
Good day. Our names are Tatiana Voronova and Elvira Dyaminova, we are engaged in data analysis at Center 2M. In particular, we train neural network models for detecting objects in images: people, special equipment, animals.
At the beginning of each project, the company negotiates with the customers about the acceptable recognition quality. This level of quality must not only be ensured upon delivery of the project, but also maintained during the further operation of the system. It turns out that it is necessary to constantly monitor and retrain the system. I would like to reduce the costs of this process and get rid of the routine procedure, freeing up time to work on new projects.
Automatic retraining is not a unique idea, many companies have similar internal pipeline tools. In this article, we would like to share our experience and show that it is not at all necessary to be a huge corporation to successfully implement such practices.
One of our projects is counting people in queues . Due to the fact that the customer is a large company with a large number of branches, people gather at certain times as scheduled, that is, a large number of objects (heads of people) are regularly detected. Therefore, we decided to start the implementation of automatic retraining precisely for this task.
This is what our plan looked like. All items, except for the work of the scriber, are carried out in automatic mode:
- Once a month, all camera images from the last week are automatically selected.
- xls- sharepoint, - : « ».
- ( ) – xml- ( ), – .
- « ». xls- ( – , – ). «». , , .
, : (, ) , , (, - ). -. - xls- «» > 0. , ( ). , . , , « ». , . , . , , .
- «» 0, – - .
- , , , , . , .
In the end, this process helped us a lot. We tracked the increase in errors of the second kind, when many heads suddenly became "masked", enriched the training dataset with a new type of heads in time and retrained the current model. Plus, this trip allows you to take into account the seasonality. We are constantly adjusting the dataset taking into account the current situation: people often wear hats or, on the contrary, almost everyone comes to the institution without them. In autumn, the number of people wearing hoods increases. The system becomes more flexible and reacts to the situation.
For example, in the image below - one of the branches (on a winter day), the frames of which were not presented in the training dataset:
If we calculate the metrics for this frame (TP = 25, FN = 3, FP = 0), then it turns out that recall is 89%, precision is 100%, and the harmonic average between accuracy and completeness is about 94. 2% (about metrics just below). Pretty good result for a new room.
Our training dataset had both caps and hoods, so the model did not get confused, but with the onset of the mask mode it began to make mistakes. In most cases, when the head is clearly visible, problems do not arise. But if a person is far from the camera, then at a certain angle, the model stops detecting the head (the left image is the result of the work of the old model). Thanks to the semi-automatic marking, we were able to fix such cases and retrain the model in time (the right image is the result of the new model).

Lady close:

When testing the model, we selected frames that were not involved in training (a dataset with a different number of people on the frame, in different angles and different sizes), to assess the quality of the model, we used recall and precision.
Recall - completeness shows what proportion of objects that really belong to a positive class, we predicted correctly.
Precision - the accuracy shows what proportion of objects recognized as objects of a positive class, we predicted correctly.
When a customer needed a single digit, a combination of precision and completeness, we provided the harmonic mean, or F-measure. Learn more about metrics.
After one cycle, we got the following results:
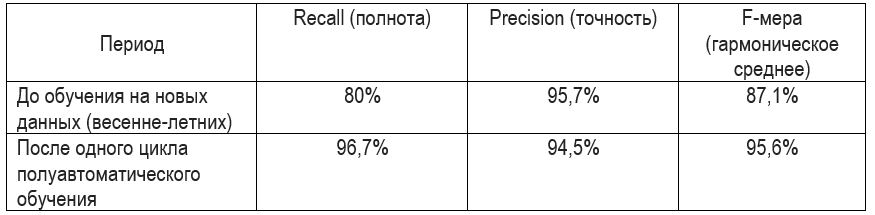
The completeness of 80% before any changes is due to the fact that a large number of new departments were added to the system, new views appeared. In addition, the season has changed; before that, "autumn-winter people" were presented in the training dataset.
After the first cycle, the completeness became 96.7%. Compared with the first article, the completeness there reached 90%. Such changes are due to the fact that now the number of people in the departments has decreased, they began to overlap each other much less (bulky down jackets have run out), and the variety of hats has diminished.
For example, before the norm was about the same number of people as in the image below.

This is how things are now.

Summing up, let's name the advantages of automation:
- Partial automation of the marking process.
- ( ).
- ( ).
- . .
- . , .
The downside is the human factor on the part of the markup designer - he may not be responsible enough to the markup, therefore markup with overlapping or the use of golden sets - tasks with a predetermined answer, serving only to control the markup quality, is necessary. In many more complex tasks, the analyst must personally check the markup - in such tasks the automatic mode will not work.
In general, the practice of automatic retraining has proven to be viable. Such automation can be considered as an additional mechanism that allows maintaining the recognition quality at a good level during the further operation of the system.
Authors of the article: Tatiana Voronova (tvoronova), Elvira Dyaminova (elviraa)