In my talk, I shared my experience of using Alembic, a well-proven tool for managing migrations. Why choose Alembic, how to use it to prepare migrations, how to run them (automatically or manually), how to solve the problems of irreversible changes, why test migrations, what problems can the tests reveal and how to implement them - I tried to answer all these questions. At the same time, I shared several life hacks that will make working with migrations in Alembic easy and enjoyable.
Since the day of the report, the code on GitHub has been slightly updated, there are more examples. If you want to see the code exactly as it appears on the slides, here is a link to a commit from that time.
- Hello! My name is Alexander, I work in Edadil. Today I want to tell you how we live with migrations and how you could live with them. Perhaps this will help you live easier.
What are migrations?
Before we get started, it's worth talking about what migrations are in general. For example, you have an application and you create a couple of tablets so that it works, goes to them. Then you roll out a new version, in which something has changed - the first plate has changed, the second is not, and the third was not there before, but it appeared.

Then a new version of the application appears, in which some plate is deleted, nothing happens to the rest. What it is? We can say that this is the state that can be described by migration. When we move from one state to another, this is an upgrade, when we want to go back - downgrade.
What are migrations?

On the one hand, this is code that changes the state of the database. On the other hand, this is the process that we start.

What properties should migrations have? It is important that the states that we switch between in versions of the application are atomic. If, for example, we want us to have two tables, but only one appears, this can lead to not very good consequences in production.
It is important that we can rollback our changes, because if you roll out a new version, it does not take off and you cannot rollback, everything usually ends badly.
It's also important that the versions are ordered so that you can chain the way they rolled.
Tools
How can we implement these migrations?
The first idea that comes to mind: okay, migration is SQL, why not take and make SQL files with queries. There are several more modules that can make our life easier.

If we look at what's going on inside, then there are indeed a couple of requests. It could be CREATE TABLE, ALTER, anything else. In the downgrade_v1.sql file, we cancel it all.

Why shouldn't you do this? Primarily because you need to do it with your hands. Do not forget to write begin, then commit your changes. When you write code, you will need to remember all the dependencies and what to do in what order. This is a fairly routine, difficult and time-consuming job.
You have no protection against accidentally launching the wrong file. You need to run all the files by hand. If you have 15 migrations it is not easy. You will need to call some psql 15 times, it will not be very cool.
Most importantly, you never know what state your database is in. You need to write down somewhere - on a piece of paper, somewhere else - which files you downloaded and which did not. It doesn't sound very good either.

There is a yoyo-migrations module . It supports the most common databases and uses raw queries.

If we look at what he offers us, it looks like this. We see the same SQL. There is already Python code on the right that imports the yoyo library.

Thus, we can already start migrations, exactly automatically. In other words, there is a command that creates and adds a new migration to the chain where we can write our SQL code. Using commands, you can apply one or more migrations, you can roll back, this is already a step forward.

The plus is that you no longer need to write on a piece of paper what requests you have performed on the database, what files you have launched and where you need to rollback if something happens. You have some kind of foolproof protection: you will no longer be able to start a migration that is designed for something else, for the transition between two other states of the database. A very big plus: this thing does each migration in a separate transaction. This also gives such guarantees.

The disadvantages are obvious. You still have raw SQL. If, for example, you have a large data production with sprawling logic in Python, you cannot use it, because you only have SQL.
Also, you will find a lot of routine work that cannot be automated. It is necessary to keep track of all the relationships between the tables - what can be written somewhere, and what is not yet possible. In general, there are quite obvious disadvantages.
Another module that is worth paying attention to and for which the entire talk today is Alembic .

It has the same things as yoyo, and a lot more. It not only monitors your migrations and knows how to create them, but also allows you to write very complex business logic, connect your entire data production, any functions in Python. Pull the data and process it internally if you want. If you don't want to, you don't have to.
He knows how to write code for you automatically in most cases. Not always, of course, but it sounds like a good plus after you've had to write a lot with your hands.
He has a lot of cool stuff. For example, SQLite does not fully support ALTER TABLE. And Alembic has functionality that allows you to easily bypass this in a couple of lines, and you won't even think about it.
In the previous slides, there was a Django-migrations module. This is also a very good module for migrations. Its principle is comparable to Alembic in functionality. The only difference is that it is framework-specific, and Alembic is not.
SQLAlchemy
Since Alembic is based on SQLAlchemy, I suggest running a little through SQLAlchemy to remember or find out what it is.

