Ab Initio has many classic and unusual transformations that can be extended with its own PDL. For a small business, such a powerful tool is likely to be redundant, and most of its capabilities may be expensive and unnecessary. But if your scale is close to Sberbank's, then Ab Initio may be interesting to you.
It helps the business to globally accumulate knowledge and develop the ecosystem, and the developer - to pump their skills in ETL, to pull up knowledge in the shell, provides an opportunity to master the PDL language, gives a visual picture of loading processes, simplifies development due to the abundance of functional components.
In this post I will talk about the capabilities of Ab Initio and give comparative characteristics of its work with Hive and GreenPlum.
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
The functionality of this product is very wide and takes a lot of time to learn. However, with the proper working skills and the right performance settings, the data processing results are quite impressive. Using Ab Initio for a developer can give him an interesting experience. This is a new take on ETL development, a hybrid between a visual environment and download development in a script-like language.
Business develops its ecosystems and this tool comes in handy more than ever. With the help of Ab Initio, you can accumulate knowledge about your current business and use this knowledge to expand old and open new businesses. Alternatives to Ab Initio can be called from the visual development environments Informatica BDM and from non-visual environments - Apache Spark.
Description of Ab Initio
Ab Initio, like other ETL tools, is a suite of products.

Ab Initio GDE (Graphical Development Environment) is an environment for a developer in which he sets up data transformations and connects them with data streams in the form of arrows. In this case, such a set of transformations is called a graph:

Input and output connections of functional components are ports and contain fields calculated within the transformations. Several graphs connected by streams in the form of arrows in the order of their execution are called a plan.
There are several hundred functional components, which is a lot. Many of them are highly specialized. Ab Initio has a wider range of classic transformations than other ETL tools. For example, Join has multiple outputs. In addition to the result of connecting datasets, you can get at the output records of input datasets, by keys of which it was not possible to connect. You can also get rejects, errors and a log of the transformation operation, which can be read in the same column as a text file and processed by other transformations:

Or, for example, you can materialize the data receiver in the form of a table and read data from it in the same column.
There are original transformations. For example, the Scan transformation has the same functionality as analytical functions. There are transformations with self-explanatory names: Create Data, Read Excel, Normalize, Sort within Groups, Run Program, Run SQL, Join with DB, etc. Graphs can use runtime parameters, including transferring parameters from the operating system or to the operating system ... Files with a ready-made set of parameters passed to the graph are called parameter sets (psets).
As expected, Ab Initio GDE has its own repository called EME (Enterprise Meta Environment). Developers have the ability to work with local versions of the code and check in their developments to the central repository.
It is possible, during execution or after the execution of the graph, to click on any stream connecting the transformation and look at the data that passed between these transformations:

It is also possible to click on any stream and see the tracking details - in how many parallels the transformation worked, how many lines and bytes in which parallels are loaded:

