Prerequisites
The task of searching for a phrase in a text paginated is reduced to calculating the relevance coefficient for each of the pages and then sorting the list in descending order of the coefficient.
In the process of calculating in accordance with the basic approach, each page is subjected to symbol-by-symbol analysis, and here lies the possibility of optimization.

When calculating the coefficient, groups of matching characters of search strings and data are analyzed, while groups can be formed only within words. On the other hand, considering the problem of overestimating the importance of "long" words (in part 2 ), as a possible solution was proposed " calculating the relevance of a search phrase as an average of the relevances of the words included in it, calculated independently ." Using an index will produce a result equivalent to this particular approach.
Index
The idea of indexing is not new and is as follows - due to the fact that words in the text are repeated, the amount of calculations can be reduced. To do this, the text in which the search will be carried out must first generate an index. In the simplest case, the index is a table of all words in the text, which, in addition to words, contains data about the pages on which they occur. Fragment of the index table based on the text of the novel by L.N. Tolstoy's "War and Peace" (in total it contains about 50 thousand words), is shown in the figure.

Directly in the process of processing a request, the search string is first broken into words. Further, for each of the words of the search string, relevance is calculated with each of the words in the index . The calculation results are accumulated intable of preliminary results containing columns "Search string word", "Index word", "Relevance factor", "Page number". The table contains only those rows of the index, the relevance coefficient for which words has exceeded the specified threshold. That is, each row of the index with a matching word generates rows in the table of preliminary results equal to the number of text pages on which this word occurs. Below is a fragment of the table of preliminary results for the search for the phrase "Evening at Anna Pavlovna Sherer's".

Then the table of preliminary results is sorted by columns Page number , Search string word , Factor(descending).

By traversing the rows of the sorted table, for each of the pages and for each word of the search string, the most relevant word of this page is identified - thanks to the sorting described above, this is the first word for each combination Page number - Search string word . The rest of the lines are discarded by combination.
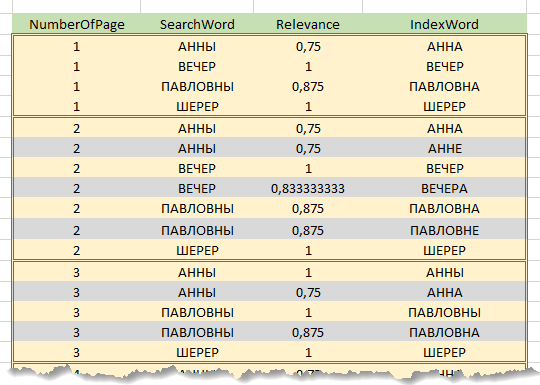
Thus, for each page of text included in the table of preliminary results , for each word in the search string, the most relevant words of this page with the corresponding coefficients will be found. The sum of the coefficients of words found on the page, referred to the number of words in the search bar, will give the coefficient of relevance for the page.

For example, in the above figure, the search is performed by the line "Evening at Anna Pavlovna Sherer's" (the preposition "y" is not taken into account), the lines highlighted in gray are discarded during the bypass. The relevance coefficient for page 1 will be (0.75 + 1 + 0.875 + 1) / 4 = 0.906, for page 2 - 0.906, for 3 - 0.75.
Benefits
If you do not take into account time spent in indexing, the results of which are reused and take into account that the total amount of computation, assessment of which is reproduced in part 1. , A multiple of the length of the data string:
 ;
;
we can say that the gain from using the index will be a multiple of the ratio:
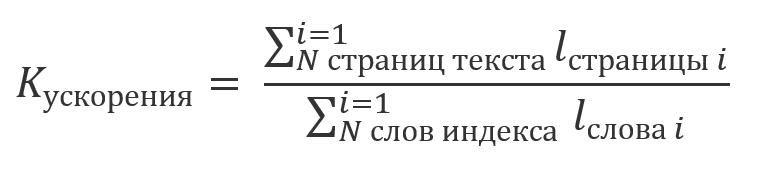
For example, on the demo stand textradar.ru , the text of the novel "War and Peace" is divided into 1488 pages of 2000 characters each. The total number of symbols in the words of the index, consisting of 52156 elements, is 434060. That is, the gain from indexing will be about 7:

Due to the fact that the results obtained using indexing are equivalent to the results obtained using one of the previously described approaches without it, it becomes possible to jointly process the search results for the indexed and non-indexed parts of the text. Due to the fact that indexing is a relatively expensive operation and is usually performed on a schedule, it is possible that a part of the text is indexed, and some is not yet. In this case, the savings in the amount of computation will be a multiple of the share of the indexed text in its total size:
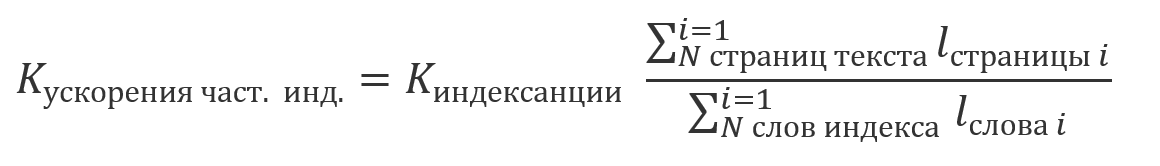
In addition to improving search speed, using an index opens up a number of other possibilities. For example, using statistics obtained from indexing, you can increase the importance of rare words, as well as highlight the pages of text on which the significant words of the search phrase are found more often. You can also extend the index table with synonyms.
This concludes the cycle of publications devoted to the description of TextRadar. Thank you all for your interest and valuable comments that allowed us to move further than originally planned.
The results of applying the described approaches can be seen on the demo stand deployed on the website textradar.ru . The implementation (C # ASP.NET MVC) can be found here .