came to the rescue , which was used to unify words back in 1980.
The essence of the algorithm: remove suffixes and endings from the word, leaving only the basic semantic part. For example, the words “important”, “important”, “important”, “important”, “important”, “important” are brought to the base “important”. That is, instead of 6 words, there will be one in the dictionary. And this is a significant reduction.
Additionally, I removed all numbers, punctuation marks, prepositions and rare words from the dictionary, so as not to create "noise". As a result, for 100k texts we got a dictionary of 3k words. You can already work with this.
Neural network training
So I already have:
- Dictionary of 3k words.
- Vectorized dictionary representation.
- The sizes of the input and output layers of the neural network. According to the theory, a dictionary is provided on the first layer (input), and the final layer (output) is the number of solution classes. I have 44 of them - by the number of divisions of the company.
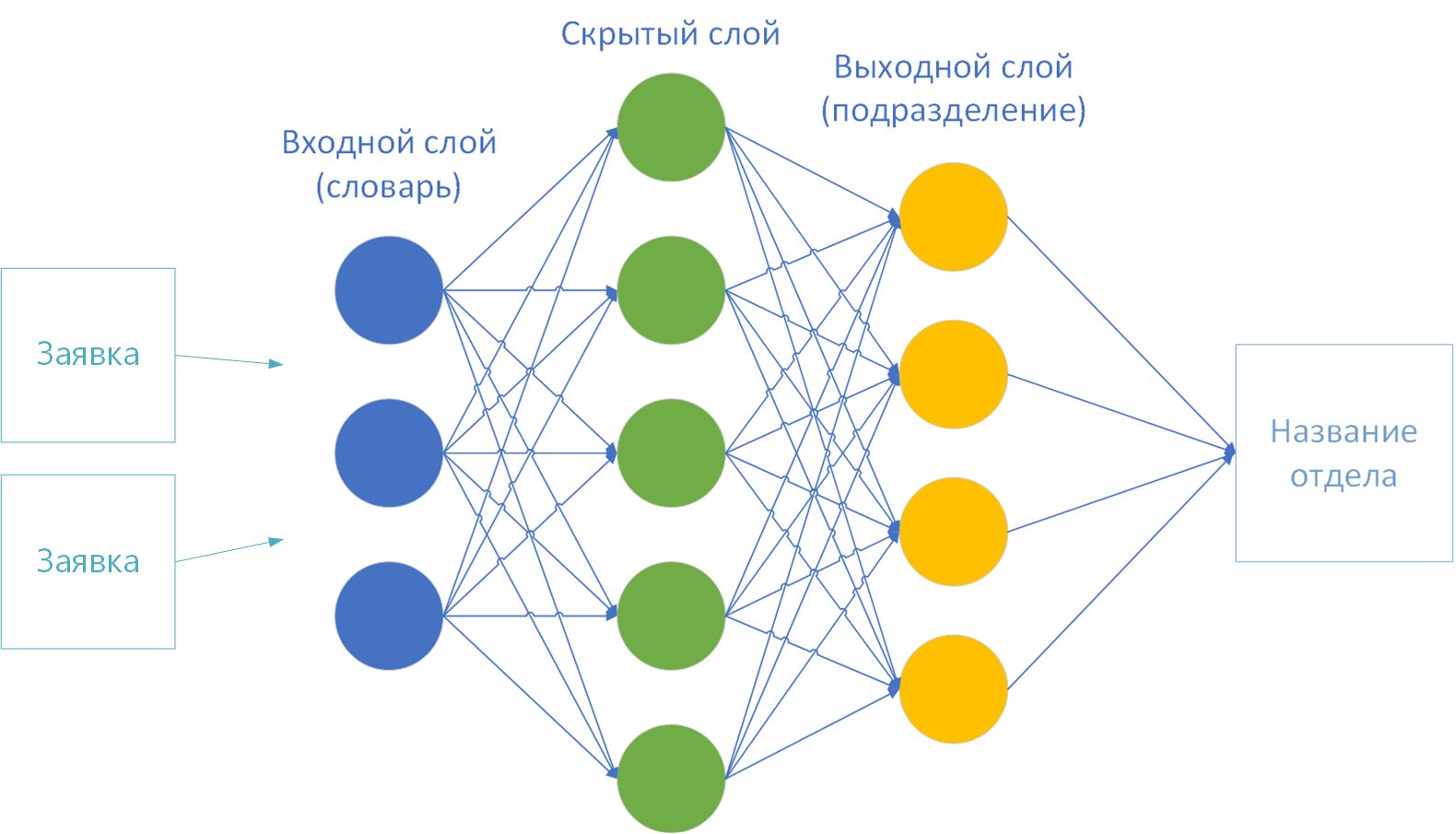
To train a neural network, there is very little left to choose:
- Teaching method.
