- In short, what plan will we have? First, we'll talk about why we're going to learn Python. Then let's see how the CPython interpreter works in more depth, how it manages memory, how the type system in Python works, dictionaries, generators and exceptions. I think it will take about an hour.
- Why Python?
- Interpreter device
- Typing
- Dictionaries
- Memory management
- Generators
- Exceptions
Why Python?
* insights.stackoverflow.com/survey/2019
** very subjective
*** interpretation of research
**** interpretation of research
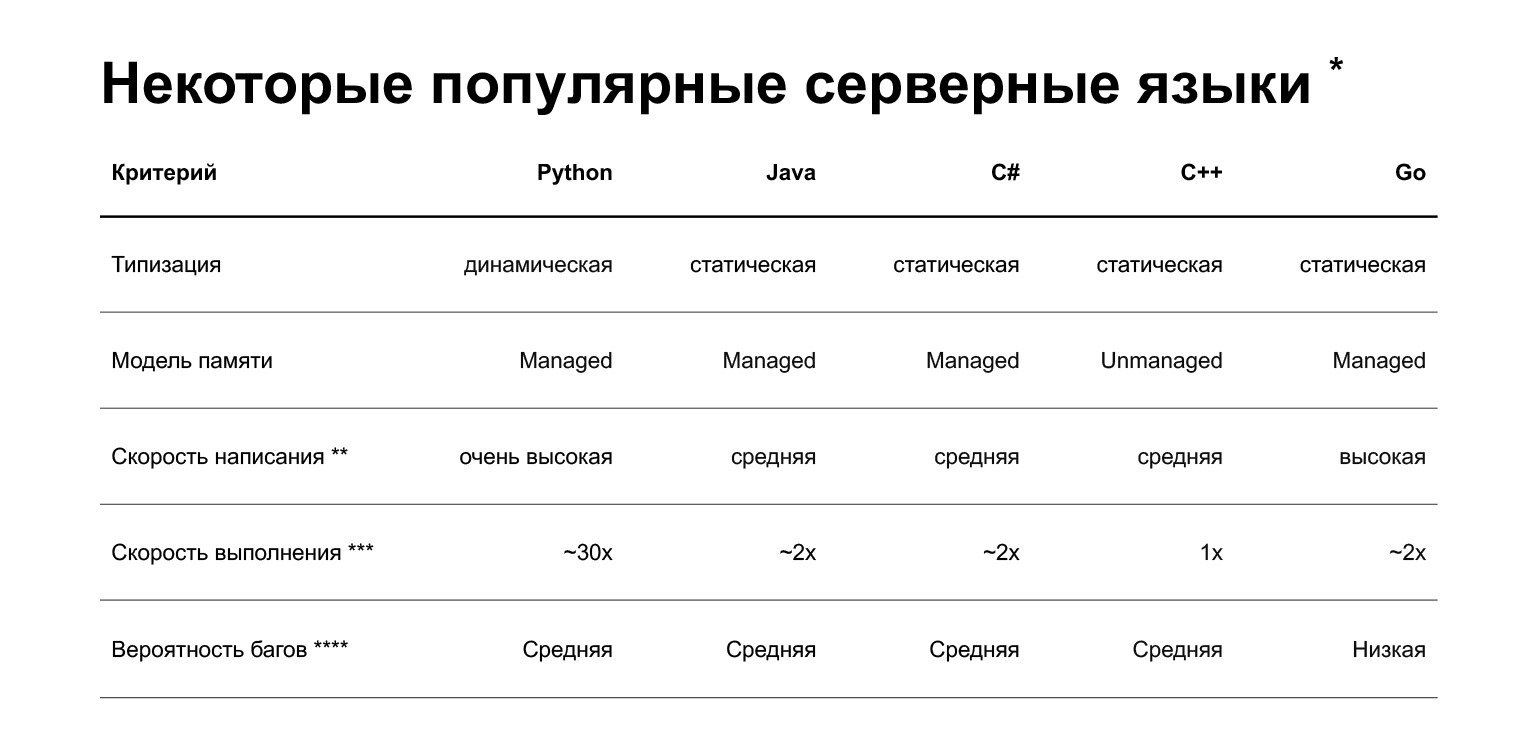
Let's get started. Why Python? The slide shows a comparison of several languages that are currently used in backend development. But in short, what is the advantage of Python? You can quickly write code on it. This, of course, is very subjective - people who write cool C ++ or Go can argue with this. But on average, writing in Python is faster.
What are the disadvantages? The first and probably the main disadvantage is that Python is slower. It can be 30 times slower than other languages, here is astudyon this topic. But its speed depends on the task. There are two classes of tasks:
- CPU bound, CPU bound tasks, CPU bound.
- I / O bound, tasks limited by input-output: either over the network, or in databases.
If you are solving the CPU bound problem, then yes, Python will be slower. If I / O is bound, and this is a large class of tasks, then to understand the speed of execution you need to run benchmarks. And perhaps comparing Python to other languages, you won't even notice the performance difference.
In addition, Python is dynamically typed: the interpreter does not check types at compile time. In version 3.5, type hints appeared, allowing you to statically specify types, but they are not very strict. That is, you will catch some errors already in production, and not at the compilation stage. Other popular languages for the backend - Java, C #, C ++, Go - have static typing: if you pass the wrong object in the code, the compiler will inform you about it.
More down to earth, how is Python used in Taxi product development? We are moving towards a microservice architecture. We already have 160 microservices, namely grocery - 35, 15 of them in Python, 20 - on pluses. That is, we are now writing either only in Python, or on pluses.
How do we choose the language? The first is the load requirements, that is, we see if Python can handle it or not. If he pulls, then we look at the competence of team developers.
Now I want to talk about the interpreter. How does CPython work?
Interpreter device
The question may arise: why do we need to know how the interpreter works. The question is valid. You can easily write services without knowing what's under the hood. The answers may be as follows:
1. Optimization for high load. Imagine you have a Python service. It works, the load is low. But one day the task comes to you - to write a pen, ready for a heavy load. You can't get away from this, you can't rewrite the entire service in C ++. So, you need to optimize the service for high load. Understanding how the interpreter works can help with this.
2. Debugging of complex cases. Let's say the service is running, but memory starts to "leak" in it. At Yandex.Taxi, we had such a case just recently. The service consumed 8 GB of memory every hour and crashed. We need to figure it out. It's about the language, Python. Knowledge of how memory management works in Python is required.
3. This is useful if you are going to write complex libraries or complex code.
4. And in general - it is considered good form to know the tool with which you are working on a deeper level, and not just as a user. This is appreciated in Yandex.
5. They ask questions about it at interviews, but that's not even the point, but your general IT outlook.

Let's briefly recall what types of translators are. We have compilers and interpreters. The compiler, as you probably know, is the thing that translates your source code directly into machine code. Rather, the interpreter translates first into bytecode, and then executes it. Python is an interpreted language.
Bytecode is a kind of intermediate code that is obtained from the original. It is not tied to the platform and runs on a virtual machine. Why virtual? This is not a real car, but some kind of abstraction.

What types of virtual machines are there? Register and stack. But here we must remember not this, but the fact that Python is a stack machine. Next, we'll see how the stack works.
And one more caveat: here we will only talk about CPython. CPython is a reference Python implementation, written, as you might guess, in C. Used as a synonym: when we talk about Python, we usually talk about CPython.
But there are other interpreters as well. There is PyPy, which uses JIT compilation and speeds up about five times. It is rarely used. I honestly have not met. There is JPython, there is IronPython, which translates bytecode for the Java Virtual Machine and for the Dotnet machine. This is out of scope of today's lecture - to be honest, I have not come across it. So let's take a look at CPython.

Let's see what happens. You have a source, a line, you want to execute it. What does the interpreter do? A string is just a collection of characters. To do something meaningful with it, you first translate the code into tokens. A token is a grouped set of characters, an identifier, a number, or some kind of iteration. Actually, the interpreter translates the code into tokens.

Further, the Abstract Syntax Tree, AST is built from these tokens. Also, do not bother yet, these are just some trees, in the nodes of which you have operations. Let's say in our case there is BinOp, a binary operation. Operation - exponentiation, operands: the number to raise, and the power to raise.
Further, you can already build some code using these trees. I miss a lot of steps, there is an optimization step, other steps. Then these syntax trees are translated into bytecode.
Let's see in more detail here. Bytecode is, as the name tells us, a code made up of bytes. And in Python, starting from 3.6, bytecode is two bytes.

The first byte is the operator itself, called the opcode. The second byte is the oparg argument. It looks like we have from above. That is, a sequence of bytes. But Python has a module called dis, from Disassembler, with which we can see a more human-readable representation.
What does it look like? There is a line number of the source - the leftmost one. The second column is the address. As I said, the bytecode in Python 3.6 takes two bytes, so all addresses are even and we see 0, 2, 4 ...
Load.name, Load.const are already the code options themselves, that is, the codes of those operations that Python should execute. 0, 0, 1, 1 are oparg, that is, the arguments of these operations. Let's see how they are done next.
(...) Let's see how the bytecode is executed in Python, what structures are there for this.

If you don't know C, it's okay. The footnotes are for general understanding.
Python has two structures that help us execute bytecode. The first one is CodeObject, you can see its summary. In fact, the structure is larger. This is code without context. This means that this structure contains, in fact, the bytecode that we just saw. It contains the names of variables used in this function, if the function contains references to constants, names of constants, something else.

The next structure is FrameObject. This is already the execution context, the structure that already contains the value of the variables; references to global variables; the execution stack, which we'll talk about a little later, and a lot of other information. Let's say the number of the instruction execution.
As an example: if you want to call a function several times, then you will have the same CodeObject, and a new FrameObject will be created for each call. It will have its own arguments, its own stack. So they are interconnected.

What is the main interpreter loop, how is the bytecode executed? You saw we had a list of these opcode with oparg. How is this all done? Python, like any interpreter, has a loop that executes this bytecode. That is, a frame enters it, and Python simply goes through the bytecode in order, looks at what kind of oparg it is, and goes to its handler using a huge switch. Only one opcode is shown here for example. For example, we have a binary subtract here, a binary subtraction, let's say "AB" will be performed at this point.
Let's explain how binary subtract works. Very simple, this is one of the simplest codes. The TOP function takes the topmost value from the stack, pops it from the topmost one, does not just pop it off the stack, and then the PyNumber_Subtract function is called. Result: The slash SET_TOP function is pushed back onto the stack. If it's not clear about the stack, an example will follow.

Very briefly about the GIL. The GIL is a process-level mutex in Python that takes this mutex in the main interpreter loop. And only after that does the bytecode start executing. This is done so that only one thread is executing the bytecode at a time in order to protect the internal structure of the interpreter.
Let's say, going a little further, that all objects in Python have a number of references to them. And if two threads change this number of links, the interpreter will break. Therefore there is a GIL.
You will be told about this in the lecture on asynchronous programming. How can this be important to you? Multithreading is not used, because even if you make several threads, then in general you will only have one of them running, the bytecode will be executed in one of the threads. Therefore, either use multiprocessing, or sish extension, or something else.