So far, we've looked at raw queries. Raw queries are not bad. This can be very good. When you have a highly loaded application, maybe this is exactly what you need. There is no need to waste time converting some objects into some queries.
No additional libraries are required. You just take the driver and that's it, it works. But for example, if you write complex queries, it will not be so easy: well, you can take a constant, bring it up, write a large multi-line code. But if you have 10-20 such requests, it will already be very difficult to read. Then you cannot reuse them in any way. You have a lot of text and, of course, functions for working with strings, f-strings and all that, but this already does not sound very good. They are hard to read.
If, for example, you have a class within which you also want to have queries and complex structures, indentation is a wild pain. If you want to do a raw migration, then the only way to find where you are using something is with grep. And you don't have a dynamic tool for dynamic queries either.
For example, a super easy task. You have an entity, it has 15 fields in one plate. You want to make a PATCH request. It would seem to be super simple. Try to write this on raw queries. It will not look very pretty, and the pull request is unlikely to be approved.

There is an alternative to this - Query builder. It certainly has drawbacks because it allows you to represent your queries as objects in Python.
You will have to pay for the convenience both by the time for generating requests and by the memory. But there are pluses. When you write large, complex applications, you need abstractions. Query builder can give you these abstractions. These queries can be decomposed; we'll see how this is done a little later. They can be reused, extended, or wrapped in functions that will already be called friendly names associated with business logic.
It is very easy to build dynamic queries. If you need to change something, write a migration, statistical analysis of the code is enough. It is very convenient.
Why is SQLAlchemy anyway? Why is it worth stopping at?