- Activation function.
- The number of hidden layers.
How I selected the parameters . The parameters are always selected empirically for each specific task. This is the longest and most tedious process, as it requires a lot of experimentation.
So, I took a reference sample of 11k applications and did the calculation of a neural network with various parameters:
- At 10k I trained a neural network.
- At 1k I checked the already trained network.
That is, at 10k we build a vocabulary and learn. And then we show the trained neural network 1k unknown texts. As a result, the percentage of error is obtained: the ratio of guessed units to the total number of texts.
As a result, I achieved an accuracy of about 70% on unknown data.
Empirically, I found out that training can continue indefinitely if the wrong parameters are chosen. A couple of times, the neuron went into an endless calculation cycle and hung the working machine for the night. To prevent this, for myself, I accepted the limit of 100 iterations or until the network error stops decreasing.
Here are the parameters:
Teaching method . Encog offers several options to choose from: Backpropagation, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
These are different ways of determining the weights at synapses. Some of the methods work faster, some are more precise, it is better to read more in the documentation. Resilient Propagation worked well for me .
Activation function . It is needed to determine the value of the neuron at the output, depending on the result of the weighted sum of the inputs and the threshold value.
I chose from 16 options . I didn't have enough time to check all the functions. Therefore, I considered the most popular: sigmoid and hyperbolic tangent in various implementations.
In the end, I settled on ActivationSigmoid .
Number of hidden layers... In theory, the more hidden layers, the longer and more difficult the calculation. I started with one layer: the calculation was quick, but the result was inaccurate. I settled on two hidden layers. With three layers, it was considered much longer, and the result did not differ much from a two-layer one.
On this I finished the experiments. You can prepare the tool for production.
To production!
Further a matter of technology.
- I screwed up Spark so that I could communicate with the neuron via REST.
- Taught to save the calculation results to a file. Not every time to recalculate when restarting the service.
- Added the ability to read actual data for training directly from the Service Desk. Previously trained on csv files.
- Added the ability to recalculate the neural network to attach the recalculation to the scheduler.
- Collected everything in a thick jar.
- I asked my colleagues for a server more powerful than a development machine.
- Zadeploil and zashedulil recount once a week.
- I screwed the button to the right place in the Service Desk and wrote to my colleagues how to use this miracle.
- I collected statistics on what the neuron chooses and what the person chose (statistics below).
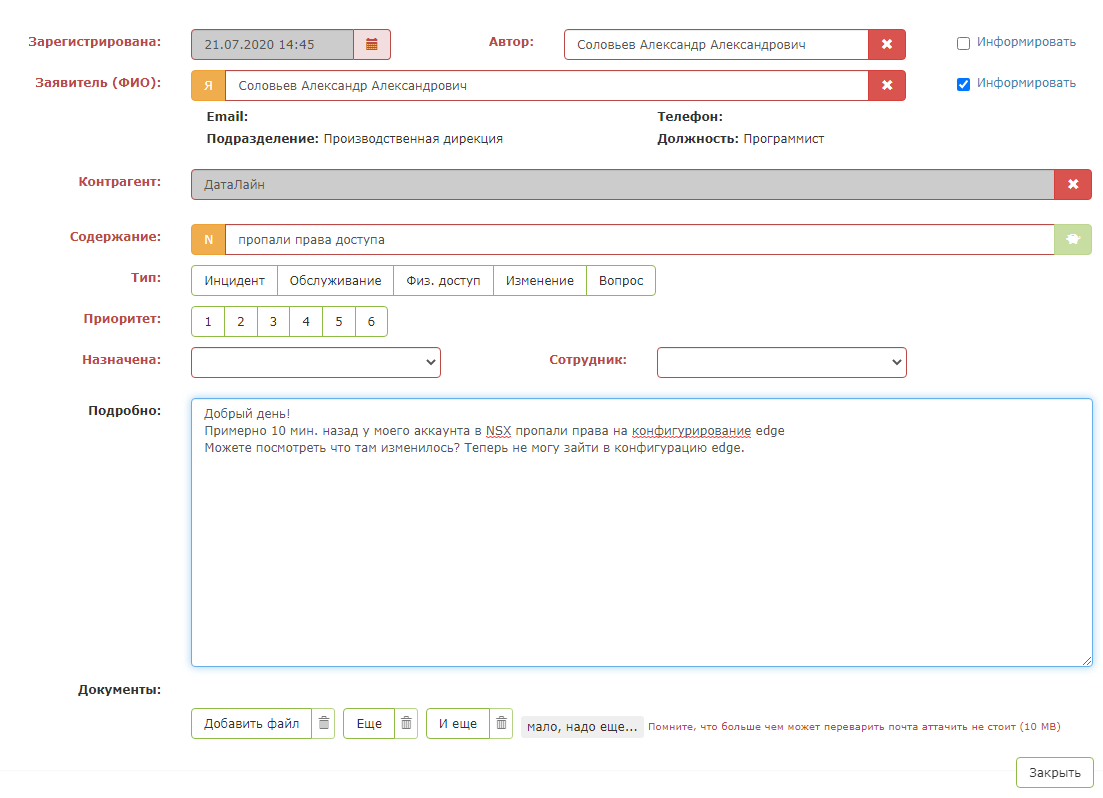
This is how a test application looks like:
But as soon as you press the "magic green button", the magic happens: the fields of the card are filled. It remains for the dispatcher to make sure that the system prompts correctly and save the request.
