
Data storage costs often become the main cost item when creating a video surveillance system. However, they would be incomparably larger if there were no algorithms in the world capable of compressing a video signal. We will talk in today's article about how effective modern codecs are, and what principles underlie their work.
Let's start with numbers for clarity. Let the video be recorded continuously, in Full HD resolution (now this is the required minimum, at least if you want to fully use the video analytics functions) and in real time (that is, with a frame rate of 25 frames per second). Let's also assume that the hardware of our choice supports H.265 hardware encoding. In this case, with different image quality settings (high, medium and low), we will get approximately the following results.
Codec |
Intensity of motion in the frame |
Disk space usage per day, GB |
H.265 (High quality) |
High |
138 |
H.265 (High quality) |
Average |
67 |
H.265 (High quality) |
Low |
41 |
H.265 (Medium quality) |
High |
86 |
H.265 (Medium quality) |
Average |
42 |
H.265 (Medium quality) |
Low |
26 |
H.265 (Low quality) |
High |
81 |
H.265 (Low quality) |
Average |
39 |
H.265 (Low quality) |
Low |
24 |
But if video compression did not exist in principle, we would see completely different numbers. Let's try to figure out why. A video stream is nothing more than a sequence of static pictures (frames) at a certain resolution. Technically, each frame is a two-dimensional array containing information about the elementary units (pixels) that form the image. TrueColor requires 3 bytes to encode each pixel. Thus, in the given example, we would get a bit rate:
1920 × 1080 × 25 × 3/1048576 = ~ 148 Mb / s
Considering that there are 86400 seconds in a day, the numbers come out truly astronomical:
148 × 86400/1024 = 12487 GB
So, if we recorded video without compression in maximum quality under the given conditions, then we would need 12 terabytes of disk space to store the data received from one single video camera during the day. But even the security system of an apartment or a small office presupposes the presence of at least two video recording devices, while the archive itself must be kept for several weeks or even months, if required by law. That is, to service any object, even a very modest size, an entire data center would be required!
Fortunately, modern video compression algorithms can significantly save disk space: for example, using the H.265 codec allows you to reduce the video volume by 90 (!) Times. Such impressive results were achieved thanks to a whole stack of various technologies that have long been successfully used not only in the field of video surveillance, but also in the "civil" sector: in analog and digital television systems, in amateur and professional filming, and many other situations.
The simplest and most obvious example is color subsampling. This is the name of a video coding method in which the color resolution of frames is deliberately reduced and the sampling rate of color-difference signals becomes less than the sampling frequency of the luminance signal. This method of video data compression is fully justified both from the point of view of human physiology and from the point of view of practical application in the field of video recording. Our eyes are good at noticing the difference in brightness, but they are much less sensitive to color changes, which is why sampling of color-difference signals can be sacrificed, because most people simply will not notice it. At the same time, it is difficult to imagine how a car of the color of a "spider plotting a crime" is declared wanted: the orientation will say "dark gray", and this is correct, because otherwise the person who read the description of the car will not even understand.what shade are we talking about.
But with a decrease in detail, everything turns out to be completely different. Technically, quantization (that is, dividing the signal range into a number of levels and then bringing them to the specified values) works great: using this method, the video size can be reduced many times over. But this way we can miss important details (for example, the number of a car passing in the distance or the facial features of an intruder): they will be blurred and such a record will be useless for us. How to proceed in this situation? The answer is simple, like everything ingenious: as soon as you take dynamic objects as a starting point, everything immediately falls into place. This principle has been successfully used since the appearance of the H.264 codec and has proven itself well, opening up a number of additional possibilities for data compression.
It was predictable: figuring out how H.264 compresses video
Let's go back to the table we started with. As you can see, in addition to parameters such as resolution, frame rate and picture quality, the decisive factor determining the final size of the video is the level of dynamism of the scene being shot. This is due to the peculiarities of the work of modern video codecs in general, and H.264 in particular: the frame prediction mechanism used in it allows you to additionally compress video, while practically not sacrificing the picture quality. Let's see how it works.