A quick example. You can safely explore this frame from Python. There is a sys module that has an underscore function get_frame. You can get a frame and see what variables are there. There is an instruction. This is more for teaching, in real life I did not use it.
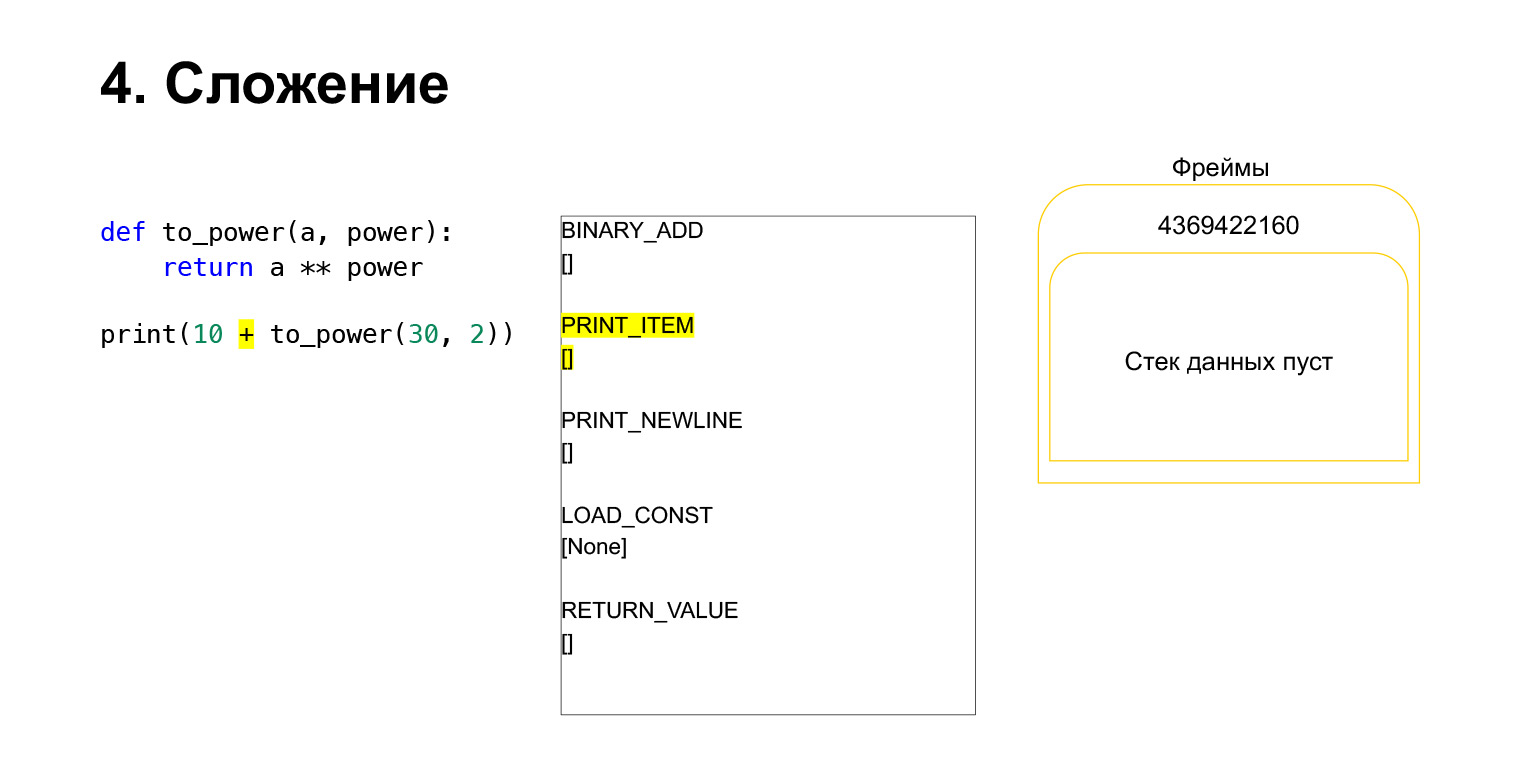
Let's try to see how the Python virtual machine stack works for understanding. We have some code, quite simple, which does not understand what it does.
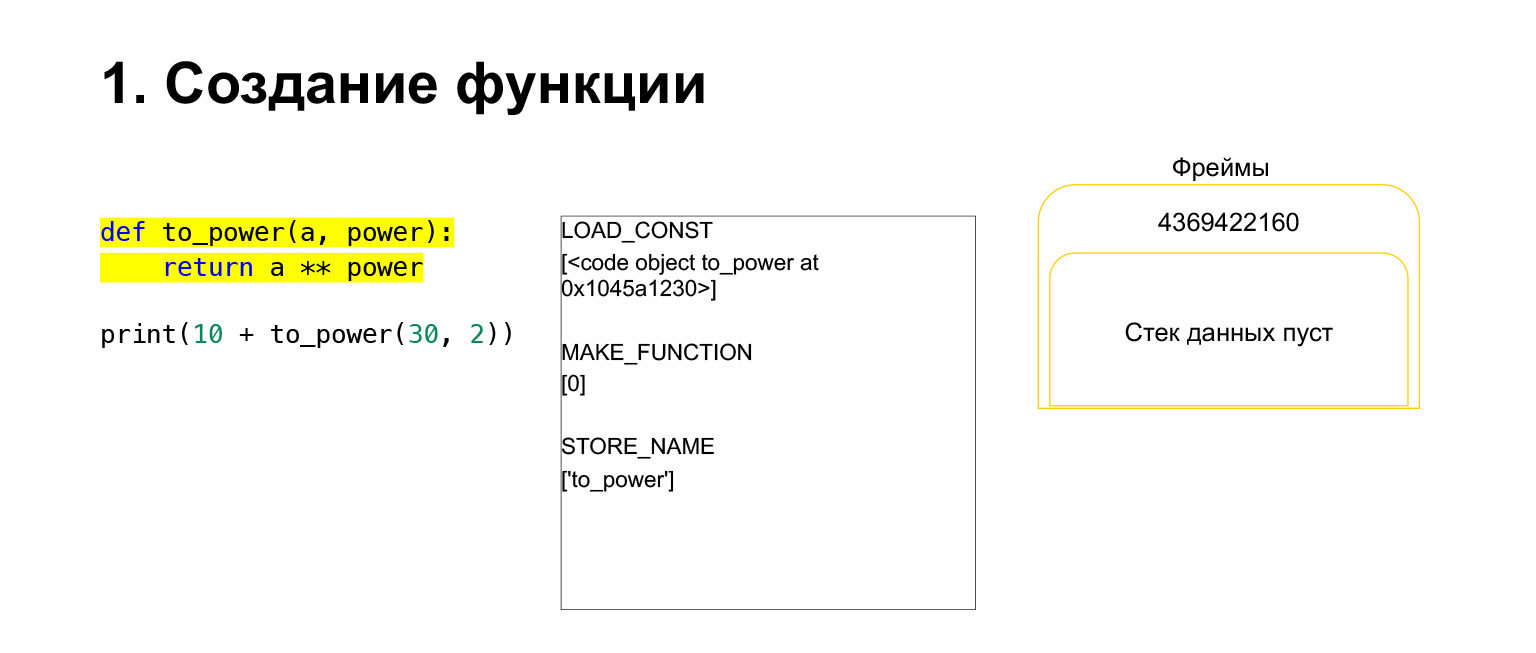
On the left is the code. The part that we are now examining is highlighted in yellow. In the second column, we have the bytecode of this piece. The third column contains frames with stacks. That is, each FrameObject has its own execution stack.
What does Python do? It just goes in order, bytecode, in the middle column, executes and works with the stack.
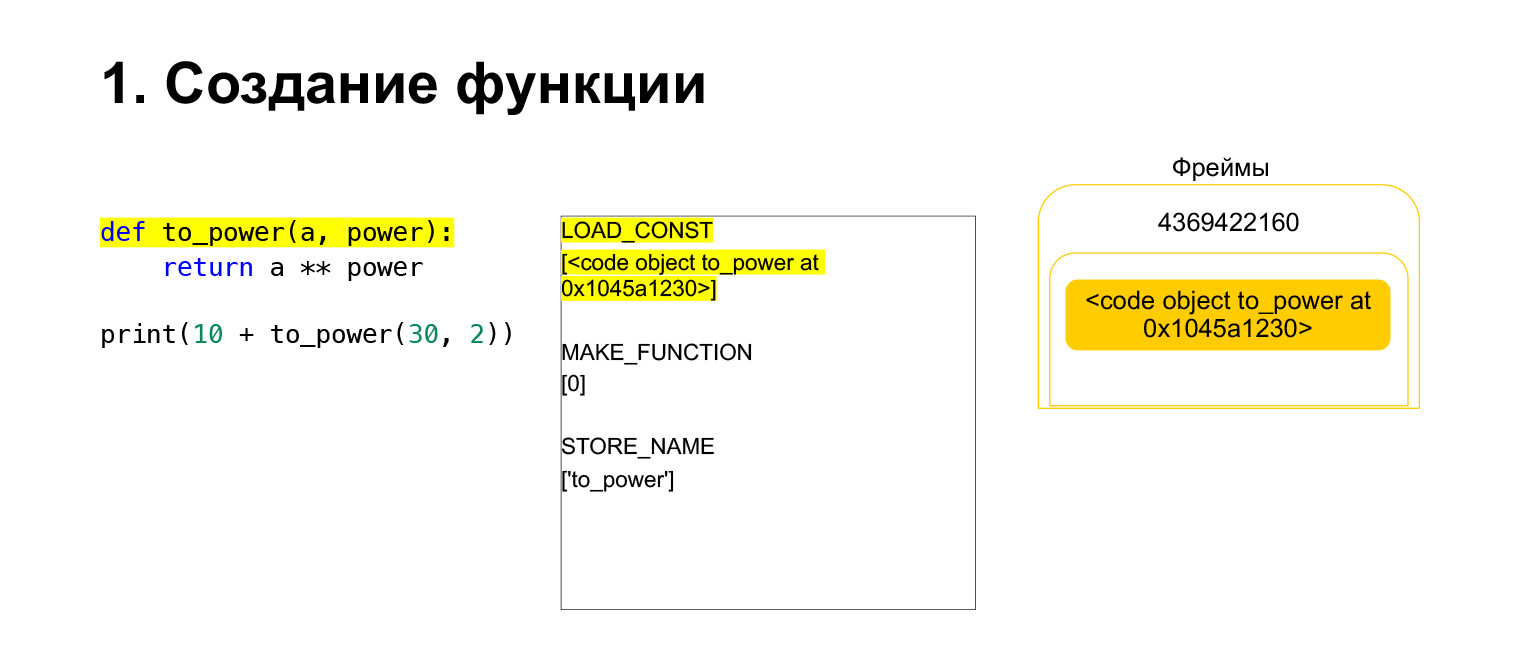
We have run the first opcode called LOAD_CONST. It loads a constant. We skipped the part, a CodeObject is created there, and we had a CodeObject somewhere in the constants. Python loaded it onto the stack using LOAD_CONST. We now have a CodeObject on the stack in this frame. We can move on.
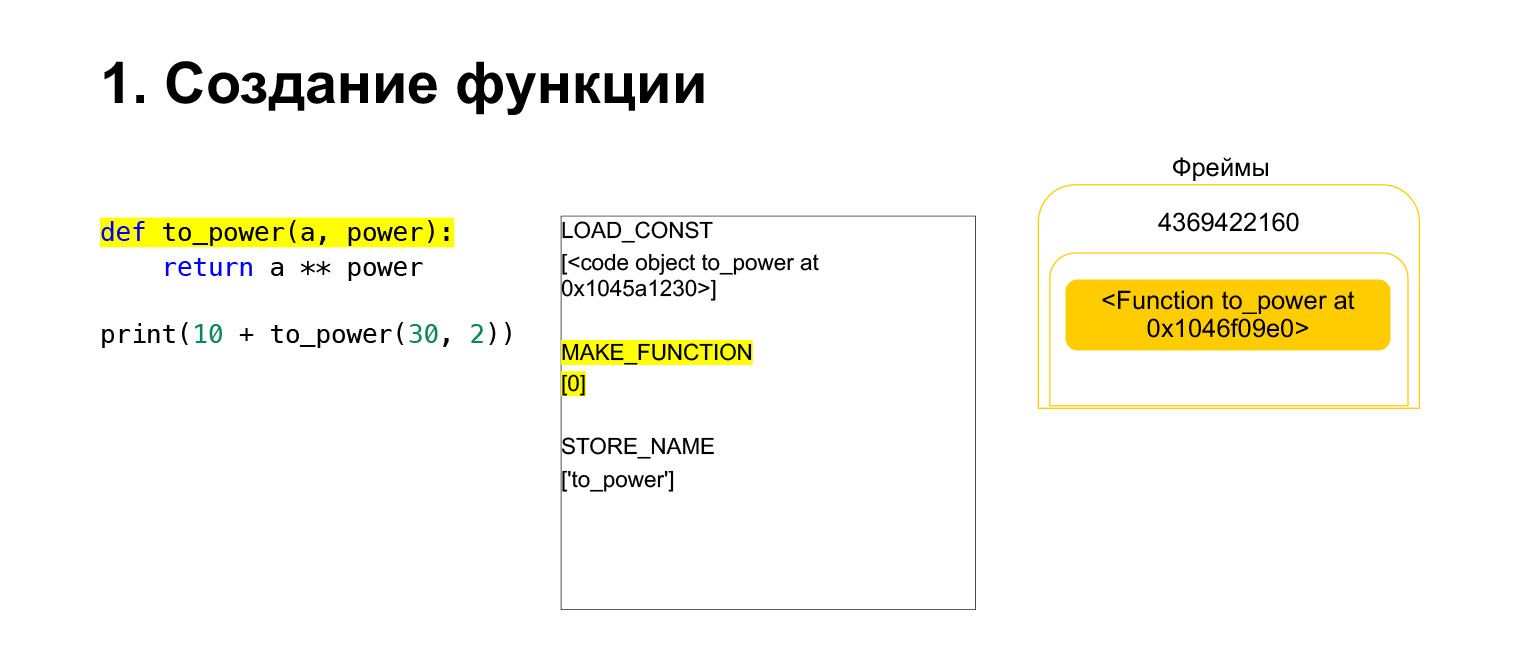
Then Python performs opcode MAKE_FUNCTION. MAKE_FUNCTION obviously makes a function. It expects you had a CodeObject on the stack. It does some action, creates a function, and pushes the function back onto the stack. Now you have FUNCTION instead of CodeObject that was on the frame stack. And now this function needs to be placed in the to_power variable so that you can refer to it.
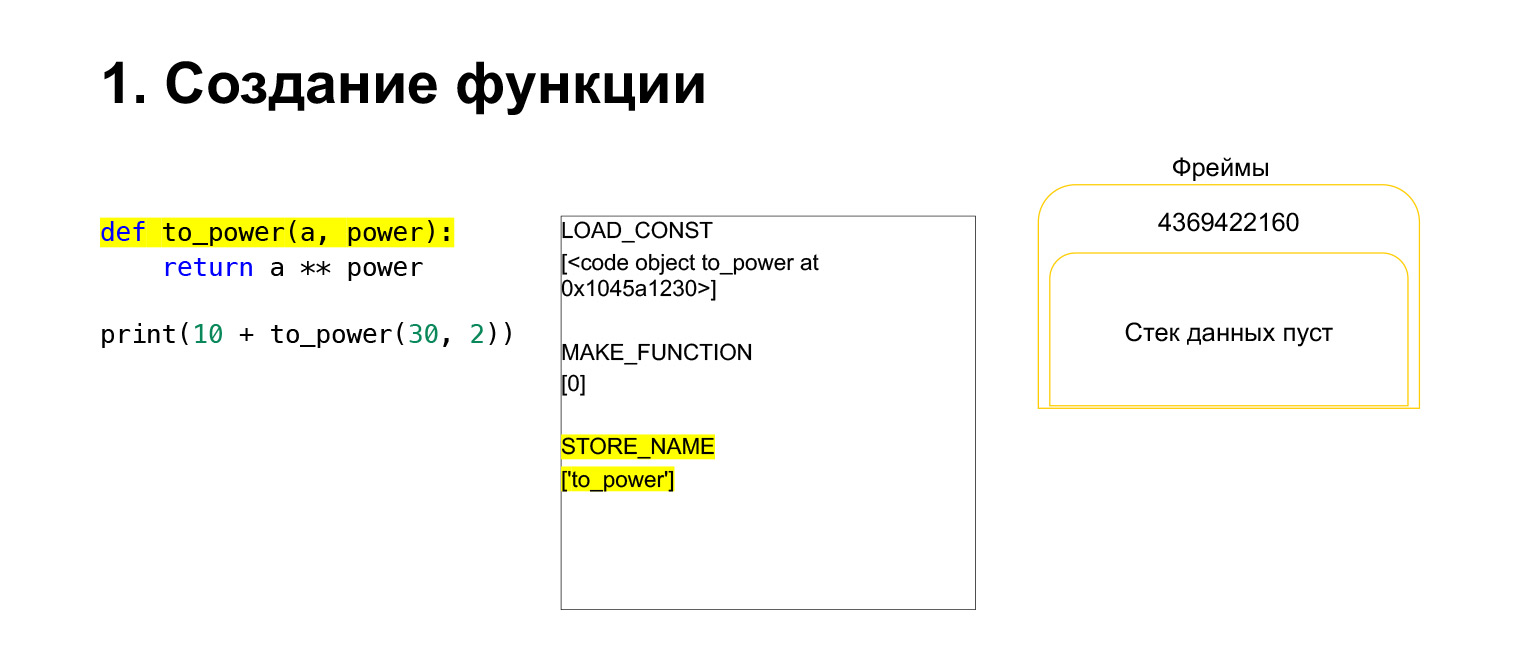
Opcode STORE_NAME is executed, it is placed in the to_power variable. We had a function on the stack, now it is the to_power variable, you can refer to it.
Next, we want to print 10 + the value of this function.
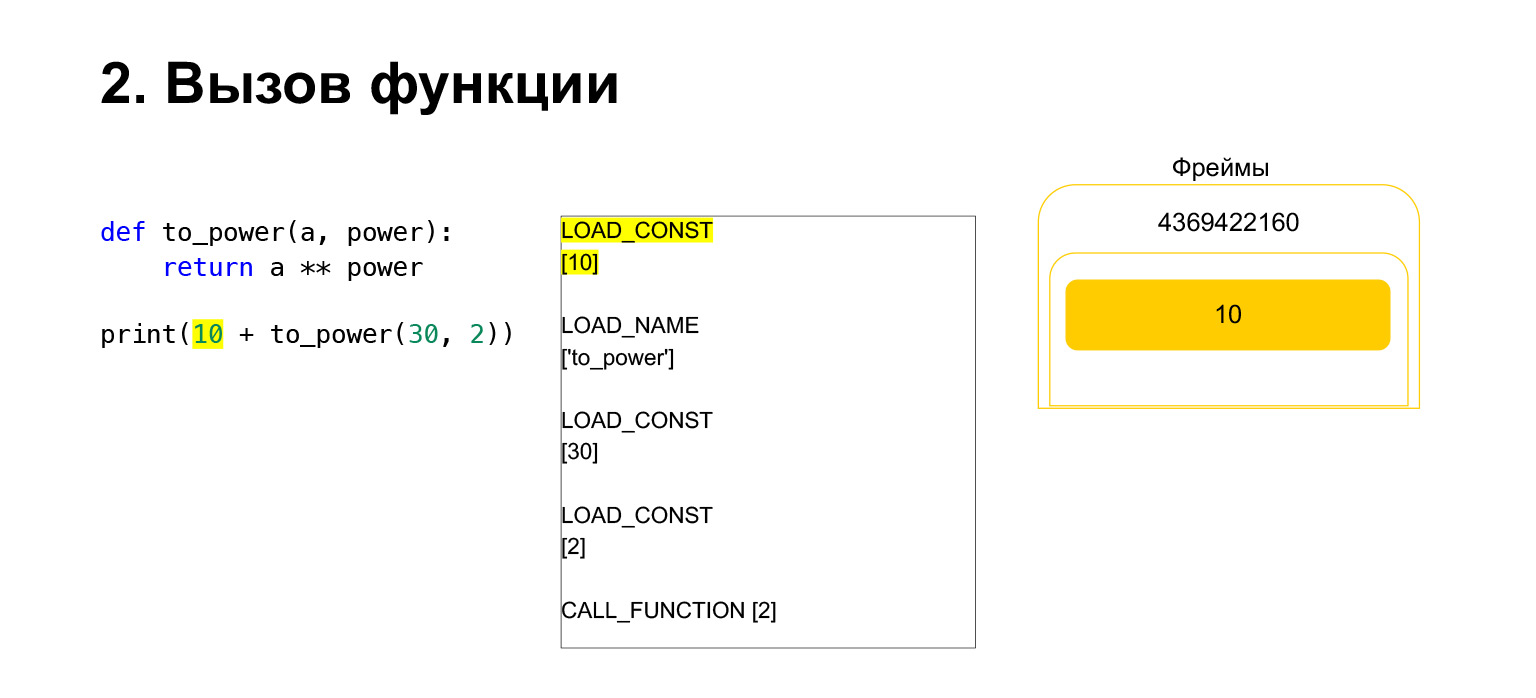
What does Python do? This was converted to bytecode. The first opcode we have is LOAD_CONST. We load the top ten onto the stack. A dozen appeared on the stack. Now we need to execute to_power.

