
Why do oilmen need NLP? How do you get a computer to understand professional jargon? Is it possible to explain to the machine what is "pressure", "throttle response", "annular"? How are new hires and the voice assistant connected? We will try to answer these questions in the article on the introduction of a digital assistant into the software for oil production support, which facilitates the routine work of a geologist-developer.
We at the institute are developing our own software ( https://rn.digital/ ) for the oil industry, and in order for its users to fall in love, you need not only to implement useful functions in it, but also to think about the convenience of the interface all the time. One of the trends in UI / UX today is the transition to voice interfaces. After all, whatever one may say, the most natural and convenient form of interaction for a person is speech. So the decision was made to develop and implement a voice assistant in our software products.
In addition to improving the UI / UX component, the introduction of the assistant also allows you to reduce the "threshold" for new employees to work with software. The functionality of our programs is extensive, and it may take more than one day to figure it out. The ability to "ask" the assistant to execute the desired command will reduce the time spent on solving the task, as well as reduce the stress of a new job.
Since the corporate security service is very sensitive to the transfer of data to external services, we thought about developing an assistant based on open source solutions that allow us to process information locally.
Structurally, our assistant consists of the following modules:
- Speech Recognition (ASR)
- Allocation of semantic objects (Natural Language Understanding, NLU)
- Command execution
- Synthesis of speech (Text-to-Speech, TTS)
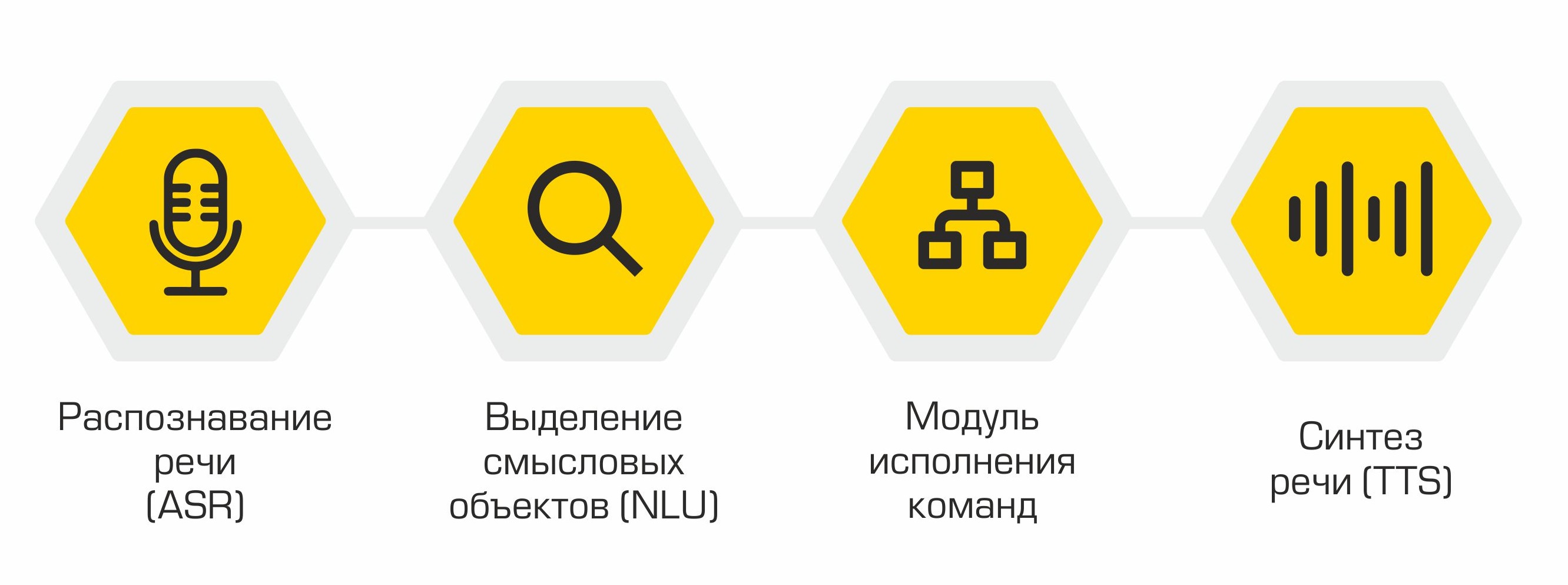
The principle of the assistant: from words (user) to actions (in software)!