The H.264 codec uses several types of frames:
- I-frames (from English Intra-coded frames, they are also called key or key) - contain information about static objects that do not change for a long time.
- P- (Predicted frames, , ) — , , I-.
- B- (Bi-predicted frames, ) — P-, I-, P- B-, , .
What does this mean? In the H.264 codec, the construction of a video image is as follows: the camera makes a reference frame (I-frame) and on its basis (which is why it is called a reference frame) subtracts the fixed parts of the image from the frame. This creates a P-frame. The third is then subtracted from this second frame and a modified P-frame is also created. This is how a series of differential frames is formed, which contain only changes between two successive frames. As a result, we get the following chain:
[START OF CAPTURE] IPPPPPPPPPPPPP- ...
Since in the process of subtraction errors are possible that lead to the appearance of graphic artifacts, then after a certain number of frames the scheme is repeated: a key frame is formed again, followed by a series frames with changes.
... -PPPPPPPIPPPPPPP ... The
complete image is formed by "superimposing" P-frames on the reference frame. At the same time, it becomes possible to independently process the background and moving objects, which allows you to additionally save disk space without the risk of missing important details (facial features, license plates, etc.). In the case of objects performing monotonous movements (for example, rotating wheels of cars), the same difference frames can be used repeatedly.
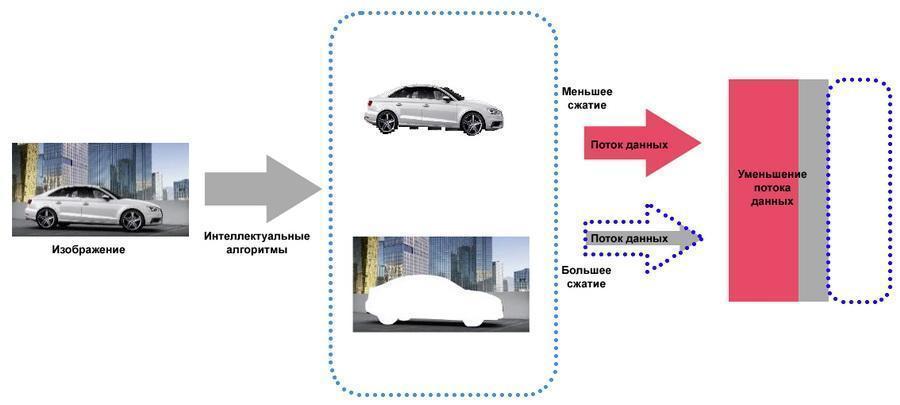
Independent processing of static and dynamic objects saves disk space.
This mechanism is called interframe compression. The predicted frames are formed based on the analysis of a wide sample of fixed scene states: the algorithm predicts where this or that object will move in the camera's field of view, which can significantly reduce the amount of recorded data when observing, for example, the roadway.
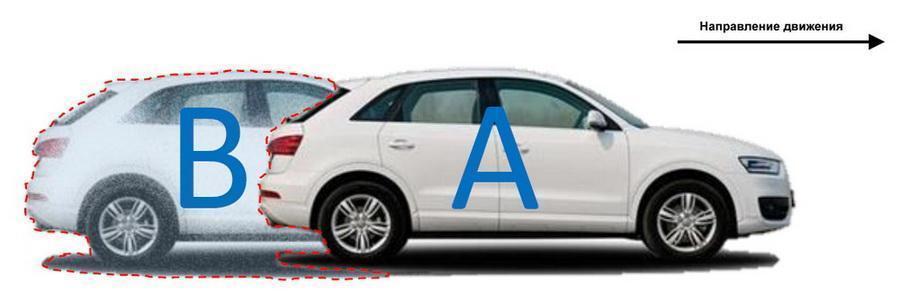
The codec generates frames, predicting where the object will move.In
turn, the use of bidirectional predicted frames allows several times to reduce the access time to each frame in the stream, since it will be enough to unpack only three frames to get it: B containing links, and I and the P he refers to. In this case, the sequence of frames can be depicted as follows.