The function is performed as follows. If it has positional arguments - we won't look at the rest for now - then first Python puts the function itself on the stack. Then it puts in all the arguments and calls CALL_FUNCTION with the argument number of function arguments.
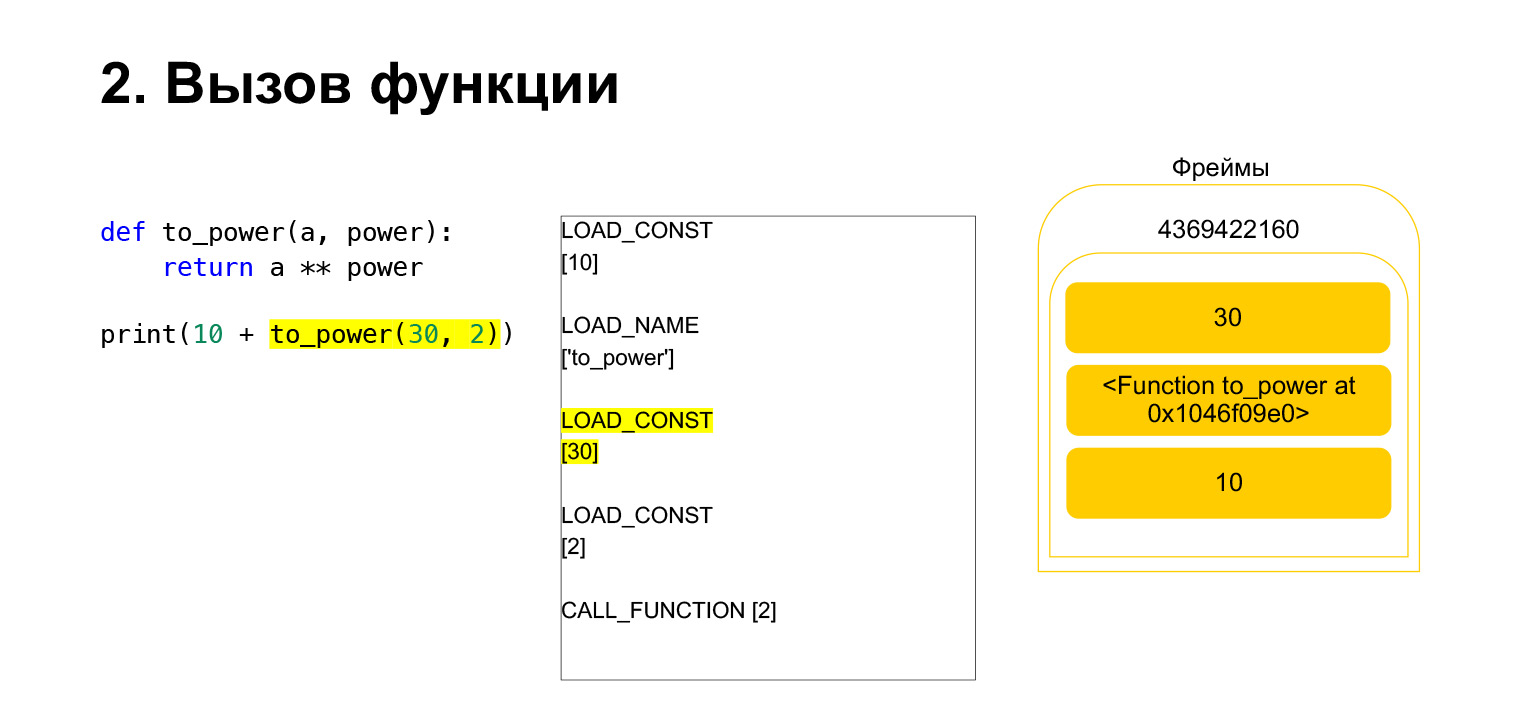
We loaded the first argument onto the stack, this is a function.
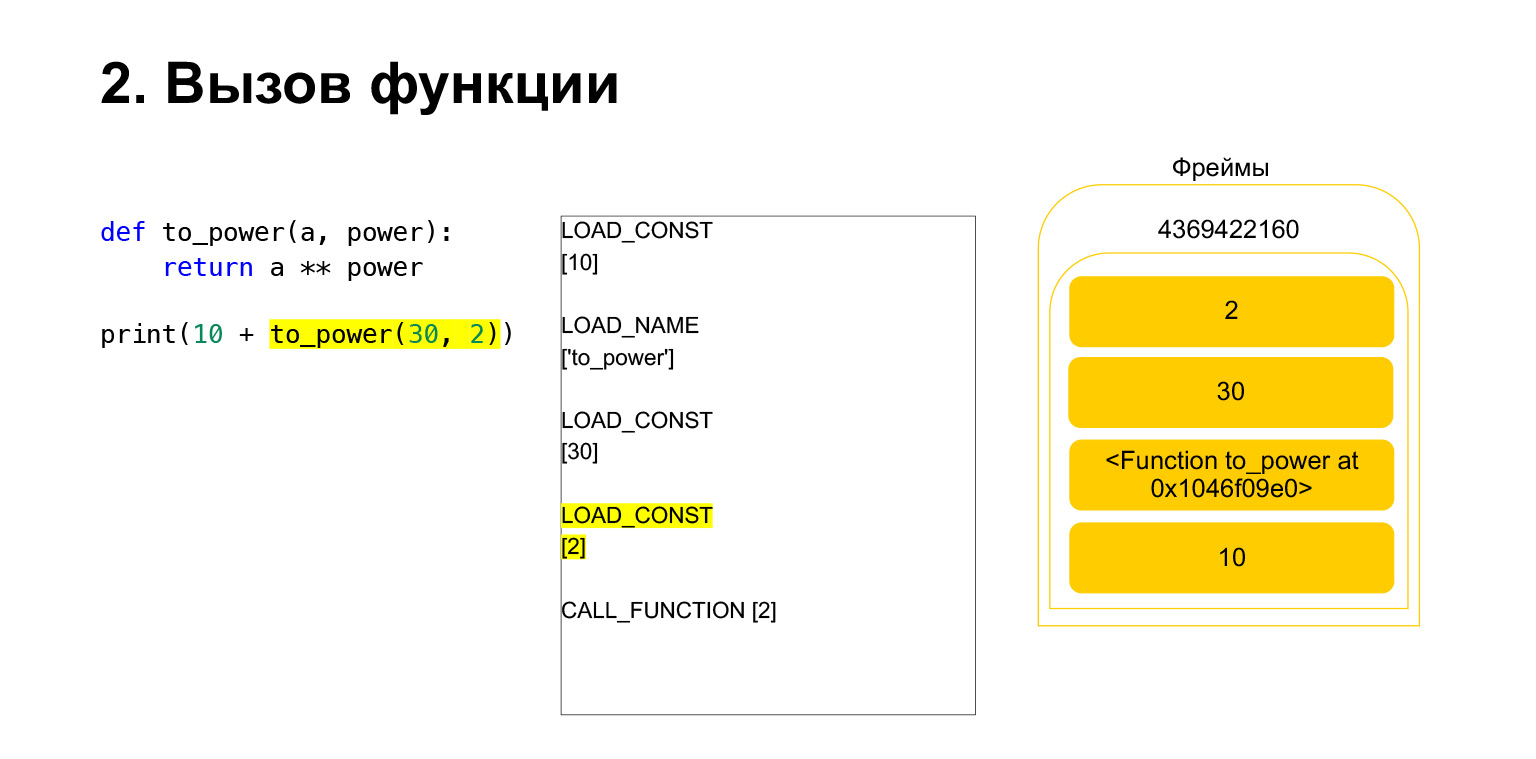
We loaded two more arguments onto the stack - 30 and 2. Now we have a function and two arguments on the stack. The top of the stack is on top. CALL_FUNCTION is waiting for us. We say: CALL_FUNCTION (2), that is, we have a function with two arguments. CALL_FUNCTION expects to have two arguments on the stack, followed by a function. We have it: 2, 30 and FUNCTION.
Opcode in progress.
