The translation of the article was prepared on the eve of the start of the course "Industrial ML on Big Data"

Distributed training on multiple HPC instances can reduce the training time of modern deep neural networks on large amounts of data from weeks to hours or even minutes, making this training technique prevalent in deep learning practice. Users need to understand how to share and synchronize data across multiple instances, which in turn has a big impact on scaling efficiency. In addition, users also need to know how to deploy a training script that runs on a single instance on multiple instances.
Apache MXNet Horovod. Horovod , MXNet , Horovod.
Apache MXNet
Apache MXNet – , , . MXNet , , , API , Python, C++, Clojure, Java, Julia, R, Scala .
MXNet
MXNet (parameter server). , . – . , . , , «--» .
Horovod
Horovod – , Uber. GPU , NVIDIA Collective Communications Library (NCCL) Message Passing Interface (MPI) . . , MXNet, Tensorflow, Keras, PyTorch.
MXNet Horovod
MXNet Horovod API , Horovod. Horovod API horovod.broadcast(), horovod.allgather() horovod.allreduce() MXNet, . , MXNet, - . distributed optimizer, Horovod horovod.DistributedOptimizer Optimizer MXNet , API Horovod . .
MNIST MXNet Horovod MacBook.
mxnet horovod PyPI:
pip install mxnet
pip install horovod: pip install horovod, , MACOSX_DEPLOYMENT_TARGET=10.vv, vv – MacOS, , MacOSX Sierra MACOSX_DEPLOYMENT_TARGET=10.12 pip install horovod
mpirun -np 2 -H localhost:2 -bind-to none -map-by slot python mxnet_mnist.py. :
INFO:root:Epoch[0] Batch [0-50] Speed: 2248.71 samples/sec accuracy=0.583640
INFO:root:Epoch[0] Batch [50-100] Speed: 2273.89 samples/sec accuracy=0.882812
INFO:root:Epoch[0] Batch [50-100] Speed: 2273.39 samples/sec accuracy=0.870000ResNet50-v1 ImageNet 64 GPU p3.16xlarge EC2, 8 GPU NVIDIA Tesla V100 AWS cloud, 45000 / (.. ). 44 90 75.7%.
MXNet 8, 16, 32 64 GPU 1 1 2 1 . 1 . y , ( ) y . . , 38% 64 GPU. Horovod .
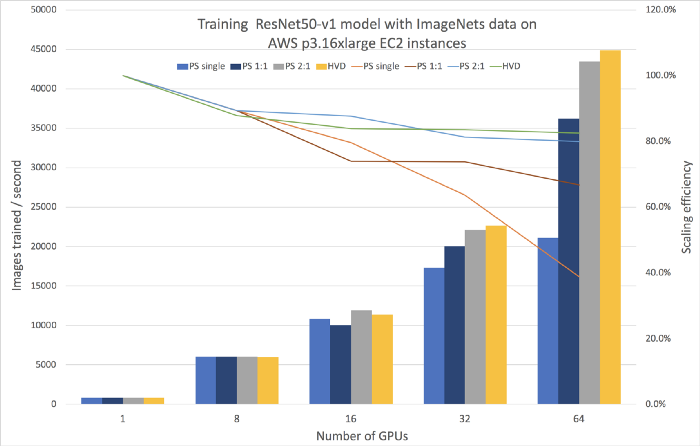
1. MXNet Horovod
1 64 GPU. MXNet Horovod .

1. Horovod 2 1.
1
MXNet 1.4.0 Horovod 0.16.0 , . GPU. Ubuntu 16.04 Linux, GPU Driver 396.44, CUDA 9.2, cuDNN 7.2.1, NCCL 2.2.13 OpenMPI 3.1.1. Amazon Deep Learning AMI, .
2
MXNet API Horovod. MXNet Gluon API . , , , . , Horovod:
- Horovod ( 8), , .
- ( 18), , .
- Horovod DistributedOptimizer ( 25), .
, Horovod-MXNet MNIST ImageNet.
1 import mxnet as mx
2 import horovod.mxnet as hvd
3
4 # Horovod: initialize Horovod
5 hvd.init()
6
7 # Horovod: pin a GPU to be used to local rank
8 context = mx.gpu(hvd.local_rank())
9
10 # Build model
11 model = ...
12
13 # Initialize parameters
14 model.initialize(initializer, ctx=context)
15 params = model.collect_params()
16
17 # Horovod: broadcast parameters
18 hvd.broadcast_parameters(params, root_rank=0)
19
20 # Create optimizer
21 optimizer_params = ...
22 opt = mx.optimizer.create('sgd', **optimizer_params)
23
24 # Horovod: wrap optimizer with DistributedOptimizer
25 opt = hvd.DistributedOptimizer(opt)
26
27 # Create trainer and loss function
28 trainer = mx.gluon.Trainer(params, opt, kvstore=None)
29 loss_fn = ...
30
31 # Train model
32 for epoch in range(num_epoch):
33 ...3
MPI. , 4 GPU , 16 GPU . (SGD) :
- mini-batch size: 256
- learning rate: 0.1
- momentum: 0.9
- weight decay: 0.0001
GPU 64 GPU GPU ( 0,1 1 GPU 6,4 64 GPU), , GPU, 256 ( 256 1 GPU 16 384 64 GPU). weight decay momentum GPU. float16 float32 , float16, GPU NVIDIA Tesla.
$ mpirun -np 16 \
-H server1:4,server2:4,server3:4,server4:4 \
-bind-to none -map-by slot \
-mca pml ob1 -mca btl ^openib \
python mxnet_imagenet_resnet50.pyApache MXNet Horovod. ImageNet, ResNet50-v1. , , Horovod.
MXNet , MXNe, MXNet. MXNet in 60 minutes, .
MXNet Horovod, Horovod, MXNet MNIST ImageNet.