[START CAPTURE] IBPBPBPBPBPBPBPBP-…
This approach can significantly increase the speed of fast forward and show and simplify the work with the video archive.
What is the difference between H.264 and H.265?

H.265 uses all the same compression principles as H.264: the background image is saved once, and then only changes originating from moving objects are recorded, which significantly reduces the requirements not only for storage, but also for bandwidth network capabilities. However, in H.265, many motion prediction algorithms and methods have undergone significant qualitative changes.
So, the updated version of the codec began to use macroblocks of a coding tree (Coding Tree Unit, CTU) of variable size with a resolution of up to 64 × 64 pixels, whereas previously the maximum size of such a block was only 16 × 16 pixels. This made it possible to significantly improve the accuracy of dynamic block extraction, as well as the efficiency of frame processing in 4K and higher resolutions.
In addition, H.265 has got an improved deblocking filter - a filter responsible for smoothing the edges of blocks, necessary to eliminate artifacts along the line of their joining. Finally, the improved Motion Vector Predictor (MVP) algorithm helped to significantly reduce the volume of video due to a radical increase in the accuracy of predictions when encoding moving objects, which was achieved by increasing the number of tracked directions: if previously only 8 vectors were taken into account, now - 36.
In addition to all of the above, H.265 has improved support for multithreading: the square areas into which each frame is divided during encoding can now be processed independently of one another. There is also support for Wavefront Parallelel Processing (WPP), which also improves compression performance. When WPP mode is activated, CTU processing is performed line by line, from left to right, however, the encoding of each subsequent line can begin even before the completion of the previous one, if the data received from the previously processed CTUs is sufficient for this. Shift time delay coding of various CTU strings,Along with support for the extended set of instructions AVX / AVX2, it can further increase the processing speed of video streams in multi-core and multi-processor systems.
Surveillance flash cards: when size is not the only thing
And again, let's return to the tablet with which we began today's conversation. Let's calculate how much disk space we need if we want to store a video archive for the last 30 days with maximum video quality:
138 × 30/1024 = 4
By today's standards, 4 terabytes for an industrial-grade hard drive is practically nothing: modern hard drives are for CCTVs have a capacity of up to 14 terabytes and boast a work resource of up to 360 TB per year with MTBF up to 1.5 million hours. As for memory cards, everything is not so simple here.
In IP cameras, flash cards play the role of backup storages: data on them are constantly overwritten so that in case of loss of connection with the video server, the missing video fragment can be restored from a local copy. This approach can significantly increase the fault tolerance of the entire security system, but at the same time the memory cards themselves are under enormous stress.
As you can see from our table, even with low image quality and with minimal activity in the frame, about 24 GB of video will be recorded in just a day. This means that a 128GB card will be completely overwritten in less than a week. If we need to get the highest quality picture, then all data on such a medium will be fully updated once a day! And this is only at Full HD resolution. What if we need a 4K picture? In this case, the load will almost double (under the given conditions, video in maximum quality will require 250 GB).
In everyday use, this is simply impossible, so even the most budget memory card can serve you for several years in a row without a single failure. And all thanks to wear leveling algorithms. Their work can be schematically described as follows. Let us have a brand new flash card, fresh from the store. We recorded several videos on it, using 7 out of 16 gigabytes. After a while, we removed some of the unnecessary videos, freeing 3 gigabytes, and recorded new ones, the volume of which was 2 GB. It would seem that you can use the space that has just been freed, but the wear leveling mechanism will allocate for new data that part of the memory that has never been used before. Although modern controllers "shuffle" bits and bytes in a much more sophisticated way, the general principle remains the same.
