bayt.
Why me this should worry
The data is stored in memory in the form of data structures, such as objects, lists, arrays, etc. But if you want to send data over the network or to a file, you need to encode them as a sequence of baytov. Translation representations in the memory in a sequence of bytes is called encoding, and inverse transformation - dekodirovaniem. eventually data diagram processed by the application, or stored in memory may evolve, new fields may be added to or removed starye. Consequently, Used encoding must have as reverse (new code must be capable read data write old code), so and direct (old code must be capable read data wrotenewcode) compatibility.
In
this article, we will discuss a variety of encoding formats, find out why the binary coding is better than JSON, XML, and also as binary coding methods support changes schemes
dannyh.
Types formats coding
Thereare two types of encoding formats:
- Text formats
- Binary formats
Text formats
Textformats to some extent chelovekochitaemy. Examples of common formats are JSON, CSV, and XML. Text formats are easy to use and understand, but they have certain problems:
- . , XML CSV . JSON , , . . , , 2^53 Twitter, 64- . JSON, API Twitter, ID — JSON- – - , JavaScript- .
- CSV , .
- Text formats take up more space than binary encoding. For example, one of the reasons is that JSON and XML are schemaless and therefore must contain field names.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}The JSON encoding of this example takes 82 bytes after all whitespace has been removed.
Binary encoding
For data analysis that is only used internally, you can choose a leaner or faster format. Although JSON is less verbose than XML, both of them still take up a lot of space when compared to binary formats. In this article, we will discuss three different binary encoding formats:
- Thrift
- Protocol buffers
- Avro
All of them provide efficient serialization of data using schemas and have tools for generating code, as well as support for working with different programming languages. They all support schema evolution, providing both backward and forward compatibility.
Thrift and Protocol Buffers
Thrift is developed by Facebook and Protocol Buffers is developed by Google. In both cases, a schema is required to encode the data. Thrift defines a schema using its own interface definition language (IDL).
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
Equivalent scheme for Protocol Buffers:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}As you can see, each field has a data type and tag number (1, 2, and 3). Thrift has two different binary encoding formats: BinaryProtocol and CompactProtocol. The binary format is simple as shown below and takes 59 bytes to encode the data above.
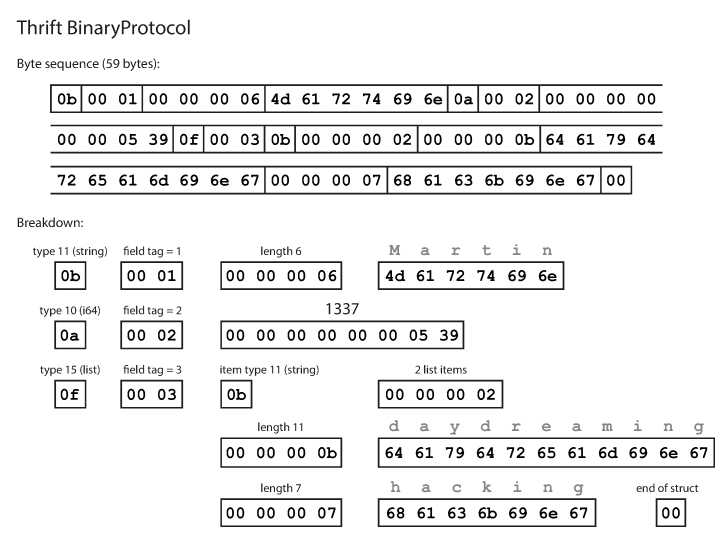
Encoding using the Thrift binary protocol The
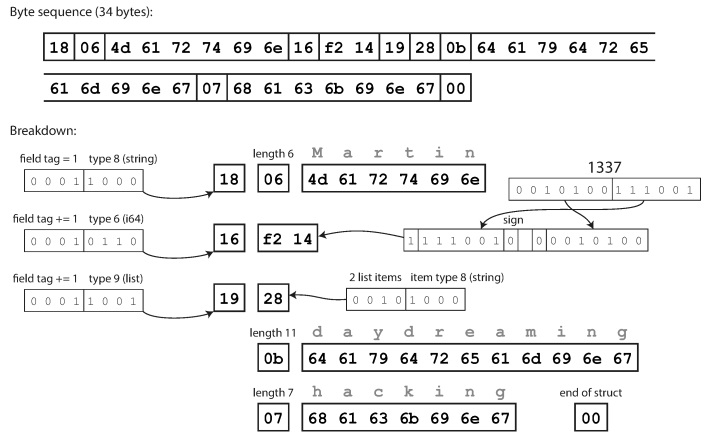
compact protocol is semantically equivalent to binary, but packs the same information into only 34 bytes. Savings are achieved by packing the field type and tag number into one byte.