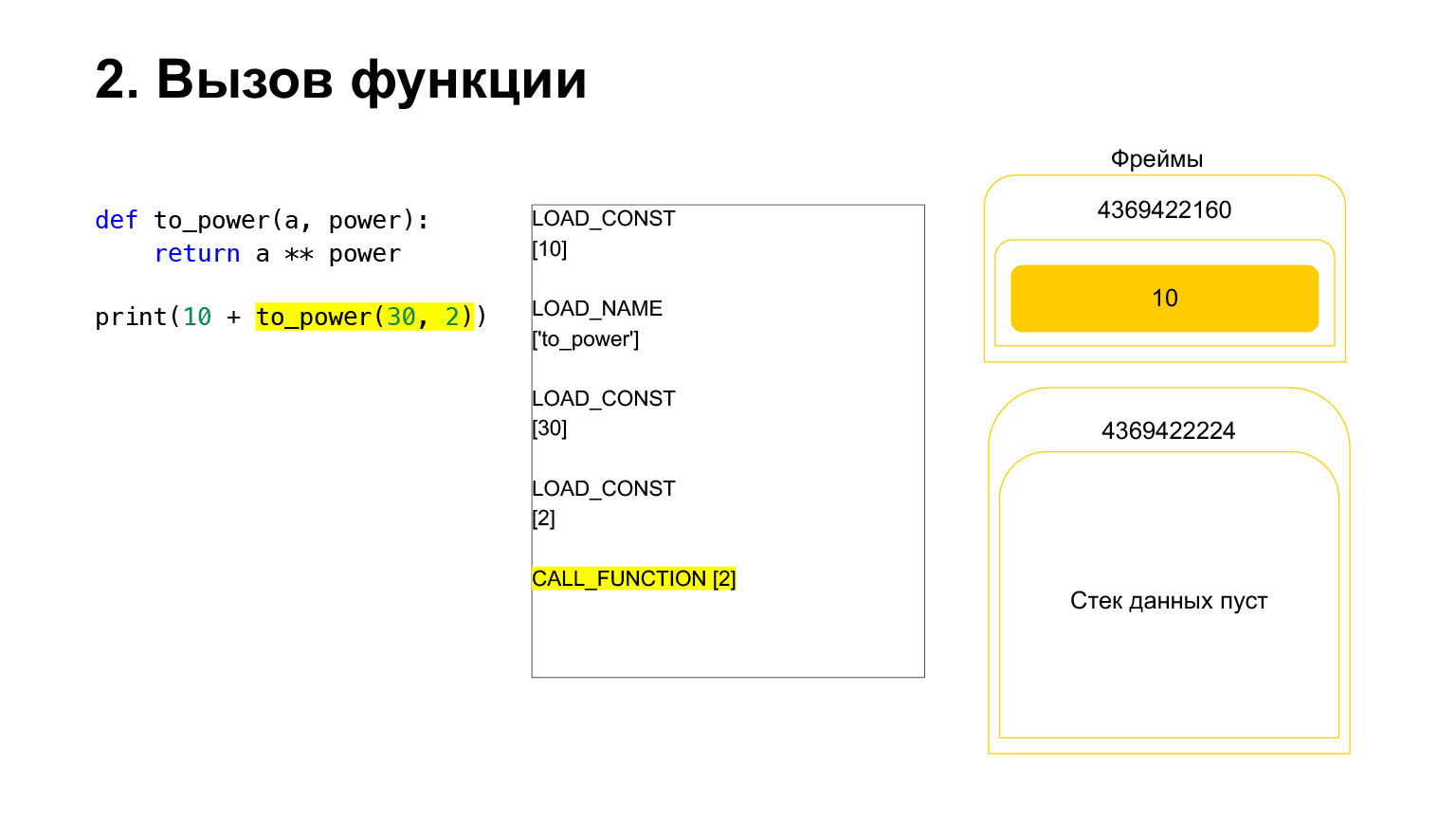
For us, accordingly, that stack leaves, a new function is created, in which the execution will now take place.
The frame has its own stack. A new frame has been created for its function. It is still empty.
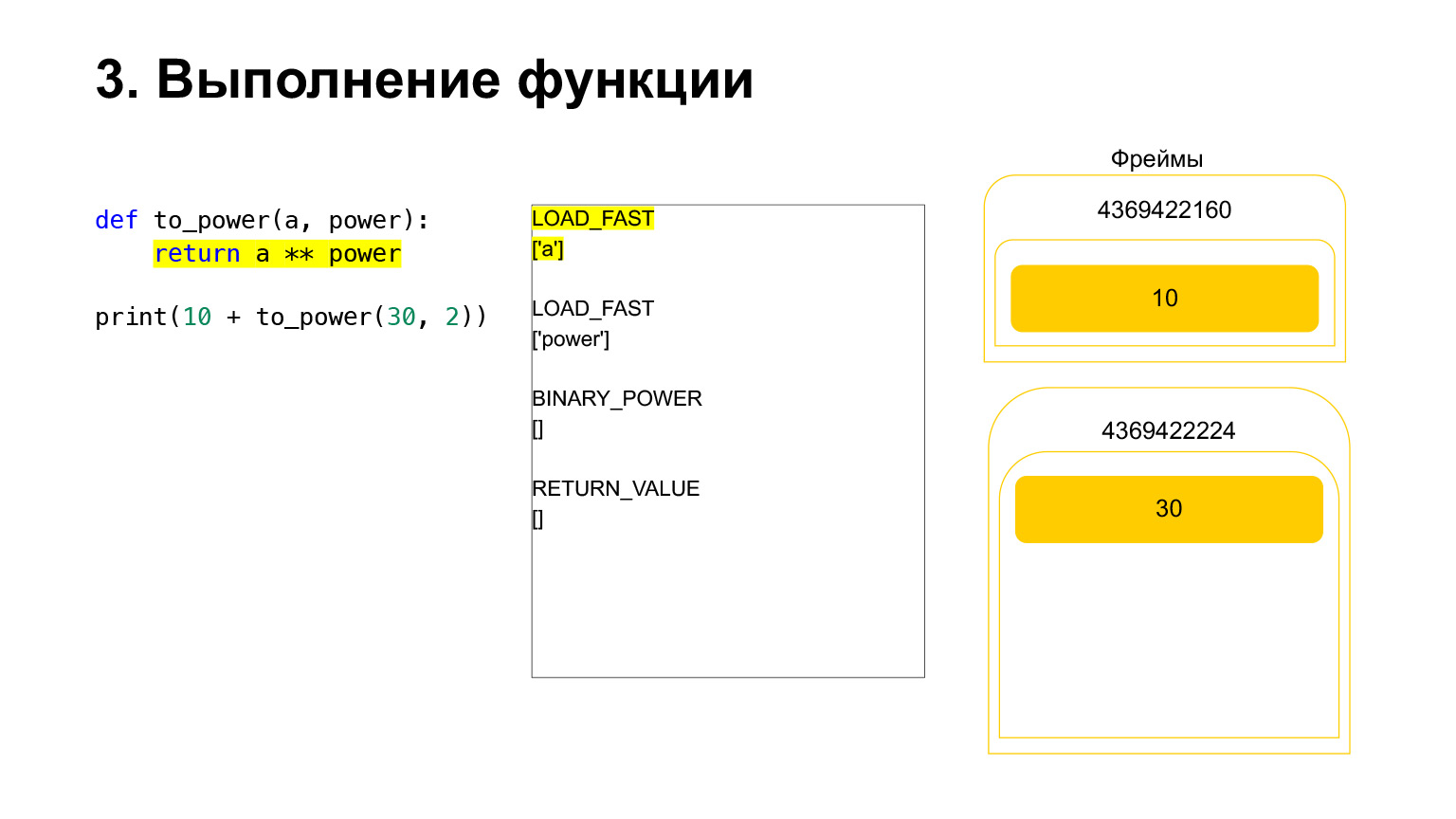
Further execution takes place. It's already easier here. We need to raise A to the power. We load the value of the variable A - 30 onto the stack. The value of the variable power - 2.
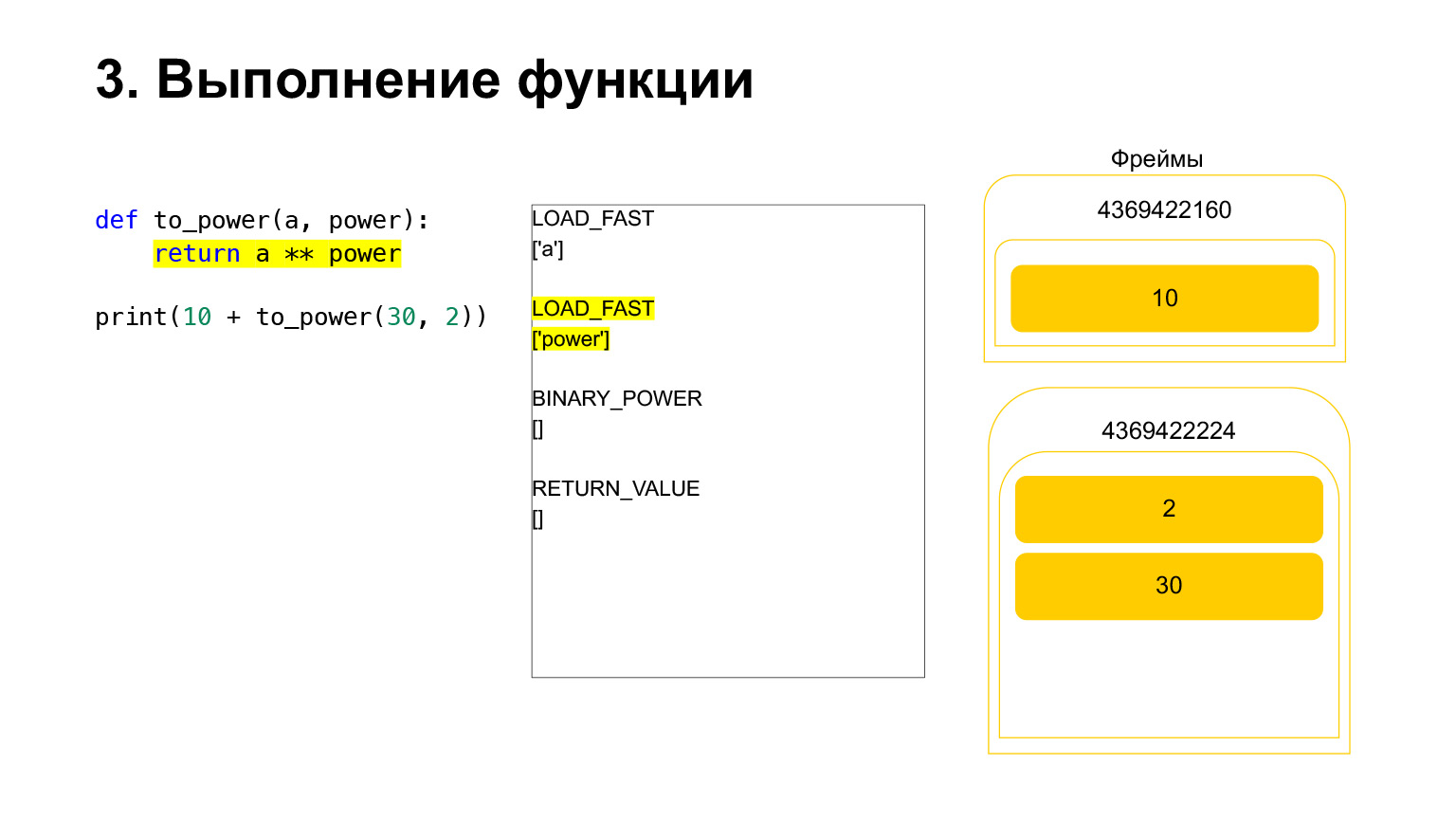
And the opcode BINARY_POWER is executed.
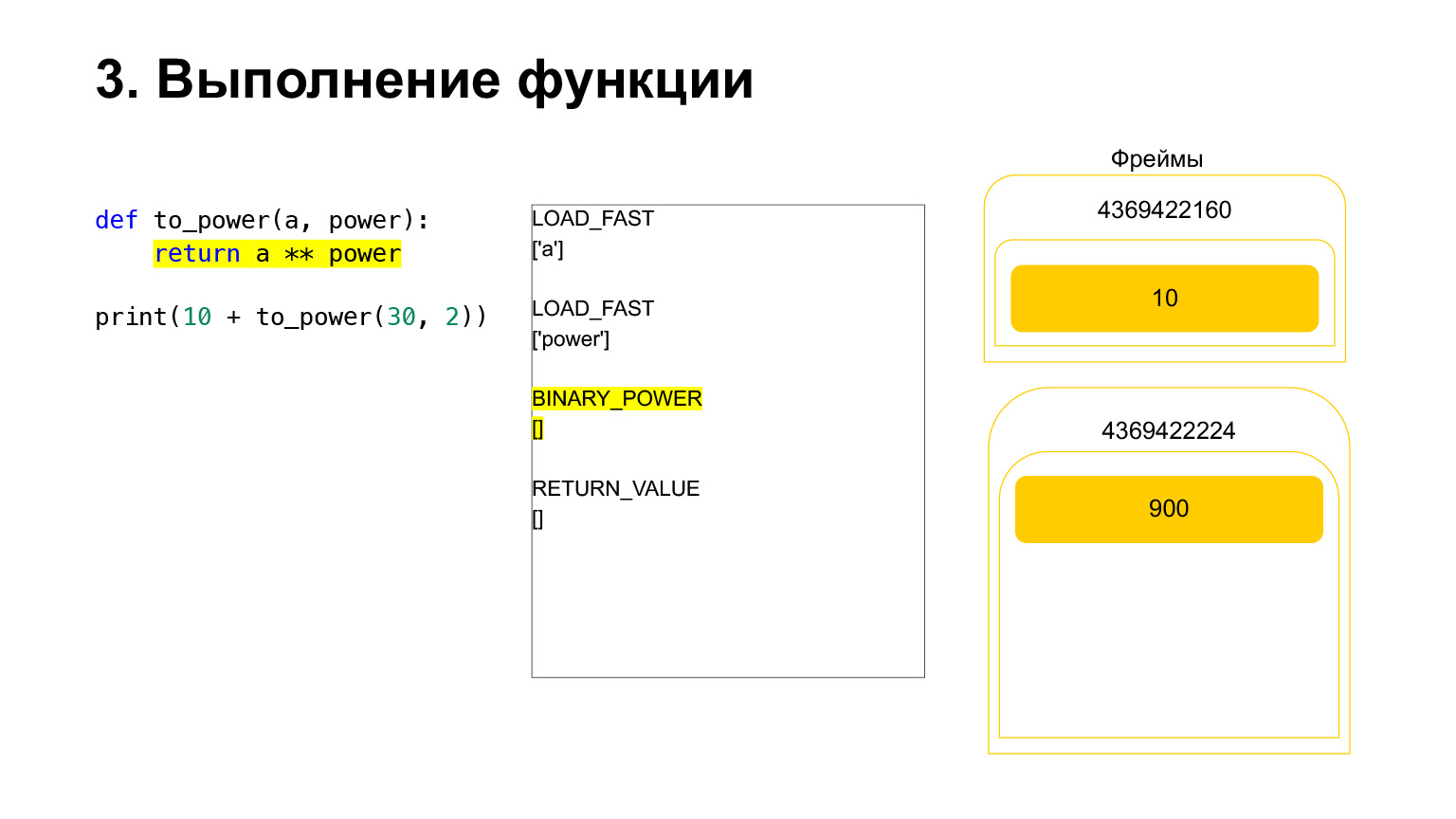
We raise one number to the power of another and put it back on the stack. It turned out 900 on the function stack.
The next opcode RETURN_VALUE will return the value from the stack to the previous frame.