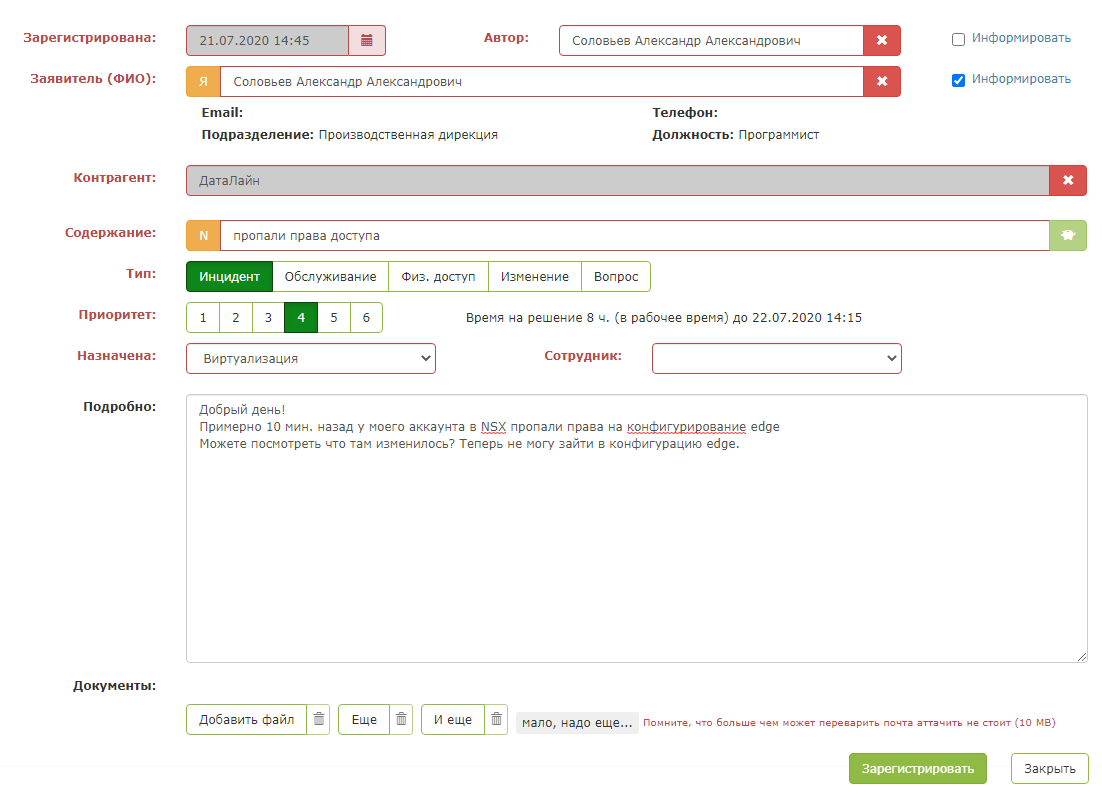
The result is such an intelligent assistant for the dispatcher.