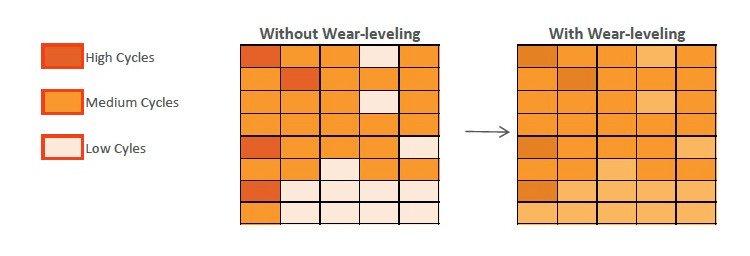
Recall that the coding of information bits occurs by changing the charge in the memory cells due to the quantum tunneling of electrons through the dielectric layer, which causes gradual wear of the dielectric layers with subsequent charge leakage. And the more often the charge changes in a particular cell, the earlier it will fail. Wear leveling is precisely aimed at ensuring that each of the available cells is overwritten approximately the same number of times and, thus, helps to increase the lifespan of the memory card.
It is easy to guess that wear leveling ceases to play any significant role if the flash card is constantly overwritten entirely: here the endurance of the chips themselves comes to the fore. The most objective criterion for evaluating the latter is the maximum number of program / erase cycles, or, in short, P / E cycles, that the flash memory can withstand. Also, the TBW (Terabytes Written) coefficient is quite accurate and in this case illustrative (since we can calculate the rewriting volumes in advance). If only one of the listed indicators is indicated in the technical characteristics, then it will not be difficult to calculate the other. It is sufficient to use the following formula:
TBW = (Capacity × Number of P / E cycles) / 1000
So, for example, TBW of a flash card with a capacity of 128 gigabytes, the resource of which is 200 P / E, will be equal to: (128 × 200) / 1000 = 25.6 TBW.
Let's count on. The endurance of consumer grade memory cards is 100-300 P / E, and 300 is at its best. Based on these figures, we can estimate their service life with a fairly high accuracy. Let's use the formula and fill in a new table for a 128GB memory card. Let's take the maximum picture quality in Full HD as a guideline, that is, the camera will record 138 GB of video per day, as we found out earlier.
Memory card resource, P / E cycles |
TBW |
MTBF |
100 |
12.8 |
3 months |
200 |
25.6 |
6 months |
300 |
38.4 |
1 year |
Want to use 64GB cards or write 4K videos? Feel free to divide the calculated time by two: on average, consumer memory cards will have to be replaced every six months, and in each camera. That is, every 6 months you will have to purchase a new batch of flash cards, incur additional maintenance costs and, of course, endanger the protected object, since the cameras will have to be taken out of service while they are being replaced.
Finally, one more point to which you should pay close attention when choosing a memory card is its speed characteristics. In the description of almost all modern flash cards, you can find an entry of the form: “Performance: up to 100 MB / s when reading, up to 90 MB / s when writing; video recording: C10, U1, V10 ". Here C10 and U1 mean nothing more than a video recording speed class, and if you look at the reference materials, then the C10, U1 and V10 classes correspond to 10 MB / s. Where does the difference 9 times come from and why is the marking triple? In fact, everything is quite simple.
In the example considered, 100 and 90 MB / s are the nominal speeds, that is, the maximum achievable performance of the card in sequential read and write operations, provided that it is used with compatible hardware, which itself has sufficient performance. C10, U1, and V1 (10 MB / s) are the minimum sustained data transfer rates under the worst test conditions. This parameter must be taken into account when choosing cards for CCTV cameras for the simple reason that if it turns out to be lower than the bitrate of the video stream, then this is fraught with the appearance of graphic artifacts on the recording and even the loss of entire frames. Obviously, in the case of security systems, this is unacceptable: any defects in the picture are fraught with the loss of critical data - for example, evidence that could help in catching an intruder.