The output of each module serves as the entry point for the next component in the system. So, the user's speech is converted into text and sent for processing to machine learning algorithms to determine the user's intent. Depending on this intention, the required class is activated in the command execution module, which fulfills the user's request. Upon completion of the operation, the command execution module transmits information about the command execution status to the speech synthesis module, which, in turn, notifies the user.
Each helper module is a microservice. So, if desired, the user can do without speech technologies at all and turn directly to the assistant's "brain" - to the module for highlighting semantic objects - through the form of a chat bot.
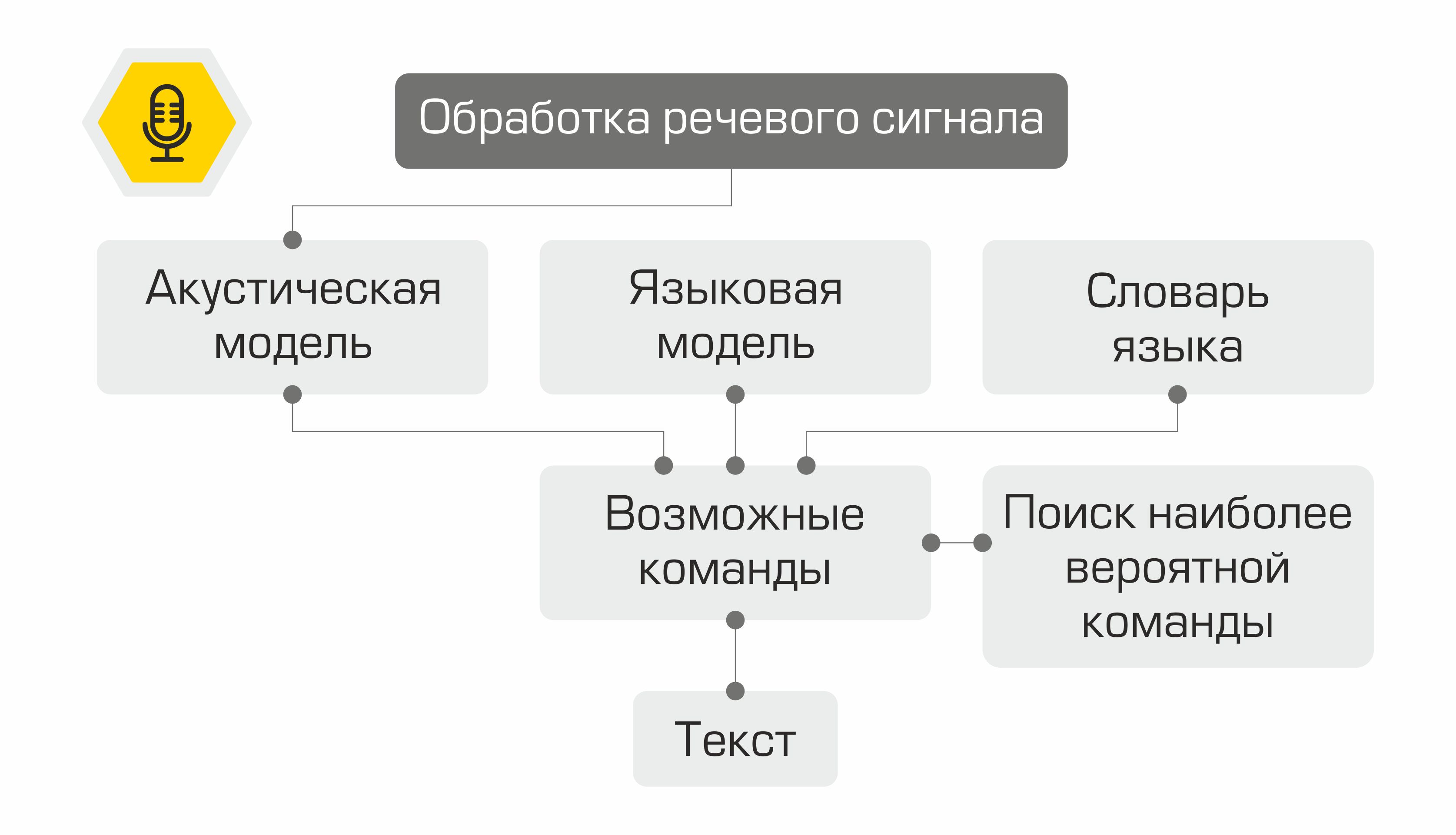
Speech recognition
The first stage of speech recognition is speech signal processing and feature extraction. The simplest representation of an audio signal is an oscillogram. It reflects the amount of energy at any given time. However, this information is not enough to determine the spoken sound. It is important for us to know how much energy is contained in different frequency ranges. To do this, using the Fourier transform, a transition is made from the oscillogram to the spectrum.