It is possible to split the execution of the graph into phases and mark that some transformations must be performed first (in phase zero), following in the first phase, following in the second phase, etc.
For each transformation, you can choose the so-called layout (where it will be executed): without parallels or in parallel threads, the number of which can be set. At the same time, temporary files created by Ab Initio during the work of transformations can be placed both in the server file system and in HDFS.
In each transformation, based on the default template, you can create your own script in the PDL language, which is a bit like a shell.
With the help of the PDL language, you can extend the functionality of transformations and, in particular, you can dynamically (at runtime) generate arbitrary code fragments depending on the runtime parameters.
Also, Ab Initio has a well-developed integration with the OS through the shell. Specifically, Sberbank uses linux ksh. You can exchange variables with shell and use them as graph parameters. You can call execution of Ab Initio graphs from the shell and administer Ab Initio.
In addition to Ab Initio GDE, the delivery includes many other products. There is a Co> Operation System with a claim to be called an operating system. There is Control> Center where you can schedule and monitor download streams. There are products for doing development at a more primitive level than Ab Initio GDE allows.
Description of the MDW framework and work on its customization for GreenPlum
Together with its products, the vendor supplies the product MDW (Metadata Driven Warehouse), which is a graph configurator designed to help with typical tasks of filling data warehouses or data vaults.
It contains custom (project-specific) metadata parsers and out-of-the-box code generators.
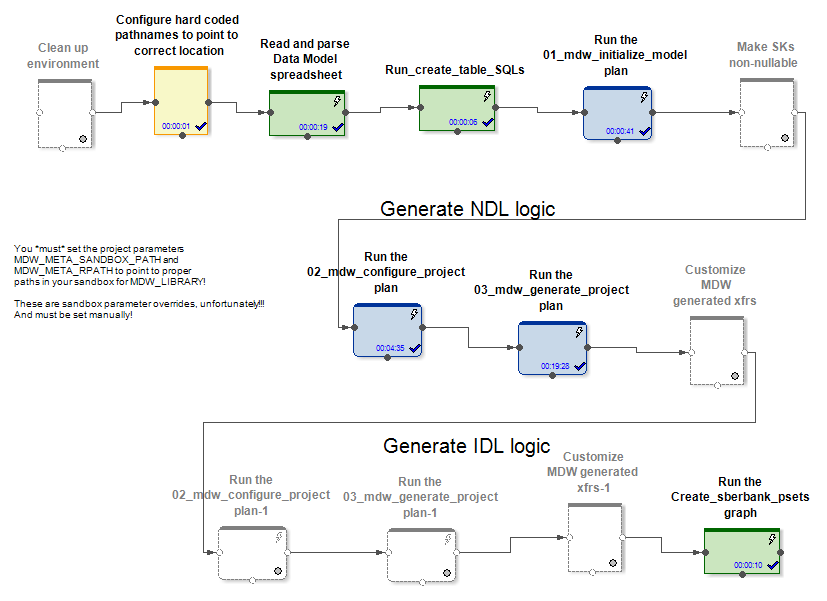
At the entrance, MDW receives a data model, a configuration file for setting up a database connection (Oracle, Teradata, or Hive) and some other settings. The project-specific part, for example, deploys the model to the database. The boxed part of the product generates graphs and configuration files for them upon loading data into the model tables. This creates graphs (and psets) for several modes of initializing and incremental work on updating entities.
In the Hive and RDBMS cases, different initializing and incremental data refresh graphs are generated.
In the case of Hive, the incoming delta data is joined by Ab Initio Join to the data that was in the table before the update. Data loaders in MDW (both in Hive and in RDBMS) not only insert new data from the delta, but also close the data validity periods for which the delta was received by the primary keys. In addition, you have to rewrite the unchanged part of the data. But this has to be done, since Hive does not have delete or update operations.
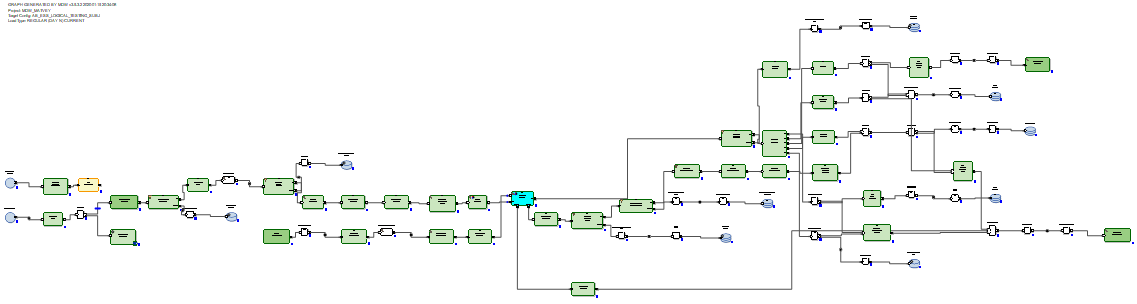
In the case of RDBMS, the incremental data update graphs look more optimal because RDBMS have real update capabilities.
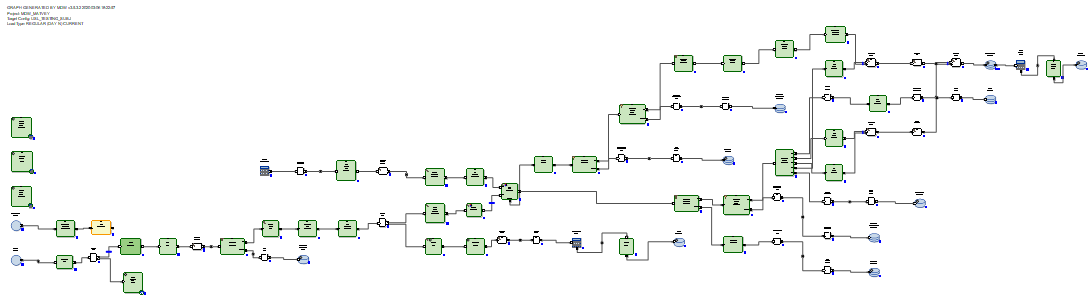
The received delta is loaded into a staging table in the database. After that, the delta is connected to the data that was in the table before the update. And this is done by means of SQL through the generated SQL query. Then, using the delete + insert SQL commands, new data from the delta is inserted into the target table and the periods of relevance of the data are closed, according to the primary keys of which the delta was received.
There is no need to rewrite unchanged data.
Thus, we came to the conclusion that in the case of Hive, MDW should go to rewrite the entire table, because Hive does not have an update function. And nothing better than a complete rewriting of data when updating is not invented. In the case of RDBMS, on the contrary, the creators of the product considered it necessary to entrust the connection and update of tables using SQL.
For a project at Sberbank, we created a new reusable implementation of the GreenPlum database loader. This was done based on the version that MDW generates for Teradata. It was Teradata, not Oracle, that came up best and closest for this. is also an MPP system. The way of working, as well as the syntax of Teradata and GreenPlum, turned out to be similar.
Examples of critical differences for MDW between different RDBMS are as follows. In GreenPlum, unlike Teradata, when creating tables, you need to write a clause
distributed byTeradata writes