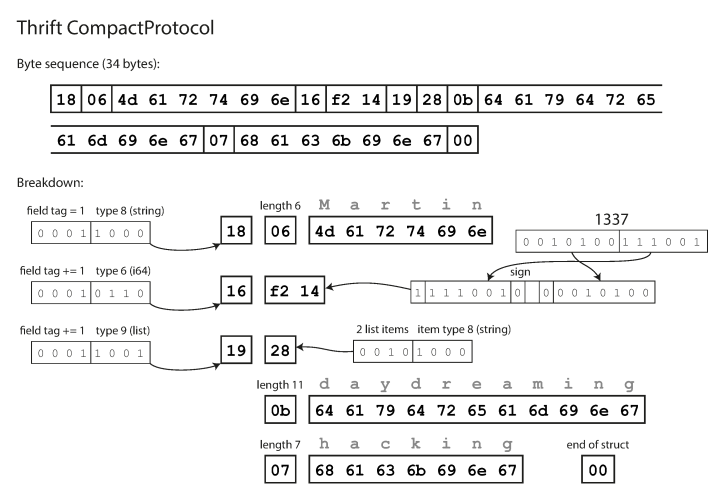
Encoding using Thrift Compact
Protocol Buffers encodes data in a manner similar to Thrift's compact protocol, and after encoding, the same data is 33 bytes.
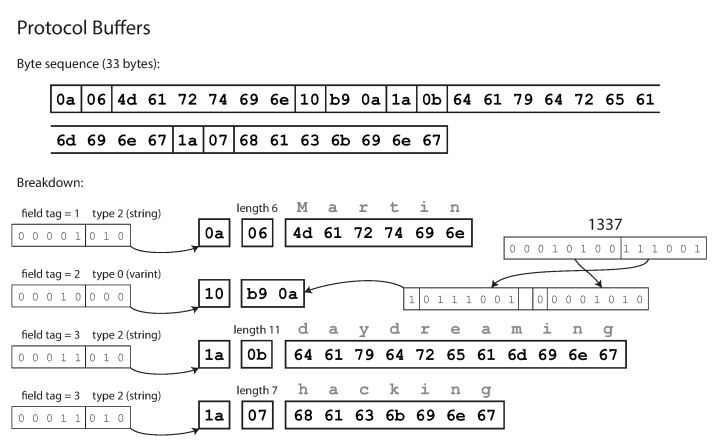
Encoding using Protocol Buffers
Tag numbers support the evolution of schemas in Thrift and Protocol Buffers. If the old code tries to read data written with the new schema, it will simply ignore the fields with the new tag numbers. Likewise, new code can read data written in the old scheme by marking the values as null for missing tag numbers.
Avro
Avro is different from Protocol Buffers and Thrift. Avro also uses a schema to define data. The schema can be defined using the Avro IDL (human readable format):
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Or JSON (a more machine-readable format):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
Note that the fields do not have label numbers. The same data encoded with Avro takes only 32 bytes.