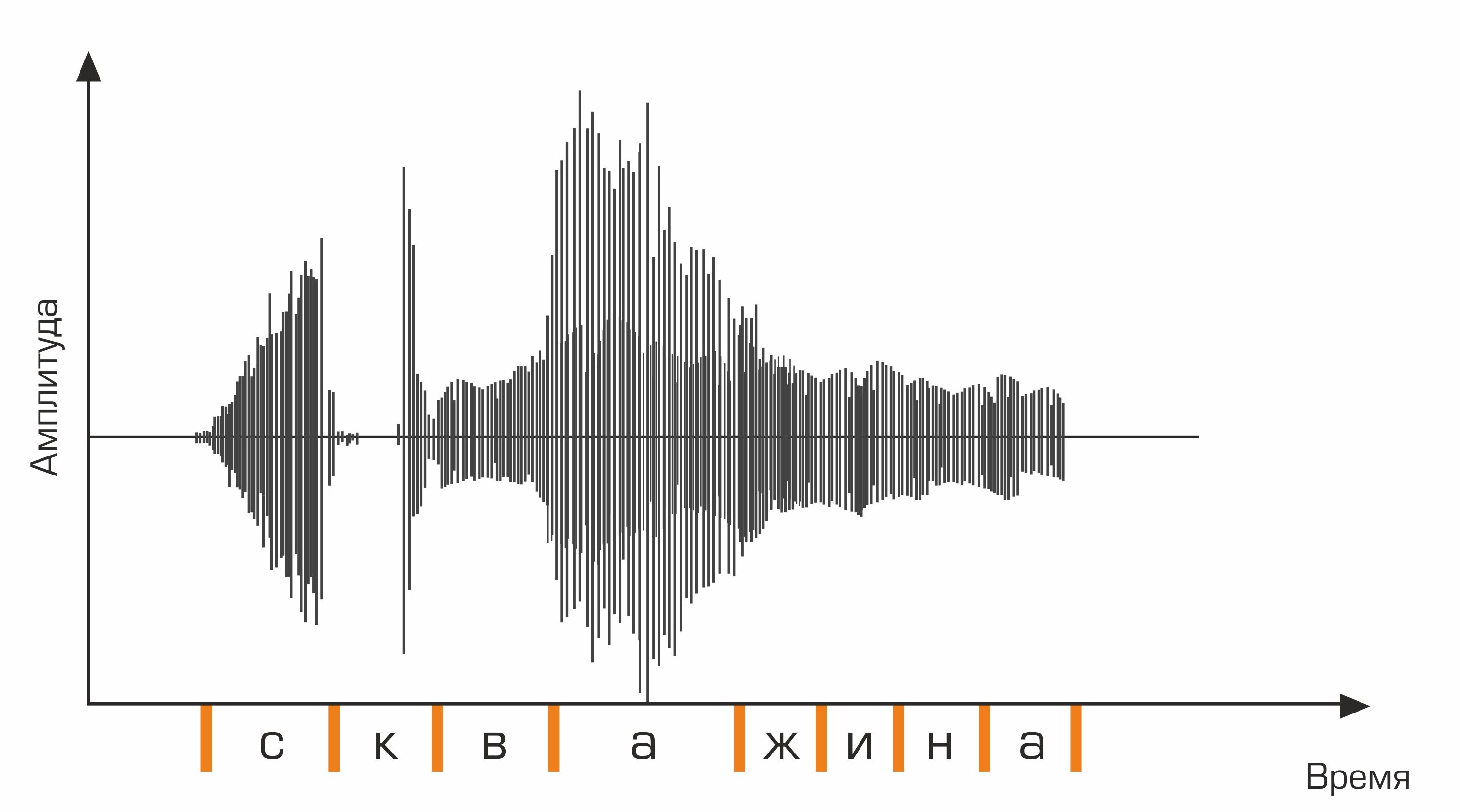
This is an oscillogram.