This is how the execution takes place. The function has completed, the frame will most likely clear if it has no references and there are two numbers on the frame of the previous function.

Then everything is about the same. Addition occurs.
(...) Let's talk about types and PyObject.
Typing

An object is a sish structure in which there are two main fields: the first is the number of references to this object, the second is the type of the object, of course, a reference to the type of the object.
Other objects inherit from PyObject by enclosing it. That is, if we look at a float, a floating point number, the structure there is PyFloatObject, then it has a HEAD, which is a PyObject structure, and, additionally, data, that is, double ob_fval, where the value of this float itself is stored.

And this is the type of object. We just looked at the type in PyObject, it's a struct that denotes a type. In fact, this is also a C-structure that contains pointers to functions that implement the behavior of this object. That is, there is a very large structure there. It has functions specified that are called if, for example, you want to add two objects of this type. Or you want to subtract, call this object, or create it. Anything you can do with types must be specified in this structure.

For example, let's look at int, integers in Python. Also a very abbreviated version. What might we be interested in? Int has tp_name. You can see that there is tp_hash, we can get hash int. If we call hash on int, this function will be called. tp_call we have zero, not defined, this means that we cannot call int. tp_str - string cast not defined. Python has a str function that can cast to a string.
It didn't get on the slide, but you all already know that int can still be printed. Why is zero here? Because there is also tp_repr, Python has two string-passing functions: str and repr. More detailed casting to string. It is actually defined, it just didn't get on the slide, and it will be called if you actually lead to a string.
At the very end, we see tp_new - a function that is called when this object is created. tp_init we have zero. We all know that int is not a mutable type, immutable. After creating it, there is no point in changing it, initializing it, so there is a zero.

Let's also look at Bool for example. As some of you may know, Bool in Python actually inherits from int. That is, you can add Bool, share with each other. This, of course, cannot be done, but it is possible.
We see that there is a tp_base - a pointer to the base object. Everything besides tp_base are the only things that have been overridden. That is, it has its own name, its own presentation function, where it is not a number that is written, but true or false. Representation as Number, some logical functions are overridden there. Docstring is its own and its creation. Everything else comes from int.

