You can do it manually, but there are also frameworks and libraries for this that make this process faster and easier. We will talk
about one of them, featuretools , as well as the practical experience of using it.

The most fashionable pipeline
Hello! I am Alexander Loskutov, I work at Leroy Merlin as a data analyst, or, as it is fashionable to call it now, a data scientist. My responsibilities include working with data, starting with analytical queries and unloading, ending with training the model, wrapping it, for example, in a service, setting up delivery and deployment of the code, and monitoring its work.
Undo prediction is one of the products I am working on.
Product Objective: Predict the likelihood of a customer canceling an online order. With the help of such a prediction, we can determine which of the customers who made an order should be called first to ask to confirm the order, and who may not be called at all. Firstly, the very fact of a call and confirmation of an order from a client by phone reduces the likelihood of cancellation, and secondly, if we call and the person refuses, then we can save resources. Employees will free up more time that they would have spent collecting the order. In addition, this way the product will remain on the shelf, and if at that moment the customer in the store needs it, he will be able to buy it. And this will reduce the number of goods that were collected in orders canceled later and were not present on the shelves.
Forerunners
For the product pilot, we only take postpaid orders for pickup at multiple stores.
A ready-made solution works like this: an order comes to us, with the help of Apache NiFi we enrich information on it - for example, pulling up data on goods. Then all this is transferred through the Apache Kafka message broker to the service written in Python. The service calculates the features for the order, and then a machine learning model is taken for them, which gives the probability of cancellation. After that, in accordance with the business logic, we prepare an answer whether we need to call the client now or not (for example, if the order was made with the help of an employee inside the store or the order was made at night, then you should not call).
It would seem, what prevents from calling everyone in a row? The fact is that we have a limited number of resources for calls, so it is important to understand who should definitely call, and who will definitely pick up their order without calling.
Model development
I was engaged in the service, the model and, accordingly, the calculation of features for the model, which will be discussed further.
When calculating features during training, we use three data sources.
- Plate with order meta information: order number, timestamp, customer device, delivery method, payment method.
- Plate with positions in receipts: order number, article, price, quantity, quantity of goods in stock. Each position goes on a separate line.
- Table - a reference book of goods: article, several fields with a category of goods, units of measure, description.
Using standard Python methods and the pandas library, you can easily combine all tables into one large one, after which, using groupby, you can calculate all sorts of features such as aggregates by order, history by product, by product category, etc. But here several problems arise.
- Parallelism of calculations. The standard groupby works in one thread, and on big data (up to 10 million rows), a hundred features is considered unacceptably long, while the capacity of the remaining cores is idle.
- The amount of code: each such request needs to be written separately, checked for correctness, and then all the results still need to be collected. This takes time, especially given the complexity of some of the calculations — for example, calculating the latest history for an item in a receipt and aggregating these characteristics for an order.
- You can make mistakes if you code everything by hand.
The advantage of the "we write everything by hand" approach is, of course, complete freedom of action, you can give your imagination to unfold.
The question arises: how can this part of the work be optimized. One solution is to use the featuretools library .
Here we are already moving on to the essence of this article, namely, the library itself and the practice of its use.
Why featuretools?