This is a question not only about migration, but in general. Because when we have Alembic, it makes sense to use the entire stack at once, because SQLAlchemy works not only with synchronous drivers. That is, Django is a very cool tool, but Alchemy can be used, for example, with asyncpg and aiopg . Asyncpg allows you to read, as Selivanov said, a million lines per second - read from the database and transfer to Python. Of course, with SQLAlchemy there will be a little less, there will be some overhead. But anyway.
SQLAlchemy has an incredible number of drivers that it knows how to work with. There are Oracle and PostgreSQL, and just everything for every taste and color. Moreover, they are already out of the box, and if you need something separate, then there, I recently looked, there is even Elasticsearch. True, only for reading, but - do you understand? - Elasticsearch in SQLAlchemy.
There is very good documentation, a large community. There are a lot of libraries. And importantly, it doesn't dictate frameworks and libraries to you. When you're doing a narrow task that needs to be done well, it can be a tool.
So what does it consist of?
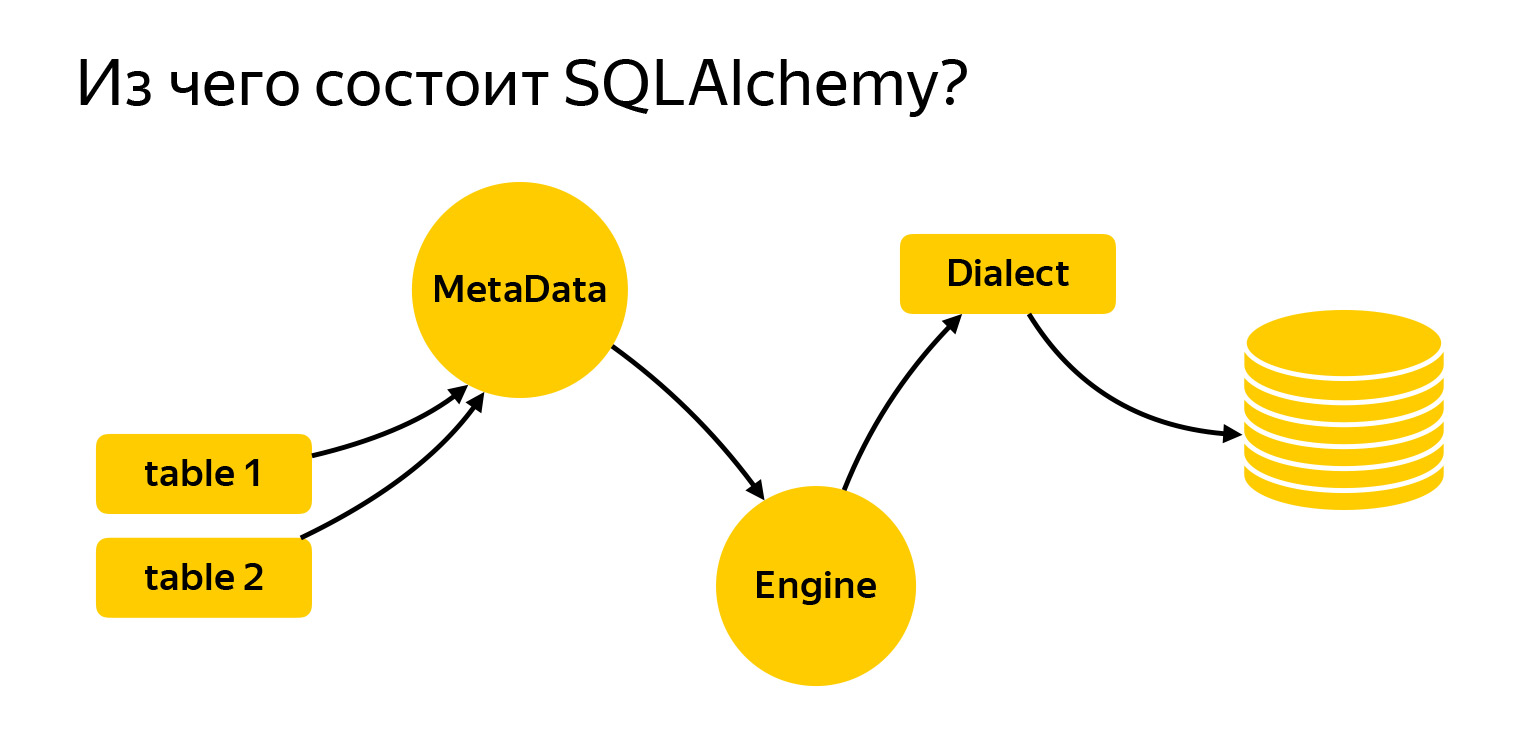
I brought here the main entities with which we will work today. These are tables. To write requests, Alchemy needs to be told what it is and what we are working with. Next is the MetaData registry. Engine is a thing that connects to the database and communicates with it through Dialect.
Let's take a closer look at what it is.

MetaData is a kind of object, a container, into which you will add your tables, indexes and, in general, all the entities that you have. This is an object that reflects, on the one hand, how you want to see the database, based on your written code. On the other hand, MetaData can go to the database, get a snapshot of what is actually there, and build this object model itself.
Also, the MetaData object has one very interesting feature. It allows you to define a default naming template for indexes and constraints. This is very important when you write migrations, because every database - be it PostgreSQL, MySQL, MariaDB - has its own vision of how indexes should be called.
Some developers also have their own vision. And SQLAlchemy allows you to set a standard once and for all how it works. I had to develop a project that needed to work with both SQLite and PostgreSQL. It was very convenient.

It looks like this: you import a MetaData object from SQLAlchemy and when you create it, specify templates using the naming_convention parameter, the keys of which specify the types of indexes and constraints: ix - regular index, uq - unique index, fk - foreign key, pk - primary-key.
In the values of the naming_convention parameter, you can specify a pattern that consists of the index type / constraint (ix / uq / fk, etc.) and the table name, separated by underscores. In some templates, you can also list all the columns. For example, it is not necessary to do this for the primary key, you can simply specify the table name.
When you start making a new project, you add naming templates to it once and forget. Since then, all migrations have been generated with the same index and constraint names.
This is important for another reason: when you decide that this index is no longer needed in your object model and you delete it, Alembic will know what it is called and will correctly generate the migration. This is already a certain guarantee of reliability, that everything will work as it should.
Another very important entity that you are bound to come across is a table, an object that describes what the table contains.