I'll tell you very briefly about lists. In Python, a list is a dynamic array. A dynamic array is an array that works like this: you initialize a memory area in advance with some dimension. Add elements there. As soon as the number of elements exceeds this size, you expand it with a certain margin, that is, not by one, but by some value more than one, so that there is a good asin point.
In Python, the size grows as 0, 4, 8, 16, 25, that is, according to some kind of formula that allows us to do the insertion asymptotically for a constant. And you can see there is an excerpt from the insert function in the list. That is, we are doing resize. If we don't have resize, we throw an error and assign the element. In Python, this is a normal dynamic array implemented in C.
(...) Let's talk about dictionaries briefly. They are everywhere in Python.
Dictionaries
We all know that in objects, the entire composition of classes is contained in dictionaries. A lot of things are based on them. Dictionaries in Python in a hash table.
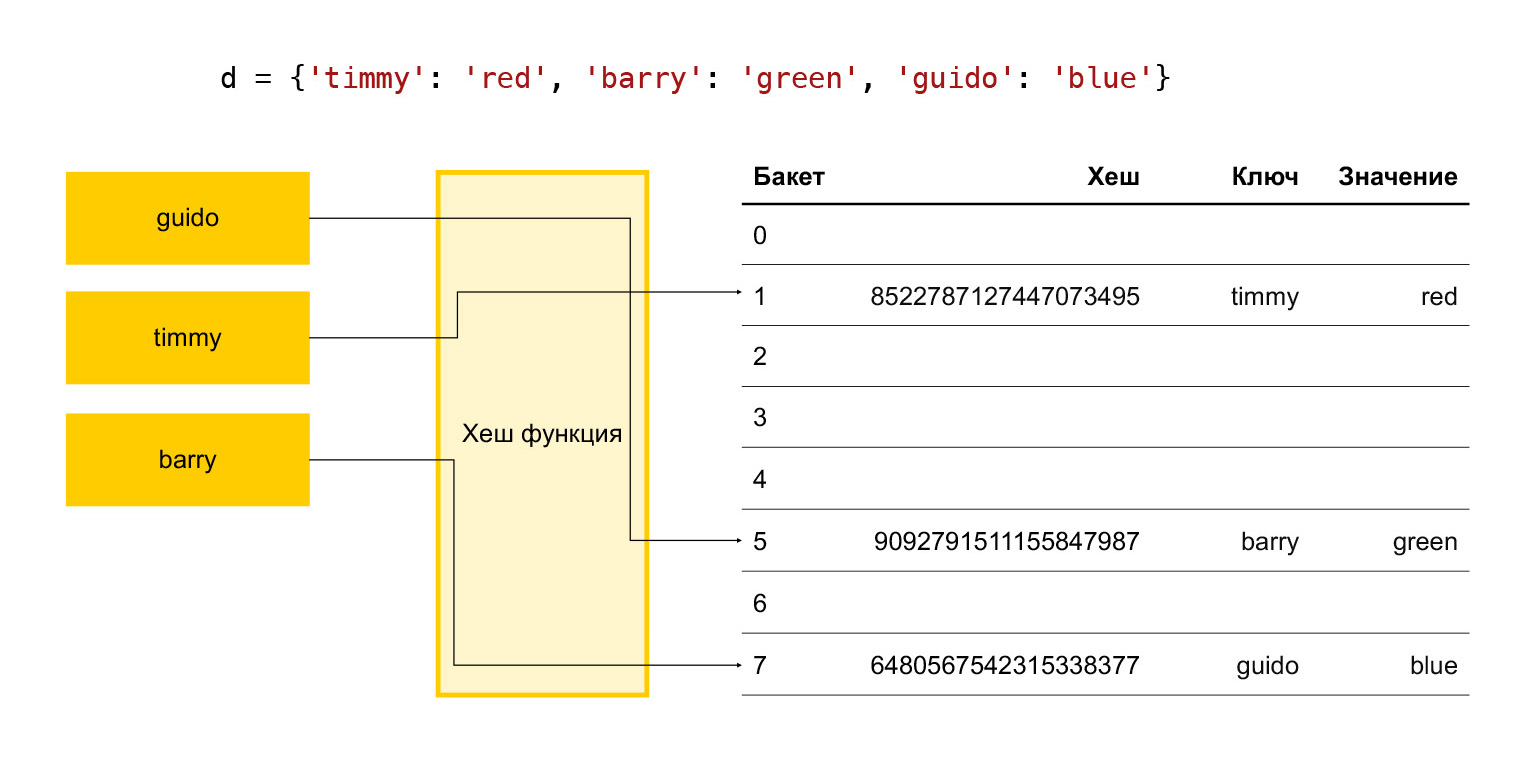
In short, how does a hash table work? There are some keys: timmy, barry, guido. We want to put them in a dictionary, we run each key through a hash function. It turns out a hash. We use this hash to find the bucket. A bucket is simply a number in an array of elements. Final modulo division occurs. If the bucket is empty, we just put the desired item in it. If it is not empty and there is already some element there, then this is a collision and we choose the next bucket, see if it is free or not. And so on until we find a free bucket.
Therefore, in order for the add operation to take place in an adequate time, we need to constantly keep a certain number of buckets free. Otherwise, when approaching the size of this array, we will search for a free bucket for a very long time, and everything will slow down.
Therefore, it is empirically accepted in Python that one third of the array elements are always free. If their number is more than two-thirds, the array expands. This is not good, because a third of the elements are wasted, nothing useful is stored.

Link from the slide
Therefore, since version 3.6, Python has done such a thing. On the left you can see how it was before. We have a sparse array where these three elements are stored. Since 3.6, they decided to make such a sparse array a regular array, but at the same time store the indices of the bucket elements in a separate indices array.
If we look at the array of indices, then in the first bucket we have None, in the second there is an element with index 1 from this array, etc.
This allowed, firstly, to reduce memory use, and secondly, we also got it out of the box for free ordered array. That is, we add elements to this array, conditionally, with the usual sish append, and the array is automatically ordered.
There are some interesting optimizations that Python uses. For these hash tables to work, we need to have an element comparison operation. Imagine we put an element in a hash table, and then we want to take an element. We take the hash, go to the bucket. We see: the bucket is full, there is something there. But is this the element we need? Maybe there was a collision when it was placed and the item actually fit in another bucket. Therefore, we must compare keys. If the key is wrong, we use the same next bucket search mechanism that is used for collision resolution. And we go further.

Link from the slide
Therefore, we need to have a key comparison function. In general, the object comparison feature can be very expensive. Therefore, such optimization is used. First, we compare the item IDs. ID in CPython is, as you know, a position in memory.
If the IDs are the same, then they are the same objects and, of course, they are equal. Then we return True. If not, look at the hashes. The hash should be a pretty fast operation if we haven't overridden somehow. We take hashes from these two objects and compare. If their hashes are not equal, then the objects are definitely not equal, so we return False.
And only in a very unlikely case - if our hashes are equal, but we don't know if it's the same object - only then we compare the objects themselves.
An interesting little thing: you cannot insert anything into keys during iteration. This is mistake.

Under the hood, the dictionary has a variable called version, which stores the version of the dictionary. When you change the dictionary, version changes, Python understands this and throws you an error.

What can dictionaries be used for in a more practical example? In Taxi we have orders, and orders have statuses that can change. When you change the status, you must perform certain actions: send SMS, record orders.
This logic is written in Python. In order not to write a huge if like “if the order status is such and such, do this”, there is a certain dict, in which the key is the order status. And to VALUE there is a tuple, which contains all the handlers that must be executed when transitioning to this status. This is a common practice, in fact, it is a replacement for the switch switch.

A few more things by type. I'll tell you about immutable. These are immutable data types, and mutable are, respectively, mutable types: dicts, classes, class instances, sheets, and maybe something else. Almost everything else is strings, ordinary numbers - they are immutable. What are mutable types for? First, they make the code easier to understand. That is, if you see in the code that something is a tuple, do you understand that it does not change further, and this makes it easier for you to read the code? understand what will happen next. In tuple ds you cannot type items. You will understand this, and it will help in reading you and all the people who will read the code for you.
Therefore, there is a rule: if you do not change something, it is better to use immutable types. It also leads to faster work. There are two constants that tuple uses: pit_tuple, tap_tuple, max, and CC. What's the point? For all tuples up to size 20, a specific allocation method is used, which speeds up this allocation. And there can be up to two thousand such objects of each type, a lot. This is much faster than sheets, so if you use tuple you will be faster.
There are also runtime checks. Obviously, if you are trying to plug something into an object, and it does not support this function, then there will be an error, some kind of understanding that you did something wrong. Keys in a dict can only be objects that have a hash that do not change during their lifetime. Only immutable objects satisfy this definition. Only they can be dict keys.

What does it look like in C? Example. On the left is a tuple, on the right is a regular list. Here, of course, not all the differences are visible, but only those that I wanted to show. In list in the tp_hash field we have NotImplemented, that is, list has no hash. In tuple there is some function that will actually return a hash to you. This is exactly why tuple, among other things, can be a dict key, and list cannot.
The next thing highlighted is the item assignment function, sq_ass_item. In list it is, in tuple it is zero, that is, you naturally cannot assign anything to tuple.

One more thing. Python doesn't copy anything until we ask it. This should also be remembered. If you want to copy something, use, say, the copy module, which has a copy.deepcopy function. What is the difference? copy copies the object, if it is a container object, such as a sibling list. All references that were in this object are inserted into the new object. And deepcopy recursively copies all objects within this container and beyond.
Or, if you want to quickly copy a list, you can use a single colon slice. You will get a copy, such a shortcut is simple.
(...) Next, let's talk about memory management.
Memory management

Let's take our sys module. It has a function that lets you see if it is using any memory. If you start the interpreter and look at the statistics of memory changes, you will see that you have created a lot of objects, including small ones. And these are only those objects that are currently created.
In fact, Python creates a lot of small objects at runtime. And if we used the standard malloc function to allocate them, we would very quickly find ourselves in the fact that our memory is fragmented and, accordingly, memory allocation is slow.

This implies the need to use your own memory manager. In short, how does it work? Python allocates to itself blocks of memory, called arena, 256 kilobytes each. Inside, he slices himself into pools of four kilobytes, this is the size of a memory page. Inside the pools, we have blocks of different sizes, from 16 to 512 bytes.
When we try to allocate less than 512 bytes to an object, Python selects in its own way a block that is suitable for this object and places the object in this block.
If the object is deallocated, deleted, then this block is marked as free. But it is not given to the operating system, and at the next location we can write this object into the same block. This speeds up memory allocation a lot.

Freeing memory. Earlier we saw the PyObject structure. She has this refcnt - reference count. It works very simply. When you reference this object, Python increments the reference count. As soon as you have an object, the reference disappears to it, you deallocate the reference count.
What is highlighted in yellow. If refcnt is not zero, then we are doing something there. If refcnt is zero, then we immediately deallocate the object. We are not waiting for any garbage collector, nothing, but right at this moment we clear the memory.
If you come across the del method, it simply removes the binding of the variable to the object. And the __del__ method, which you can define in the class, is called when the object is actually removed from memory. You will call del on the object, but if it still has references, the object will not be deleted anywhere. And its Finalizer, __del__, will not be called. Although they are called very similar.
A short demo on how you can see the number of links. There is our favorite sys module, which has a getrefcount function. You can see the number of links to an object.

I'll tell you more. An object is made. The number of links is taken from it. Interesting detail: variable A points to TaxiOrder. You take the number of links, you will get "2" printed. It would seem why? We have one object reference. But when you call getrefcount, this object is wrapped around the argument inside the function. Therefore, you already have two references to this object: the first is the variable, the second is the function argument. Therefore, "2" is printed.
The rest is trivial. We assign one more variable to the object, we get 3. Then we remove this binding, we get 2. Then we remove all references to this object, and the finalizer is called, which will print our line.