Let's consider various frameworks for machine learning in the form of a plate (the picture itself is honestly stolen from here , and probably not all are indicated there, but still):
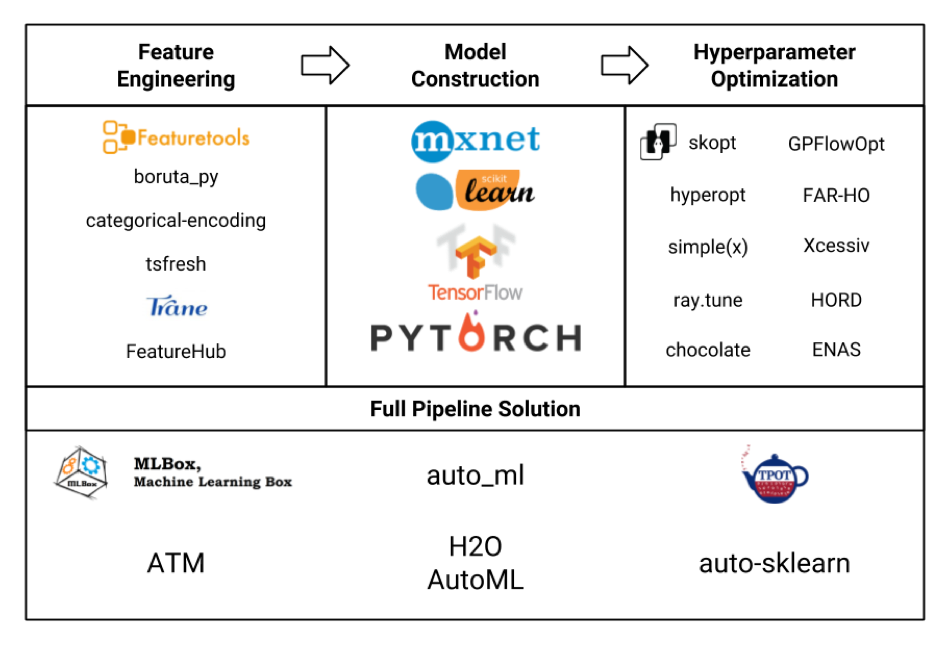
We are primarily interested in the Feature Engineering block. If we look at all these frameworks and packages, it turns out that featuretools is the most sophisticated of them, and it even includes the functionality of some other libraries like tsfresh .
Also, the advantages of featuretools (not advertising at all!) Include:
- parallel computing out of the box
- availability of many features out of the box
- flexibility in customization - quite complex things can be considered
- accounting for relationships between different tables (relational)
- less code
- less likely to make a mistake
- by itself, everything is free, without registration and SMS (but with pypi)
But it's not that simple.
- The framework requires some learning, and full mastering will take a decent amount of time.
- It doesn't have such a large community, although the most popular questions still google well.
- The use itself also requires care so as not to inflate the feature space unnecessarily and not to increase the calculation time.
Training
I will give an example of the configuration of featuretools.
Next, there will be a code with brief explanations, in more detail about featuretools, its classes, methods, capabilities, you can read, among other things, in the documentation on the framework's website. If you are interested in examples of practical application with a demonstration of some interesting possibilities in real tasks, then write in the comments, perhaps I will write down a separate article.
So.
First, you need to create an object of the EntitySet class, which contains tables with data and knows about their relationship with each other.
Let me remind you that we have three tables with data:
- orders_meta (order meta information)
- orders_items_lists (information about items in orders)
- items (reference of articles and their properties)
We write (further, the data of only 3 stores are used):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

Hooray! Now we have an object that will allow us to count all sorts of signs.
I will give a code for calculating fairly simple features: for each order, we will calculate various statistics on prices and quantity of goods, as well as a couple of features by time and the most frequent products and categories of goods in the order (functions that perform various transformations with data are called primitives in featuretools) ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)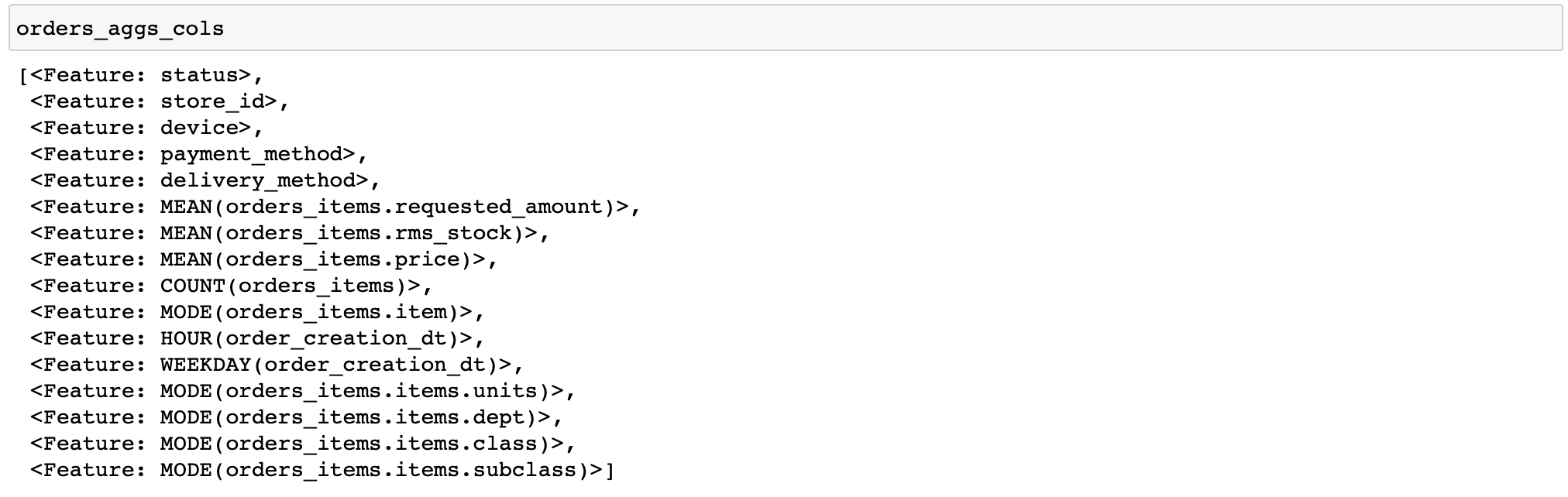

There are no boolean columns in the tables, so the any primitive was not applied. In general, it is convenient that featuretools itself analyzes the data type and applies only the appropriate functions.
Also, I manually specified only a few orders for calculation. This allows you to quickly debug your calculations (what if you configured something wrong).
Now let's add a few more aggregates to our features, namely percentiles. But featuretools do not have built-in primitives to calculate them. So you need to write it yourself.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
And add them to the calculation:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)Then everything is the same. So far, everything is pretty simple and easy (relatively, of course).
