
Data editor
Large value editor
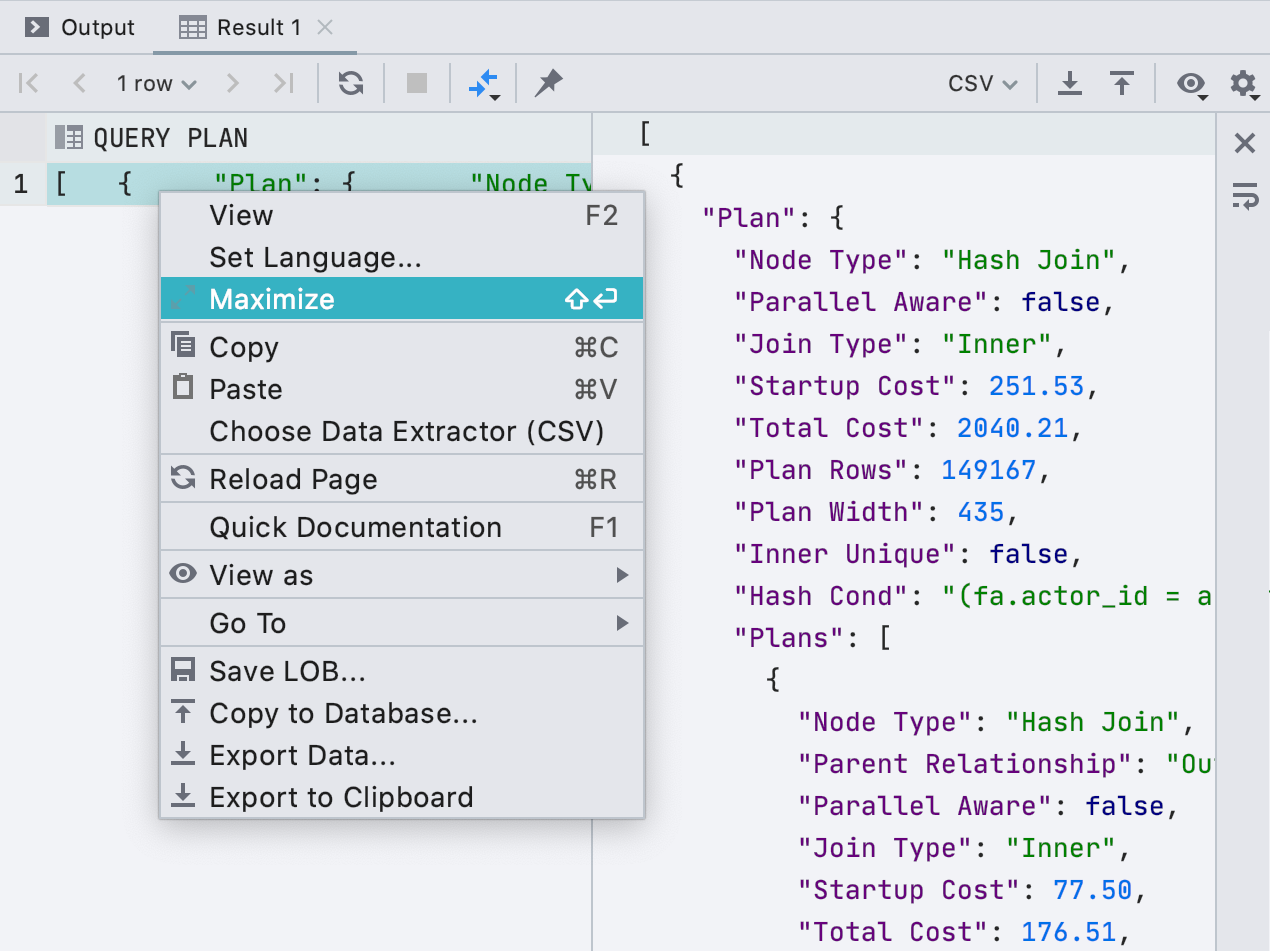
We have attached a full editor to the cells. If a cell contains a long value, such as XML or JSON, it is convenient to open it in a separate panel. To do this, click
Maximize in the context menu.
Previewing a Query While Editing
Now, before writing new values in the data editor, you can see which query will be executed. To do this, click the DML button on the toolbar.
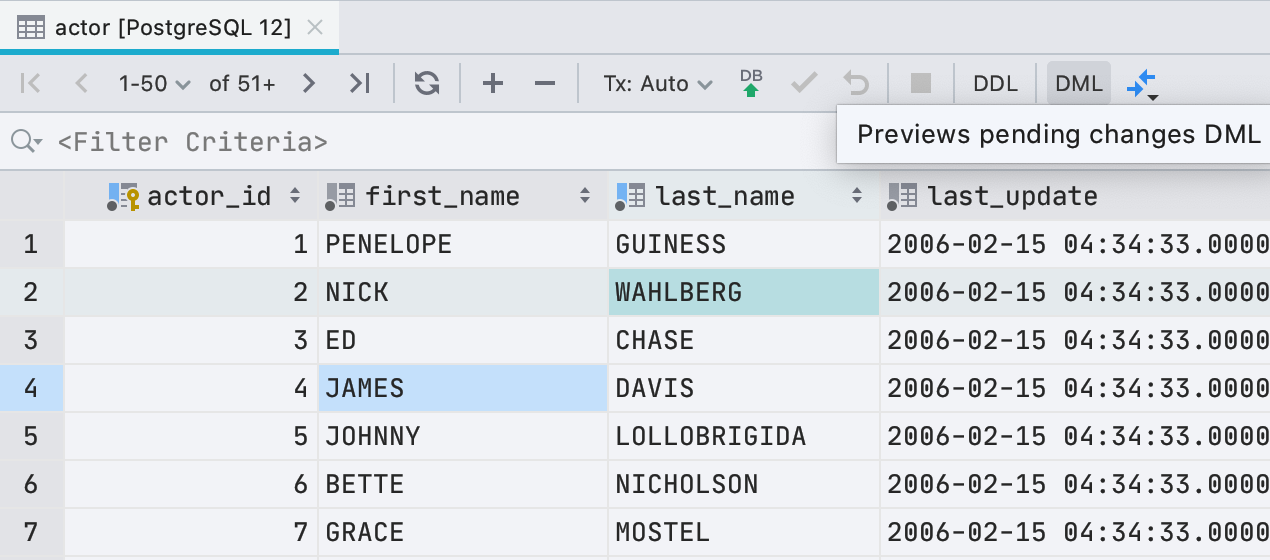
To be honest, it's not just the query that we run because for editing data DataGrip uses JDBC-driver. But in most cases, what we show will coincide with what actually starts.
New display of logical cells
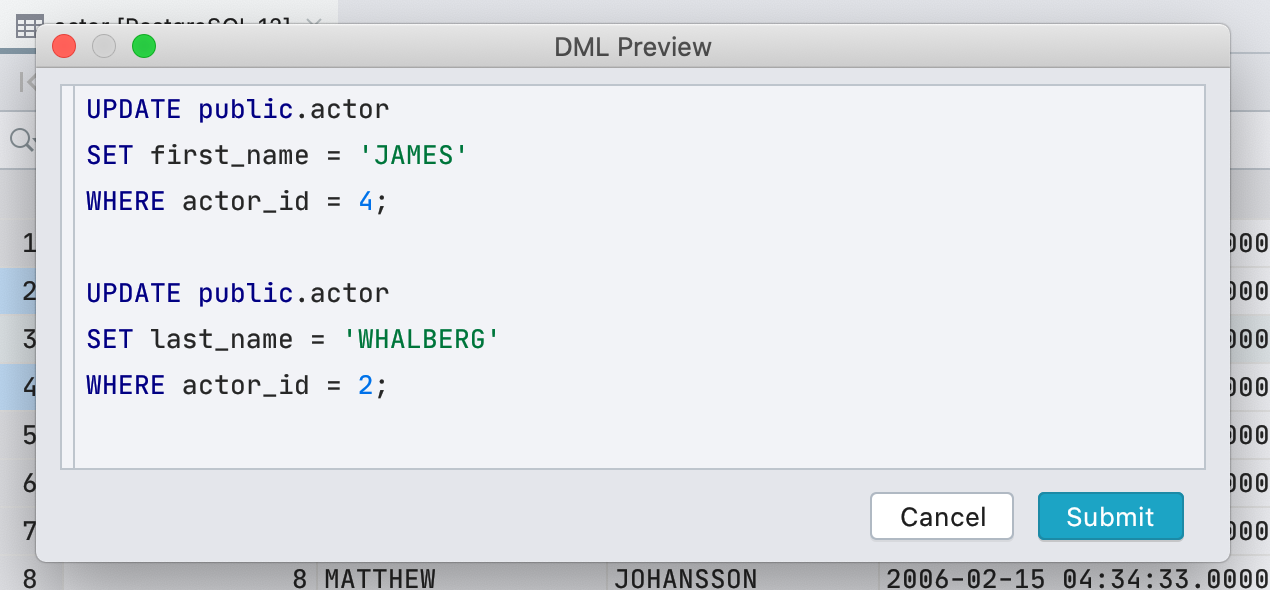
Previously, we used a checkbox to display cells with the boolean type . This was inconvenient: not everyone understood how to distinguish null from false , and default, computed and null were displayed the same at all. We decided not to be smart and write the meaning in text.