As for the presence of three markings at once, the reasons for this are purely historical. C10 belongs to the very first classifications created by the SD Card Association, which was compiled back in 2006, having received the simple and uncomplicated name Speed Class. The emergence of the UHS Speed Class classification, which is indicated by the U1 marking, is associated with the creation of the Ultra High Speed interface, which is used today in the vast majority of flash cards. Finally, the last classification, Video Speed Class (V1), was developed by the SD Card Association in 2016 in connection with the proliferation of devices that support ultra-high definition video recording (4K, 8K and 3D).
Since the listed classifications partially overlap, we have prepared a comparative table for you, in which the speed characteristics of flash cards are compared with each other and correlated with videos of different resolutions.
Speed Class |
UHS Speed Class |
Video speed class |
Minimum sustained write speed |
Video resolution |
C2 |
- |
- |
2 MB / s |
Standard definition video recording (SD, 720 by 576 pixels) |
C4 |
- |
- |
4 MB / s |
High Definition (HD) video recording including Full HD (720p to 1080p / 1080i) |
C6 |
- |
V6 |
6 MB / s |
|
C10 |
U1 |
V10 |
10 MB / s |
Full HD (1080p) video recording at 60 frames per second |
- |
U3 |
V30 |
30 MB / s |
Video recording up to 4K resolution and 60/120 fps |
- |
- |
V60 |
60 MB / s |
Record video files with 8K resolution and frame rate 60/120 frames per second |
- |
- |
V90 |
90 MB / s |
It should be borne in mind that the correspondences given in the table are relevant for amateur, semi-professional and professional video cameras. In the video surveillance industry, where real-time recording is carried out at a maximum rate of 25 frames per second, and high-performance H.264 and H.265 codecs are used to compress the video stream, using predictive coding, in the vast majority of cases, memory cards corresponding to the U1 class will be sufficient / V10, since the bitrate in such conditions almost never exceeds the threshold of 10 MB / s.
WD Purple microSD Cards for Surveillance Systems

Taking into account all the above features, Western Digital has developed a specialized series of WD Purple microSD memory cards, which currently includes two product lines: WD Purple QD102 and WD Purple SC QD312 Extreme Endurance. The first included four drives ranging from 32 to 512 GB, the second - three models, for 64, 128 and 256 GB. Compared to consumer solutions, WD Purple has been specifically tailored for today's digital video surveillance systems with several important enhancements.
The main advantage of the purple series is a significantly greater working resource compared to household devices: cards of the QD102 line can withstand 1000 programming / erasing cycles, while QD312 already 3000 P / E cycles, which allows them to extend their service life many times even in round-the-clock recording mode. and makes these cards ideal for use in specially protected facilities, where recording is carried out 24/7. Conversely, compliance with UHS Speed Class 1 and Video Speed Class 10 allows WD Purple cards to be used in high definition cameras, including for real-time recording.
In addition, WD Purple memory cards have a number of other important features worth mentioning:
- ( 1 ) ( -25°C +85°C) WD Purple , ;
- 5000 500 g ;
- , , .
For clarity, we have prepared a comparison table for you, which shows the main characteristics of WD Purple memory cards.
Series |
WD Purple QD102 |
WD Purple QD312 |
||||||
Volume, GB |
32 |
64 |
128 |
256 |
512 |
64 |
128 |
256 |
Form- factor |
microSDHC |
microSDXC |
||||||
Performance |
Up to 100 MB / s in sequential read operations, up to 65 MB / s in sequential write operations |
|||||||
Speed class |
U1 / V10 |
|||||||
Record Resource (P / E) |
1000 |
3000 |
||||||
Write resource (TBW) |
32 |
64 |
128 |
256 |
512 |
192 |
384 |
768 |
Operating temperature range |
-25 ° C to 85 ° C |
|||||||
Warranty |
3 years |
|||||||