What if we want to save our feature calculator and use it at the stage of model execution, that is, in the service?
Featuretools in combat
This is where the main difficulties begin.
To calculate the characteristics for an incoming order, you will have to do all the operations with the creation of the EntitySet again. And if for large tables it seems quite normal to throw pandas.DataFrame objects into the EntitySet, then doing similar operations for DataFrames from one row (there are more of them in the table with checks, but on average 3.3 positions per check, that is, not enough) - not very much. After all, the creation of such objects and calculations with their help inevitably contain an overhead, that is, an unremovable number of operations necessary, for example, for memory allocation and initialization when creating an object of any size or the parallelization process itself when calculating several features simultaneously.
Therefore, in the mode of operation "one order at a time" in our product featuretools shows not the best efficiency, taking on average 75% of the service response time (on average 150-200 ms depending on the hardware). For comparison: calculating a prediction using catboost on ready-made features takes 3% of the service response time, that is, no more than 10 ms.
In addition, there is another pitfall associated with the use of custom primitives. The fact is that we cannot simply save in pickle an object of the class containing the primitives we have created, since the latter are not pickled.
Then why not use the built-in save_features () function, which can save a list of FeatureBase objects, including the primitives we created?
It will save them, but it will not be possible to read them later using the load_features () function if we do not create them again in advance. That is, the primitives that we, in theory, should read from disk, we first create again so that we will never use them again.
It looks like this:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorIn the load () function, you have to create primitives (declaring the custom_primitives variable) that will not be used. But without this, further feature loading at the place of the load_features () function call will fail with the RuntimeError: Primitive "percentile05" in module "featuretools.primitives.base.aggregation_primitive_base" not found .
It turns out not very logical, but it works, and you can save both the calculator already tied to a certain data format (since the features are tied to the EntitySet for which they were calculated, albeit without the values themselves), and the calculator only with a given list of primitives.
Perhaps in the future this will be corrected and it will be possible to conveniently save an arbitrary set of FeatureBase objects.
Why then do we use it?
Because from the point of view of development time, it is cheap, while the response time under the existing load fits into our SLA (5 seconds) with a margin.
However, you should be aware that for a service that must quickly respond to frequently received requests, using featuretools without additional "squats" like asynchronous calls will be problematic.
This is our experience of using featuretools at the learning and inference stages.
This framework is very good as a tool for quickly calculating a large number of features for training, it greatly reduces development time and reduces the likelihood of errors.
Whether to use it at the stage of withdrawal depends on your tasks.