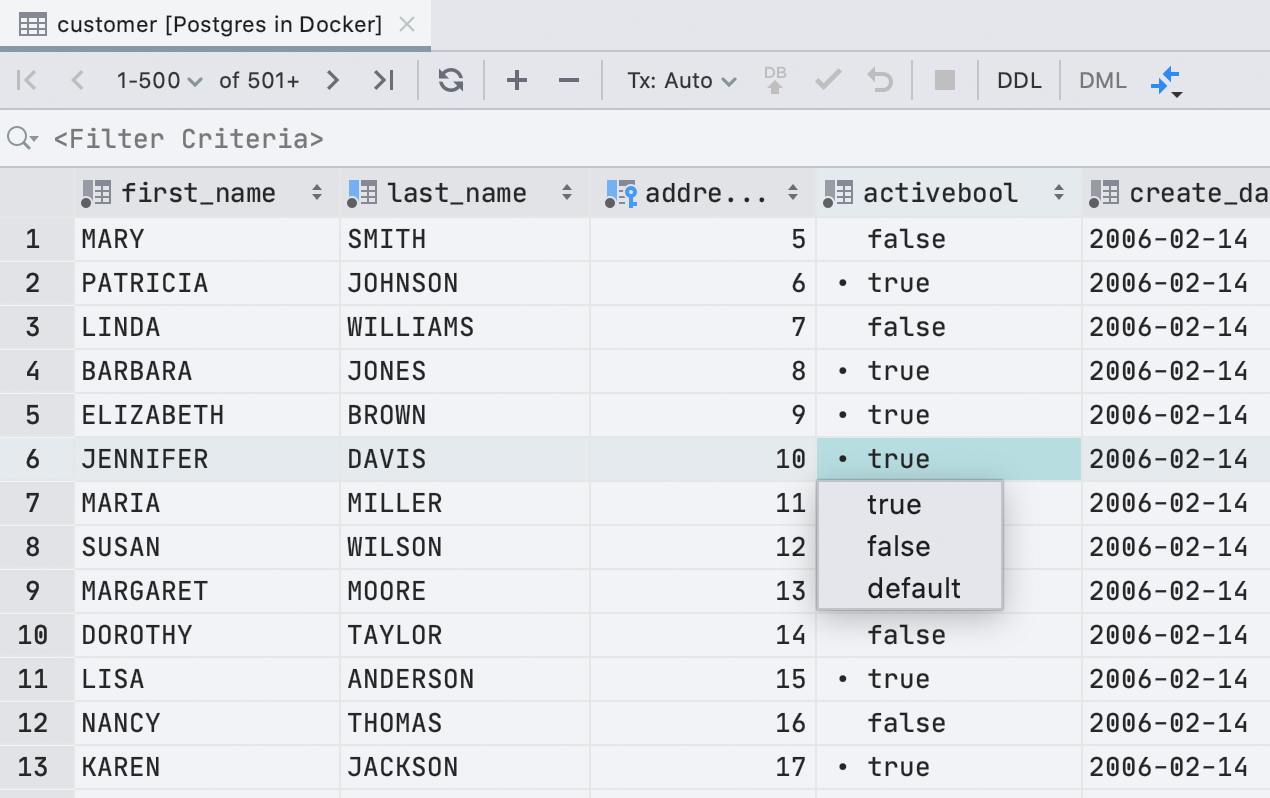
The checkbox had one plus: it is easy to visually find true values . In the new interface, the point performs this task.
We're lucky: in English, all possible meanings start with different letters. Therefore, to edit, just press the first letter of the value you need: f, t, d, n, g or c.If we print something else, we will show a drop-down list. And the space bar toggles between the available values.
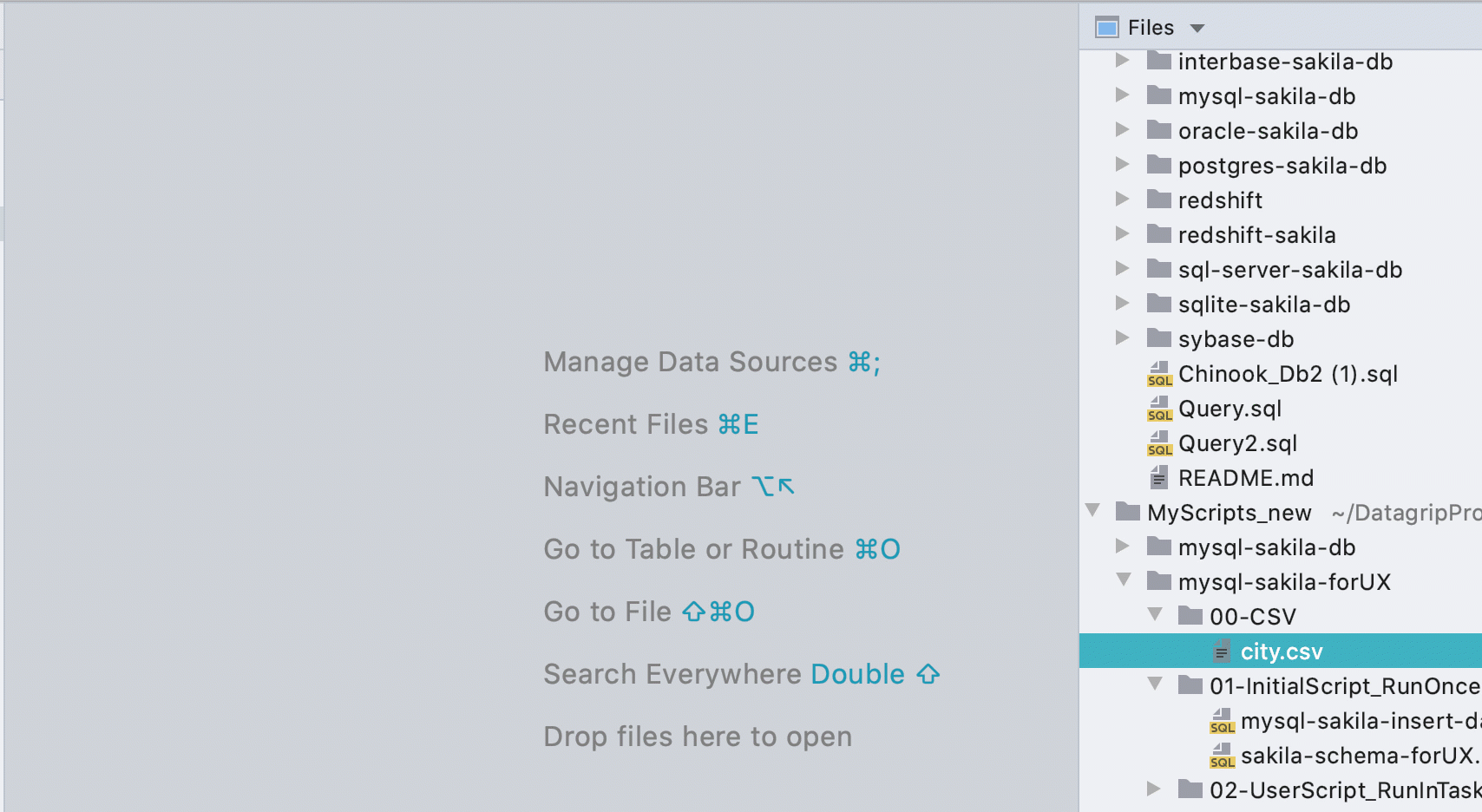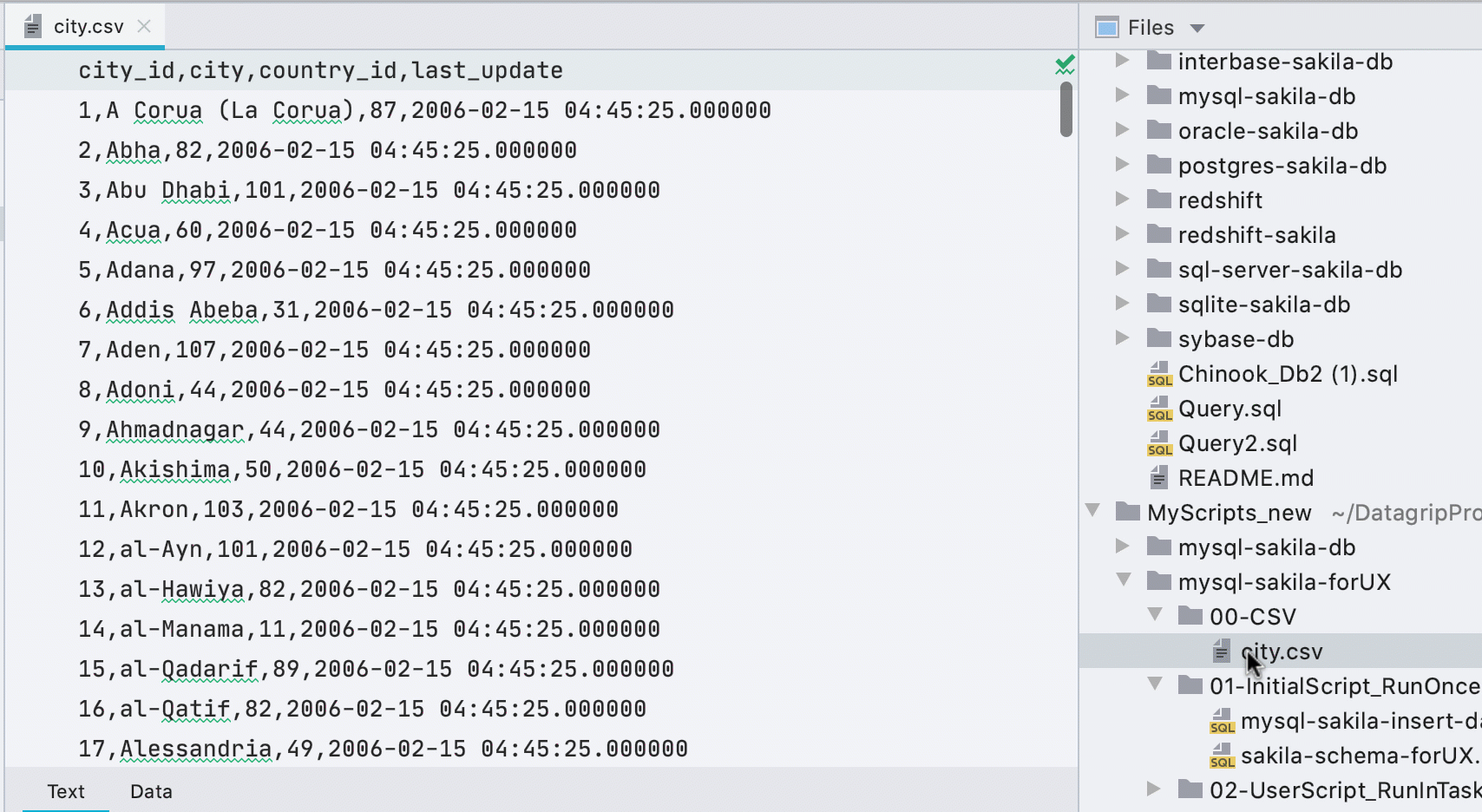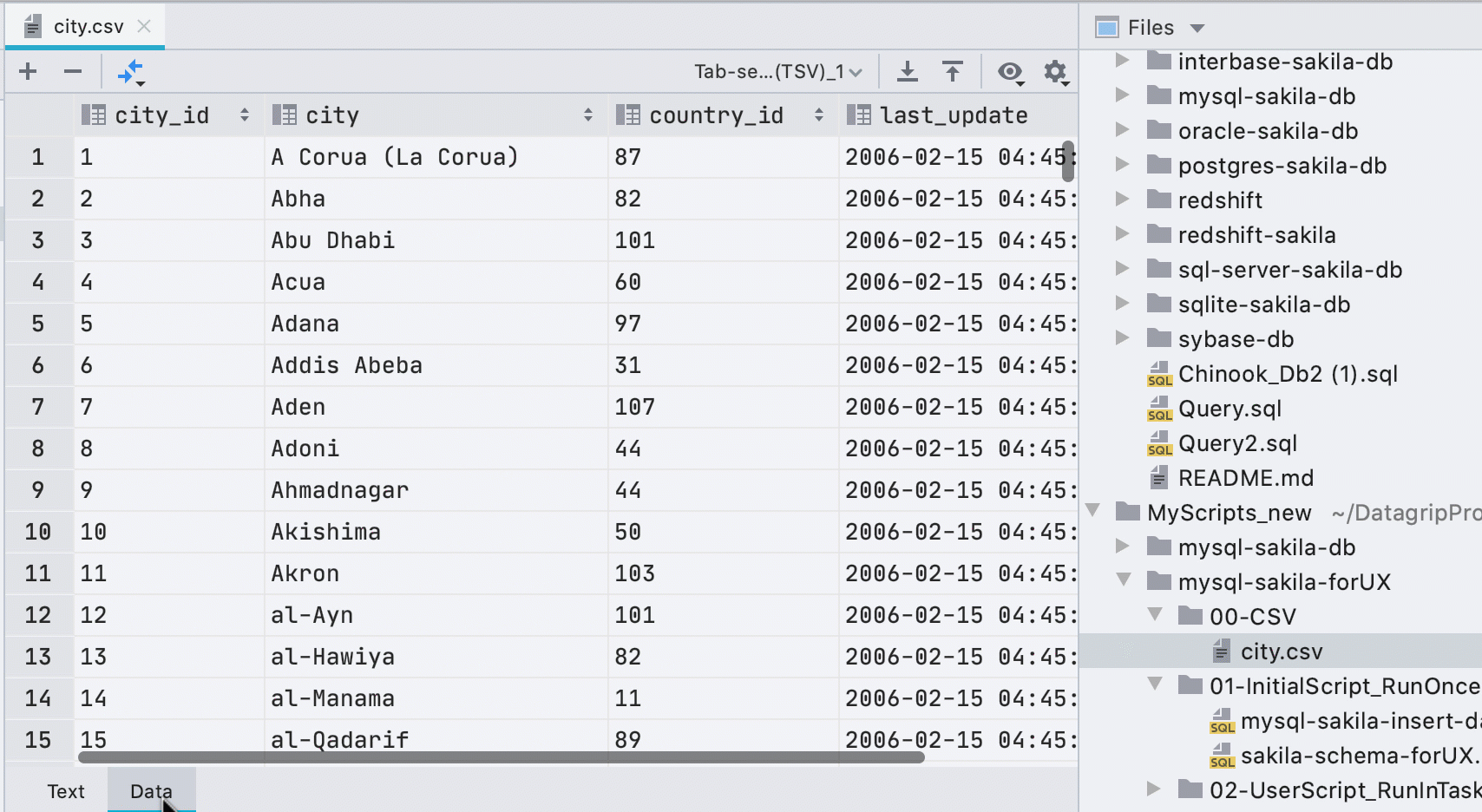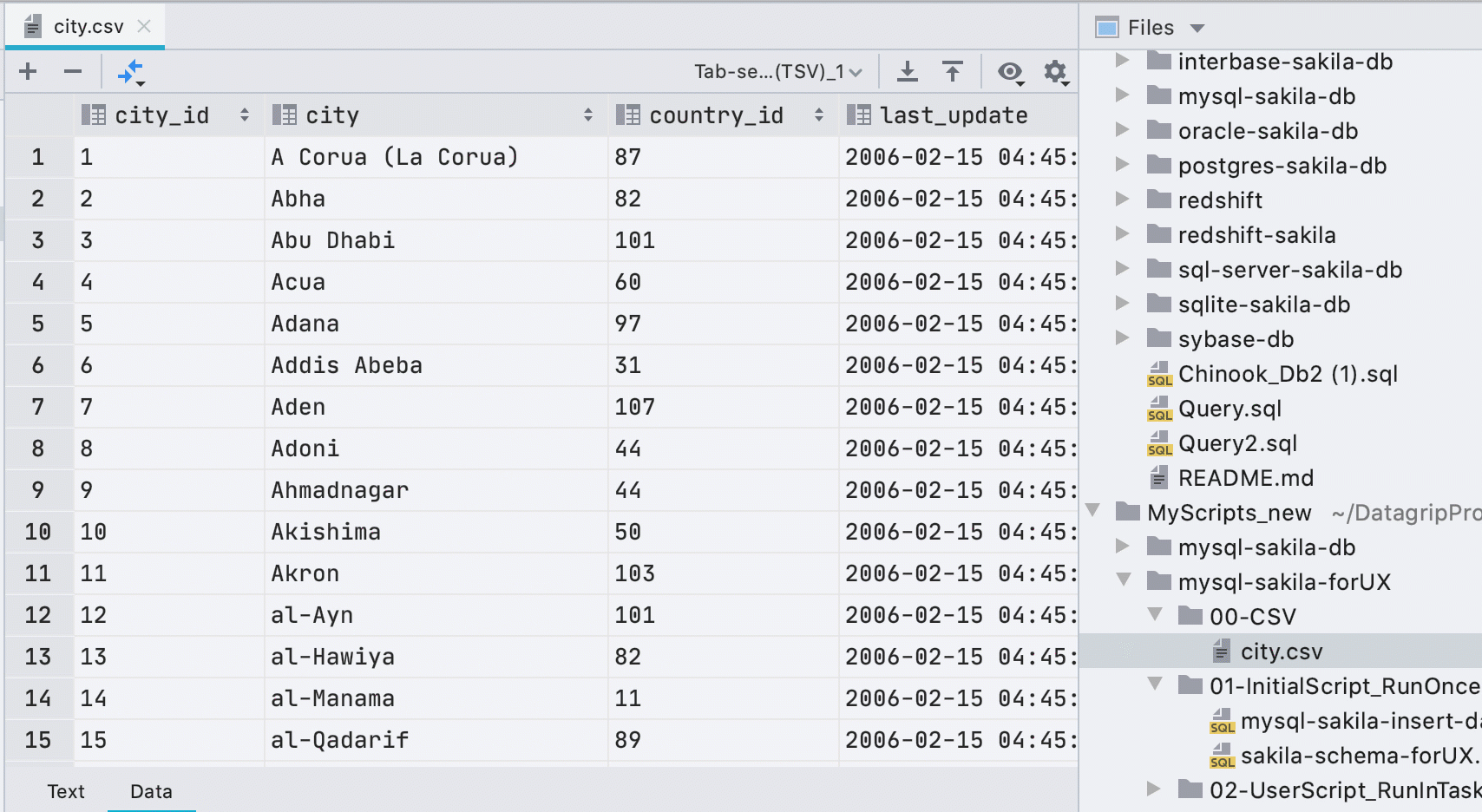
Automatic data editor for CSV files
Previously, you had to call the data editor from the context menu, and a small yellow bar advertised a third-party plugin when opening CSV files. Now we figure out what's what and show the Data tab for CSV files.