delete <table> all, and in GreenePlum they write
delete from <table>Oracle writes for optimization purposes
delete from t where rowid in (< t >), and Teradata and GreenPlum write
delete from t where exists (select * from delta where delta.pk=t.pk)We also note that for Ab Initio to work with GreenPlum, it was required to install the GreenPlum client on all nodes of the Ab Initio cluster. This is because we have connected to GreenPlum simultaneously from all nodes in our cluster. And in order for reading from GreenPlum to be parallel and each parallel Ab Initio thread to read its own portion of data from GreenPlum, it was necessary to put a construction understood by Ab Initio in the "where" section of SQL queries
where ABLOCAL()and determine the value of this construction by specifying the parameter reading from the transformation database
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»which compiles to something like
mod(sk,10)=3, i.e. you have to tell GreenPlum an explicit filter for each partition. For other databases (Teradata, Oracle) Ab Initio can do this parallelization automatically.
Comparative performance characteristics of Ab Initio for working with Hive and GreenPlum
An experiment was conducted at Sberbank to compare the performance of the graphs generated by MDW in relation to Hive and in relation to GreenPlum. As part of the experiment, in the case of Hive, there were 5 nodes on the same cluster as Ab Initio, and in the case of GreenPlum, there were 4 nodes on a separate cluster. Those. Hive had some hardware advantage over GreenPlum.
We looked at two pairs of graphs that perform the same task of updating data in Hive and GreenPlum. The graphs generated by the MDW configurator were launched:
- initializing load + incremental loading of randomly generated data into the Hive table
- initializing load + incremental loading of randomly generated data into the same GreenPlum table
In both cases (Hive and GreenPlum) launched downloads in 10 parallel threads on the same Ab Initio cluster. Ab Initio saved intermediate data for calculations in HDFS (in terms of Ab Initio, MFS layout using HDFS was used). One line of randomly generated data occupied 200 bytes in both cases.
The result is like this:
Hive:
| Initializing loading in Hive | |||
| Rows inserted | 6,000,000 | 60,000,000 | 600,000,000 |
| Duration of initializing
load in seconds |
41 | 203 | 1 601 |
| Incremental loading in Hive | |||
| The number of rows in the
target table at the start of the experiment |
6,000,000 | 60,000,000 | 600,000,000 |
| Number of delta rows applied to the
target table during the experiment |
6,000,000 | 6,000,000 | 6,000,000 |
| Incremental
download duration in seconds |
88 | 299 | 2,541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
We see that the speed of initializing loading in both Hive and GreenPlum linearly depends on the amount of data and, for reasons of better hardware, it is somewhat faster for Hive than for GreenPlum.
Incremental loading in Hive also linearly depends on the amount of previously loaded data in the target table and is rather slow as the amount grows. This is due to the need to completely overwrite the target table. This means that applying small changes to huge tables is not a good use case for Hive.
Incremental loading in GreenPlum weakly depends on the amount of previously loaded data available in the target table and is quite fast. This happened thanks to SQL Joins and the GreenPlum architecture, which allows the delete operation.
So, GreenPlum injects the delta using the delete + insert method, while Hive does not have delete or update operations, so the entire data array had to be rewritten entirely during an incremental update. The most indicative is the comparison of the cells highlighted in bold, as it corresponds to the most frequent variant of the operation of resource-intensive downloads. We see that GreenPlum won 8 times over Hive in this test.
Ab Initio with GreenPlum in Near Real Time
In this experiment, we will test Ab Initio's ability to update the GreenPlum table with randomly generated chunks of data in near real time. Consider the table GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, with which we will work.
We will use three Ab Initio graphs to work with it:
1) Create_test_data.mp graph - creates files with data in HDFS for 6,000,000 lines in 10 parallel streams. The data is random, their structure is organized for insertion into our table