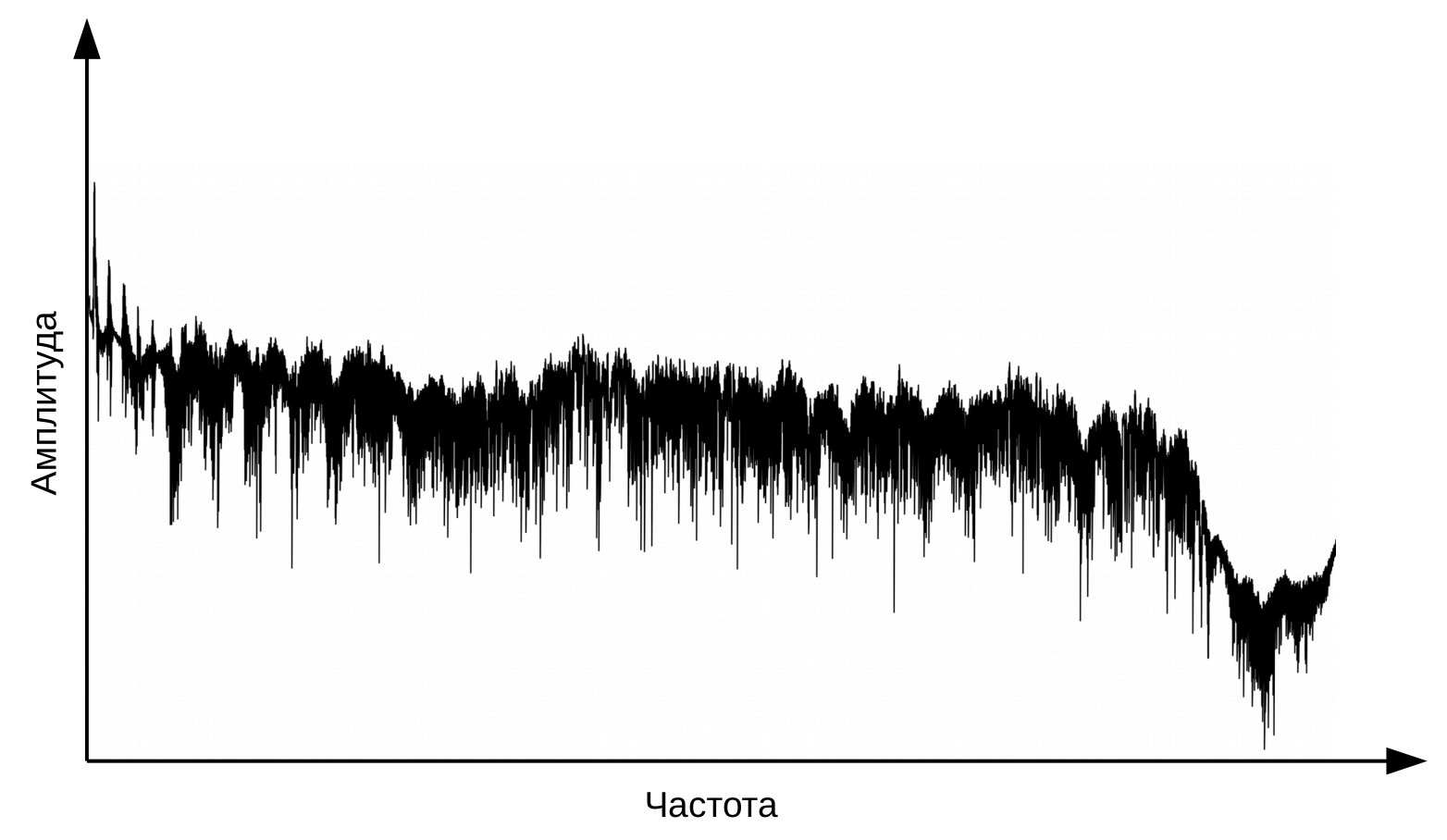
And this is the spectrum for each moment in time.
Here it is necessary to clarify that speech is formed when a vibrating air flow passes through the larynx (source) and the vocal tract (filter). To classify phonemes, we only need information about the configuration of the filter, that is, about the position of the lips and tongue. This information can be distinguished by the transition from spectrum to cepstrum (cepstrum is an anagram of the word spectrum), performed using the inverse Fourier transform of the logarithm of the spectrum. Again, the x-axis is not frequency, but time. The term “frequency” is used to distinguish between the time domains of the cepstrum and the original audio signal (Oppenheim, Schafer. Digital Signal Processing, 2018).