New rows when pasting values
If you paste data into a table from the clipboard, we will automatically create the required number of new rows.
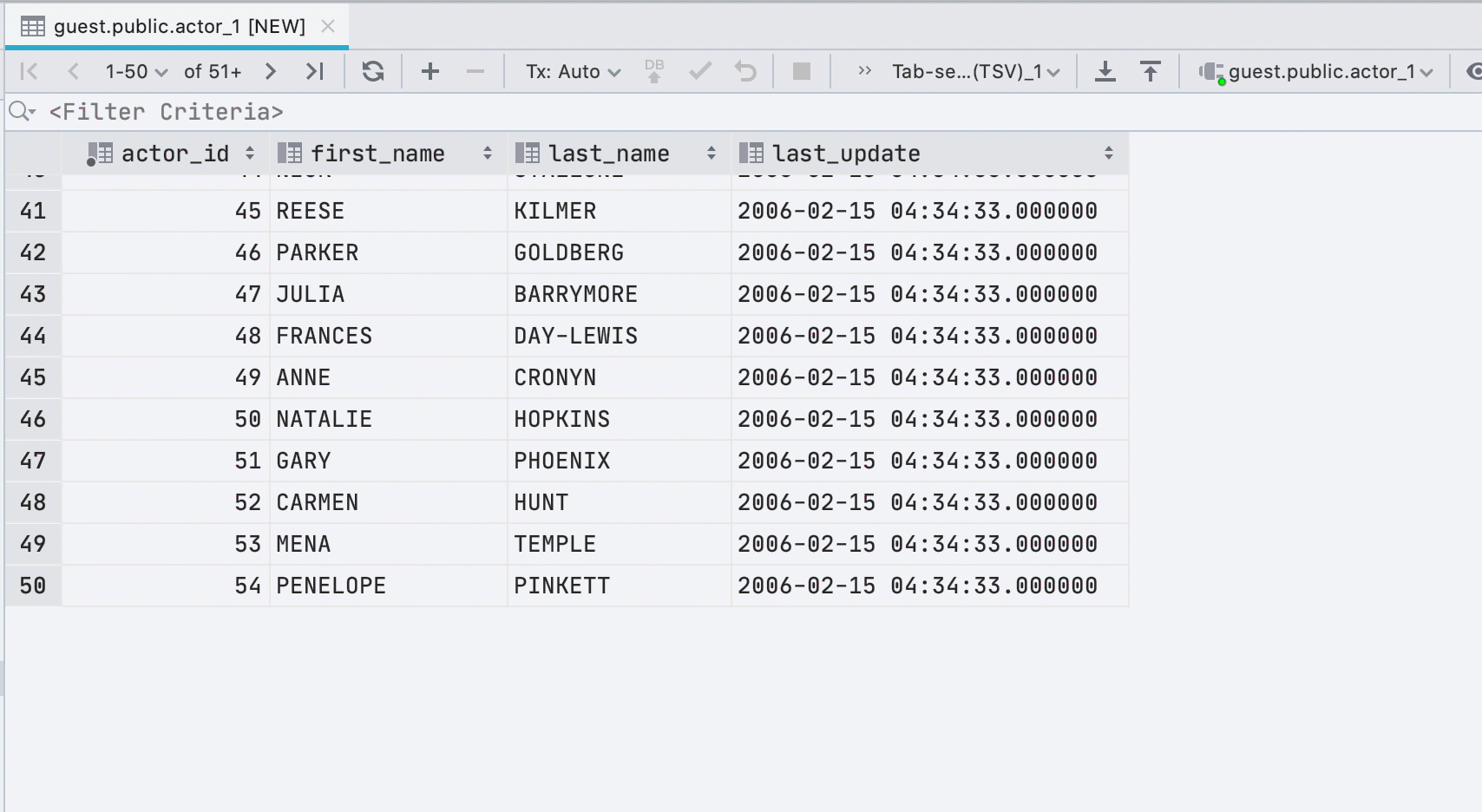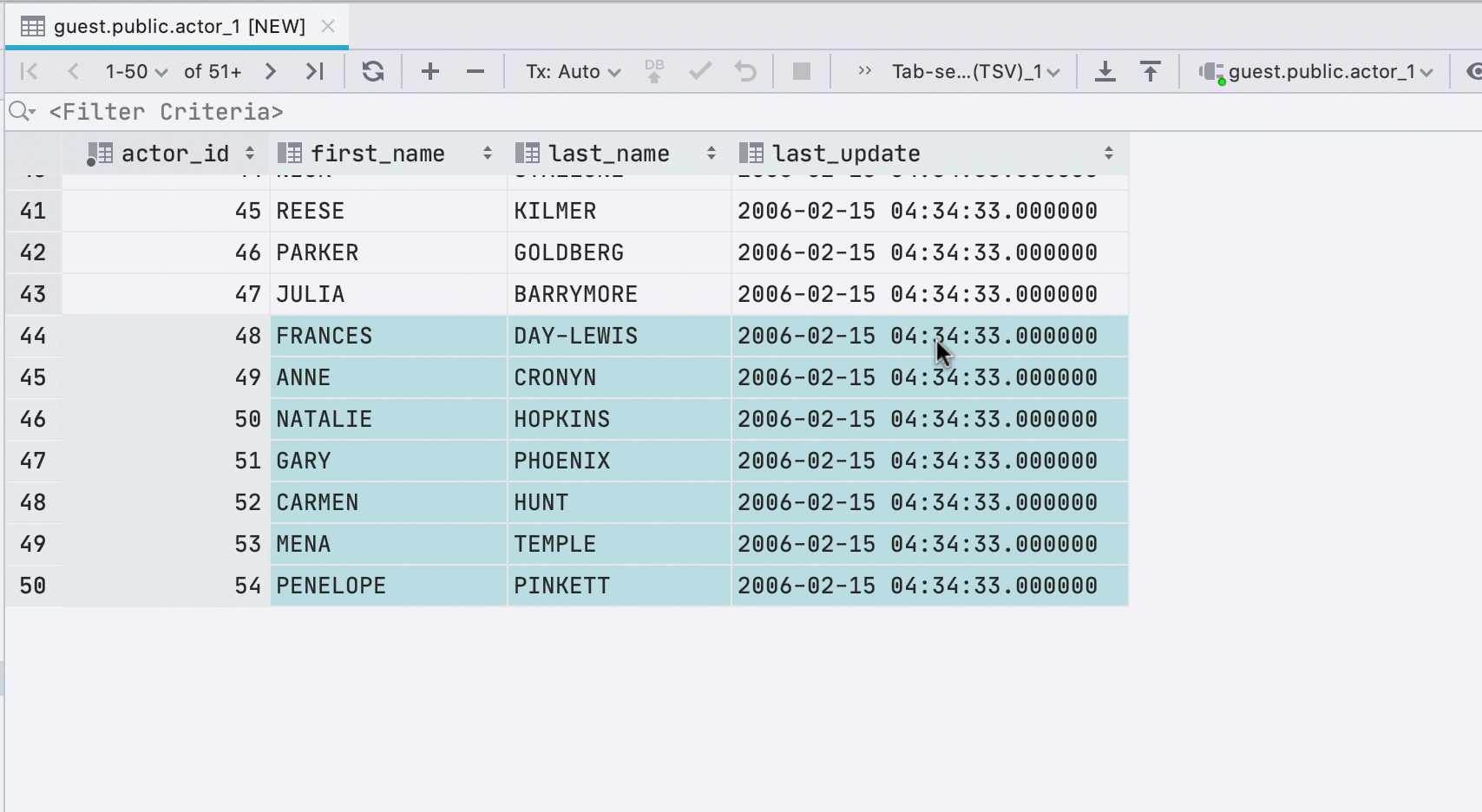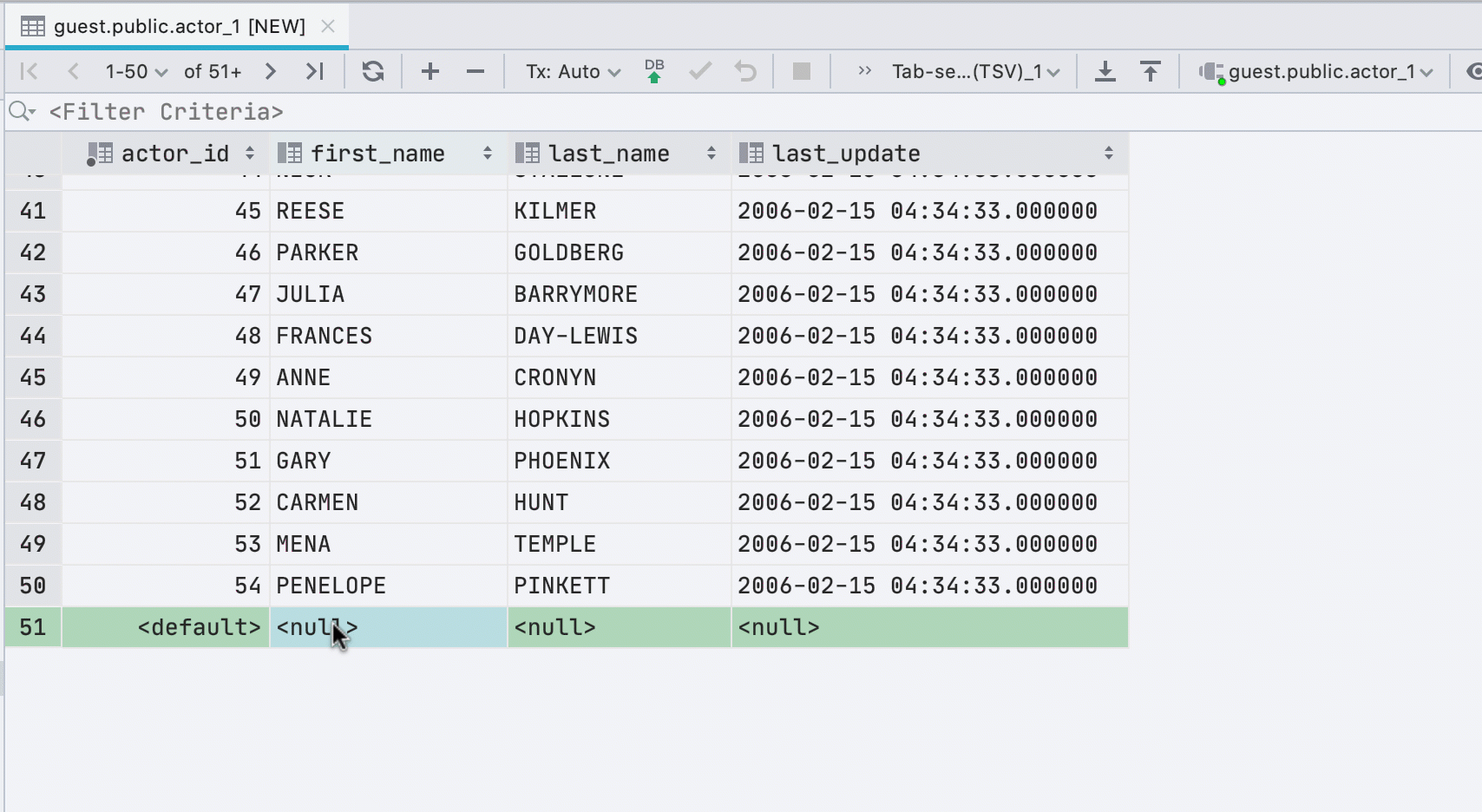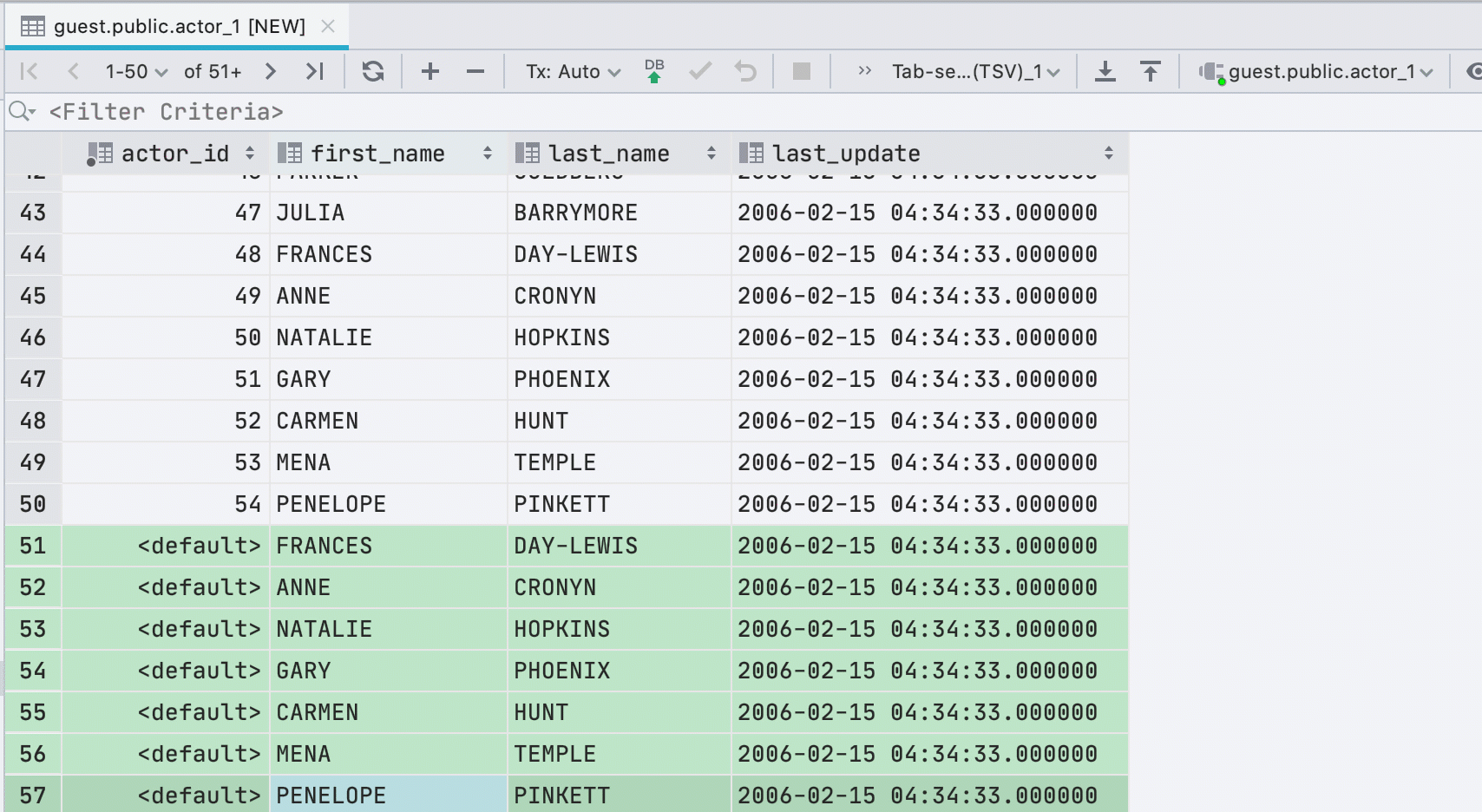
New interface for underloaded data
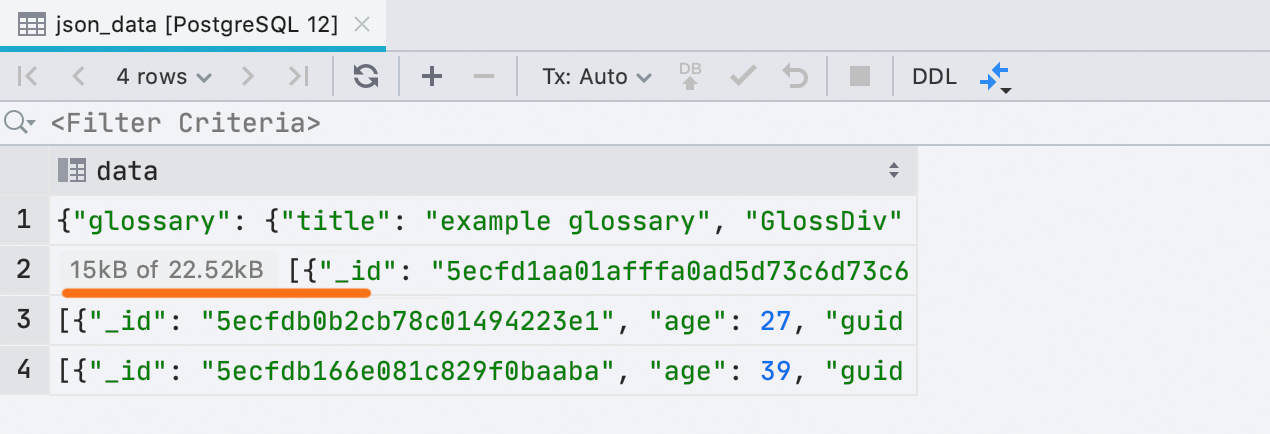
Sometimes DataGrip cannot load all data into a cell if it takes up a lot of memory. This is determined by the Database | Data views | Max LOB length.Previously, we inserted text about this directly into the cell value, and this is inconvenient. Now it is a small separate plate:
Export to the clipboard from the context menu
In the last release, we made a dialog box for export, leaving out one small case: it became less convenient to copy the entire result to the clipboard with the mouse. Now this can be done from the context menu.