The table has a name, columns with data types, and it necessarily refers to the MetaData registry, since MetaData is a registry of everything that you describe. And there are columns with data types.
Thanks to what we have described, SQLAlchemy now can and knows a lot. If we had specified a foreign key here, she would still know how our tables are connected to each other. And she would know the order in which something needs to be done.

SQLAlchemy also has Engine. Important: what we said about queries can be used separately, and Engine can be used separately. And you can use everything together, no one forbids. That is, Engine knows how to connect directly to the server, and gives you exactly the same interface. No, of course, different drivers try to comply with DBAPI, there is a PEP in Python that makes recommendations. But Engine gives you exactly the same interface for all databases, and it's very convenient.

The last major milestone is Dialect. This is how the Engine communicates with different databases. There are different languages, different people, and different Dialect here.
Let's see what all this is for.

This is what a normal Insert will look like. If we want to add a new line, the plate that we described earlier, in which there was an ID and email field, here we specify the email, do Insert, and immediately get back everything that we have inserted.
What if we want to add many lines? No problem.

You can simply transfer a list of dictations here. Looks like perfect code for some super simple pen. The data came in, passed some kind of validation, some JSON schema, and everything got into the database. Super easy.
Some queries are quite complex. Sometimes a request can even be viewed with a print, sometimes you have to compile it. This is not difficult. Alchemy allows you to do all this. In this case, we have compiled the request, and you can see what will actually fly into the database.

The data request looks quite simple. Literally two lines, you can even write in one.

Let's go back to our question on how, for example, to write a PATCH request for 15 fields. Here you should write only the name of the field, its key and value. This is all that is needed. No files, no string building, nothing at all. Sounds convenient.
Perhaps the most important Alchemy feature that I use every day in my work is query decomposition and expansion.

Suppose you are writing an interface in PostgreSQL, your application must somehow authorize a person and enable him to perform CRUD. Okay, there isn't much to decompose.
When you write a very complex application that uses data versioning, a bunch of different abstractions, the queries that you will generate can consist of a huge number of subqueries. Subqueries are joined with subqueries. There are different tasks. And sometimes query decomposition helps a lot, it allows great separation of logic and code design.
Why does it work like this? When you call the users_table.select () method, for example, it returns an object. When you call any other method on the resulting object, such as where (), it returns a completely new object. All query objects are immutable. Therefore, you can build on top anything you like.
Migrations from alembic
So, we have dealt with SQLAlchemy and now we can finally write Alembic migrations.

Getting started using Alembic is not at all difficult, especially if you have already described your tables, as we said earlier, and specified a MetaData object. You just pip install alembic, call alembic init alembic. alembic - the name of the module, this is command-line, you will have it. init is a command. The last argument is the folder to put it in.
When you call this command, you will have several files, which we will take a closer look at now.

There will be general configuration in alembic.ini. script_location is exactly where you would like it to go. Next, there will be a template for the names of your migrations that you will generate, and information for connecting to the database.

There is also a template for new migrations. You say, "I want a new migration," and Alembic will create it according to a certain template. You can customize all of this, it's very simple. You go into this file and edit whatever you need. All the variables that can be specified here are in the documentation. This is the first part. There is some kind of commentary at the top so that it is convenient to see what is happening there. Then there is a set of variables that should be in every migration - revision, down_revision. We will work with them today. Further - additional meta-information.

The most important methods are upgrade and downgrade. Alembic will substitute here whatever difference the MetaData object finds between your schema description and what is in the database.

env.py is the most interesting file in Alembic. It controls the progress of commands and allows you to customize it for yourself. It is in this file that you connect your MetaData object. As I said before, the MetaData object is the registry for all the entities in your database.
You are connecting this MetaData object here. And from that time on, Alembic understands that here they are, my models, here they are, my plates. He understands what he is working with. Next, Alembic has a code that calls Alembic either offline or online. We will now also consider all this.
This is exactly the line where you need to connect MetaData in your project. Don't worry if something is not very clear, I collected everything into a project and posted it on GitHub . You can clone it and see, feel it all.