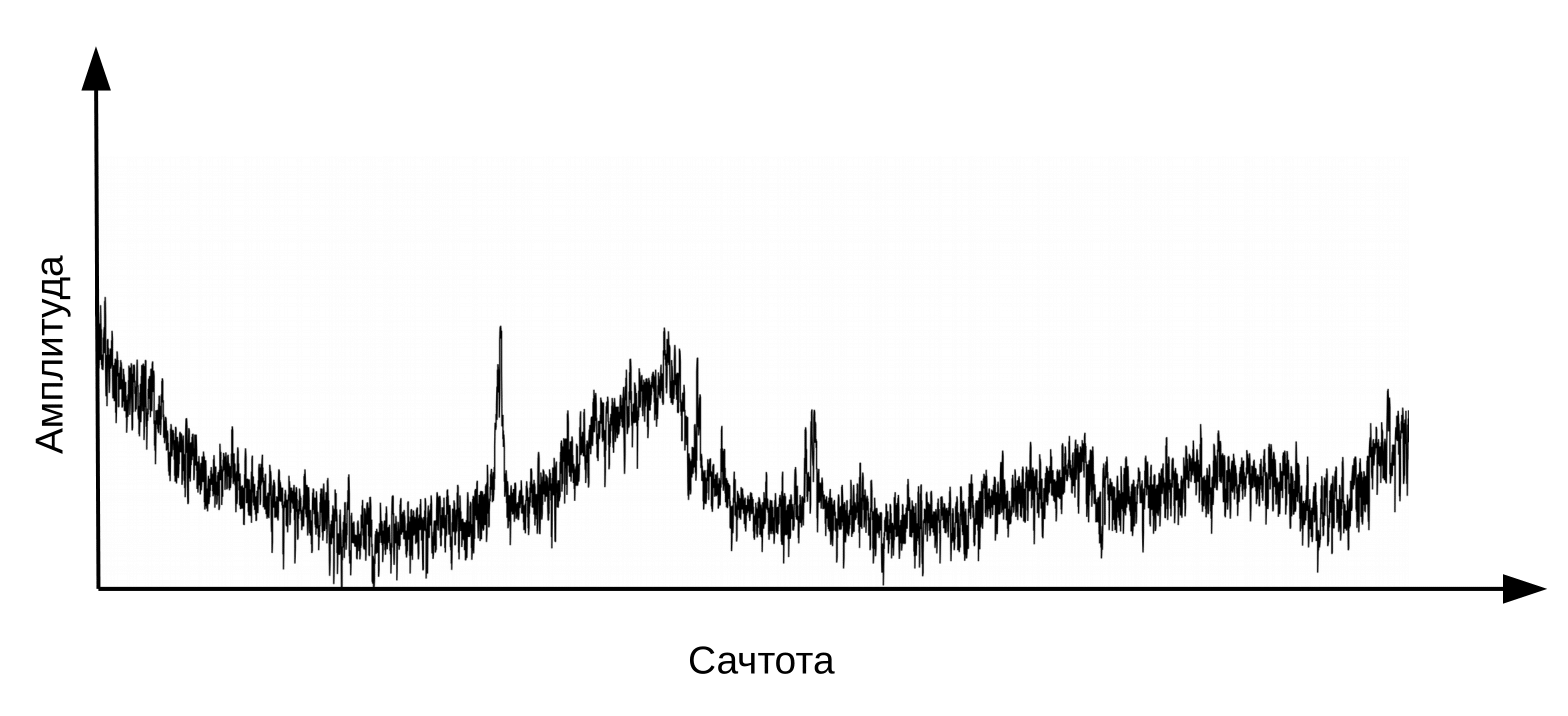
Cepstrum, or simply “spectrum of the logarithm of the spectrum”. Yes, yes, common is a term , not a typo
Information about the position of the vocal tract is found in the first 12 cepstrum coefficients. These 12 cepstral coefficients are supplemented with dynamic features (delta and delta-delta) describing changes in the audio signal. (Jurafsky, Martin. Speech and Language Processing, 2008). The resulting vector of values is called the MFCC vector (Mel-frequency cepstral coefficients) and is the most common acoustic feature used in speech recognition.
What happens next with the signs? They are used as input to the acoustic model. It shows which linguistic unit is most likely to "spawn" such an MFCC vector. In different systems, such linguistic units can be parts of phonemes, phonemes, or even words. Thus, the acoustic model transforms a sequence of MFCC vectors into a sequence of most likely phonemes.
Further, for the sequence of phonemes, it is necessary to select the appropriate sequence of words. This is where the language dictionary comes into play, containing the transcription of all the words recognized by the system. Compiling such dictionaries is a laborious process that requires expert knowledge of the phonetics and phonology of a particular language. An example of a line from a dictionary of transcriptions:
well skv aa zh yn ay
In the next step, the language model determines the prior probability of the sentence in the language. In other words, the model gives an estimate of how likely such a sentence is to appear in a language. A good language model will determine that the phrase "Chart the oil rate" is more likely than the sentence "Chart the nine oil".