Recall that this action copies the entire result or table. And Ctrl / Cmd + C or the
Copy action copies only the selection.
Filtering improvements for MongoDB
Besides ObjectId and ISODate , you can now filter by UUID , NumberDecimal , NumberLong, and
BinData . Also, if you have a suitable value for UUID / ObjectId / ISODate in your clipboard, DataGrip will offer to use it for filtering.
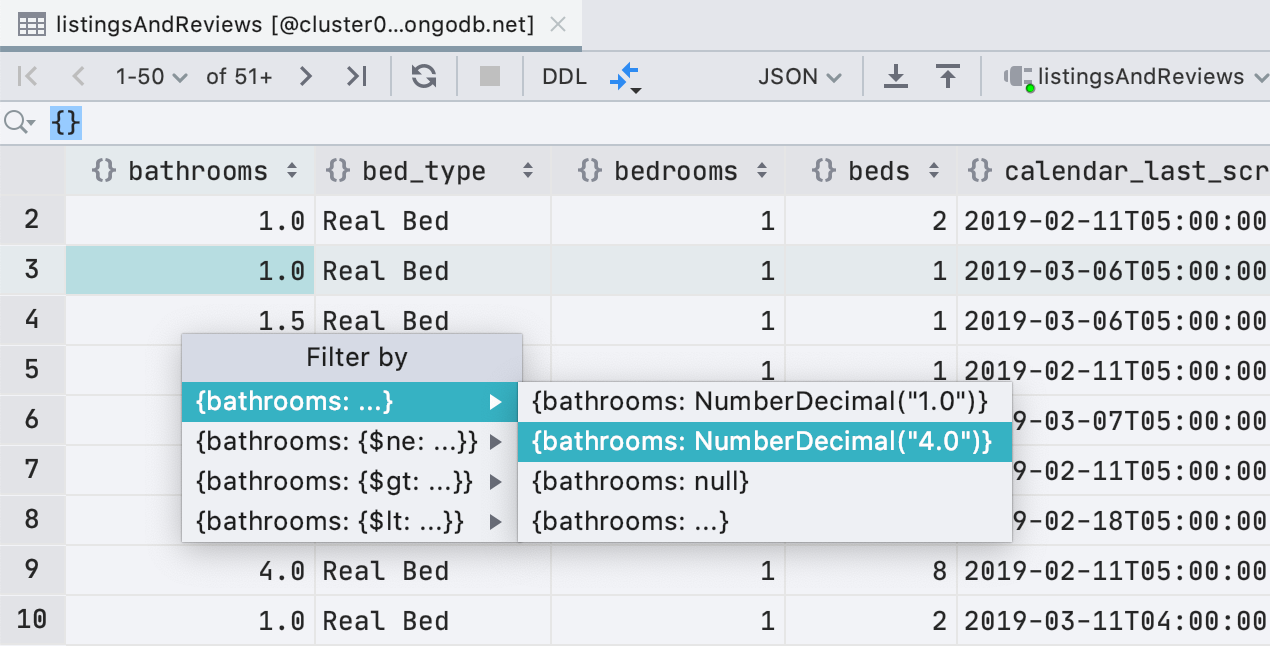
We also added regular expressions to the filter conditions so that you don't miss the
LIKE filter in relational databases too much .