(...) There is another interesting feature of CPython, which cannot be built on, and it seems that it is not said about it anywhere in the docs. Integers are often used. It would be wasteful to recreate them every time. Therefore, the most commonly used numbers, the Python developers chose the range from –5 to 255, they are Singleton. That is, they are created once, lie somewhere in the interpreter, and when you try to get them, you get a reference to the same object. We took A and B, ones, printed them, compared their addresses. Got True. And we have, let's say, 105 references to this object, simply because now there are so many.
If we take some number larger - for example, 1408 - these objects are not equal for us and there are, respectively, two references to them. In fact, one.
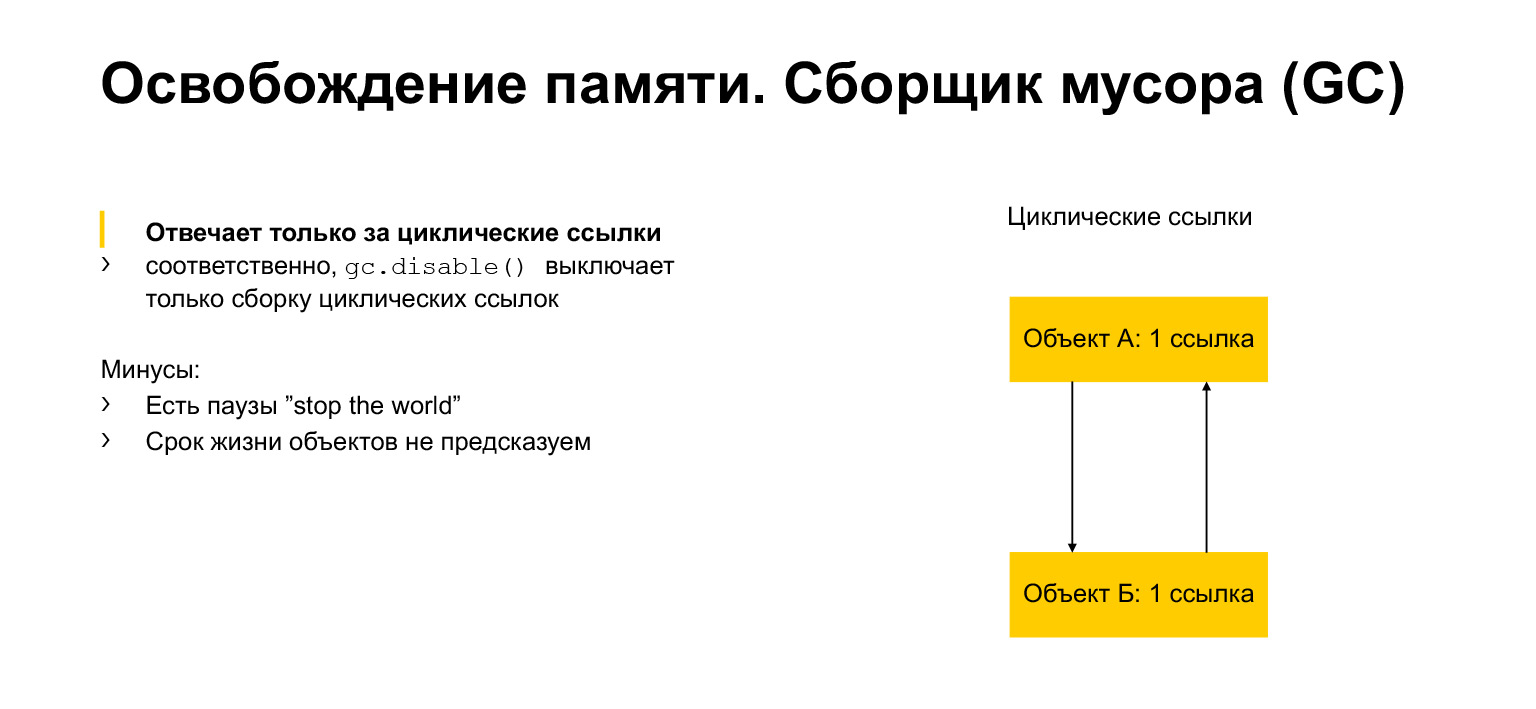
We talked a little about memory allocation and freeing. Now let's talk about the garbage collector. What is it for? It would seem that we have a number of links. Once no one has referenced the object, we can delete it. But we can have circular links. An object can refer to itself, for example. Or, as in the example, there may be two objects, each referring to a neighbor. This is called a cycle. And then these objects can never give a reference to another object. But at the same time, for example, they are unattainable from another part of the program. We need to remove them, because they are inaccessible, useless, but they have links. This is exactly what the garbage collector module is for. It detects cycles and removes these objects.
How does he work? First, I will briefly talk about generations, and then about the algorithm.
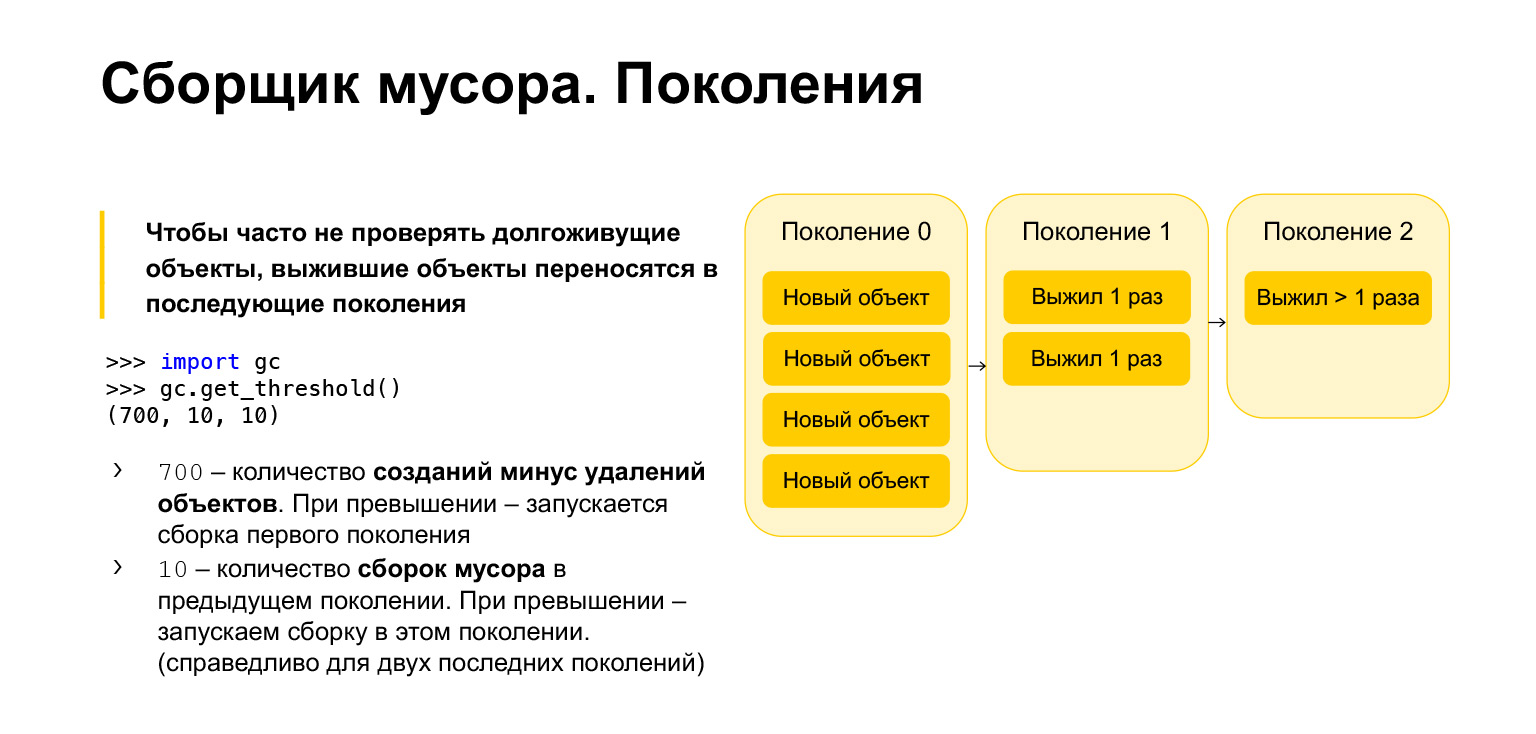
To optimize the speed of the garbage collector in Python, it is generational, that is, it works using generations. There are three generations. What are they needed for? It is clear that those objects that have been created quite recently are more likely to be unnecessary than long-lived objects. Let's say you create something in the course of functions. Most likely, it will not be needed when exiting the function. It's the same with loops, with temporary variables. All of these objects need to be cleaned more often than those that have been around for a long time.
Therefore, all new objects are placed in the zero generation. This generation is cleaned periodically. Python has three parameters. Each generation has its own parameter. You can get them, import the garbage collector, call the get_threshold function, and get these thresholds.
By default there are 700, 10, 10. What is 700? This is the number of object creation minus the number of deletions. As soon as it exceeds 700, a new generation garbage collection is started. And 10, 10 is the number of garbage collections in the previous generation, after which we need to start garbage collection in the current generation.
That is, when we clear the zero generation 10 times, we will start the build in the first generation. After cleaning the first generation 10 times, we will start the build in the second generation. Accordingly, objects move from generation to generation. If they survive, they move to the first generation. If they survived a garbage collection in the first generation, they are moved to the second. From the second generation, they no longer move anywhere, they remain there forever.
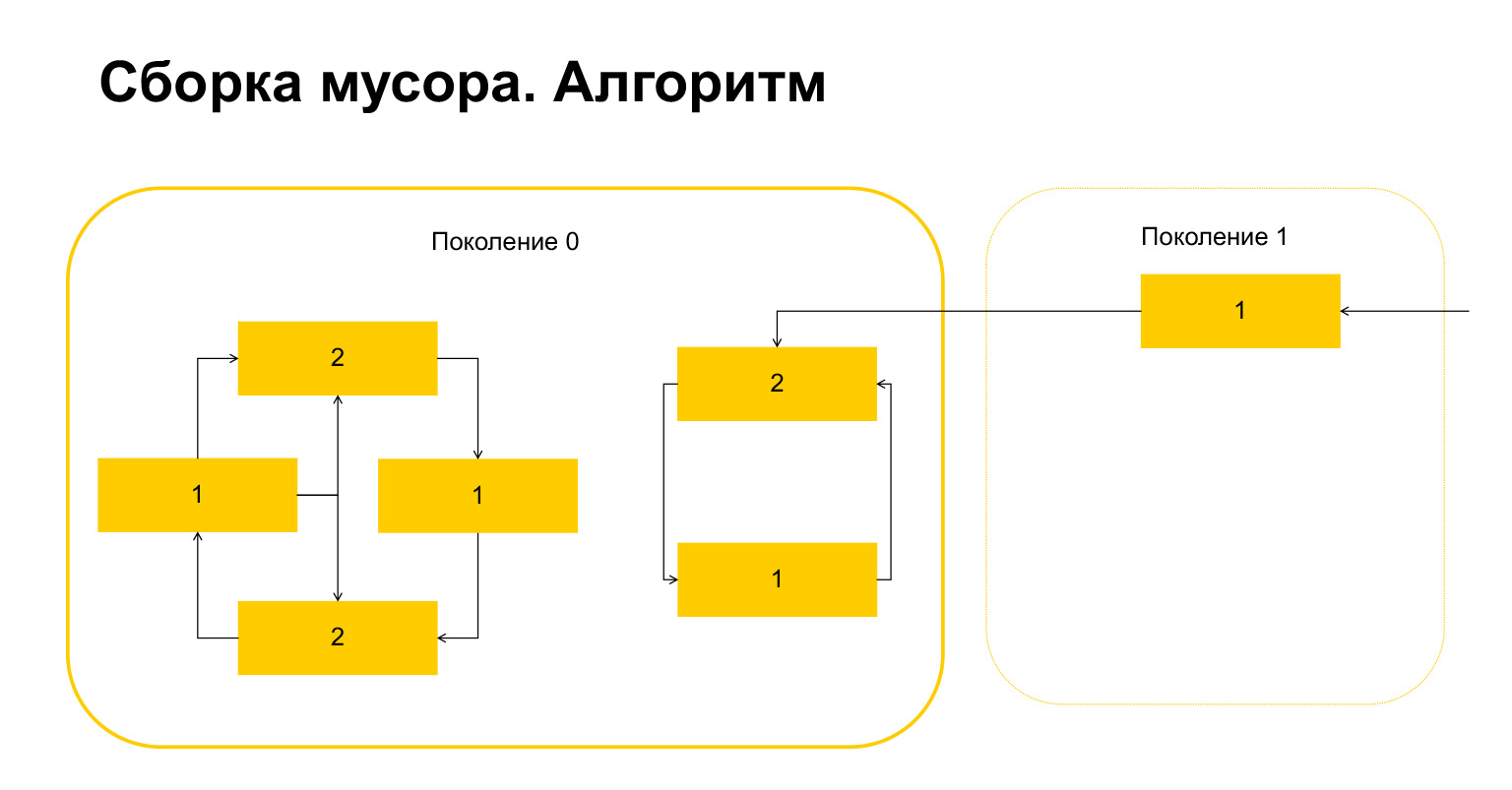
How does garbage collection work in Python? Let's say we start garbage collection in generation 0. We have some objects, they have cycles. There is a group of objects on the left that refer to each other, and the group on the right also refers to each other. An important detail - they are also referenced from generation 1. How does Python detect loops? First, a temporary variable is created for each object and the number of references to this object is written into it. This is reflected on the slide. We have two links to the object on top. But an object from generation 1 is being referenced from outside by someone. Python remembers this. Then (important!) It goes through each object within the generation and deletes, decrements the counter by the number of references within this generation.
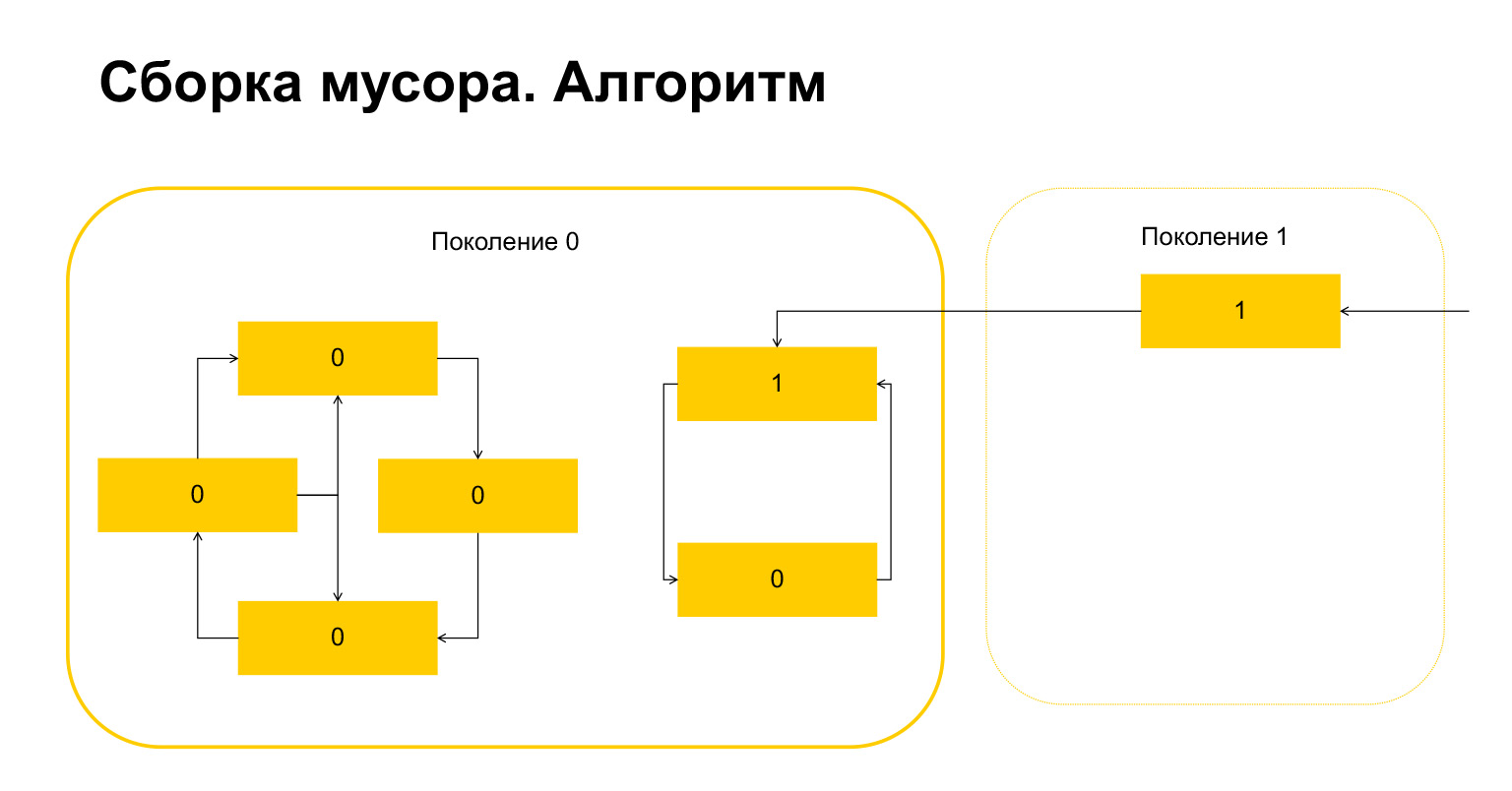
Here's what happened. For objects that only refer to each other within a generation, this variable has automatically become equal to zero by construction. Only objects that are referenced from the outside have a unit.
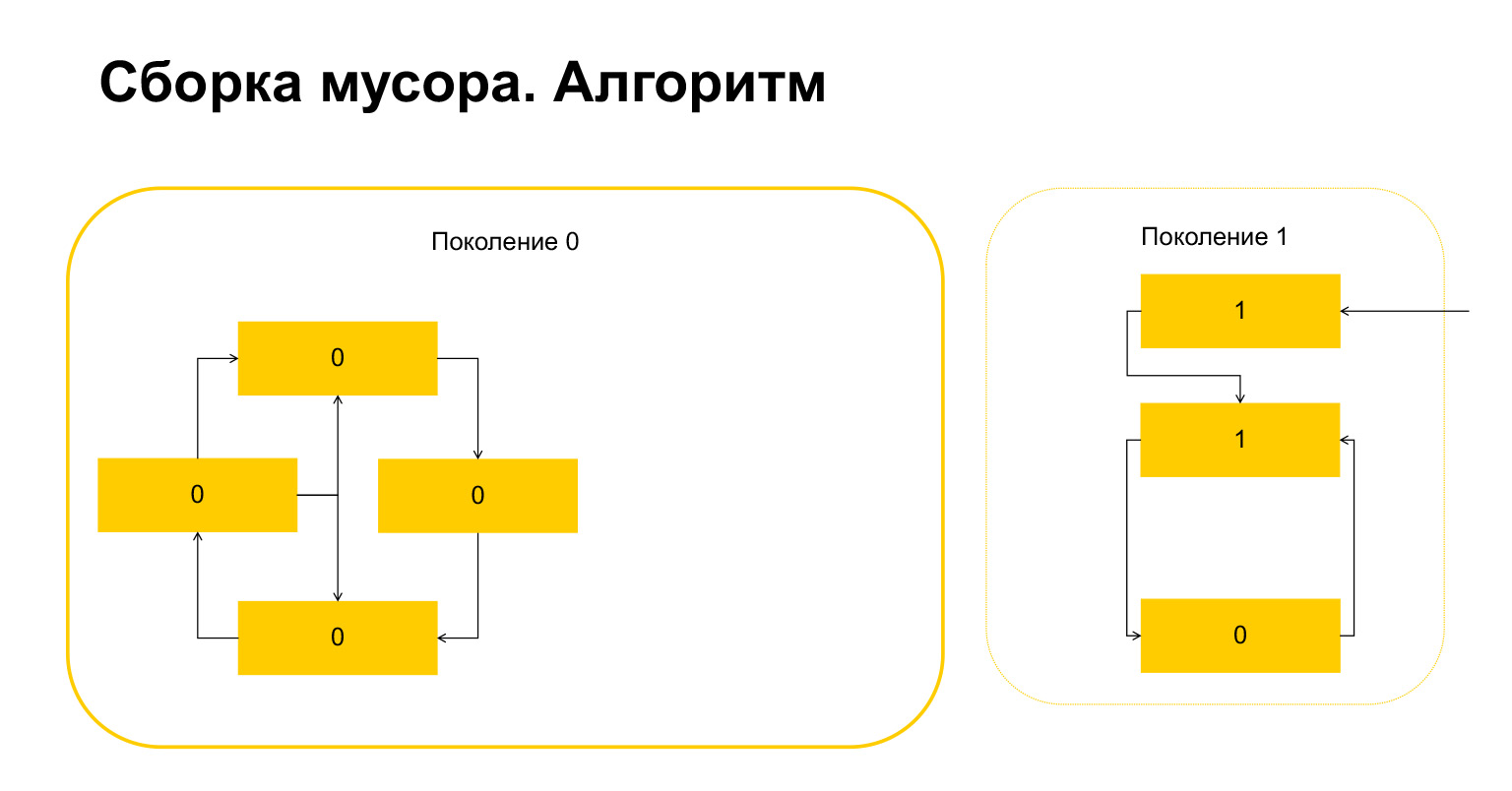
What does Python do next? He, since there is one here, understands that these objects are referenced from outside. And we can not delete either this object or this one, because otherwise we will get an invalid situation. Therefore, Python transfers these objects to generation 1, and everything that is left in generation 0, it deletes, cleans up. Everything about garbage collector.
(...) Move on. I'll tell you very briefly about generators.
Generators