The combination of an acoustic model, a language model, and a pronunciation dictionary creates a “grid” of hypotheses - all possible word sequences from which the most probable one can be found using the dynamic programming algorithm. Its system will offer it as a recognized text.
Schematic representation of the operation of the speech recognition system
It would be impractical to reinvent the wheel and write a speech recognition library from scratch, so our choice fell on the kaldi framework . The undoubted advantage of the library is its flexibility, allowing, if necessary, to create and modify all the components of the system. In addition, the Apache License 2.0 allows you to freely use the library in commercial development.
As the data for training an acoustic model used freeware audio dataset VoxForge . To convert a sequence of phonemes into words, we used the Russian language dictionary provided by the CMU Sphinx library . Since the dictionary did not contain the pronunciation of terms specific to the oil industry, based on it, using the utilityg2p-seq2seq trained a grapheme-to-phoneme model to quickly create transcriptions for new words. The language model was trained both on audio transcripts from VoxForge and on a dataset that we created, containing the terms of the oil and gas industry, the names of fields and mining companies.
Selection of semantic objects
So, we recognized the user's speech, but this is just a line of text. How do you tell the computer what to do? The earliest voice control systems used a tightly limited command set. Having recognized one of these phrases, it was possible to call the corresponding operation. Since then, technologies in natural language processing and understanding (NLP and NLU, respectively) have leaped forward. Already today, models trained on large amounts of data are able to understand well the meaning of a statement.
To extract meaning from the text of a recognized phrase, it is necessary to solve two machine learning problems:
- User team classification (Intent Classification).
- Allocation of named entities (Named Entity Recognition).
When developing the models, we used the open source Rasa library , distributed under the Apache License 2.0.
To solve the first problem, it is necessary to represent the text as a numerical vector that can be processed by a machine. For such a transformation, the StarSpace neural model is used , which allows " nesting " the request text and the request class into a common space.

StarSpace Neural Model
During training, the neural network learns to compare entities so as to minimize the distance between the request vector and the vector of the correct class and maximize the distance to the vectors of different classes. During testing, class y is selected for query x so that:
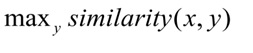
The cosine distance is used as a measure of the similarity of vectors:,
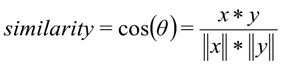
where
x is the user's request, y is the request category.
3000 queries were marked up to train the user intent classifier. In total, we graduated from 8 classes. We divided the sample into training and test samples in a 70/30 ratio using the target variable stratification method. Stratification allowed preserving the original distribution of classes in the train and test. The quality of the trained model was assessed by several criteria at once:
- Recall - the proportion of correctly classified requests for all requests of this class.
- The share of correctly classified requests (Accuracy).
- Precision - the proportion of correctly classified requests relative to all requests that the system assigned to this class.
- F1 – .