SQL editor
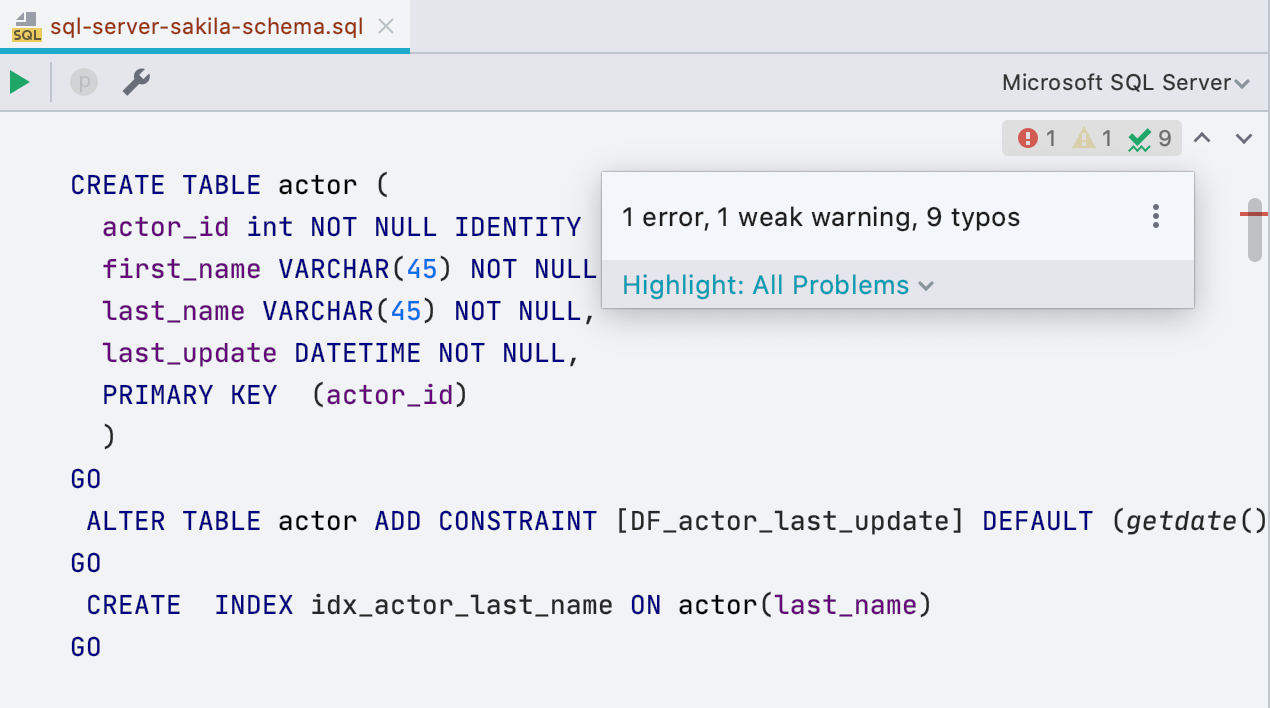
New widget with inspections
A small panel has appeared to the right of the editor - it will tell you how many errors are in the script and how many places are suspicious. From there you can navigate or choose what to highlight and what not. The F2 keyboard shortcut still works for the same.
Suggestion to rename
This appeared in many of our IDEs: if you renamed something not using the built-in refactoring, but changed the name in the code, you will be prompted to refactor and rename and all uses. For example, here's how it works with aliases:

JOIN completion just got better
Previously, in order for us to offer a complete JOIN condition, we had to type this keyword. Now we understand what is needed as soon as you typed
'J'.

We also learned to offer double conditions if table keys are set like that.

Refresh database information
If DataGrip does not know anything about objects from your queries, it will inform you about it. Sometimes this happens if you just sealed yourself. It also happens that the file was associated with the wrong data source. Another reason for such an event is that the object has already appeared, but DataGrip has not received information about it from the database. To do this, we added the ability to start updating the database structure from the editor if the object is unknown.

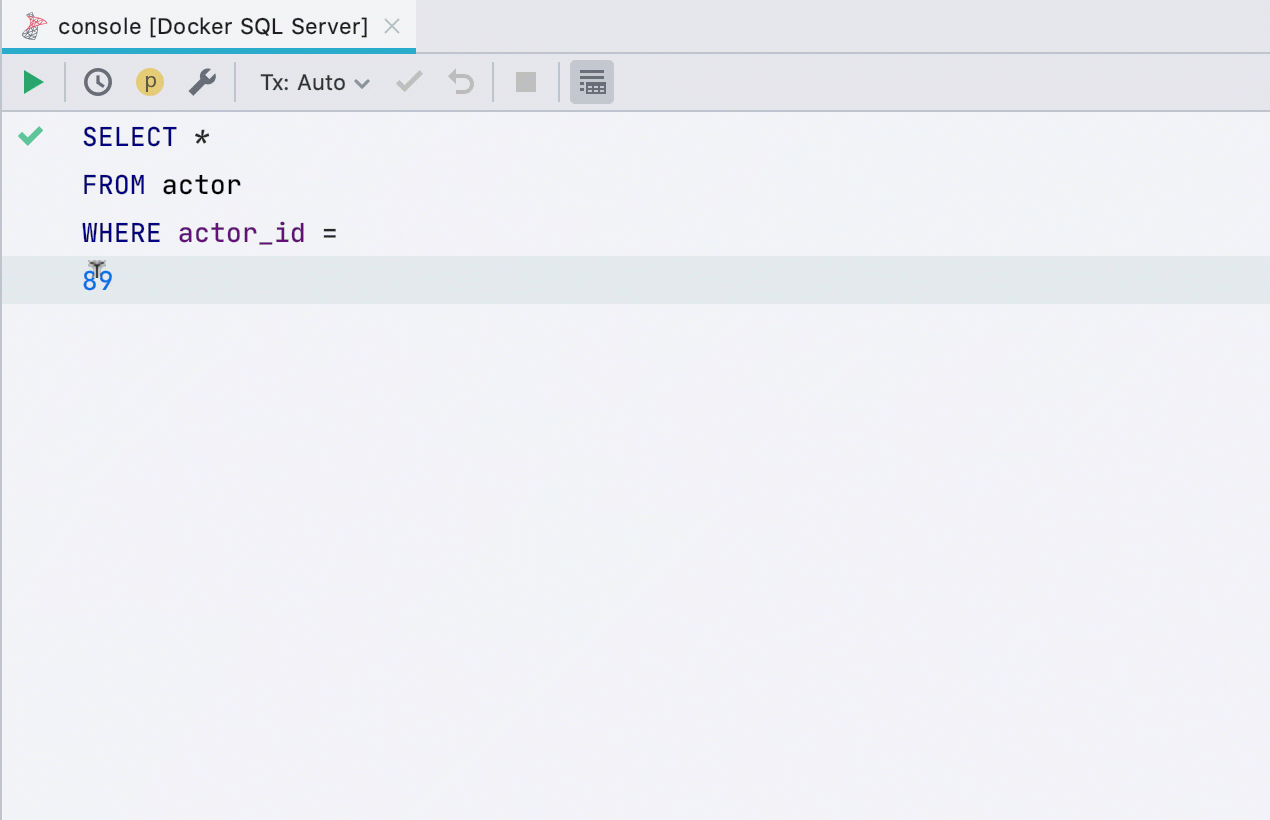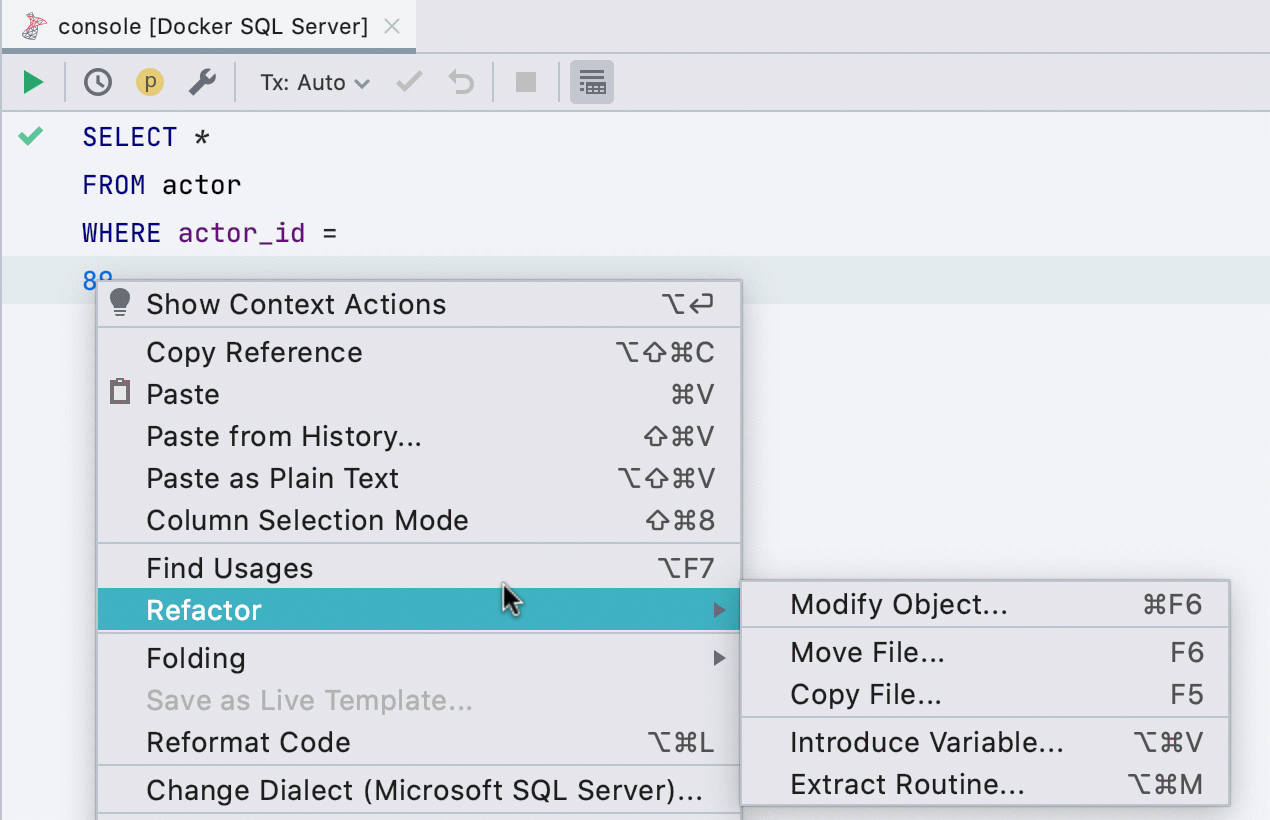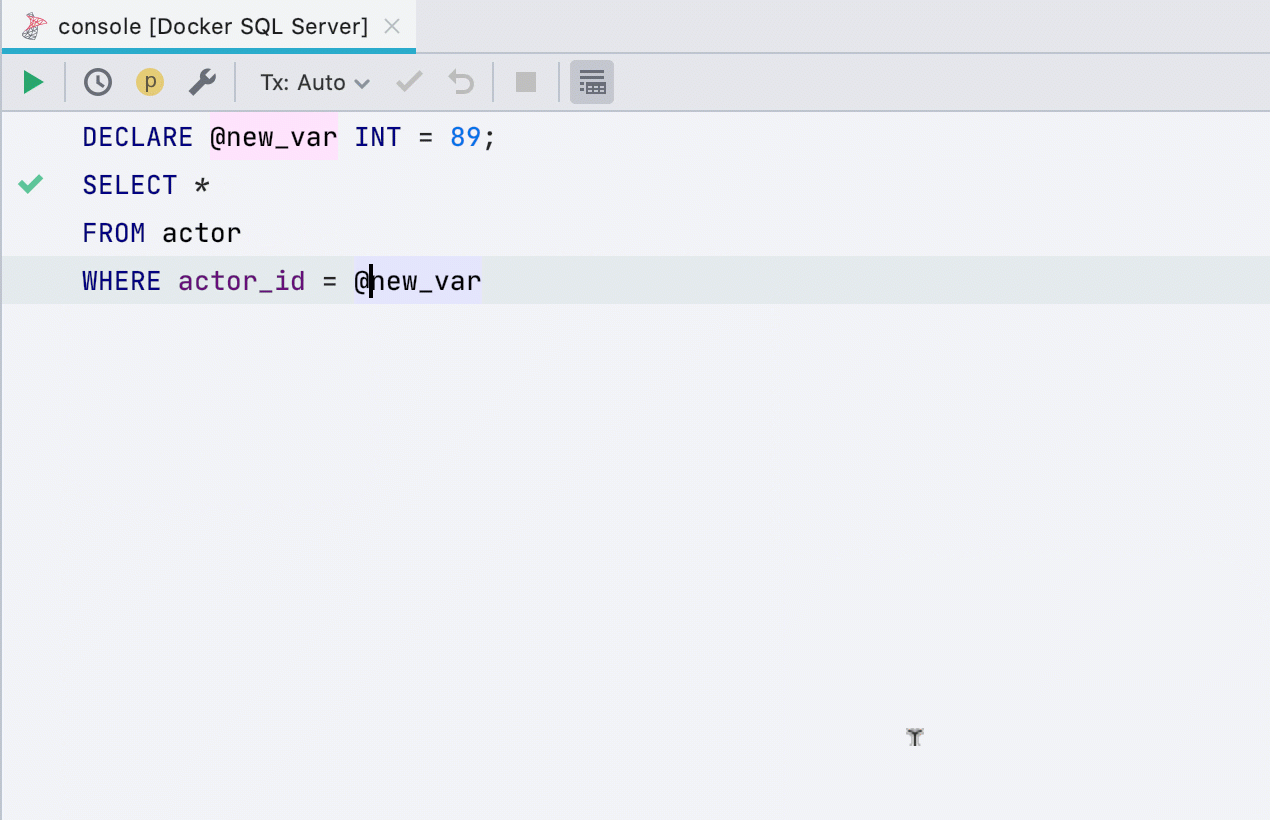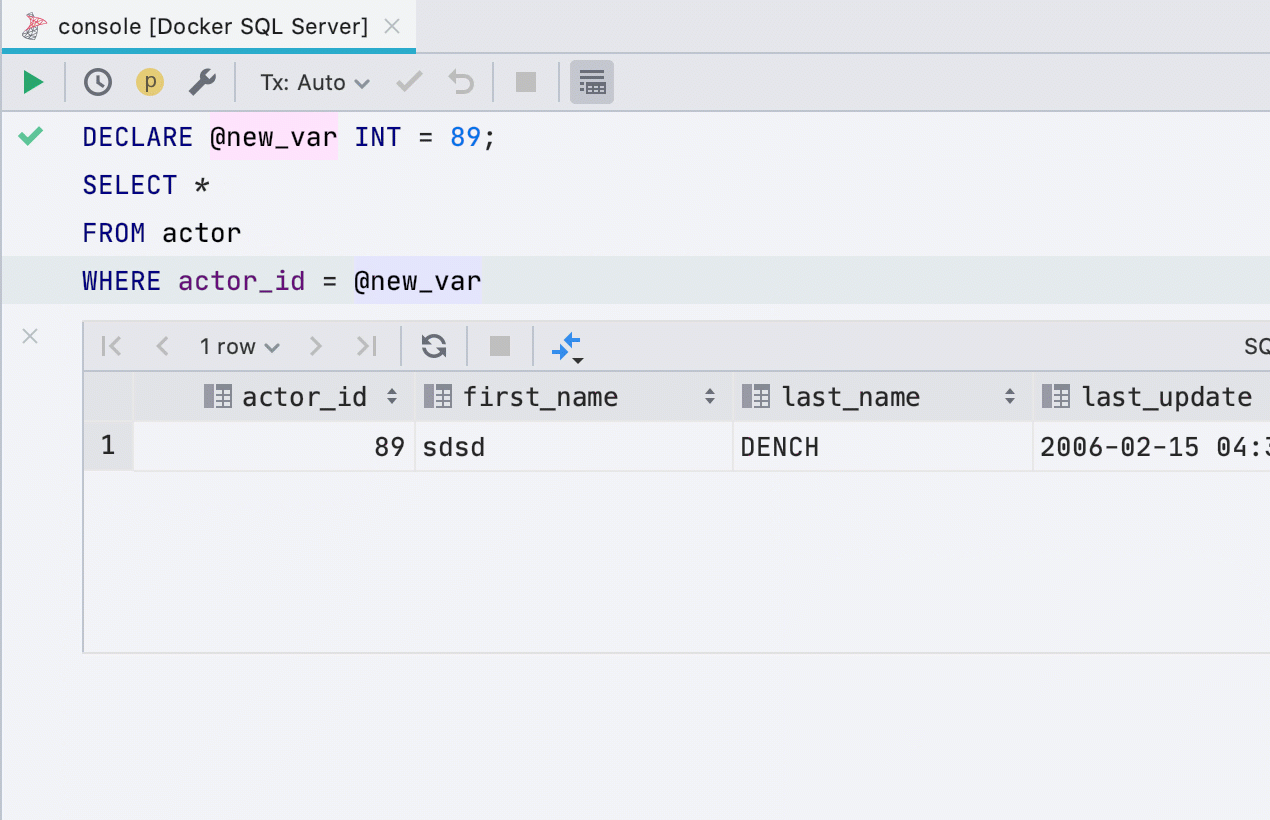
Allocate variable
This refactoring previously did not work for all databases, now works in SQL Server, Db2, Exasol, HSQL, Redshift and Sybase .
Google BigQuery highlighting
Added new dialects: Google BigQuery. So far, this is not full-fledged database support, but only correct code highlighting. Accordingly, you do not need to select code to run queries, we ourselves will determine what to run.