What is online mode? In online mode, Alembic connects to the database specified in the sqlalchemy.url parameter in the alembic.ini file and starts running migrations.
Why are we looking at this piece of code at all? Alembic can be customized very flexibly.
Imagine you have an application that needs to live in different database schemas. For example, you want to have a lot of application instances running at once, and each one lives in its own scheme. It can be convenient and necessary.
It doesn't cost you anything at all. After calling the context.begin_transaction () method, you can write the command "SET search_path = SCHEMA", which will tell PostgreSQL to use a different default schema. And that's all. From now on, your application lives in a completely different scheme, migrations roll into a different scheme. This is a one line question.

There is also an offline mode. Note that Alembic does not use Engine here. You can simply pass a link to him here. You can, of course, transfer the Engine too, but it does not connect anywhere. It just generates raw queries that you can then execute somewhere.

So, you have Alembic and some MetaData with tables. And you finally want to generate migrations for yourself. You execute this command, and that's basically it. Alembic will go to the database and see what is there. Is there his special label “alembic_versions”, which will tell you that migrations have already been rolled out in this database? Will see what tables exist there. Will see what data you need in the database. It will analyze all this, generate a new file, just based on this template, and you will have a migration. Of course, you should definitely look at what was generated in the migration, because Alembic does not always generate what you want. But most of the time it works.

What have we generated? There was a users sign. When we generated the migration, I indicated the Initial message. The migration will be named initial.py with some other template that was previously specified in alembic.ini.
Also here is information about what ID this migration has. down_revision = None - this is the first migration.
The next slide will be the most important part: upgrade and downgrade.

In the upgrade we see that we have a plate being created. In downgrade, this sign is removed. Alembic, by default, specifically adds such comments so that you go there, edit it, at least delete these comments. And just in case, we reviewed the migration, made sure that everything suits you. This is a matter of one team. You already have a migration.

After that, you most likely want to apply this migration. It couldn't be easier. You just need to say: alembic upgrade head. He will apply absolutely everything.
If we say head, it will try to update to the most recent migration. If we name a specific migration, it will update to it.
There is also a downgrade command - in case you change your mind, for example. All this is done in transactions and it works quite simply.

So, you have migrations, you know how to run them. You have an application, and you ask, for example, this question: I have CI, tests are running, and I don't even know if I want, for example, to run migrations automatically? Maybe it's better to do it with your hands?
There are different points of view here. Probably, it is worth adhering to the rule: if you do not have easy access, the ability to get on a car with a database, then it is better, of course, to do it automatically.
If you have access, you make a service that works in the cloud, and you can go there from a laptop that you always have with you, then you can do it yourself and thereby give yourself more control.
In general, there are many tools to do this automatically. For example, in the same Kubernetes. There are init containers that can do this and in which you can run these commands. You can add a launch command directly to Docker to do this.
You just need to consider: if you apply migrations automatically, then you need to think about what happens if, for example, you want to rollback, but you cannot. For example, you had a 500 gigabyte data plate. You thought: okay, this data is no longer needed for business logic, you can probably drop it. They took it and dropped it. Or changed the type of a column, which changed with data loss. For example, there was a long line, but it became short. Or something is gone. Or you have deleted a column. You cannot rollback even if you want to.
At one time I made products for on-premises, which are put by an exe file to people directly on the machine. Once you understand: yes, you wrote the migration, it went into production, people have already installed it. In the next five years, it may work for them according to the SLA, and you want to change something, something could be better. At this moment, you think about how to deal with irreversible changes.

No rocket science here either. The idea is that you can avoid using these columns or using tables as much as possible. Stop contacting them. You can, for example, mark fields with a special decorator in the ORM. He will say in the logs that you seemed to want not to touch this field, but you are still referring to him. Just create a task in the backlog and delete it someday.
You, if anything, will have time to roll back. And if everything goes well, you will calmly do this task later in the backlog. Make another migration that will actually delete everything.
Now for the most important question: why and how to test migrations?