Also, the system error matrix is used to assess the quality of the classification model. The y-axis is the true class of the statement, the x-axis is the class predicted by the algorithm.
On the control sample, the model showed the following results:
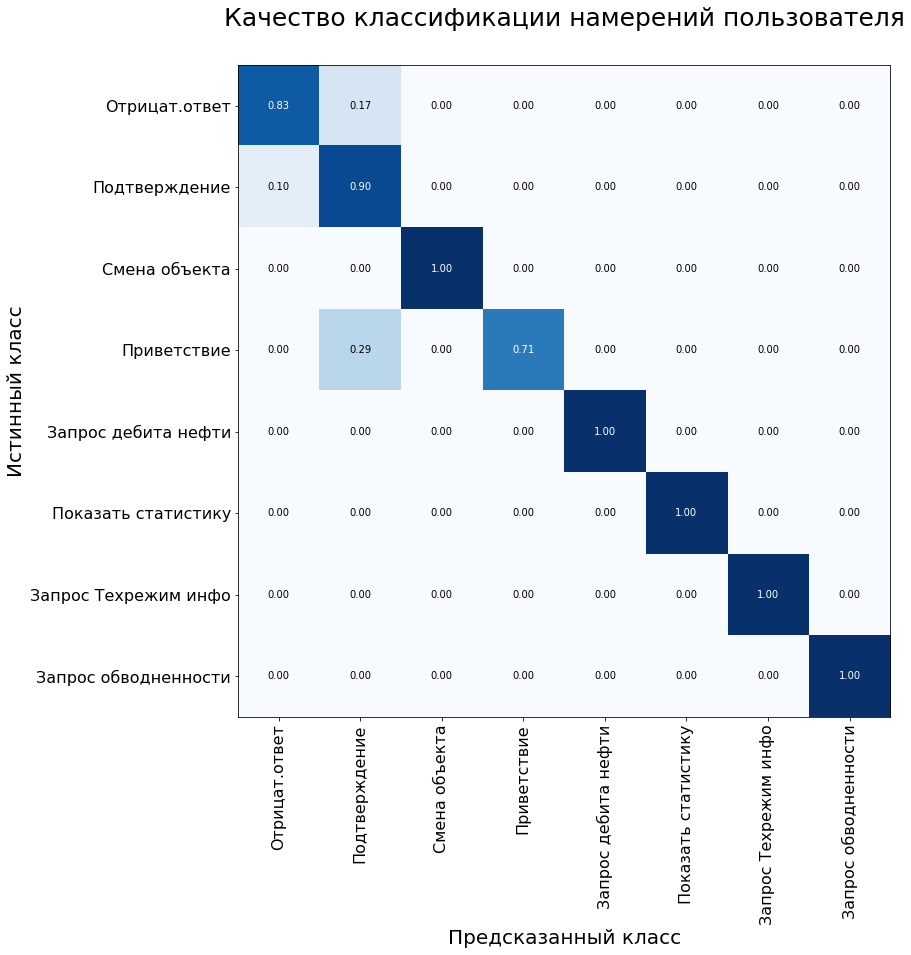
Model metrics on the test dataset: Accuracy - 92%, F1 - 90%.
The second task - the selection of named entities - is to identify words and phrases that denote a specific object or phenomenon. Such entities can be, for example, the name of a deposit or a mining company.
To solve the problem, we used an algorithm of Conditional Random Fields, which are a kind of Markov fields. CRF is a discriminative model, i.e. it models the conditional probability P(Y | X) latent state Y (word class) from observation X (word).
To fulfill user requests, our assistant needs to highlight three types of named entities: field name, well name, and development object name. To train the model, we prepared a dataset and made an annotation: each word in the sample was assigned a corresponding class.

An example from the training set for the Named Entity Recognition problem.
However, everything turned out to be not so simple. Professional jargon is quite common among field developers and geologists. It is not difficult for people to understand that the "injector" is an injection well, and "Samotlor", most likely, means the Samotlor field. For a model trained on a limited amount of data, it is still difficult to draw such a parallel. To cope with this limitation, such a wonderful feature of the Rasa library helps to create a dictionary of synonyms.
## synonym: Samotlor
- Samotlor
- Samotlor
- the largest oil field in Russia
The addition of synonyms also allowed us to slightly expand the sample. The volume of the entire dataset was 2000 requests, which we divided into train and test in a 70/30 ratio. The quality of the model was assessed using the F1 metric and was 98% when tested on a control sample.
Command execution
Depending on the user request class defined in the previous step, the system activates the corresponding class in the software kernel. Each class has at least two methods: a method that directly performs the request and a method for generating a response for the user.
For example, when assigning a command to the "request_production_schedule" class, an object of the RequestOilChart class is created, which unloads information on oil production from the database. Dedicated named entities (for example, well and field names) are used to fill slots in queries to access the database or the software kernel. The assistant answers with the help of prepared templates, the spaces in which are filled with the values of the uploaded data.

An example of an assistant prototype working.
Speech synthesis

How concatenative speech synthesis works.
The user notification text generated at the previous stage is displayed on the screen and is also used as an input for the oral speech synthesis module. Speech generation is carried out using the RHVoice library... The GNU LGPL v2.1 license allows the framework to be used as a component of commercial software. The main components of the speech synthesis system are the linguistic processor, which processes the input text. The text is normalized: the numbers are reduced to written representation, abbreviations are deciphered, etc. Then, using the pronunciation dictionary, a transcription for the text is created, which is then transmitted to the input of the acoustic processor. This component is responsible for selecting sound elements from the speech database, concatenating the selected elements and processing the sound signal.