Here, unfortunately, there will be no introduction to generators, but let's try to tell you what a generator is. This is a kind of, relatively speaking, function that remembers the context of its execution using the word yield. At this point, it returns a value and remembers the context. You can then refer to it again and get the value it gives out.
What can you do with generators? You can yield a generator, it will return values to you, remember the context. You can return the generator. In this case, the StopIteration execution will be thrown, the value inside which will contain the value, in this case Y.
Lesser known fact: You can send some values to the generator. That is, you call the send method on the generator, and Z - see example - will be the value of the yield expression that the generator will invoke. If you want to control the generator, you can pass values there.
You can also throw exceptions there. The same thing: take a generator object, throw it. You throw a mistake there. You will have an error in place of the last yield. And close - you can close the generator. Then the GeneratorExit execution is raised, and the generator is expected to yield nothing else.

Here I just wanted to talk about how it works in CPython. You actually have an execution frame in your generator. And as we remember, FrameObject contains the entire context. From this it seems clear how the context is preserved. That is, you just have a frame in the generator.

When you execute a generator function, how does Python know you don't need to execute it, but create a generator? The CodeObject we looked at has flags. And when you call a function, Python checks its flags. If the CO_GENERATOR flag is present, it understands that the function does not need to be executed, but only needs to create a generator. And he creates it. PyGen_NewWithQualName function.

How is the execution going? From GENERATOR_FUNCTION, the generator first calls GENERATOR_Object. Then you can call GENERATOR_Object using next to get the next value. How does next call happen? Its frame is taken from the generator, it is stored in the variable F. And sent to the main loop of the interpreter EvalFrameEx. You are executed as in the case of a normal function. The YIELD_VALUE mapcode is used to return, pause the execution of the generator. It remembers all the context in the frame and stops executing. This was the penultimate topic.
(...) A quick recap of what exceptions are and how they are used in Python.
Exceptions

Exceptions are a way to handle error situations. We have a try block. We can write in try those things that can throw exceptions. Let's say we can raise an error using the word raise. With the help of except we can catch certain types of exceptions, in this case SomeError. With except, we catch all exceptions without expression. The else block is used less often, but it exists and will only be executed if no exceptions were thrown. The finally block will execute anyway.
How do exceptions work in CPython? In addition to the execution stack, each frame also has a stack of blocks. It is better to use an example.


A block stack is a stack on which blocks are written. Each block has a type, Handler, a handler. Handler is the bytecode address to jump to in order to process this block. How does it work? Let's say we have some code. We made a try block, we have an except block in which we catch RuntimeError exceptions, and a finally block, which should be in any case.
This all degenerates into this bytecode. At the very beginning of the bytecode on the try block, we see two two opcode SETUP_FINALLY with arguments to 40 and to 12. These are the addresses of the handlers. When SETUP_FINALLY is executed, a block is placed on the block stack, which says: to process me, go in one case to the 40th address, in the other - to the 12th.
12 down the stack is except, the line containing the else RuntimeError. This means that when we have an exception, we will look at the block stack in search of a block with the SETUP_FINALLY type. Find the block in which there is a transition to address 12, go there. And there we have a comparison of the exception with the type: we check if the type of the exception is RuntimeError or not. If it is equal, we execute it, if not, we jump somewhere else.
FINALLY is the next block in the block stack. It will be executed for us if we have some other exception. Then the search will continue on this block stack, and we will come to the next SETUP_FINALLY block. There will be a handler that tells us, for example, address 40. We jump to address 40 - you can see from the code that this is a finally block.

It works very simply in CPython. We have all functions that can raise exceptions return a value code. If all is well, 0 is returned. If it is an error, -1 or NULL is returned, depending on the type of function.
Take such an inset at C. We see how the division occurs. And there is a check that if B is equal to zero and we don't want to divide by zero, then we remember the exception and return NULL. So an error has occurred. Therefore, all other functions that are higher on the call stack should also throw out NULL. We will see this in the main loop of the interpreter and jump here.

This is stack unwinding. Everything is like I said: we go through the entire block stack and check that its type is SETUP_FINALLY. If so, jump over Handler, very simple. This, in fact, is all.
Links
General interpreter:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
Memory management:
arctrix.com/nas/python/gc
rushter.com/blog/python -memory-managment
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
Exceptions:
bugs.python.org/issue17611