Highlighting TextMate
Like our other IDEs, DataGrip can now highlight code using the TextMate plugin. It can be useful if you have scripts in Python, lua, javascript. For a complete list of languages see Settings / Preferences | Editor | TextMate bundles .

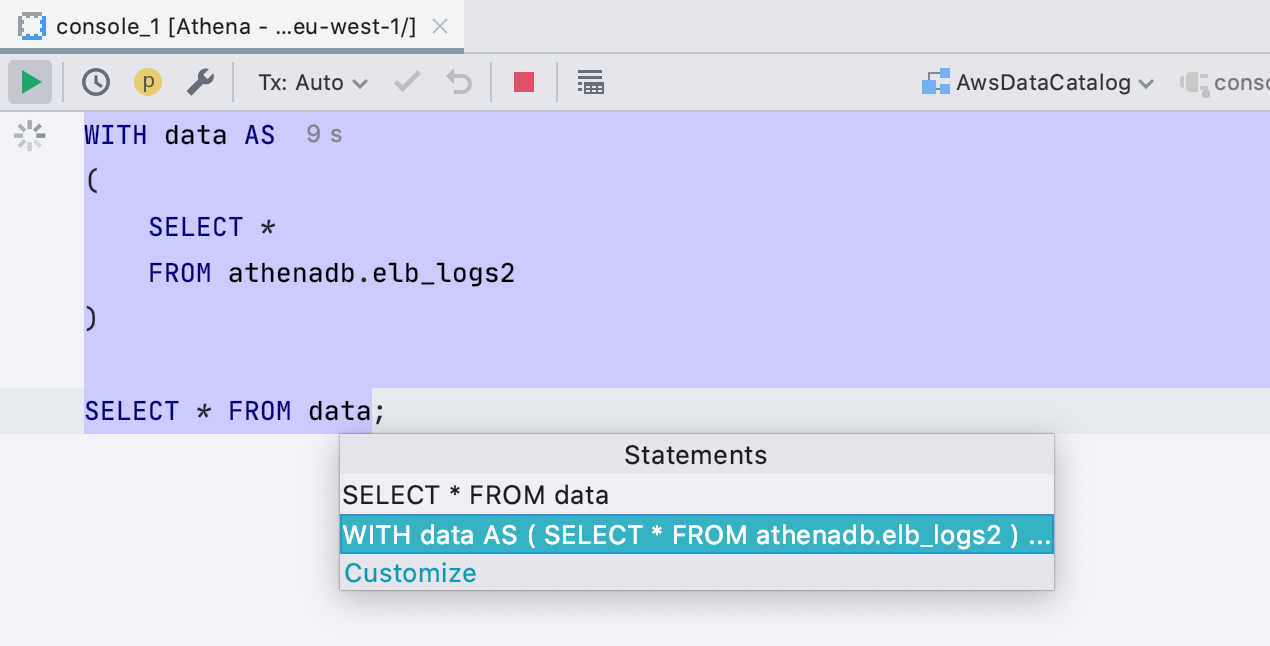
SQL 2016 as a <Generic> dialect
If you work with a database that we do not support, queries are parsed and highlighted with the < Generic > dialect . Previously, it was SQL 92, now SQL 2016. The most important thing is that now we correctly process queries with a WITH block, respectively, they are not only correctly highlighted, but you can also run them without highlighting the code.
Case of object names in formatting
In the formatting settings, there were three settings for the names of database objects - uppercase , lowercase, or not change . But it turned out that there is a fourth case: users want to use the case that was used when creating the object in the script. We supported this.

In the example, the Actor table is created with the first capital letter, and in use we have converted the table name to the same case.

We only look for creation scripts within the same file where the formatting takes place. If you want the formatter to find the object declaration in a neighboring file, create a DDL-based data source from your files .
Multiple carets in a selection
Now you can select a piece of code and put a caret on each line of it. For this use the action Add Carets to Ends of Selected Lines or the keyboard shortcut Shift + Alt + G

Database Explorer
All bases and schemes in the tree
By default, we show in the tree only those bases and schemes that you have selected yourself. The tree is not lazy, and all the meta information about the objects is used for the further work of the IDE. Therefore, we download only what is needed so as not to accidentally hang on a giant base.
However, many are used to tools that always show all objects, and people who are not familiar with our concept may lose sight of the bases and diagrams. Therefore, we made the Show All Namespaces setting , and when it is enabled, all databases and schemes will be shown in the tree, even if information about their objects is not loaded. Such schemes and bases are marked in gray.

Interface for creating views
We usually say that the code generation function in the editor (Alt + Ins or Cmd + N ) covers many of the developer's object creation needs, but sometimes it is still less convenient. Therefore, we started adding interfaces for creating objects: in the new version, you can create views.

Script files in the Files panel
If you created a DDL-based data source, these files will automatically go to the
Files panel . So it will be convenient for you to view and edit them.