2) Graph mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset - generated MDW graph for initializing data insertion into our table in 10 parallel threads (test data generated by graph (1) is used)

3) Graph mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset - MDW-generated graph for incremental updating of our table in 10 parallel threads using a portion of fresh incoming data (delta) generated by the graph (1)

Let's execute the following script in NRT mode:
- generate 6,000,000 test lines
- do initializing load insert 6,000,000 test lines into empty table
- repeat 5 times incremental download
- generate 6,000,000 test lines
- make an incremental insert of 6,000,000 test rows into the table (in this case, the old data is stamped with the expiration time valid_to_ts and more recent data with the same primary key are inserted)
Such a scenario emulates the mode of real operation of a certain business system - a fairly large portion of new data appears in real time and immediately pours into GreenPlum.
Now let's see the log of the script:
Start Create_test_data.input.pset at 2020-06-04 11:49:11
Finish Create_test_data.input.pset at 2020-06-04 11:49:37
Start mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:49:37
Finish mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:50:42
Start Create_test_data.input.pset at 2020-06-04 11:50:42
Finish Create_test_data.input.pset at 2020-06-04 11:51:06
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
Start Create_test_data.input.pset at 2020-06-04 11:59:55
Finish Create_test_data.input.pset at 2020-06-04 12:00:23
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 12:00:23
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 12:03:23
Start Create_test_data.input.pset at 2020-06-04 12:03:23
Finish Create_test_data.input.pset at 2020-06-04 12:03:49
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 12:03:49
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 12:03:49 : 46 The
picture looks like this:
| Graph | Start time | Finish time | Length |
|---|---|---|---|
| Create_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Create_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Create_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Create_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 06/04/2020 11:59:55 | 00:02:41 |
| Create_test_data.input.pset | 06/04/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 06/04/2020 12:03:23 PM | 00:03:00 |
| Create_test_data.input.pset | 06/04/2020 12:03:23 PM | 06/04/2020 12:03:49 PM | 00:00:26 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:03:49 PM | 06/04/2020 12:06:46 PM | 00:02:57 |
We see that 6,000,000 increment lines are processed in 3 minutes, which is quite fast.
The data in the target table turned out to be distributed as follows:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;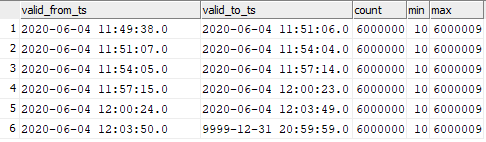
You can see the correspondence of the inserted data to the moments of the graph launch.
This means that you can start incremental loading of data into GreenPlum in Ab Initio with a very high frequency and observe a high speed of inserting this data into GreenPlum. Of course, it will not be possible to start once a second, since Ab Initio, like any ETL tool, takes time to "swing" at startup.
Conclusion
Now Ab Initio is used in Sberbank to build the Unified Semantic Data Layer (ESS). This project involves building a single version of the state of various banking business entities. Information comes from various sources, replicas of which are prepared on Hadoop. Based on the needs of the business, a data model is prepared and data transformations are described. Ab Initio uploads information to the ECC and the loaded data is not only of interest to the business in itself, but also serves as a source for building data marts. At the same time, the functionality of the product allows you to use various systems (Hive, Greenplum, Teradata, Oracle) as a receiver, which makes it possible to effortlessly prepare data for business in various formats it requires.
Ab Initio's capabilities are wide, for example, the included MDW framework makes it possible to build technical and business historical data out of the box. For developers, Ab Initio gives the opportunity to “not reinvent the wheel”, but to use many of the available functional components, which are, in fact, libraries needed when working with data.
The author is an expert of the Sberbank professional community SberProfi DWH / BigData. The professional community SberProfi DWH / BigData is responsible for the development of competencies in such areas as the Hadoop ecosystem, Teradata, Oracle DB, GreenPlum, as well as BI tools Qlik, SAP BO, Tableau, etc.