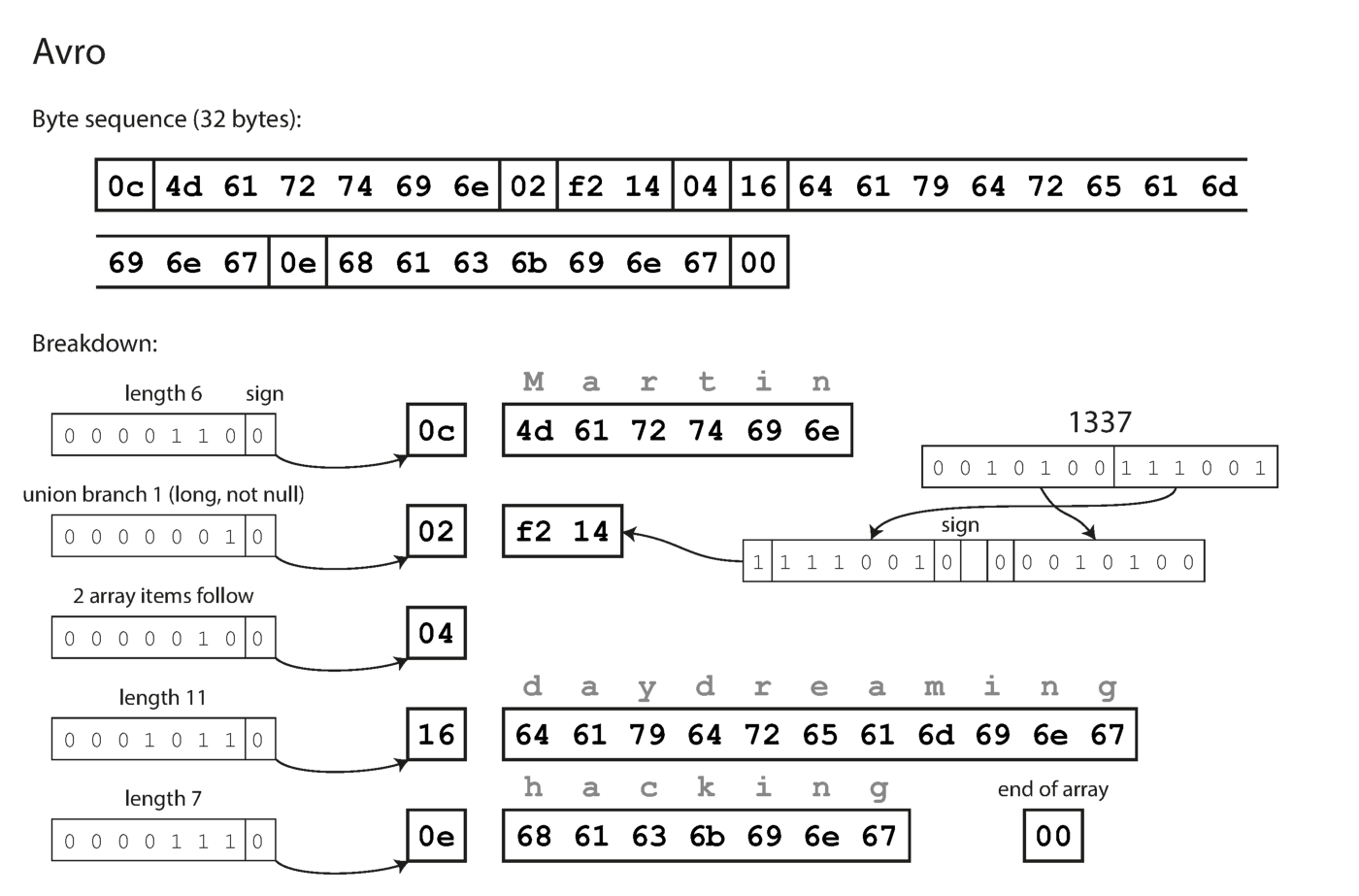
Coding with Avro.
As you can see from the above sequence of bytes, the fields cannot be identified (in Thrift and Protocol Buffers labels with numbers are used for this), it is also impossible to determine the data type of the field. The values are simply put together. Does this mean that any change to the circuit during decoding will generate incorrect data? Avro's key idea is that the schema for writing and reading does not have to be the same, but it must be compatible. When the data is decoded, the Avro library solves this problem by looking at both circuits and translating the data from the recorder circuit to the reader circuit.