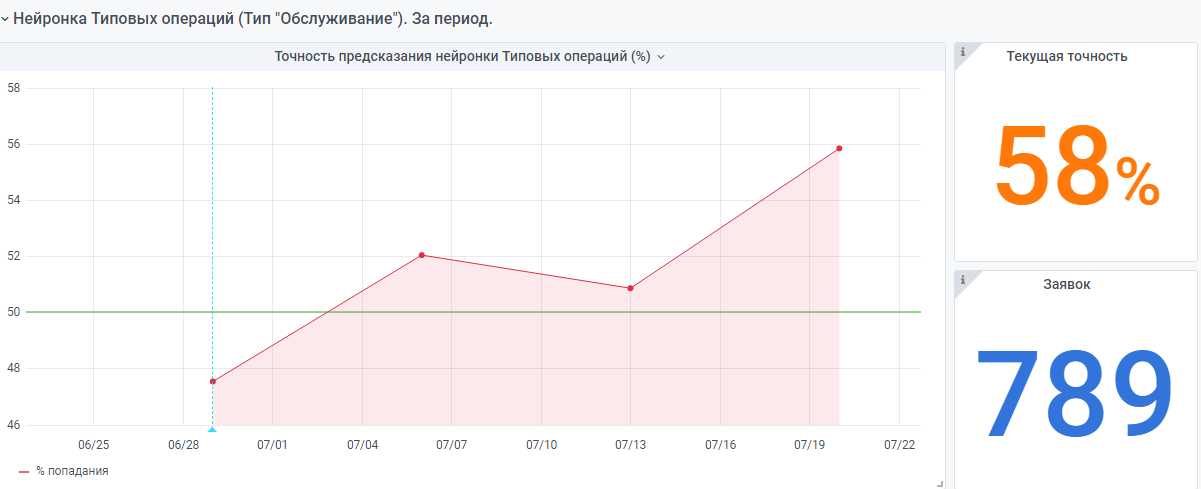
For example, statistics from the beginning of the year.
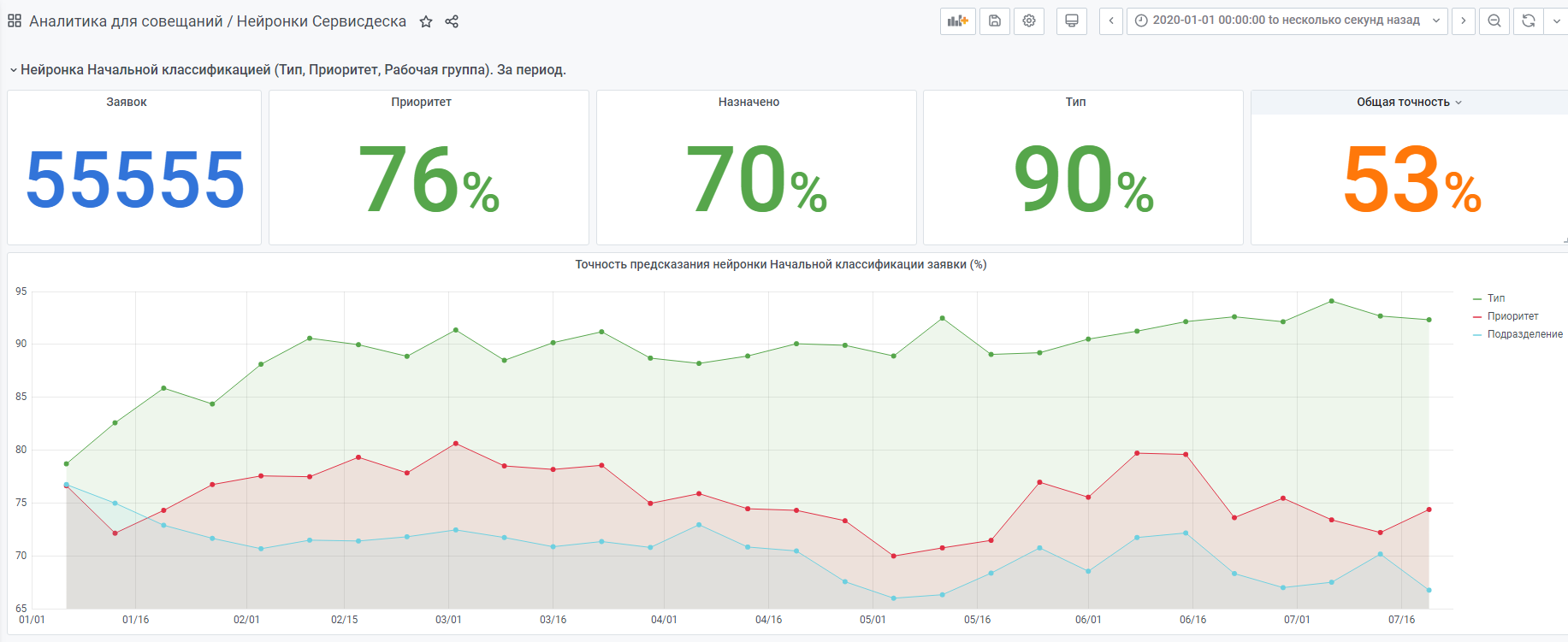
There is also a "very young" neural network made according to the same principle. But there is still little data, she is still gaining experience.
I will be glad if my experience will help someone in creating their own neural network.
If you have any questions, I will be happy to answer.