In this article, you will learn
- What is CNN and how it works
- What is a feature map
- What is max pooling
- Loss functions for various deep learning tasks
Small introduction
This series of articles aims to provide an intuitive understanding of how deep learning works, what the tasks are, network architectures, why one is better than the other. There will be few specific things in the spirit of "how to implement it." Going into every detail makes the material too complex for most audiences. About how the computation graph works or how backpropagation through convolutional layers works has already been written. And, most importantly, it is written much better than I would explain.
In the previous article, we discussed FCNN - what it is and what the problems are. The solution to those problems lies in the architecture of convolutional neural networks.
Convolutional Neural Networks (CNN)
Convolutional neural network. It looks like this (vgg-16 architecture):
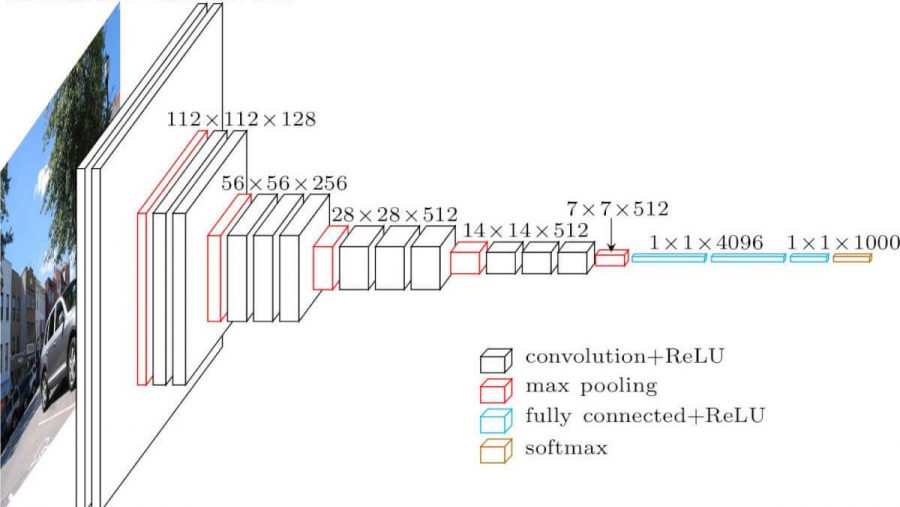
What are the differences from a fully meshed network? The hidden layers now have a convolution operation.
This is how the convolution looks like:

We just take an image (for now - single-channel), take a convolution kernel (matrix), consisting of our training parameters, "overlay" the kernel (usually 3x3) on the image, perform element-wise multiplication of all the pixel values of the image that hit the kernel. Then all this is summed up (you also need to add the bias parameter - offset), and we get some number. This number is the element of the output layer. We move this core along our image with some step (stride) and get the next elements. A new matrix is constructed from such elements, and the next convolution kernel is applied to it (after applying the activation function to it). In the case when the input image is three-channel, the convolution kernel is also three-channel - a filter.
But everything is not so simple here. Those matrices that we get after the convolution are called feature maps, because they store some features of the previous matrices, but in some other form. In practice, several convolution filters are used at once. This is done in order to "bring" as many features as possible to the next convolution layer. With each layer of the convolution, our features, which were in the input image, are presented more and more in abstract forms.
A couple more notes:
- After folding, our feature map becomes smaller (in width and height). Sometimes, in order to reduce the width and height weaker, or not to reduce it at all (same convolution), use the zero padding method - filling with zeros "along the contour" of the input feature map.
- After the most recent convolutional layer, classification and regression tasks use several fully-connected layers.
Why is it better than FCNN
- We can now have fewer trainable parameters between layers
- Now, when we extract features from the image, we take into account not only a single pixel, but also pixels near it (identifying certain patterns in the image)
Max pooling
It looks like this:
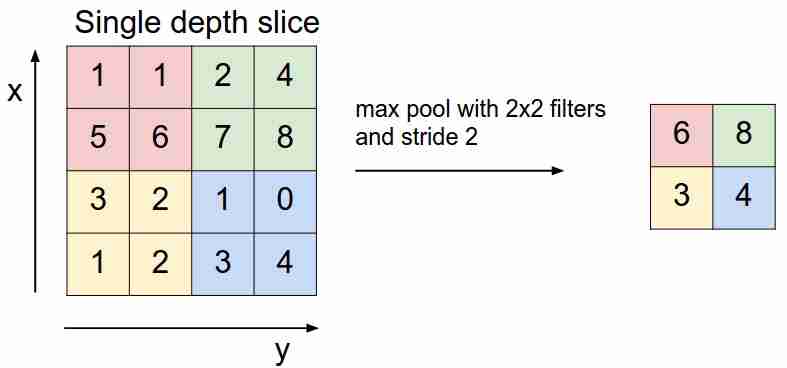
We "slide" over our feature map with a filter and select only the most important (in terms of the incoming signal, as some value) features, decreasing the dimension of the feature map. There is also average (weighted) pooling, when we average the values that fall into the filter, but in practice it is max pooling that is more applicable.
- This layer has no trainable parameters
Loss functions
We feed the network X to the input, reach the output, calculate the value of the loss function, perform the backpropagation algorithm - this is how modern neural networks learn (for now, we are only talking about supervised learning).
Depending on the tasks that neural networks solve, different loss functions are used:
- Regression problem . Mostly they use the mean squared error (MSE) function.
- Classification problem . They mainly use cross-entropy loss.
We are not considering other tasks yet - this will be discussed in the next articles. Why exactly such functions for such tasks? Here you need to enter the maximum likelihood estimation and mathematics. Who cares - I wrote about it here .
Conclusion
I also want to draw your attention to two things used in neural network architectures, including convolutional ones - dropout (you can read it here ) and batch normalization . I highly recommend reading.
In the next article we will analyze CNN architectures, we will understand why one is better than the other.