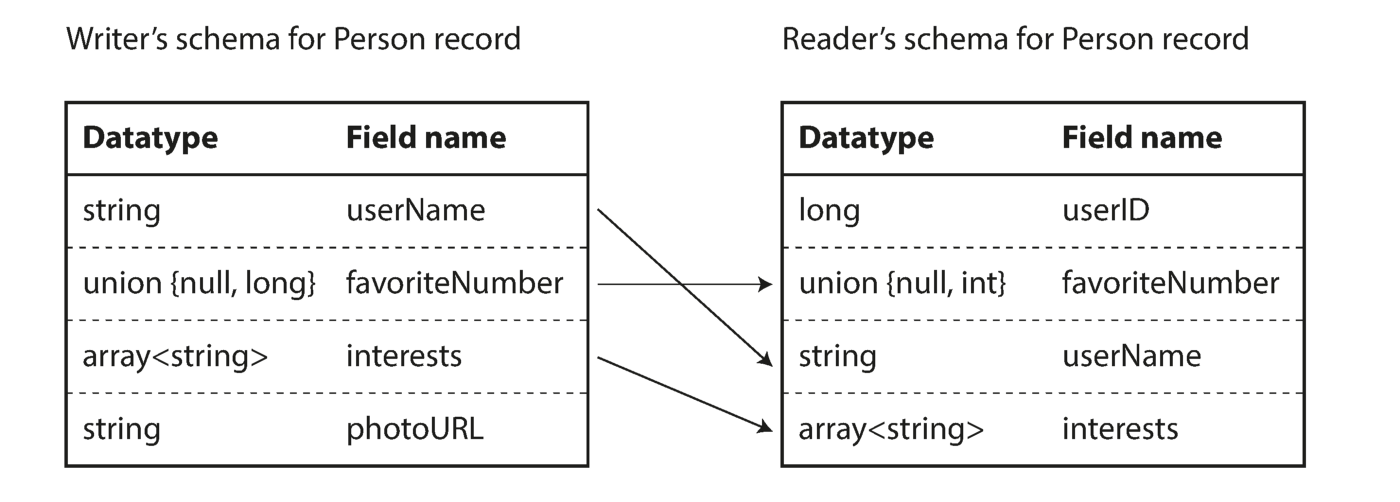
Eliminating the Difference Between Reader and Writer Circuitry
You are probably thinking about how the reader learns about the writer circuitry. It's all about the encoding usage scenario.
- When transferring large files or data, the recorder may include the circuit at the beginning of the file once.
- In a database with individual records, each row can be written with its own schema. The simplest solution is to include a version number at the beginning of each entry and keep a list of schemas.
- To send a record over the network, the reader and writer can agree on a schema when the connection is established.
One of the main advantages of using the Avro format is the support for dynamically generated schemas. Since no numbered tags are generated, you can use a version control system to store different entries encoded with different schemes.
Conclusion
In this article, we looked at text and binary encoding formats, discussed how the same data can occupy 82 bytes with JSON encoded, 33 bytes encoded with Thrift and Protocol Buffers, and only 32 bytes using Avro encoding. Binary formats offer several distinct advantages over JSON when transferring data over the network between back-end services.
Resources
To learn more about encoding and designing data-intensive applications, I highly recommend reading the book Designing Data-Intensive Applications by Martin Kleppman.

Find out the details of how to get a high-profile profession from scratch or Level Up in skills and salary by taking SkillFactory's paid online courses:
- Machine Learning Course (12 weeks)
- Learning Data Science from scratch (12 months)
- Analytics profession with any starting level (9 months)
- Python for Web Development Course (9 months)
Read more
- Trends in Data Scene 2020
- Data Science is dead. Long live Business Science
- Cool Data Scientists don't waste time on statistics
- How to Become a Data Scientist Without Online Courses
- 450 free courses from the Ivy League
- Data Science : «data»
- Data Sciene : Decision Intelligence