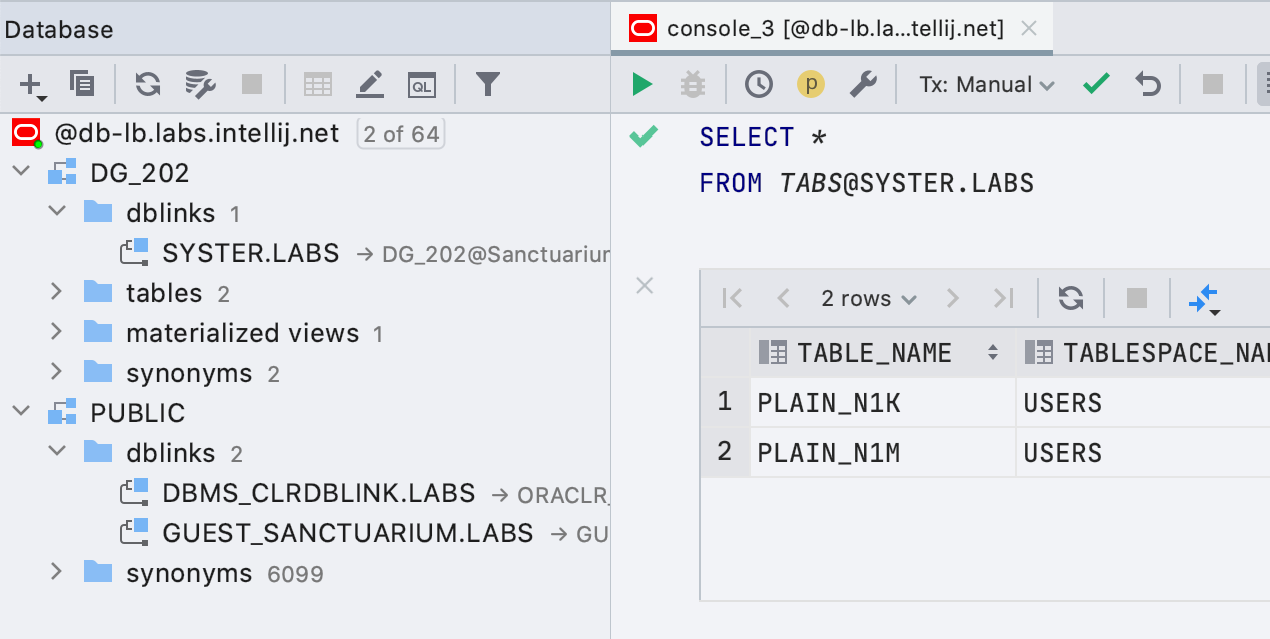
Simple Oracle
Database Linking Database links are now shown in Explorer and queries that use them are highlighted correctly.
General
No More Long Tab Names
You've often complained that tabs are growing out of control .

From now on:
- Database | General | Always show qualified names for database objects , , .
- 20 , .
- , .
- — 36 , .
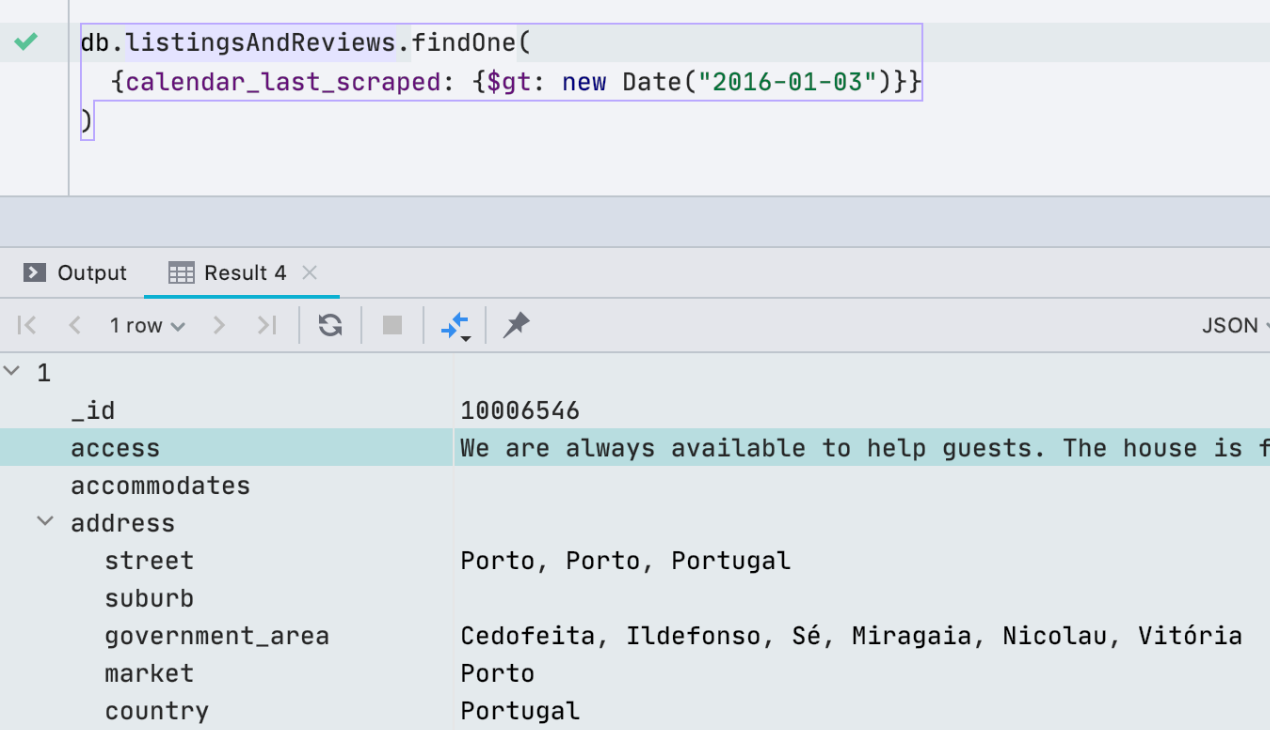
MongoDB shell support
A month ago we updated the driver we use to connect to MongoDB to support the MongoDB shell. This means new commands and methods have worked, such as help, db.getCollectionInfos (), db.getCollectionNames (), db.collection.remove () and others. Detailed article in English about MongoDB shell support here .
Native Libraries in Driver Settings
Now you can specify the path to the native library that the driver needs. Here are a few times when you might need it.

- SQL Server mssql-jdbc_auth-<version>-<arch>.dll SSO, . , SSO .
- Oracle ocijdbc, OCI .
- SQLite, ,
, , .
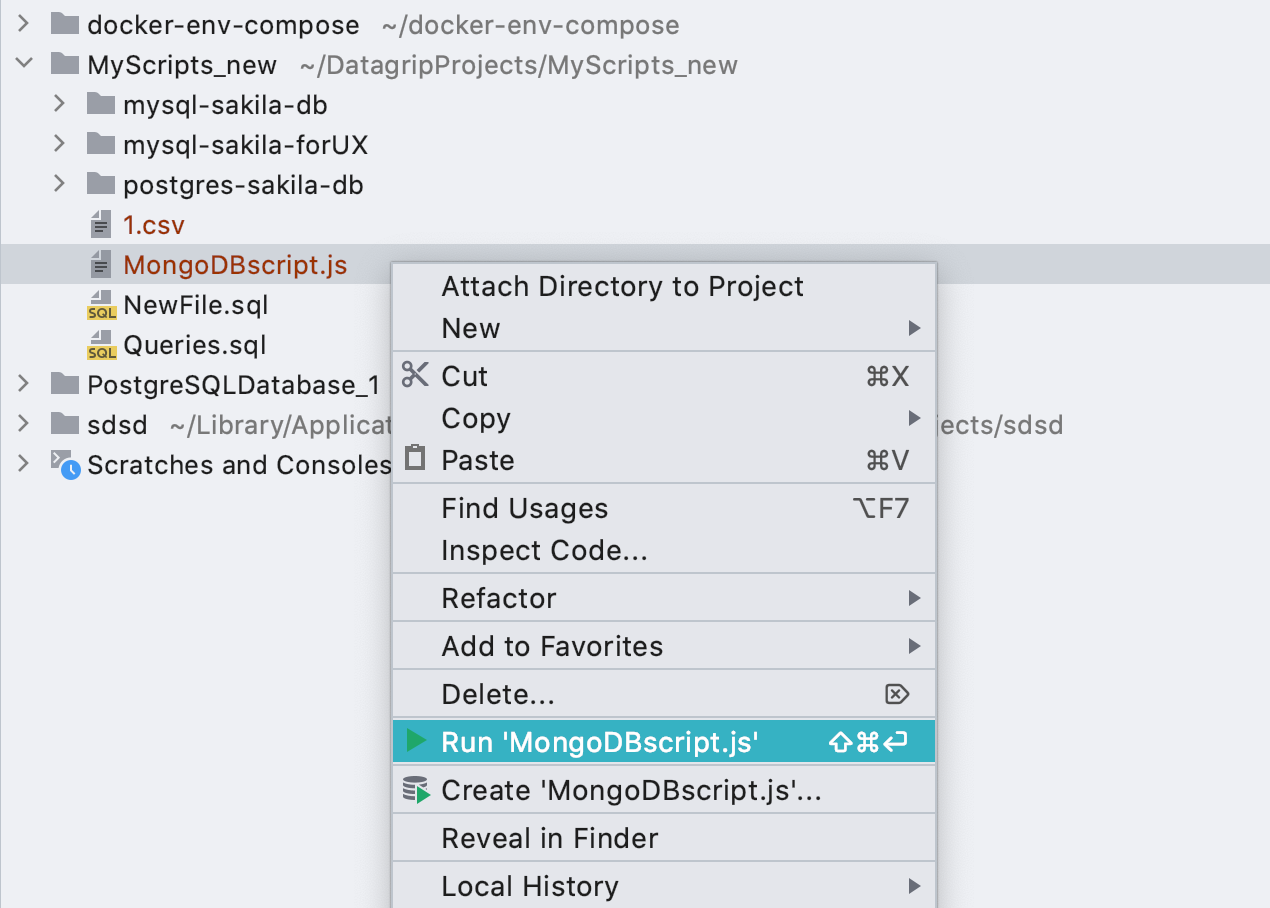
Launch configurations for * .js files
Now launch configurations work for MongoDB scripts as well .
Integration with Git and Github works out of the box
Our survey showed that quite a few people store scripts in version control systems, so we decided to package two of the most popular plugins in this area.

Thank you for attention! Let us remind you that we have our own channel in Telegram , where you can ask questions and share experiences. But if you find a bug, it's better to immediately write to the tracker so that it doesn't get lost. Well, here, of course, also write comments :)
That's all!
DataGrip Team