This is done by a few of those whom I asked. But it's better to do it. This is a rule written in pain, blood and sweat. Using migration in production is always risky. You never know how it might end. Even a very good migration on a perfectly normal working production, when you have CI configured, can jerk.
The point is that when you are testing migrations, you can even download, for example, stage or some part of production. The production can be large, you cannot download it completely for tests or other tasks. Development bases are, as a rule, not really production bases. They do not have much of what could have accumulated over the years.

This can be corrupted data, when we migrated something, or old software that brought the data into an inconsistent state. It can also be implied dependencies - if someone forgot to add a foreign key. He thinks it is connected, but his colleagues, for example, do not know about it. The fields are also called quite by accident, it is not at all clear that they are connected.
Then someone decided to go in and add some kind of index directly to production, because "it slows down now, but what if it starts working faster?" Maybe I'm exaggerating, but people really sometimes change something right in the databases.
There are, of course, mistakes in tools, in schema migration. To be honest, I have not come across this. Usually there were the first three problems. And perhaps more errors in assumptions about how data should be transferred.
When you have a very large object model, it's difficult to keep everything in mind. It is difficult to constantly write up-to-date documentation. The most up-to-date documentation is your code, and it doesn’t always have fully written business logic: what and how should work, who had what in mind.

What can we check? At least the fact that the migration starts. This is already great. And that there are no stupid typos in the code. We can check that there is a valid downgrade () method, that the downgrade () method deletes all data types created by SQLAlchemy.
SQLAlchemy does a lot of nice things. For example, when you describe a table and specify an Enum column type, SQLAlchemy will automatically create the data type for that enum in PostgreSQL. But the code to remove this data type in the downgrade () method will not be automatically generated.
You need to remember and check this: when you want to rollback and reapply the migration, an attempt to create an existing data type in the upgrade () method will throw an exception. And most importantly, if the migration changes any data, you need to check that the data changes correctly in the upgrade. And it's very important to check that they roll back correctly in downgrade without side effects.

Before moving on to the tests themselves, let's see how best to prepare for writing them. I've seen many approaches to this. Some people create a base, plates, then write a fixture that cleans it all up, use some auto-apply fixtures . But the ideal way that will protect you 100% and will run tests in a completely isolated space is to create a separate database.
There is an awesome sqlalchemy_utils module that can create and delete databases. In PostgreSQL, he also checks: if one of the clients fell asleep and did not disconnect, he will not crash with the error that “someone is using the database, I can’t do anything with it, I can’t delete it”. Instead, he will calmly see who has connected to them, disconnect these clients and calmly delete the base.
Building a database and applying a migration to each test is not always a quick process. This can be solved as follows: PostgreSQL supports creating new databases from a template, so you can split the preparation of the database into two fixtures.
The first fixture runs once to run all tests (scope = session), creates a database and applies migrations to it. The second fixture (scope = function) creates bases directly for each test based on the base from the first fixture.
Creating a database from a template is very fast and saves time on applying migrations for each test.

If we're just talking about how we can temporarily create a database, then we can write such a fixture. What's going on here? We will generate a random name. We add, just in case, to the end of pytest, so that when we go to localhost to ourselves through some Postico, we can understand what was created by tests and what was not.
Then we generate from the link with information about connecting to the database, which the person showed, a new one, already with a new database. We create it and just send it to tests. After a person has worked with this database, we delete it.

We can also prepare the Engine to connect to this database. That is, in this fixture we refer to the previous fixture used as a dependency. We create an Engine and send it to tests.

So what tests can we write? The first test is just a brilliant invention of my colleague. Since it appeared, I think I have forgotten about the problems with migrations.
This is a very simple test. You add it to your project once. It is in the project on GitHub... You can just drag it off to you, add and forget, perhaps, about 80 percent of problems.
It does a very simple thing: it gets a list of all migrations and starts iterating over them. Calls upgrade, downgrade, upgrade.