Putting it all together
So, all the components of the voice assistant are ready. It remains only to "collect" them in the correct sequence and test. As we mentioned earlier, each module is a microservice. The RabbitMQ framework is used as a bus for connecting all modules. The illustration clearly demonstrates the internal work of the assistant using the example of a typical user request:
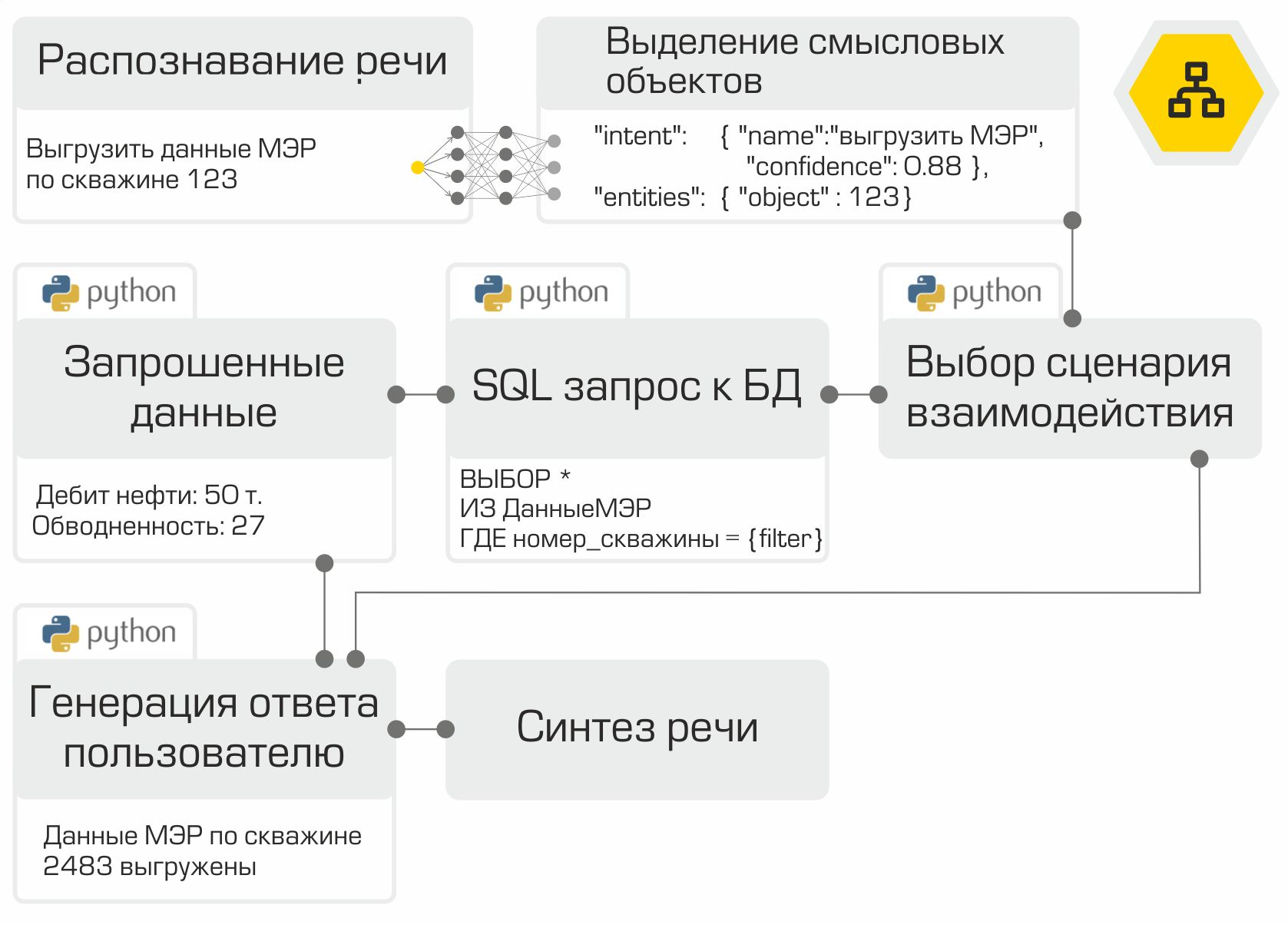
The created solution allows placing the entire infrastructure in the Company's network. Local information processing is the main advantage of the system. However, you have to pay for autonomy because you have to collect data, train and test models yourself, rather than using the power of top vendors in the digital assistant market.
We are currently integrating the assistant into one of our products.
How convenient it will be to search for your well or your favorite bush with just one phrase!
At the next stage, it is planned to collect and analyze feedback from users. There are also plans to expand the commands recognized and executed by the assistant.
The project described in the article is far from the only example of using machine learning methods in our Company. So, for example, data analysis is used to automatically select candidate wells for geological and technical measures, the purpose of which is to stimulate oil production. In one of the upcoming articles, we will tell you how we solved this cool problem. Subscribe to our blog not to miss it!