For example, we have five migrations. Let's see how this will work. Here is the first migration. We have fulfilled it. Rollback the first migration, run it again. What happened here? In fact, we saw here that a person correctly implemented the downgrade () method, because two times, for example, it would not have been possible to create tables.
We see that if a person created some data types, he also deleted them, because there are no typos and in general it at least somehow works.
Then the test moves on. He takes the second migration, immediately runs up to it, rolls back one step, runs forward again. And this happens as many times as you have migrations.
The purpose of this test is to find basic errors, problems when changing the data structure.
Stairway starts on an empty base and is usually very fast. That is, this test is more about the data structure. This is not about changing data in migrations. But overall, it can save your life very well.
If you want a quick fix, this is it. This rule is. As a rule of thumb: insert it into your project, and it becomes easier for you.

This test looks something like this. We get all the revisions, generate the Alembic config. Here is what we saw before, the alembic.ini file, here is the get_alembic_config function, it reads this file, adds our temporary base to it, because there we specified the path to the base. And after that we can use Alembic commands.
The previously executed command - alembic upgrade head - can also be safely imported. Unfortunately, this slide does not fit all the imports, but take my word for it. It's just from alembic.com import upgrade. You translate config there, tell where to go through upgrade. Then say: downgrade.
Downgrade rolls back the migration to down_revision, that is, to the previous revision, or to "-1"
"-1" is an alternative way to tell Alembic to rollback the current migration. It is very relevant when the first migration starts, its down_revision is None, while the Alembic API does not allow passing None to the downgrade command.
Then the upgrade command is run again.
Now let's talk about how to test migrations with data.

Data migrations are the kind of thing that usually seems very simple, but it hurts the most. It would seem that you could write some select, insert, take data from one table, transfer it to another in a slightly different format - what could be simpler?
It remains to be said about this test that, unlike the previous one, it is very expensive to develop. When I did large migrations, it sometimes took me six hours to look at all the invariants, it's ok to describe everything. But when I was already rolling these migrations, I was calm.

How does this test work? The idea is that we apply all migrations up to the one we now want to test. We insert into the database a set of data that will change. We can think about inserting additional data that might change implicitly. Then we upgrade. We check that the data was changed correctly, execute downgrade, and check that the data was changed correctly.

The code looks something like this. That is, there is also a parameterization by revision, there is a set of parameters. We accept our Engine here, accept the migration with which we want to start testing.
Then rev_head, which is what we want to test. And then three callbacks. These are the callbacks that we define somewhere, and they will be called after something is done. We can check what's going on there.
Where can I see an example?
I packed it all into an example on GitHub . There really isn't a lot of code in there, but it's hard to add to the slide. I tried to endure the most basic. You can go to GitHub and see how it works in the project itself, this will be the easiest way.
What else is worth paying attention to? During startup Alembic looks for the alembic.ini configuration file in the folder where it was launched. Of course, you can specify the path using the environment variable ALEMBIC_CONFIG, but this is not always convenient and obvious.
Another problem: information for connecting to the database is specified in alembic.ini, but often you need to be able to work with several databases in turn. For example, roll out migrations to stage and then to prod. In general, you can specify connection information in the SQLALCHEMY_URL environment variable, but this is not very obvious to end users of your software.
It will also be much more intuitive for end users to use the "$ project $ -db" utility than "alembic".
As you look at the examples in the project, take a look at the staff-db utility. It's a thin wrapper around Alembic, and yet another way to customize Alembic for you. By default, it looks for the alembic.ini file in the project relative to its location. From whatever folder users call her, she herself will find the configuration file. Also, staff-db adds an argument --db-url, with which you can specify information to connect to the database. And, importantly, see it by passing the generally accepted --help option. After all, the name of the utility is intuitive.
All executable project commands begin with the name of the "staff" module: staff-api, which runs the REST API, and staff-db, which manages the base state. Understanding this pattern, the client will write the name of your program and will be able to see all available utilities by pressing the TAB key, even if he forgets the full name. I have everything, thanks.